Istio: Istio is picking up new virtualservice slowly
Affected product area (please put an X in all that apply)
[ ] Configuration Infrastructure
[ ] Docs
[ ] Installation
[X] Networking
[X] Performance and Scalability
[ ] Policies and Telemetry
[ ] Security
[ ] Test and Release
[ ] User Experience
[ ] Developer Infrastructure
Affected features (please put an X in all that apply)
[ ] Multi Cluster
[ ] Virtual Machine
[ ] Multi Control Plane
Version (include the output of istioctl version --remote and kubectl version and helm version if you used Helm)
client version: 1.5.4
cluster-local-gateway version:
cluster-local-gateway version:
cluster-local-gateway version:
ingressgateway version: 1.5.4
ingressgateway version: 1.5.4
ingressgateway version: 1.5.4
pilot version: 1.5.4
pilot version: 1.5.4
pilot version: 1.5.4
data plane version: 1.5.4 (6 proxies)
How was Istio installed?
cat << EOF > ./istio-minimal-operator.yaml
apiVersion: install.istio.io/v1alpha1
kind: IstioOperator
spec:
values:
global:
proxy:
autoInject: disabled
useMCP: false
# The third-party-jwt is not enabled on all k8s.
# See: https://istio.io/docs/ops/best-practices/security/#configure-third-party-service-account-tokens
jwtPolicy: first-party-jwt
addonComponents:
pilot:
enabled: true
prometheus:
enabled: false
components:
ingressGateways:
- name: istio-ingressgateway
enabled: true
- name: cluster-local-gateway
enabled: true
label:
istio: cluster-local-gateway
app: cluster-local-gateway
k8s:
service:
type: ClusterIP
ports:
- port: 15020
name: status-port
- port: 80
name: http2
- port: 443
name: https
EOF
./istioctl manifest generate -f istio-minimal-operator.yaml \
--set values.gateways.istio-egressgateway.enabled=false \
--set values.gateways.istio-ingressgateway.sds.enabled=true \
--set values.gateways.istio-ingressgateway.autoscaleMin=3 \
--set values.gateways.istio-ingressgateway.autoscaleMax=6 \
--set values.pilot.autoscaleMin=3 \
--set values.pilot.autoscaleMax=6 \
--set hub=icr.io/ext/istio > istio.yaml
kubectl apply -f istio.yaml // more visibility than istioctl manifest apply
Environment where bug was observed (cloud vendor, OS, etc)
IKS
When we create ~1k virtualservices in a single cluster, the ingress gateway is picking up new virtualservice slowly.

The blue line in the chart indicates the overall time for probing to gateway pod return with success. (200 response code and expected header K-Network-Hash). The stepped increasing of time is caused by the exponential retry backoff to execute probing. But the overall trend seems to have a linear growth which takes ~50s for a new virtual service to be picked up with 800 virtual services present.
I also tried to dump and grep the configs in istio-ingress-gateway pod after the virtual service was created.
Initially the output was empty and It takes about 1min for the belowing result to showup.
curl localhost:15000/config_dump |grep testabc
"name": "outbound_.8022_._.testabc-hhmjj-1-private.default.svc.cluster.local",
"service_name": "outbound_.8022_._.testabc-hhmjj-1-private.default.svc.cluster.local"
"name": "outbound_.80_._.testabc-hhmjj-1-private.default.svc.cluster.local",
"service_name": "outbound_.80_._.testabc-hhmjj-1-private.default.svc.cluster.local"
"name": "outbound_.80_._.testabc-hhmjj-1.default.svc.cluster.local",
"service_name": "outbound_.80_._.testabc-hhmjj-1.default.svc.cluster.local"
"name": "outbound_.9090_._.testabc-hhmjj-1-private.default.svc.cluster.local",
"service_name": "outbound_.9090_._.testabc-hhmjj-1-private.default.svc.cluster.local"
"name": "outbound_.9091_._.testabc-hhmjj-1-private.default.svc.cluster.local",
"service_name": "outbound_.9091_._.testabc-hhmjj-1-private.default.svc.cluster.local"
"name": "outbound|8022||testabc-hhmjj-1-private.default.svc.cluster.local",
"service_name": "outbound|8022||testabc-hhmjj-1-private.default.svc.cluster.local"
"sni": "outbound_.8022_._.testabc-hhmjj-1-private.default.svc.cluster.local"
"name": "outbound|80||testabc-hhmjj-1-private.default.svc.cluster.local",
"service_name": "outbound|80||testabc-hhmjj-1-private.default.svc.cluster.local"
"sni": "outbound_.80_._.testabc-hhmjj-1-private.default.svc.cluster.local"
"name": "outbound|80||testabc-hhmjj-1.default.svc.cluster.local",
"service_name": "outbound|80||testabc-hhmjj-1.default.svc.cluster.local"
"sni": "outbound_.80_._.testabc-hhmjj-1.default.svc.cluster.local"
"name": "outbound|9090||testabc-hhmjj-1-private.default.svc.cluster.local",
"service_name": "outbound|9090||testabc-hhmjj-1-private.default.svc.cluster.local"
"sni": "outbound_.9090_._.testabc-hhmjj-1-private.default.svc.cluster.local"
"name": "outbound|9091||testabc-hhmjj-1-private.default.svc.cluster.local",
"service_name": "outbound|9091||testabc-hhmjj-1-private.default.svc.cluster.local"
"sni": "outbound_.9091_._.testabc-hhmjj-1-private.default.svc.cluster.local"
"name": "testabc.default.dev-serving.codeengine.dev.appdomain.cloud:80",
"testabc.default.dev-serving.codeengine.dev.appdomain.cloud",
"testabc.default.dev-serving.codeengine.dev.appdomain.cloud:80"
"prefix_match": "testabc.default.dev-serving.codeengine.dev.appdomain.cloud"
"cluster": "outbound|80||testabc-hhmjj-1.default.svc.cluster.local",
"config": "/apis/networking.istio.io/v1alpha3/namespaces/default/virtual-service/testabc-ingress"
"operation": "testabc-hhmjj-1.default.svc.cluster.local:80/*"
"value": "testabc-hhmjj-1"
"name": "testabc.default.svc.cluster.local:80",
"testabc.default.svc.cluster.local",
"testabc.default.svc.cluster.local:80"
"prefix_match": "testabc.default.dev-serving.codeengine.dev.appdomain.cloud"
"cluster": "outbound|80||testabc-hhmjj-1.default.svc.cluster.local",
"config": "/apis/networking.istio.io/v1alpha3/namespaces/default/virtual-service/testabc-ingress"
"operation": "testabc-hhmjj-1.default.svc.cluster.local:80/*"
"value": "testabc-hhmjj-1"
"name": "testabc.default.svc:80",
"testabc.default.svc",
"testabc.default.svc:80"
"prefix_match": "testabc.default.dev-serving.codeengine.dev.appdomain.cloud"
"cluster": "outbound|80||testabc-hhmjj-1.default.svc.cluster.local",
"config": "/apis/networking.istio.io/v1alpha3/namespaces/default/virtual-service/testabc-ingress"
"operation": "testabc-hhmjj-1.default.svc.cluster.local:80/*"
"value": "testabc-hhmjj-1"
"name": "testabc.default:80",
"testabc.default",
"testabc.default:80"
"prefix_match": "testabc.default.dev-serving.codeengine.dev.appdomain.cloud"
"cluster": "outbound|80||testabc-hhmjj-1.default.svc.cluster.local",
"config": "/apis/networking.istio.io/v1alpha3/namespaces/default/virtual-service/testabc-ingress"
"operation": "testabc-hhmjj-1.default.svc.cluster.local:80/*"
"value": "testabc-hhmjj-1"
There is no mem/cpu pressure for istio components.
