Notepad3: German umlaute often an issue
Sample 1: https://s19.directupload.net/images/200309/6lot9a54.png
Sample 2 https://s19.directupload.net/images/200309/h6gatgos.png
Instead the german umlaute the program convert to the wrong char.
But only with some texts document not at all. I've tested different versions from the program
instead a german ä its convert to xE4 with UTF-8 seems ok, but with Ansi or ISO-8859-1 must be ok the program show only the ? instead the german umlaute
Edited: correction of the URL's to show the pictures
 ghost
ghost
All 21 comments
@hpwamr *lol* really... ? he should change the Coding ! or, it should programming in search the switchword "chcp %codingnumber%" to have a automatic recoding in the right codingnumber.. how i told it in the past.. to have the right mutated vowel in German like "für, über and Brücke" / "for, over and bridge" in english.. also the special sigh in a batch file like ascii sign and so on.. ..
@PDirk ... Sachmal Dirk, hast Du vielleicht mal dran gedacht, dass eine Textdatei
in verschiedene arten von codierung sein kann, wie UDF8, UDF16 und in deinem Fall eben sollte sie sein :
=>Datei=>Codierung=> voreinstellung => Pulldownmenu= Central European (Windows-1250)
850 oder eben 1250 damit die Umlaute angezeigt werden.
Wenn Du das so einstellst und dann über strg+umschalt+F (Recodierung as default) immer eingibst und dann abspeicherst, sollte dann auch deine Umlaute ordendlich angezeigt werden..,
anders ist es, wenn Du so gearbeitest hast und dann eben die codierung im textfile nicht gespeichert wird und als andere codierung geöffnet wird, dadurch dann die umlaute nicht correckt angezeigt wird, was ich eben auch das problem hab, deshalb hab ich vor ne weile auch schon gesagt, daß man vielleicht chcp und nummer für die codierung
finden lassen sollte wie eben "chcp 850" oder in deinem fall eben "chcp 1250" in
irgendeiner zeile schreiben können sollte, die dann auch gefunden wird und dann das textdocu auch in eben dieser codierung geöffnet werden solle, hilft bei textdateien und hilft bei cmd/batch dateien die eben dann auch exact die codierung braucht die eben gebraucht wird (codierung siehe wikipedia, die ganzen codierungen haben nummern die dann mit chcp in der commandozeile oder beim Prompt im WinNT aufgerufen werden können)
Daher, auch mein grundbedürftnis in cmd/batch dateien sowas/oder die möglichkeiten zu haben.. irgendwo rein tippern zu können "chcp %codingnumber%" damit dann bei öffnen des textdocuments eben das genauso codiert wird wie's irgendwo drin steht in der datei.
aber bleib mal bei English, wollte dir das nur mal nebenher mitteilen.
( @RaiKoHoff )
 blackcrack
on 9 Mar 2020
blackcrack
on 9 Mar 2020
Upps, @ghost is gone ...
 RaiKoHoff
on 9 Mar 2020
RaiKoHoff
on 9 Mar 2020
@hpwamr : We like UTF-8 everywhere, but maybe we have a lot of users, who are not familiar with file encoding and still use for their text-files their system's code-page (ANSI blabla). Maby we should switch off by default "Open 7-bit ASCII files in UTF-8 mode."
This means, if Encoding-detector is not sure, it prefers local ANSI cod-page over UTF-8.
(This is good old (12y) Notepad2 behavior) 🤔 🤔

RaiKoHoff
on 9 Mar 2020
@RaiKoHoff,
Being a pioneer is not easy! 😬 🤔 🤣
Maybe the general public is not yet mature for UTF-8?
OK, let's try with your proposal as a new default and let's see the reactions! 😏
 hpwamr
on 9 Mar 2020
hpwamr
on 9 Mar 2020
I will be sure to keep an eye on this, being one of the users who has fully transitioned to UTF-8! In particular, my recent files with a small number of UTF8-encoded accented characters. I'm hoping this change won't affect their encoding selection.
Question: wasn't that setting overloaded to do something else at some recent point?
 craigo-
on 9 Mar 2020
craigo-
on 9 Mar 2020
In particular, my recent files with a small number of UTF8-encoded accented characters. I'm hoping this change won't affect their encoding selection.
It will an interesting check. 👍
Feel free to test the RC version "Notepad3Portable_5.20.309.4_RC3.paf.exe.7z" or higher.
