Notepad3: Change Encoding-Detector from CED to UCHARDET
Notepad3 uses Google's "Compact Encoding Detector" (CED) to guide the encoding detection for final encoding decission on file load.
Some people think, Mozilla's (u)chardet would generate better results, they would like to switch to this Encoding-Detector.
To feed this discussion with data, I created an experimental Notepad3 version to test the differences between both Encoding-Detectors:
Please test development beta version _5.19.301.1628_XpErImEnTaL from Xperimental sub-dir.
(For beta channel, see issue #160) or download from my Google Drive.
This version shows in the titlebar both original detector results.

The result of new UCHARDET is used to calculate the final encoding result (depending on some other settings: fallback and reliability).
To get a final result close to the UCHARDET detector, please use following default encoding settings:

Don't forget to disable the file history (encoding of loaded files is persisted here).
 RaiKoHoff
RaiKoHoff
All 34 comments
Hello @RaiKoHoff ,
In attachment a test with RC files "(be_BY)" 😃

All settings are as you requested.
- Same tests with RC files "(ru_RU)" given a Conf=75% CED (NOT reliable)
- Same tests with RC files "(ja-JP)", "(zn-CN)", "(ko-KR)" given a Conf=99% CED (reliable)
Do you want that I perform others tests. 🤔
 hpwamr
on 1 Mar 2019
hpwamr
on 1 Mar 2019
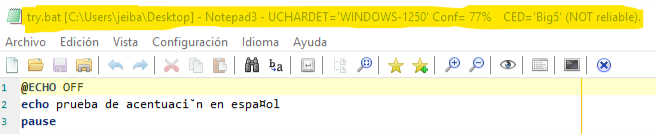
I would have liked it to detect the CP DOS-850
This is my test:
 jczanfona
on 1 Mar 2019
jczanfona
on 1 Mar 2019
Hi @RaiKoHoff ,
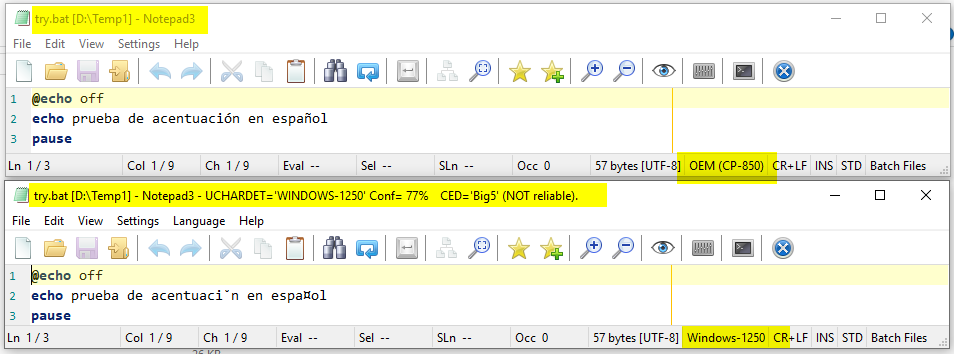
- 1st screenshot : the text is open with
**Notepad3 (64-bit) v5.19.108.1602**(out-of-the-box) and the encoding is changed from UTF-8 (no sign) to OEM(CP-850) and saved as try.bat - 2nd screenshot : the same text is open with
Notepad3 (64-bit) v5.19.301.1628 XpErImEnTaL😬
Attachement: Try_bat.zip
hpwamr
on 2 Mar 2019
Exactly, the same as I said.
jczanfona
on 2 Mar 2019
Obviously too few input characters for both encoding detectors 😞
The easy way out for this cases are "file encoding tags" :
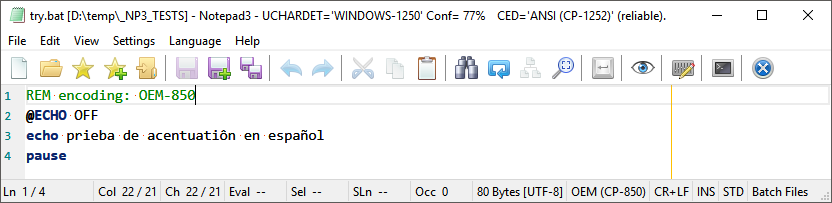
Ensure you didn't activate Don't use file encoding tags. option.