kubectl -n istio-system top pods
NAME CPU(cores) MEMORY(bytes)
cluster-local-gateway-644fd5f945-f4d6d 29m 953Mi
cluster-local-gateway-644fd5f945-mlhkc 34m 952Mi
cluster-local-gateway-644fd5f945-nt4qk 30m 958Mi
istio-ingressgateway-7759f4649d-b5whx 37m 1254Mi
istio-ingressgateway-7759f4649d-g2ppv 43m 1262Mi
istio-ingressgateway-7759f4649d-pv6qs 48m 1431Mi
istiod-6fb9877647-7h7wk 8m 875Mi
istiod-6fb9877647-k6n9m 9m 914Mi
istiod-6fb9877647-mncpn 26m 925Mi
Below is a typical virtual service created by knative.
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
annotations:
networking.knative.dev/ingress.class: istio.ingress.networking.knative.dev
creationTimestamp: "2020-07-20T08:23:54Z"
generation: 1
labels:
networking.internal.knative.dev/ingress: hello29
serving.knative.dev/route: hello29
serving.knative.dev/routeNamespace: default
name: hello29-ingress
namespace: default
ownerReferences:
- apiVersion: networking.internal.knative.dev/v1alpha1
blockOwnerDeletion: true
controller: true
kind: Ingress
name: hello29
uid: 433c415d-901e-4154-bfd9-43178d0db192
resourceVersion: "47989694"
selfLink: /apis/networking.istio.io/v1beta1/namespaces/default/virtualservices/hello29-ingress
uid: 20162863-b721-4d67-aa19-b84adc7dffe0
spec:
gateways:
- knative-serving/cluster-local-gateway
- knative-serving/knative-ingress-gateway
hosts:
- hello29.default
- hello29.default.dev-serving.codeengine.dev.appdomain.cloud
- hello29.default.svc
- hello29.default.svc.cluster.local
http:
- headers:
request:
set:
K-Network-Hash: 12a72f65db15ba3a00ad16b328c40b5398a86cc84ba3239ad37f4d5ef811b0fa
match:
- authority:
prefix: hello29.default
gateways:
- knative-serving/cluster-local-gateway
retries: {}
route:
- destination:
host: hello29-cpwpf-1.default.svc.cluster.local
port:
number: 80
headers:
request:
set:
Knative-Serving-Namespace: default
Knative-Serving-Revision: hello29-cpwpf-1
weight: 100
timeout: 600s
- headers:
request:
set:
K-Network-Hash: 12a72f65db15ba3a00ad16b328c40b5398a86cc84ba3239ad37f4d5ef811b0fa
match:
- authority:
prefix: hello29.default.dev-serving.codeengine.dev.appdomain.cloud
gateways:
- knative-serving/knative-ingress-gateway
retries: {}
route:
- destination:
host: hello29-cpwpf-1.default.svc.cluster.local
port:
number: 80
headers:
request:
set:
Knative-Serving-Namespace: default
Knative-Serving-Revision: hello29-cpwpf-1
weight: 100
timeout: 600s
---
 lanceliuu
lanceliuu
All 82 comments
How is pilot doing? Is workload properly distributed to each pilot instance?
Also, can you describe your scenario on fast you are applying these VSs? And can you disable telemetry v2 if you are not using it?
 linsun
on 21 Jul 2020
linsun
on 21 Jul 2020
@linsun how to check the pilot if doing well ? In our case, from the diagram(blue line), the delay is increasing continually when we create knative service, each knative service will create one VS to config route in istio gateway.
And the output is of testabc is result of config route in istio gateway after we created 800 knative service, existing 800 knative service causes 1 min delay from VS creation to config route in istio gateway.
For telemetry, I do not think we enable it, you can check the install script we are using. Or how to check if telemetry v2 enabled or not ?
 ZhuangYuZY
on 21 Jul 2020
ZhuangYuZY
on 21 Jul 2020
@linsun we tested this case on istio 1.6.5, the behavior is same. Thank you.
ZhuangYuZY
on 22 Jul 2020
@ZhuangYuZY I have not personally ran a systemwide profile (yet) with your use case - however usually kubeapi is the culprit in this scenario. I have ran systemwide profiles of creating a service entry CR, and see very poor performance in past versions.
The diagnosed problem in the SE scenario is kubeapi rate-limits incoming CR creation, which will make it appear as if "Istio" is slow. Istio's discovery mechanism works by reading K8s's CR list. K8s CR creation is slow. Therefore, Istio is often blamed for K8s API scalability problems.
Kubernetes can only handle so many creations of any type of object per second, and the count is low.
I'll take a look early next week at this particular problem for you and verify this is just not how Kubernetes "works"...