See "Notepad3 BETA-channel access #1129" or here Notepad3Portable_5.20.309.4_RC3.paf.exe.7z.7z
Note: "Notepad3Portable RC" can be used in "2 flavors", see with or without extension ".7z".
Your comments and suggestions are welcome... 😃
hpwamr
on 9 Mar 2020
OK, let's try with your proposal as a new default and let's see the reactions! 😏
Hello @RaiKoHoff , @craigo-
NOT sure it's a good idea ! 🤔
- Remember Recent Files --> "Unchecked"
Et le développement continue!---> save file in "UTF-8 and exitEt le développement continue!--> reopend the file (it is now in ANSI (CP-1252)) !!! 😬
hpwamr
on 9 Mar 2020
Tiny examples with only few chars to distinguish are no good tests.
Take your example and save it as ANSI CP-1252. Reopen - et voila - it says Windows CP-1250 😲
BUT: It is still correct (ANSI CP1250 and CP-1252 have the same encoding fo é

With this option OFF, this example works perfectly for both UTF-8 and ANSI CP-1252:


Even this is not German (some German "Umlauts") 🤣
RaiKoHoff
on 9 Mar 2020
The rule of thumbs 👍 is: If users have more UTF-8 files, they should have this option checked (ON),
if they are using more ANSI local CP files, they should have this option unchecked (OFF).
The question for the default setting is: Which users are the majority ?
@craigo- :
Question: wasn't that setting overloaded to do something else at some recent point?
Yes, core meaning is for pure ASCII files, they can be interpreted as ANSI or UTF-8 (no SIG), it does not matter ANSI and UTF-8 have the same encoding for the first 127 chars (7-bit).
This option was to set the users flavor (ANSI or UTF-8).
The double meaning is: If the user prefers the one over the other, the chance is good, that, if the encoding analyzer is not sure to chose ANSI or UTF-8, this option shows the direction 😉 .
RaiKoHoff
on 9 Mar 2020
@ghost i hope it helps now :)
blackcrack
on 10 Mar 2020
With this option OFF, this example works perfectly for both UTF-8 and ANSI CP-1252:
Hello @RaiKoHoff ,
Maybe, It works because your "AnalyzeReliableConfidenceLevel=92%" is changed to 66% ? 🤔 🤔
hpwamr
on 10 Mar 2020
https://en.wikipedia.org/wiki/Code_page
@hpwamr
is not utf-8 8 bit ?
code page 65000 =UTF-7 Unicode
code page 65001 = UTF-8 Unicode
and the US Ascii is 7 Bit :
cp 20127 US-ASCII char (7 Bit)
best regards
Blacky
https://de.wikipedia.org/wiki/Zeichensatztabelle
blackcrack
on 10 Mar 2020
@blackcrack : UTF-8 is a Multi-Byte-Character-Set (MBCS) to be able to encode Unicode characters.

Quelle: https://de.wikipedia.org/wiki/UTF-8#Zul%C3%A4ssige_Bytes_und_ihre_Bedeutung
The English Wikipedia pages don't have the same nice graphic ...
RaiKoHoff
on 10 Mar 2020
@hpwamr : Let us analyze following case with a confidence level of 92%:

The encoding detection (analysis) is not sure (for CP-1252: 80% < 92%) so its answer is CP-1252 but not reliable. Then the fallback will be used:
- if
Open 7-bit ASCII files in UTF-8 mode.is checked OK: it chooses UTF-8, which is WRONG. - if
Open 7-bit ASCII files in UTF-8 mode.is _NOT_ checked: it chooses my OS-CP, which is CP-1252, which is CORRECT.
So what to do ?
The best is the rule of thumbs from comment above.
RaiKoHoff
on 10 Mar 2020
@hpwamr :
I increased the cohesion to locale ANSI CP a little bit.
Feel free to test the RC version "Notepad3Portable_5.20.310.1_RC3.paf.exe.7z" or higher.
See "Notepad3 BETA-channel access #1129" or here Notepad3Portable_5.20.310.1_RC3.paf.exe.7z.7z
I thing a confidence level of 92% is very high, the power of UCHARDET gets lost.
For a good level:
Let Open 7-bit ASCII files in UTF-8 mode. ON (the UTF-8 lovers default) and
create some test files for your locale ANSI (CP-1252 I assume) containing different Belgian/French text ( é à ..., maybe German's ßäüöÄÖÜ etc), maybe batch files with French comments, etc. and watch the confidence level detected .. 🤔 (To get correct CP-1252 instead of UTF-8).