RaiKoHoff
on 2 Mar 2019
Yeah!
For me this works fine:
REM encoding: IBM850
Thanks a lot!
jczanfona
on 2 Mar 2019
Some time ago I suggested using tellenc first, then CED. :smile:
Now I have another idea: back to tellenc.
But in another way: add a dialog in which to show tellenc's statistics for current file.
And save and load this statistics in simple configuration files that users can correct themselves.
 data-man
on 2 Mar 2019
data-man
on 2 Mar 2019
@data-man : Yes tellenc is very lean in adding source-code to Notepad3 (only one file),
unfortunately, tellenc's "_one language-special-char occurrence frequency analysis_" is a little bit too simple for this purpose.
On the other hand, using both/three (CED and UCHARDET (and tellenc) ) for encoding detection and choose the best of two/three worlds, would be too much, since the corresponding detection intersection will be quite huge ... 🤔
Nice idea, to show a selection dialog in case of ambiguity 😃
RaiKoHoff
on 2 Mar 2019
Development beta version _5.19.304.1630_XpErImEnTaL uses both detector results in final decision.
Ed.: This version also enhanced the commandline encoding selection (using all encoding possibilities).
(For beta channel, see issue #160) or download from my Google Drive.
RaiKoHoff
on 4 Mar 2019
New test with of "BAD Detection" of af-AF RC files.

hpwamr
on 4 Mar 2019
Regarding last comment https://github.com/rizonesoft/Notepad3/issues/973#issuecomment-469394975:
CED has no confidence level but only reliable=true/false. To compare both reliability levels, I set CED(reliable)=75%_confidence - so CED detection won (52% < 75%).
Maybe 75% is too much, will reduce that to ???.
RaiKoHoff
on 4 Mar 2019
Found a small UCHARDET documentation, worth to know:
Uchardet uses language data, and therefore rather than supporting a
charset, we in fact support a couple (language, charset). So for
instance if uchardet supports (French, ISO-8859-15), it should be able
to recognize French text encoded in ISO-8859-15, but may fail at
detecting ISO-8859-15 for non-supported languages.This is why, though less flexible, it also makes uchardet much more
accurate than other detection system, as well as making it an efficient
language recognition system._Since many single-byte charsets actually share the same layout (or very_
_similar ones), it is actually impossible to have an accurate single-byte_
_encoding detector for random text._Therefore you need to describe the language and the codepoint layouts of
every charset you want to add support for.Notepad3 implementation uses UCHARDET code taken from:
https://github.com/PyYoshi/uchardet#supported-languagesencodings.
RaiKoHoff
on 4 Mar 2019
Unrelated, but probably not worthy of a separate issue...
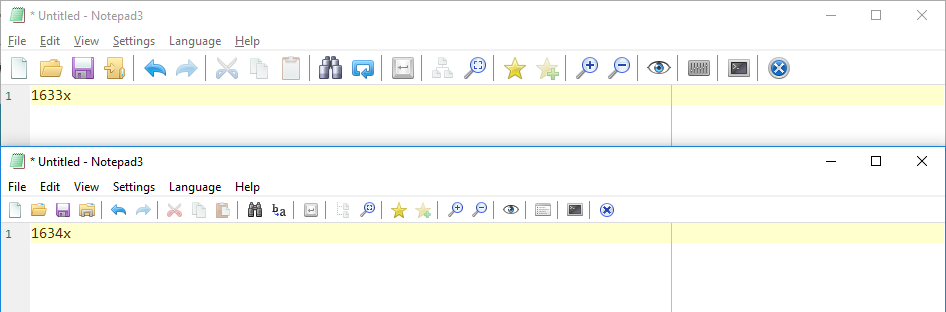
Between 1633x and 1634x, did something change with regards to the HighDPI toolbar selection code?
Out of the box, on a 1920 x 1080 display:
- Notepad3 (64-bit) v5.19.304.1633 XpErImEnTaL: HighDPI Toolbar selected
- Notepad3 (64-bit) v5.19.304.1634 XpErImEnTaL: HighDPI Toolbar unselected
 craigo-
on 5 Mar 2019
craigo-
on 5 Mar 2019
Between 1633x and 1634x, did something change with regards to the HighDPI toolbar selection code?