Cheers,
-steve
 sdake
on 30 Jul 2020
sdake
on 30 Jul 2020
cc / @mandarjog
sdake
on 30 Jul 2020
Basic tooling to test with and without Istio in the path: https://github.com/sdake/knative-perf
sdake
on 1 Aug 2020
Running the manifest created by the vs tool in https://github.com/istio/istio/issues/25685#issuecomment-667541373, but changing the hub to a valid hub, the following results are observed:
real 0m13.657s
user 0m2.886s
sys 0m0.451s
System = VM on vsphere7 with 128gb ram + 8 cores, istio-1.6.5
sdake
on 1 Aug 2020
Running with just an application of vs-crd.yaml and not istio.yaml - the timings look much better:
real 0m8.271s
user 0m3.036s
sys 0m0.426s
(edit - first run of this had an error, re-ran - slightly slower results)
With istio.yaml applied, the validating webhook was manually deleted:
sdake@sdake-dev:~/knative-perf$ kubectl delete ValidatingWebhookConfiguration -n istio-system istiod-istio-system
The results were close to baseline (vs-crd.yaml):
real 0m9.997s
user 0m3.043s
sys 0m0.468s
@lanceliuu - is the use case here that knative uses a pattern of creating a large amount of virtual services, all at about the same time? Attempting to replicate your benchmark - it feels synthetic, and I am curious if it represents a real-world use case.
Cheers,
-steve
sdake
on 1 Aug 2020
ON IKS:
Running with just an application of vs-crd.yaml and not istio.yaml, nearly two extra minutes to create the VS in the remote cluster:
real 2m7.649s
user 0m3.756s
sys 0m0.656s
ON IKS:
Running with istio.yaml and applying vs.yaml from the test repo, the time to create 1000 VS in the remote cluster:
real 1m33.499s
user 0m3.016s
sys 0m1.062s
Yes, we create 800 kn service (trigger 800 vs creation), we saw salability problem of configuration setup in gateway, the time continue increase, from 1 sec to > 1 min.
ZhuangYuZY
on 2 Aug 2020
@ZhuangYuZY I am attempting to reproduce your problem, although I have to write my own tools to do so as you haven't published yours.
Here is the question:
Are you creating 800 vs. then pausing for 5-10 minutes. Then measuring the creation of that last VS at 1 minute?
Or are you measuring the registration of the VS in the ingress gateway after each creation in the kubeapi?
Cheers,
-steve
sdake
on 2 Aug 2020
@sdake
Actually the overall ready time for new vs after creating 800 vs remains stable at about 50s. We did pause for hours and then create new services. In the world of knative the Ready of vs means that a http request probe target to ingress with success response code and expected header K-Network-Hash.
e.g.
curl -v http://hello.default.dev-serving.codeengine.dev.appdomain.cloud -H "User-Agent: Knative-Ingress-Probe" -H "K-Network-Probe: probe"
* Trying 130.198.104.44...
* TCP_NODELAY set
* Connected to hello.default.dev-serving.codeengine.dev.appdomain.cloud (130.198.104.44) port 80 (#0)
> GET / HTTP/1.1
> Host: hello.default.dev-serving.codeengine.dev.appdomain.cloud
> Accept: */*
> User-Agent: Knative-Ingress-Probe
> K-Network-Probe: probe
>
< HTTP/1.1 200 OK
< k-network-hash: 12a72f65db15ba3a00ad16b328c40b5398a86cc84ba3239ad37f4d5ef811b0fa
< date: Mon, 03 Aug 2020 02:54:53 GMT
< content-length: 0
< x-envoy-upstream-service-time: 1
< server: istio-envoy
<
* Connection #0 to host hello.default.dev-serving.codeengine.dev.appdomain.cloud left intact
* Closing connection 0
From the logs of knative we can confirm that the failed probes always caused by 404 response code. It is not related with DNS as the probe force to resolve the domain to the pod ip of istio ingress gateway.
IIRC with 800 ksvcs present, when we create new vs, we can see logs for istiod pilot popping up with logs quickly like following
2020-08-03T02:59:59.849636Z info Handle EDS: 0 endpoints for fddfefllfo-hwblr-1-private in namespace default
2020-08-03T02:59:59.877423Z info Handle EDS: 3 endpoints for fddfefllfo-hwblr-1 in namespace default
2020-08-03T02:59:59.877473Z info ads Full push, new service fddfefllfo-hwblr-1.default.svc.cluster.local
2020-08-03T02:59:59.877485Z info ads Full push, service accounts changed, fddfefllfo-hwblr-1.default.svc.cluster.local
2020-08-03T02:59:59.977789Z info ads Push debounce stable[547] 3: 100.259888ms since last change, 190.482336ms since last push, full=true
So I think it is not related with kube API and informers could cache and refelect the changes quickly.
But currently I have no further clue do diagnose the process after pushing configs to ingress until it is picked up by envoy.
There is another problem which might also affect the performance. For services created by knative, it will also create coressponding kubernetes service and endpoints. And istio will also create rules like following even the virtualservice is not created. I wonder that the EDS might also stress the ingress gateway.