RaiKoHoff
on 10 Mar 2020
I thing a confidence level of 92% is very high, the power of UCHARDET gets lost.
Hello @RaiKoHoff ,
I'm just back at home, I will test v310.1 asap.
In the test, we have also to taking in account the 20 UTF-8 test files in Notepad3\test\test_files\encoding\UTF-8\
- if Open 7-bit ASCII files in UTF-8 mode. is checked, it's OK: all 20/20 files are correctly displayed!
if Open 7-bit ASCII files in UTF-8 mode. is NOT checked: Only 13/20 files are correct (7 files are NOT correctly displayed, because thy are NOT recognized as UTF-8) ! 🤔
hpwamr
on 10 Mar 2020
Hello @RaiKoHoff ,
My opinion is "Open 7-bit ASCII files in UTF-8 mode" must remain checked! 😏
Here are 2 examples with a summary of the lines with special characters.
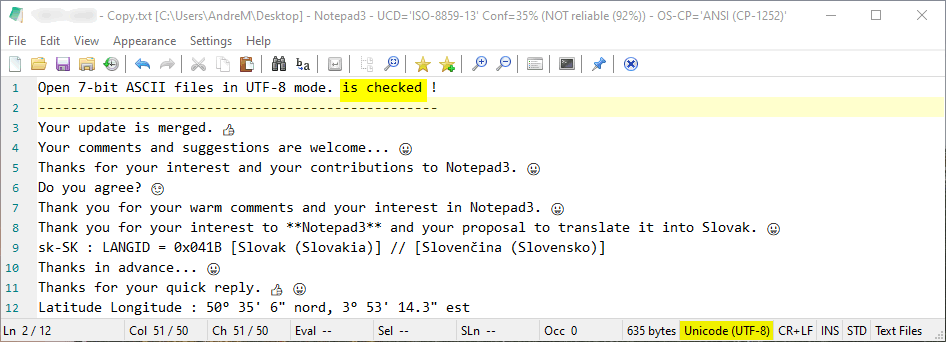
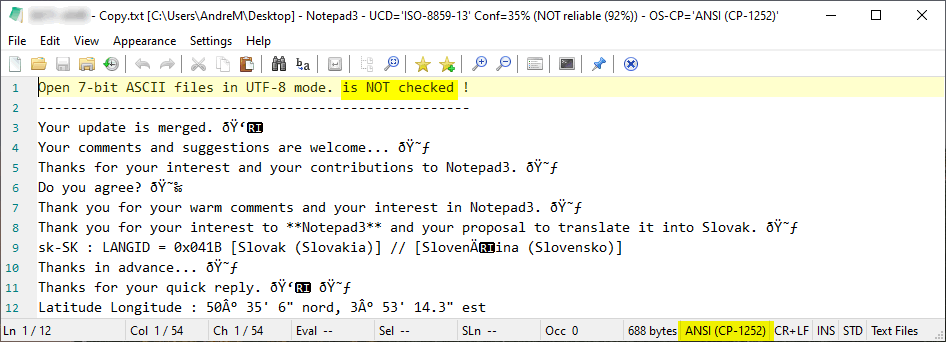
hpwamr
on 10 Mar 2020
My analysis of one file matches that of @hpwamr...
Notepad3 (64-bit) v5.20.310.1 RC3:
(Note that UCD's encoding guess is incorrect in any case.)