Hello @RaiKoHoff ,
I confirm, @craigo- above issue, the HightDPI Toolbar is no longer selected by default ? 😉
Idem for v5.19.305.1636_XpErImEnTaL
hpwamr
on 5 Mar 2019
Tested with: v5.19.305.1636 XpErImEnTaL
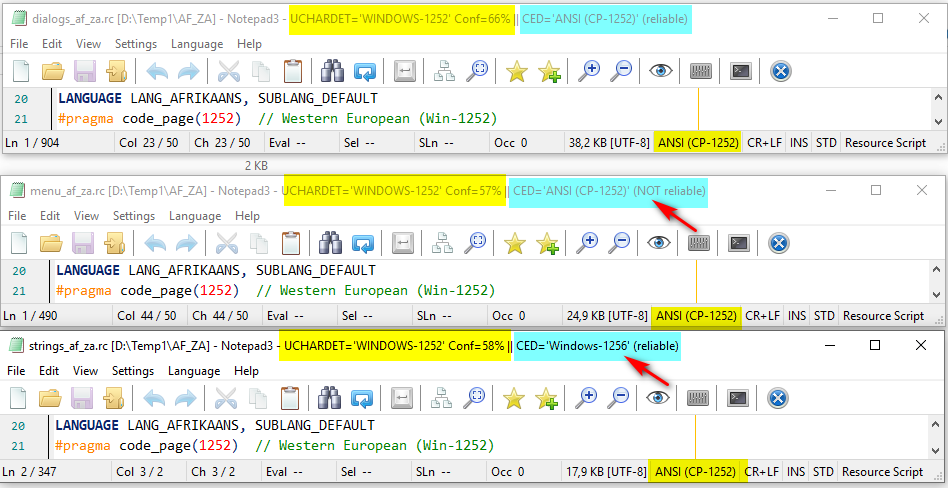
With "Training for Afrikaans" in "UCHARDET", the result of RC "af-ZA" detection is correct. 😄
My opinion:
- With its training ability and its detection parameter in "%", UCHARDET is really superior ! 😄
- Let's drop-out CED ! 😏
hpwamr
on 5 Mar 2019
@hpwamr , @craigo- : You are right: rework of loading external toolbar bitmap introduced this little problem, should be fixed with _5.19.305.1637_XpErImEnTaL.
Training capabilities of UCHARDET are limited, it is not a machine-learning Artificial-Intelligence :wink:
RaiKoHoff
on 5 Mar 2019
Please test version _5.19.307.1647_XpErImEnTaL.
I think, we should keep both detectors, to get the best of both worlds:
New[Settings2] options:
DevDebugMode=1
# Encoding Detector information in Titlebar (maybe later used for other output)
AnalyzeReliableConfidenceLevel=51
# Confidence/Reliability level for reliability switch in encoding dialog:
md5-c26c65e3ed2c54dee264785e7bffef7d
ReliableCEDConfidenceMapping=66 # if CED has reliable result, set this value for Confidence
UnReliableCEDConfidenceMapping=20 # if CED has not a reliable result, set this value for Confidence
Setting ReliableCEDConfidenceMapping to 100(%), reliable results from CED will win over UCHARDET results.
Setting UnReliableCEDConfidenceMapping to values grater than UCHARDET's Confidence-Level,
unreliable CED results will win over UCHARDET's result.
Setting UnReliableCEDConfidenceMapping to values grater than AnalyzeReliableConfidenceLevel,
unreliable CED results may be used, even with reliability switch ON.
RaiKoHoff
on 7 Mar 2019
I think, we should keep both detectors, to get the best of both worlds:
I like the UCHARSET analysis and philosophy, but YES, I agree with you, sometimes both detection methods are needed to improve the end result.... 😉
hpwamr
on 7 Mar 2019
:+1: version _5.19.307.1648_XpErImEnTaL starts the detectors in parallel for large files, so the detection speed is optimized. Unfortunately the binaries grow in size because of the <futures> usage.