"name": "outbound_.8022_._.testabc-hhmjj-1-private.default.svc.cluster.local",
"service_name": "outbound_.8022_._.testabc-hhmjj-1-private.default.svc.cluster.local"
"name": "outbound_.80_._.testabc-hhmjj-1-private.default.svc.cluster.local",
"service_name": "outbound_.80_._.testabc-hhmjj-1-private.default.svc.cluster.local"
"name": "outbound_.80_._.testabc-hhmjj-1.default.svc.cluster.local",
"service_name": "outbound_.80_._.testabc-hhmjj-1.default.svc.cluster.local"
"name": "outbound_.9090_._.testabc-hhmjj-1-private.default.svc.cluster.local",
"service_name": "outbound_.9090_._.testabc-hhmjj-1-private.default.svc.cluster.local"
"name": "outbound_.9091_._.testabc-hhmjj-1-private.default.svc.cluster.local",
"service_name": "outbound_.9091_._.testabc-hhmjj-1-private.default.svc.cluster.local"
"name": "outbound|8022||testabc-hhmjj-1-private.default.svc.cluster.local",
"service_name": "outbound|8022||testabc-hhmjj-1-private.default.svc.cluster.local"
"sni": "outbound_.8022_._.testabc-hhmjj-1-private.default.svc.cluster.local"
"name": "outbound|80||testabc-hhmjj-1-private.default.svc.cluster.local",
"service_name": "outbound|80||testabc-hhmjj-1-private.default.svc.cluster.local"
"sni": "outbound_.80_._.testabc-hhmjj-1-private.default.svc.cluster.local"
"name": "outbound|80||testabc-hhmjj-1.default.svc.cluster.local",
"service_name": "outbound|80||testabc-hhmjj-1.default.svc.cluster.local"
"sni": "outbound_.80_._.testabc-hhmjj-1.default.svc.cluster.local"
"name": "outbound|9090||testabc-hhmjj-1-private.default.svc.cluster.local",
"service_name": "outbound|9090||testabc-hhmjj-1-private.default.svc.cluster.local"
"sni": "outbound_.9090_._.testabc-hhmjj-1-private.default.svc.cluster.local"
"name": "outbound|9091||testabc-hhmjj-1-private.default.svc.cluster.local",
"service_name": "outbound|9091||testabc-hhmjj-1-private.default.svc.cluster.local"
"sni": "outbound_.9091_._.testabc-hhmjj-1-private.default.svc.cluster.local"
Thank you for the detail. The first problem I spotted is in this VS. gateways may not contain a slash. The validation for / as a gateway: field fails. Are you certain this slash is present in the VS created by knative?
Cheers,
-steve
Below is a typical virtual service created by knative.
apiVersion: networking.istio.io/v1beta1 kind: VirtualService metadata: annotations: networking.knative.dev/ingress.class: istio.ingress.networking.knative.dev creationTimestamp: "2020-07-20T08:23:54Z" generation: 1 labels: networking.internal.knative.dev/ingress: hello29 serving.knative.dev/route: hello29 serving.knative.dev/routeNamespace: default name: hello29-ingress namespace: default ownerReferences: - apiVersion: networking.internal.knative.dev/v1alpha1 blockOwnerDeletion: true controller: true kind: Ingress name: hello29 uid: 433c415d-901e-4154-bfd9-43178d0db192 resourceVersion: "47989694" selfLink: /apis/networking.istio.io/v1beta1/namespaces/default/virtualservices/hello29-ingress uid: 20162863-b721-4d67-aa19-b84adc7dffe0 spec: gateways: - knative-serving/cluster-local-gateway - knative-serving/knative-ingress-gateway hosts: - hello29.default - hello29.default.dev-serving.codeengine.dev.appdomain.cloud - hello29.default.svc - hello29.default.svc.cluster.local http: - headers: request: set: K-Network-Hash: 12a72f65db15ba3a00ad16b328c40b5398a86cc84ba3239ad37f4d5ef811b0fa match: - authority: prefix: hello29.default gateways: - knative-serving/cluster-local-gateway retries: {} route: - destination: host: hello29-cpwpf-1.default.svc.cluster.local port: number: 80 headers: request: set: Knative-Serving-Namespace: default Knative-Serving-Revision: hello29-cpwpf-1 weight: 100 timeout: 600s - headers: request: set: K-Network-Hash: 12a72f65db15ba3a00ad16b328c40b5398a86cc84ba3239ad37f4d5ef811b0fa match: - authority: prefix: hello29.default.dev-serving.codeengine.dev.appdomain.cloud gateways: - knative-serving/knative-ingress-gateway retries: {} route: - destination: host: hello29-cpwpf-1.default.svc.cluster.local port: number: 80 headers: request: set: Knative-Serving-Namespace: default Knative-Serving-Revision: hello29-cpwpf-1 weight: 100 timeout: 600s ---
sdake
on 3 Aug 2020
Feels environmental. My system is very fast - 8000 virtual services representing the 1000 services (and their endpoints) are created more quickly then I can run the debug commands.
Please check my performance testing repo and see if you can reproduce in your environment. You will need istioctl-1.7.0a2. You need this version because the route command was added to proxy-config is istioctl in 1.7 and doesn't do much useful work in 1.6.
istio.yaml was created using istioctl-1..6.5 and the IOP you provided above.
Here are my results on a single node virtual machine with 128gb of ram and 8 core of xeon CPU:
sdake@sdake-dev:~/knative-perf$ kubectl create ns istio-system
sdake@sdake-dev:~/knative-perf$ kubectl apply -f istio.yaml
sdake@sdake-dev:~/knative-perf$ kubectl apply -f vs.yaml
sdake@sdake-dev:~/knative-perf$ ./istioctl proxy-config route istio-ingressgateway-6f9df9b8-6fwdc -n istio-system | wc -l
8004
sdake@sdake-dev:~/knative-perf$ ./istioctl proxy-config endpoints istio-ingressgateway-6f9df9b8-6fwdc -n istio-system | wc -l
2087
The last two commands run the curl command above - sort of - to determine the endpoints and virtual service routes. Please note I noticed one of the ingress is not used. Also, please double-check my methodology represents what is happening in knative.
Cheers,
-steve
sdake
on 3 Aug 2020
I tried this on IKS. IKS performance is not as good as my dedicated gear. I did notice the ALB was in a broken state:

sdake
on 4 Aug 2020
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 30m default-scheduler Successfully assigned istio-system/istio-ingressgateway-6f9df9b8-bwn4p to 10.221.80.115
Normal Pulling 30m kubelet, 10.221.80.115 Pulling image "docker.io/istio/proxyv2:1.6.5"
Normal Pulled 30m kubelet, 10.221.80.115 Successfully pulled image "docker.io/istio/proxyv2:1.6.5"
Normal Created 30m kubelet, 10.221.80.115 Created container istio-proxy
Normal Started 30m kubelet, 10.221.80.115 Started container istio-proxy
Warning Unhealthy 20m (x172 over 27m) kubelet, 10.221.80.115 Readiness probe failed: Get http://172.30.33.68:15021/healthz/ready: net/http: request canceled (Client.Timeout exceeded while awaiting headers)
I have tested istioctl-1.7.0a2 release and got a different result than we met before.
After 800 knative services (which will create 800 vs accordingly) are created, when I try to create new knative services, the ready time keeps about 10~20 seconds. Which is much lower than we tested on 1.6.5 and piror releases.