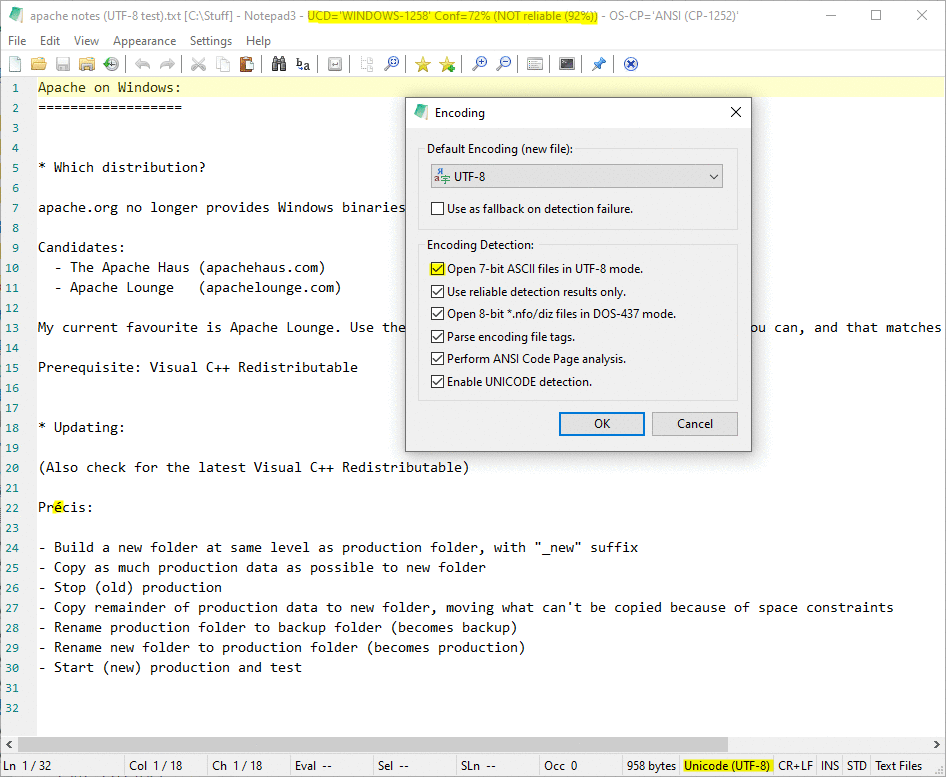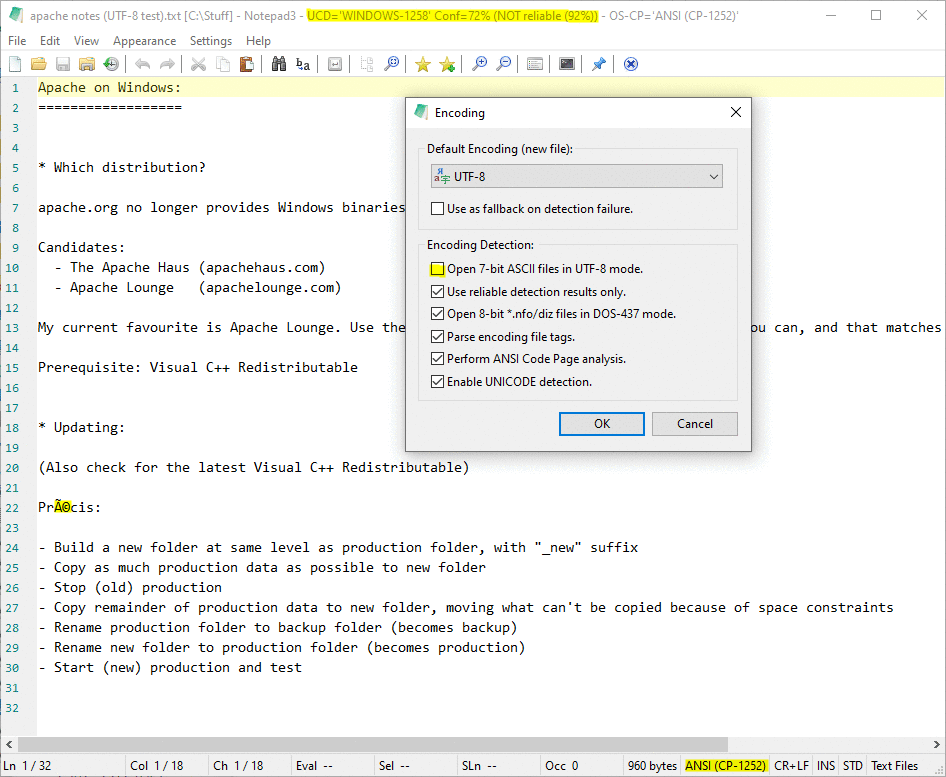
craigo-
on 11 Mar 2020
Hello @RaiKoHoff , @craigo- ,
This text: Summary special chars in UTF-8.txt is definitely an UTF-8 text (confirmed by: Notepad++, VS Code 2019, EditPadLite, Notepad2-zufuliu, etc..)!!! 😃
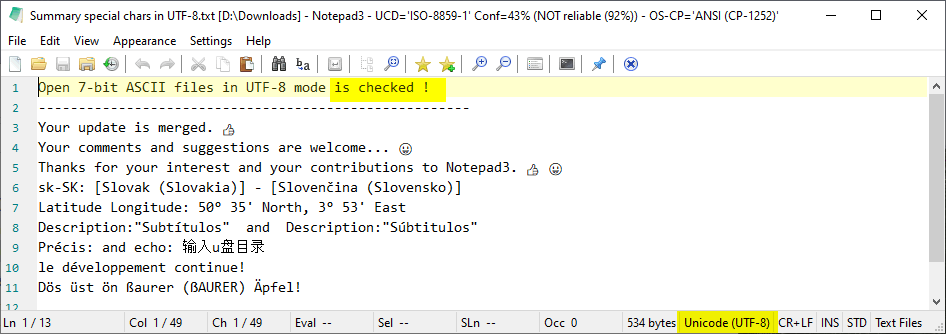
And "Uncheck" "Open 7-bit ASCII files in UTF-8 mode" should NOT display it as an ANSI text !!! 😬
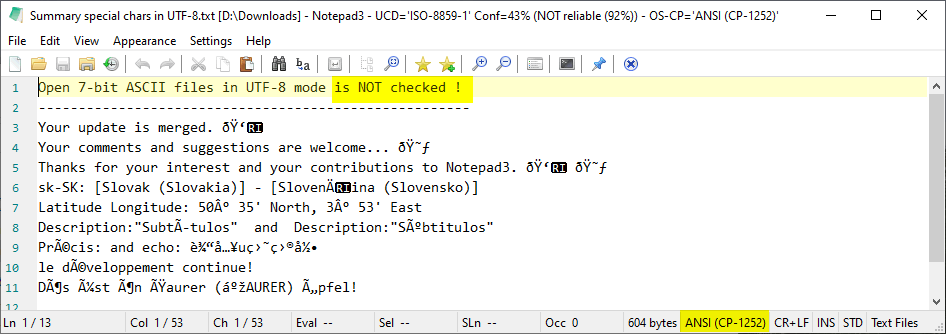
hpwamr
on 11 Mar 2020
For the latest betas, I removed the double meaning for Open 7-bit ASCII files in UTF-8 mode.
It now has its origin meaning: How to interpret pure (US-)ASCII: as system's locale ANSI or UTF-8.
To tune the system back, to like system's locale ANSI (if UCHARDET think it is this ANSI CP but not sure), you can raise the confidence voting with parameter [Settings2] LocaleAnsiCodePageAnalysisBonus=33.
This parameter gives a bonus on top of UCHARDET's confidence level if the analyzed ANSI CP is the same as current system's locale ANSI code-page (not if they are different):
- 0 = no bonus
- 50 = add half of difference between confidence and 100% as bonus
(example for 50: if confidence is 72% , then, in case of same ANSI:
(100%-72%) * (50/100) = 14 on top: 72% -> 86% - 100 = 100% confidence that UCHARDET is right, if it detects current system's ANSI CP.
RaiKoHoff
on 12 Mar 2020