RaiKoHoff
on 7 Mar 2019
What is happening:
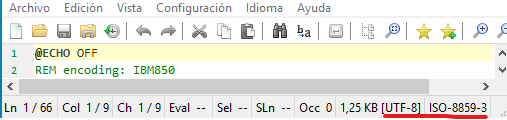
Notepad3 (64-bit) v5.19.309.1652 XpErImEnTaL
I've unckeked the option: 'Don't parse encoding file tags'
jczanfona
on 9 Mar 2019
Versions v5.19.309.1652 and above are working fine for me ?
Please clear file History, maybe a wrong encoding is written there ?
RaiKoHoff
on 9 Mar 2019
There si nothing to clean: just I downloaded the version and make the try (the history was empty)
😮
jczanfona
on 9 Mar 2019
There si nothing to clean: just I downloaded the version and make the try (the history was empty)
5.19.309.1654 is available.
 lenny20
on 9 Mar 2019
lenny20
on 9 Mar 2019
For another test that I have done, it seems that the '_Encoding file tag_' must be placed in the 1st line (not in the 2nd).
Is it really mandatory?
jczanfona
on 9 Mar 2019
In my opinon, the encoding tags is useful for parsing easily.
lenny20
on 9 Mar 2019
@lenny20 , @jczanfona : please see my comment for encoding tags : https://github.com/rizonesoft/Notepad3/issues/964#issuecomment-471358716
RaiKoHoff
on 11 Mar 2019
As we want to keep both encoding detectors, we need a reasonable default value for:
AnalyzeReliableConfidenceLevel=51
# Confidence/Reliability level for reliability switch in encoding dialog
(Currently set to 51%)
and
ReliableCEDConfidenceMapping=66 # if CED has reliable result, set this value for Confidence
UnReliableCEDConfidenceMapping=20 # if CED has not a reliable result, set this value for Confidenc
Last parameters are for balancing results between UCHARDET and CED ... 🤔
RaiKoHoff
on 11 Mar 2019
To give CED more weight in decision making, I would like to raise its (initial default) confidence level of a "reliable" result to 85% (ReliableCEDConfidenceMapping=85).
(Means if CED's result is "reliable", it gets a confidence level of 85. UCHARDET's confidence level must be higher to beat CED).
What do you think?
(Yes, having a statistic would be better base for decision, currently this value is only a gut feeling)
RaiKoHoff
on 27 Mar 2019
Hello @RaiKoHoff ,
Tested with all my MUI Resources files with the new settings #1093
It seems to me OK. 🤔
Hello @lhmouse and @lenny20
It would be very interesting to have a feedback from the Chinese tester's side ? 😉
Latest beta of today: Notepad3Portable_5.19.328.1666_develop.paf.exe.7z
hpwamr
on 28 Mar 2019
@hpwamr : Did you switch on "Don't parse encoding file tags"? Otherwise there is no encoding detection, the file tags overrule the detection ;-)
RaiKoHoff
on 28 Mar 2019
Oops, I just forgot...
I will renew my tests and make a statistical table.
@RaiKoHoff Could you, please, check in "Exchange" the file "UCHARDET_CET_Detection_Rate.xlsx"
Let me know if you want more details. 🤔
hpwamr
on 28 Mar 2019
I have encountered no encoding detection problems so far.
 lhmouse
on 29 Mar 2019
lhmouse
on 29 Mar 2019
With beta version v5.19.503.1689, the CED encoding detector has been removed from the binaries.
Some detection analysis shows, that there is few/no supplementary benefit from CED using it concurrently to UCHARDET.
(So the "debug" display, as shown above, changed accordingly.)
RaiKoHoff
on 10 May 2019
With the change from CED to UCHARDET, I did not encounter any detection issue.
As far as I am concerned, this issue may be closed....
hpwamr
on 17 Jun 2019
Related issues
 valhristov
·
3Comments
hpwamr
·
3Comments
valhristov
·
3Comments
hpwamr
·
3Comments
 tzleon
·
3Comments
tzleon
·
3Comments
 zb-z
·
3Comments
zb-z
·
3Comments
 omega32
·
3Comments
omega32
·
3Comments
Most helpful comment
With beta version v5.19.503.1689, the CED encoding detector has been removed from the binaries.
Some detection analysis shows, that there is few/no supplementary benefit from CED using it concurrently to UCHARDET.
(So the "debug" display, as shown above, changed accordingly.)