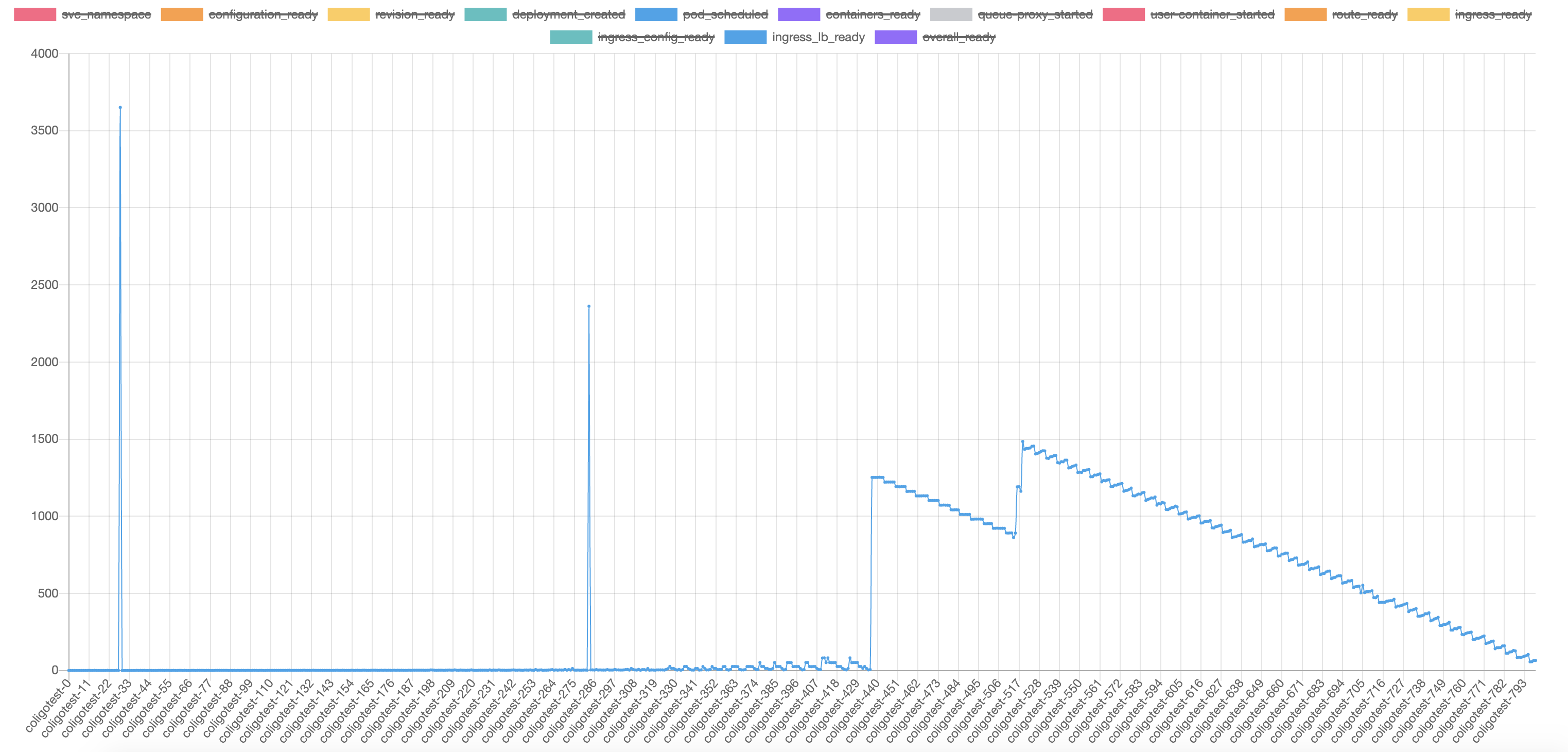
From the graph we can tell that despite of the peaks, the ready time can back to a resonable value than before.
Also I noticed that from the probing logs the failed probing almost fails with a 503 error response. I tried to curl manually and got a response like below.
curl http://coligotest-676.coligotest-6.serving-perf-temporary-cd5bb76c946a0f930dd9607ba0ddd3a1-0001.au-syd.containers.appdomain.cloud -v
* Uses proxy env variable http_proxy == 'http://127.0.0.1:8001'
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to 127.0.0.1 (127.0.0.1) port 8001 (#0)
> GET http://coligotest-676.coligotest-6.serving-perf-temporary-cd5bb76c946a0f930dd9607ba0ddd3a1-0001.au-syd.containers.appdomain.cloud/ HTTP/1.1
> Host: coligotest-676.coligotest-6.serving-perf-temporary-cd5bb76c946a0f930dd9607ba0ddd3a1-0001.au-syd.containers.appdomain.cloud
> User-Agent: curl/7.64.1
> Accept: */*
> Proxy-Connection: Keep-Alive
>
< HTTP/1.1 503 Service Unavailable
< Content-Length: 19
< Connection: keep-alive
< Content-Type: text/plain
< Date: Tue, 04 Aug 2020 09:01:10 GMT
< Keep-Alive: timeout=4
< Proxy-Connection: keep-alive
< Server: istio-envoy
<
* Connection #0 to host 127.0.0.1 left intact
no healthy upstream* Closing connection 0
If I retry the curl command and some of them could return with 200 success. Seems that some of the gateway is ready but others are not. Knative need all pods of gateways to be ready to serve the domain and then it will mark service as ready. Currently we have 3 replicas of public gateways of istio.
lanceliuu
on 4 Aug 2020
Per offline discussion with @sdake, we're not using IKS ALB mentioned above. So no traffic will go through IKS ingress but will go to Istio ingress gateway.
And during Knative service creation, the ingress_lb_ready duration basically means Knative have applied a Istio Virtual Service but will send a http request as below to make sure the Istio config works.
curl -k -v -H "Host: knative-service.domain.com" -H "User-Agent: Knative-Ingress-Probe" "K-Network-Probe: probe" http://172.30.49.209:80
# 172.30.49.209 is the istio ingressgeteway IP
 zhanggbj
on 4 Aug 2020
zhanggbj
on 4 Aug 2020
As I understand, NLB uses keepalived on IKS. As a result, there are still processes running to keep the packets moving in a keepalived scenario within the cluster.
