Notepad3: UTF-8 Encoding Detection Broken
UTF-8 detection is broken since commit: 63b09def6ab3b6671311bac16438447113202e56
+ enh: optimized UTF-8 enoding detection
My UTF-8 files are detected as ANSI (CP-1252).
Reverting to commit 48e8e2f3e90851bfdac3333bc0ed6815ed046063 fixes the problem.
To reproduce:
- Discard the file history so that Notepad3 forgets about the encoding of your files. Either deleting the contents of section
[Recent Files]in the .ini config file or through the GUI (File> Recent (History)... > Discard). - Open a UTF-8 encoded file. The detected encoding won't be UTF-8. In my case, they are detected as ANSI (CP-1252).
 omega32
omega32
All 14 comments
Related to #614.
Please provide some example files for testing (preferred .zip package).
 RaiKoHoff
on 22 Aug 2018
RaiKoHoff
on 22 Aug 2018
I'm attaching a test UTF-8 encoded file (utf-8.txt). I'm also including my Notepad3.ini just in case.
issue#618.zip
If you open utf-8.txt with Notepad3 63b09def6ab3b6671311bac16438447113202e56 or newer, the encoding it's not detected correctly.
omega32
on 22 Aug 2018
Hello @RaiKoHoff ,
I confirm the issue of @omega32 🤔
- With the first opening of:
utf-8.txtwithNotepad3 (64-bit) v4.18.512.992
NP3.ini file:
[Recent Files]
01=D:\Downloadsutf-8.txt
ENC01=3
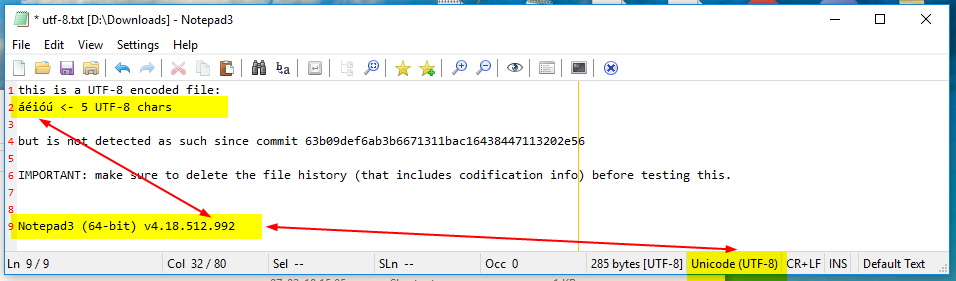
- With the first opening of:
utf-8.txtwithNotepad3 (64-bit) TinyExpr v4.18.821.1066
NP3.ini file:
[Recent Files]
01=D:\Downloadsutf-8.txt
!!! NO "ENCxx" Settings with this version !!!

 hpwamr
on 22 Aug 2018
hpwamr
on 22 Aug 2018
I am currently reworking the Unicode, UTF-8 and ANSI-CodePage detection stuff.
Thanks for testing - please test development beta version _TinyExpr_4.18.822.1067.
RaiKoHoff
on 22 Aug 2018
Short explanation of encoding detection settings:

By default, Notepad3 uses the Window System's ANSI CodePage for file encoding ( e.g. Western European (Windows-1252) - which is Code Page 1252). Which is set at the _top_ of the selection list-box (dependent on Systems regional settings).
I the file has been loaded before and is still recorded in Notepad3's the file history, the encoding of the file history record (recorded in history, when file has been closed) is enforced.
If you open a file (and Skip ANSI Code Page detection is checked ON = default) this Systems's ANSI Code Page is used to encode the file - except it is Unicode UTF-8/16.
In case of Unicode files, the encoding should be detected correctly (except Skip UNICODE detection is checked).
In case of only 7-bit characters in file, the file can be encoded as ASCII/ANSI CodePage or UTF-8, the displayed result will be the same.
Use Open 7-bit ASCII files in UTF-8 mode switch to force UTF-8 instead of default ANSI CodePage in this case.
If you have a file with unknown encoding, you can try to use the ANSI Code Page detection (remove the Skip ANSI Code Page detection) to identify the right encoding.
Default Encoding (new file):_obvious_Use as fallback on detection failure:
- Use selected encoding (instead of system's default ANSI CodePage) as preferred encoding
Skip ANSI Code Page detection: _see explanation above_Skip UNICODE detection: IMO there are only very rare cases, where this option is needed.Open 7-bit ASCII files in UTF-8 mode: _see explanation above_Open 8-bit *.nfo/diz files in DOS-437 mode: ->ANSI ArtDon't parse encoding file tags: this flag wil skip the encoding enforcement by the tag in the file.
e.g.// encoding:windows-1257as a first line of a file
@hpwamr : ... worth a documentation entry ?
RaiKoHoff
on 22 Aug 2018
commit e0a5713605a66f1be69df058a9893724b0e28a7b (build 1067) fixes the problem. 👍
tested with latest master commit as well and UTF-8 encoding detection seems to be working again. thanks
omega32
on 22 Aug 2018
Hello @omega32, @RaiKoHoff,
Tested with: Notepad3 (64-bit) TinyExpr v4.18.822.1067
Issue corrected. 👍 ❤️
As far as I am concerned, this issue may be closed....
hpwamr
on 22 Aug 2018
I would like to test the changed detection algorithm against some more UTF-8 files (w/o Signature aka BOM). Do you know a download source in the web?
Ed.: Found some kind of artificial test documents https://github.com/bits/UTF-8-Unicode-Test-Documents. Tests of printable files are satisfying to me, real life files would be better ... 😉
RaiKoHoff
on 22 Aug 2018
Hello @RaiKoHoff,
In attachment 2 small files in UTF-8 w/o signature (and to easily check: "FRHED" a little hex editor) 😄
Updated: TXT_utf-8_W/O_signature.zip
hpwamr
on 23 Aug 2018
Hello,
I may have found an UTF-8 file that is not detected properly [utf8-detection-bug-02.zip]. It was detected properly in commits prior to 63b09def6ab3b6671311bac16438447113202e56. But not in the most recent version.
There may be a repository out-there with example UTF-8 files with edge cases to use as a base to automate some testing... but I haven't found any.
omega32
on 23 Sep 2018
@omega32 : Please test development beta version _TinyExpr_4.18.923.1117 (PR https://github.com/rizonesoft/Notepad3/pull/698)
I relaxed the conditions for being UTF-8 (CED Analyzer: allow less reliable UTF-8 detection results)
RaiKoHoff
on 23 Sep 2018
Hello @omega32, @RaiKoHoff,
Tested with: Notepad3 (64-bit) TinyExpr v4.18.923.1117
The issue with [utf8-detection-bug-02.zip] seems corrected. 👍
As far as I am concerned, this issue may be closed....
hpwamr
on 23 Sep 2018
Thanks. Detection seems to be working better now. It's correctly detecting both my ANSI and UTF-8 files so far. I'll be testing it and reporting back if I find any issues.
omega32
on 23 Sep 2018
@omega32 : thank you for testing - your help is highly appreciated.
RaiKoHoff
on 24 Sep 2018
Related issues
hpwamr
·
4Comments
omega32
·
3Comments
 vvyoko
·
3Comments
vvyoko
·
3Comments
 blackcrack
·
3Comments
blackcrack
·
3Comments
 tzleon
·
3Comments
tzleon
·
3Comments
Most helpful comment
@omega32 : Please test development beta version _TinyExpr_4.18.923.1117 (PR https://github.com/rizonesoft/Notepad3/pull/698)
I relaxed the conditions for being UTF-8 (CED Analyzer: allow less reliable UTF-8 detection results)