This text: Summary special chars in UTF-8.txt is definitely an UTF-8 text (confirmed by: Notepad++, VS Code 2019, EditPadLite, Notepad2-zufuliu, etc..)!!! 😃
Hello @RaiKoHoff ,
Test with Notepad3 (64-bit) v5.20.313.3 RC3:
Now, the UTF-8 file remains correctly UTF-8 when in encoding "Open 7-bit ASCII files in UTF-8 mode" is unchecked! 👍
Hello @ghost ,
As far as I'm concerned, I think you (requester) can close this issue... 🤣
hpwamr
on 14 Mar 2020
Related issues
 tzleon
·
3Comments
tzleon
·
3Comments
 omega32
·
3Comments
omega32
·
3Comments
 dlong500
·
3Comments
dlong500
·
3Comments
 ggordon-vispero
·
3Comments
ggordon-vispero
·
3Comments
 zb-z
·
3Comments
zb-z
·
3Comments
Most helpful comment
For the latest betas, I removed the double meaning for
Open 7-bit ASCII files in UTF-8 mode.It now has its origin meaning: How to interpret pure (US-)ASCII: as system's locale ANSI or UTF-8.
To tune the system back, to like system's locale ANSI (if UCHARDET think it is this ANSI CP but not sure), you can raise the confidence voting with parameter
[Settings2] LocaleAnsiCodePageAnalysisBonus=33.This parameter gives a bonus on top of UCHARDET's confidence level if the analyzed ANSI CP is the same as current system's locale ANSI code-page (not if they are different):
(example for 50: if confidence is 72% , then, in case of same ANSI:
(100%-72%) * (50/100) = 14 on top: 72% -> 86%