My theory is that when you run your 1k processes, it overloads the cluster. You start to see this overload at about 330 processes, and then it really increases up later at 340 processes.
Kubernetes is designed to run 30 pods per node. At maximum - with configuration, Kubernetes on a very fast machine such as bare metal can run 100 pods per node maximum. If you have 10-15 nodes, you will see the above results, because you have overloaded the K8s platform and the scheduler will begin to struggle. It would be interesting to take a look at dmesg output during this ramp up to see if processes are killed as a result of OOM, or other kernel failures are occuring.
Cheers,
-steve
sdake
on 4 Aug 2020
We are testing using a cluster with 12 worker nodes of the following configurations
Capacity:
cpu: 16
ephemeral-storage: 102821812Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 32913324Ki
pods: 160
Allocatable:
cpu: 15880m
ephemeral-storage: 100025058636
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 29117356Ki
pods: 160
So I think it should be to able to test 800 knative services (also 800 pods if we set minscale =1). The test application is just a basic hello world go example. I noticed that even we set minscale = 0, which means that the deployment will scale to zero pods when it is ready and no traffic goes through, we can get a similar result.
It is interesting that envoy givess a 503 errors with response no healthy upstream. When we are testing 1.6.5 or piror releases the error should always be 404.
I also try to dump the dmesg for the node hosting ingress gateway pods and found the following error on one node. I have no clue whether it is critical or not. But I cannot find any OOM errors.
[83473.038700] wrk:worker_1[194281]: segfault at 20 ip 000056211e436207 sp 00007effcd7b70b0 error 4 in envoy[56211cdd9000+232a000]
[83475.185571] wrk:worker_7[194453]: segfault at 21 ip 000055fdbb3e2207 sp 00007ff7e32ed0b0 error 4 in envoy[55fdb9d85000+232a000]
[83492.175520] wrk:worker_3[194705]: segfault at 20 ip 000055733073f207 sp 00007f8bfd3e70b0 error 4 in envoy[55732f0e2000+232a000]
[83518.877194] wrk:worker_7[195086]: segfault at 20 ip 000055a729bcd207 sp 00007fce2e67e0b0 error 4 in envoy[55a728570000+232a000]
[83577.918847] wrk:worker_0[195759]: segfault at 30 ip 00005582aec16207 sp 00007f12bd7c20b0 error 4 in envoy[5582ad5b9000+232a000]
[83663.561086] wrk:worker_4[196638]: segfault at 21 ip 0000561e2efe1207 sp 00007f897422d0b0 error 4 in envoy[561e2d984000+232a000]
[83835.123111] wrk:worker_3[198375]: segfault at 30 ip 000055935dcbb207 sp 00007fd87e7b50b0 error 4 in envoy[55935c65e000+232a000]
[84138.453503] wrk:worker_0[201249]: segfault at 21 ip 00005576d5ada207 sp 00007f45668820b0 error 4 in envoy[5576d447d000+232a000]
[84442.424616] wrk:worker_5[204183]: segfault at 20 ip 000056050f968207 sp 00007ff9ab7b10b0 error 4 in envoy[56050e30b000+232a000]
@sdake FYI, here is the benchmark tool we're using which will help to generate the Knative Service with different intervals as @lanceliuu mentioned above and can get the ingress_lb_ready duration time and dashboard.
https://github.com/zhanggbj/kperf
zhanggbj
on 5 Aug 2020
@sdake
From the recent tests we find that the increasing of ready time for knative services is not caused by the delay for pilot pushing configs to envoy. After enable debug logs of enovy we find that the probes for knative fails with the following error:
2020-08-07T03:59:33.442763Z debug envoy http [C66564] new stream
2020-08-07T03:59:33.442841Z debug envoy http [C66564][S14276412531493771392] request headers complete (end_stream=true):
':authority', 'coligotdestg-50.coligotest-19.serving-perf-temporary-cd5bb76c946a0f930dd9607ba0ddd3a1-0001.au-syd.containers.appdomain.cloud:80'
':path', '/healthz'
':method', 'GET'
'user-agent', 'Knative-Ingress-Probe'
'k-network-probe', 'probe'
'accept-encoding', 'gzip'
2020-08-07T03:59:33.442855Z debug envoy http [C66564][S14276412531493771392] request end stream
2020-08-07T03:59:33.443011Z debug envoy router [C66564][S14276412531493771392] cluster 'outbound|80||coligotdestg-50-w4hcq.coligotest-19.svc.cluster.local' match for URL '/healthz'
2020-08-07T03:59:33.443043Z debug envoy upstream no healthy host for HTTP connection pool
2020-08-07T03:59:33.443100Z debug envoy http [C66564][S14276412531493771392] Sending local reply with details no_healthy_upstream
2020-08-07T03:59:33.443139Z debug envoy http [C66564][S14276412531493771392] encoding headers via codec (end_stream=false):
':status', '503'
'content-length', '19'
'content-type', 'text/plain'
'date', 'Fri, 07 Aug 2020 03:59:33 GMT'
'server', 'istio-envoy'
Seems that the host in virtualservice is recongized and the upstream cluster config is also configured correctly. But envoy treat it as unhealthy. I can confirm the dns for upstream host is able to resolve in ingress-gateway-pods when the error occurred. And no healthy checkers is specified in the upstream cluster config. The document of envoy said that
If no configuration is specified no health checking will be done and all cluster members will be considered healthy at all times.
I wonder why envoy reports it as unhealthy and takes several minutes to recover.
lanceliuu
on 7 Aug 2020
Can you check out https://karlstoney.com/2019/05/31/istio-503s-ucs-and-tcp-fun-times/index.html and to see if there is more you can find from these 503s?
also, you can turn on access logs https://istio.io/docs/tasks/telemetry/logs/access-log/ and there is a "Response Flag" field that will give more details about the 503 (like DC, UC, etc).
linsun
on 7 Aug 2020
I found more details for the 503 errors returned by ingress-gateway.
During my tests I noticed that a knative service does not get ready for minutes. I checked the logs and find the similar output no healthy host for HTTP connection pool.
I checked the endpoint config for the gateway and found the following output.
~/.istioctl/bin/istioctl proxy-config endpoint istio-ingressgateway-77447996c4-pg8k8.istio-system |grep coligotest1-766
172.30.113.110:8012 HEALTHY OK outbound_.80_._.coligotest1-766-mf766-private.coligotest-15.svc.cluster.local
172.30.113.110:8012 HEALTHY OK outbound|80||coligotest1-766-mf766-private.coligotest-15.svc.cluster.local
172.30.113.110:8022 HEALTHY OK outbound_.8022_._.coligotest1-766-mf766-private.coligotest-15.svc.cluster.local
172.30.113.110:8022 HEALTHY OK outbound|8022||coligotest1-766-mf766-private.coligotest-15.svc.cluster.local
172.30.113.110:9090 HEALTHY OK outbound_.9090_._.coligotest1-766-mf766-private.coligotest-15.svc.cluster.local
172.30.113.110:9090 HEALTHY OK outbound|9090||coligotest1-766-mf766-private.coligotest-15.svc.cluster.local
172.30.113.110:9091 HEALTHY OK outbound_.9091_._.coligotest1-766-mf766-private.coligotest-15.svc.cluster.local
172.30.113.110:9091 HEALTHY OK outbound|9091||coligotest1-766-mf766-private.coligotest-15.svc.cluster.local
Notice that only the private service is present but the but the cluster configuration need endpoint outbound|80||coligotest1-766-mf766.coligotest-15.svc.cluster.local which is absent from the endpoint list.
I also checked the kubernetes svc and found that both two svc are present and have the similar creation timestamp.
For a typical knative service It will create two coressponding sets of kubernetes endpoints like following:
hello-gshwx-1 172.30.113.77:8012,172.30.217.120:8012,172.30.252.131:8012 28h
hello-gshwx-1-private <none> 28h
Only the one without -private suffix is required for the virtualservice configuration.
When I saw the ksvc stuck for minutes, I tried to restart istiod pods and found that the missing endpoints is configured back immediately. Then the knative service got ready in the next probe.
~/.istioctl/bin/istioctl proxy-config endpoint istio-ingressgateway-77447996c4-hmz7p.istio-system |grep coligotest1-766
172.30.113.110:8012 HEALTHY OK outbound_.80_._.coligotest1-766-mf766-private.coligotest-15.svc.cluster.local
172.30.113.110:8012 HEALTHY OK outbound|80||coligotest1-766-mf766-private.coligotest-15.svc.cluster.local
172.30.113.110:8022 HEALTHY OK outbound_.8022_._.coligotest1-766-mf766-private.coligotest-15.svc.cluster.local
172.30.113.110:8022 HEALTHY OK outbound|8022||coligotest1-766-mf766-private.coligotest-15.svc.cluster.local
172.30.113.110:9090 HEALTHY OK outbound_.9090_._.coligotest1-766-mf766-private.coligotest-15.svc.cluster.local
172.30.113.110:9090 HEALTHY OK outbound|9090||coligotest1-766-mf766-private.coligotest-15.svc.cluster.local
172.30.113.110:9091 HEALTHY OK outbound_.9091_._.coligotest1-766-mf766-private.coligotest-15.svc.cluster.local
172.30.113.110:9091 HEALTHY OK outbound|9091||coligotest1-766-mf766-private.coligotest-15.svc.cluster.local
172.30.113.77:8012 HEALTHY OK outbound_.80_._.coligotest1-766-mf766.coligotest-15.svc.cluster.local
172.30.113.77:8012 HEALTHY OK outbound|80||coligotest1-766-mf766.coligotest-15.svc.cluster.local
172.30.217.120:8012 HEALTHY OK outbound_.80_._.coligotest1-766-mf766.coligotest-15.svc.cluster.local
172.30.217.120:8012 HEALTHY OK outbound|80||coligotest1-766-mf766.coligotest-15.svc.cluster.local
172.30.252.131:8012 HEALTHY OK outbound_.80_._.coligotest1-766-mf766.coligotest-15.svc.cluster.local
172.30.252.131:8012 HEALTHY OK outbound|80||coligotest1-766-mf766.coligotest-15.svc.cluster.local
I wonder there might be issues for EDS to push endpoint to envoy when the endpoint is created initially and may need additonal full push to get synced? I think this causes the high peaks we met during the tests. We did not see such frequent high peaks prior to 1.6 releases. The 1.5.4 have stepped increasing overall ready time but the result is at least "stable".
lanceliuu
on 12 Aug 2020
Another result for missing endpoints
Kubernetes endpoint is existing for 28 minutes
kubectl -n coligotest-14 get ep |grep coligotest2-125
coligotest2-125-fpl9d 172.30.113.77:8012,172.30.217.120:8012,172.30.252.131:8012 28m
coligotest2-125-fpl9d-private 172.30.246.59:8022,172.30.246.59:8012,172.30.246.59:9090 + 1 more... 28m
Ingress gateway pod istio-ingressgateway-84ddc4b654-2m5jt is still missing the correct endpoint configuration
~/Dev/coligo ❯ ~/.istioctl/bin/istioctl proxy-config endpoint istio-ingressgateway-84ddc4b654-pcj67.istio-system |grep coligotest2-125
172.30.113.77:8012 HEALTHY OK outbound_.80_._.coligotest2-125-fpl9d.coligotest-14.svc.cluster.local
172.30.113.77:8012 HEALTHY OK outbound|80||coligotest2-125-fpl9d.coligotest-14.svc.cluster.local
172.30.217.120:8012 HEALTHY OK outbound_.80_._.coligotest2-125-fpl9d.coligotest-14.svc.cluster.local
172.30.217.120:8012 HEALTHY OK outbound|80||coligotest2-125-fpl9d.coligotest-14.svc.cluster.local
172.30.246.59:8012 HEALTHY OK outbound_.80_._.coligotest2-125-fpl9d-private.coligotest-14.svc.cluster.local
172.30.246.59:8012 HEALTHY OK outbound|80||coligotest2-125-fpl9d-private.coligotest-14.svc.cluster.local
172.30.246.59:8022 HEALTHY OK outbound_.8022_._.coligotest2-125-fpl9d-private.coligotest-14.svc.cluster.local
172.30.246.59:8022 HEALTHY OK outbound|8022||coligotest2-125-fpl9d-private.coligotest-14.svc.cluster.local
172.30.246.59:9090 HEALTHY OK outbound_.9090_._.coligotest2-125-fpl9d-private.coligotest-14.svc.cluster.local
172.30.246.59:9090 HEALTHY OK outbound|9090||coligotest2-125-fpl9d-private.coligotest-14.svc.cluster.local
172.30.246.59:9091 HEALTHY OK outbound_.9091_._.coligotest2-125-fpl9d-private.coligotest-14.svc.cluster.local
172.30.246.59:9091 HEALTHY OK outbound|9091||coligotest2-125-fpl9d-private.coligotest-14.svc.cluster.local
172.30.252.131:8012 HEALTHY OK outbound_.80_._.coligotest2-125-fpl9d.coligotest-14.svc.cluster.local
172.30.252.131:8012 HEALTHY OK outbound|80||coligotest2-125-fpl9d.coligotest-14.svc.cluster.local
~/Dev/coligo ❯ ~/.istioctl/bin/istioctl proxy-config endpoint istio-ingressgateway-84ddc4b654-8zhbp.istio-system |grep coligotest2-125
172.30.113.77:8012 HEALTHY OK outbound_.80_._.coligotest2-125-fpl9d.coligotest-14.svc.cluster.local
172.30.113.77:8012 HEALTHY OK outbound|80||coligotest2-125-fpl9d.coligotest-14.svc.cluster.local
172.30.217.120:8012 HEALTHY OK outbound_.80_._.coligotest2-125-fpl9d.coligotest-14.svc.cluster.local
172.30.217.120:8012 HEALTHY OK outbound|80||coligotest2-125-fpl9d.coligotest-14.svc.cluster.local
172.30.246.59:8012 HEALTHY OK outbound_.80_._.coligotest2-125-fpl9d-private.coligotest-14.svc.cluster.local
172.30.246.59:8012 HEALTHY OK outbound|80||coligotest2-125-fpl9d-private.coligotest-14.svc.cluster.local
172.30.246.59:8022 HEALTHY OK outbound_.8022_._.coligotest2-125-fpl9d-private.coligotest-14.svc.cluster.local
172.30.246.59:8022 HEALTHY OK outbound|8022||coligotest2-125-fpl9d-private.coligotest-14.svc.cluster.local
172.30.246.59:9090 HEALTHY OK outbound_.9090_._.coligotest2-125-fpl9d-private.coligotest-14.svc.cluster.local
172.30.246.59:9090 HEALTHY OK outbound|9090||coligotest2-125-fpl9d-private.coligotest-14.svc.cluster.local
172.30.246.59:9091 HEALTHY OK outbound_.9091_._.coligotest2-125-fpl9d-private.coligotest-14.svc.cluster.local
172.30.246.59:9091 HEALTHY OK outbound|9091||coligotest2-125-fpl9d-private.coligotest-14.svc.cluster.local
172.30.252.131:8012 HEALTHY OK outbound_.80_._.coligotest2-125-fpl9d.coligotest-14.svc.cluster.local
172.30.252.131:8012 HEALTHY OK outbound|80||coligotest2-125-fpl9d.coligotest-14.svc.cluster.local
~/Dev/coligo ❯ ~/.istioctl/bin/istioctl proxy-config endpoint istio-ingressgateway-84ddc4b654-2m5jt.istio-system |grep coligotest2-125
172.30.246.59:8012 HEALTHY OK outbound_.80_._.coligotest2-125-fpl9d-private.coligotest-14.svc.cluster.local
172.30.246.59:8012 HEALTHY OK outbound|80||coligotest2-125-fpl9d-private.coligotest-14.svc.cluster.local
172.30.246.59:8022 HEALTHY OK outbound_.8022_._.coligotest2-125-fpl9d-private.coligotest-14.svc.cluster.local
172.30.246.59:8022 HEALTHY OK outbound|8022||coligotest2-125-fpl9d-private.coligotest-14.svc.cluster.local
172.30.246.59:9090 HEALTHY OK outbound_.9090_._.coligotest2-125-fpl9d-private.coligotest-14.svc.cluster.local
172.30.246.59:9090 HEALTHY OK outbound|9090||coligotest2-125-fpl9d-private.coligotest-14.svc.cluster.local
172.30.246.59:9091 HEALTHY OK outbound_.9091_._.coligotest2-125-fpl9d-private.coligotest-14.svc.cluster.local
172.30.246.59:9091 HEALTHY OK outbound|9091||coligotest2-125-fpl9d-private.coligotest-14.svc.cluster.local
error logs in ingress gateway pods
2020-08-12T10:15:19.847374Z debug envoy http [C15790] new stream
2020-08-12T10:15:19.847472Z debug envoy http [C15790][S3220026141768338699] request headers complete (end_stream=true):
':authority', 'coligotest2-125.coligotest-14.example.com:80'
':path', '/healthz'
':method', 'GET'
'user-agent', 'Knative-Ingress-Probe'
'k-network-probe', 'probe'
'accept-encoding', 'gzip'
2020-08-12T10:15:19.847479Z debug envoy http [C15790][S3220026141768338699] request end stream
2020-08-12T10:15:19.847615Z debug envoy router [C15790][S3220026141768338699] cluster 'outbound|80||coligotest2-125-fpl9d.coligotest-14.svc.cluster.local' match for URL '/healthz'
2020-08-12T10:15:19.847642Z debug envoy upstream no healthy host for HTTP connection pool
2020-08-12T10:15:19.847670Z debug envoy http [C15790][S3220026141768338699] Sending local reply with details no_healthy_upstream
2020-08-12T10:15:19.847703Z debug envoy http [C15790][S3220026141768338699] encoding headers via codec (end_stream=false):
':status', '503'
'content-length', '19'
'content-type', 'text/plain'
'date', 'Wed, 12 Aug 2020 10:15:19 GMT'
'server', 'istio-envoy'
failed probing in knative
{"level":"error","ts":"2020-08-12T10:15:19.848Z","logger":"istiocontroller.istio-ingress-controller.status-manager","caller":"status/status.go:396","msg":"Probing of http://coligotest2-125.coligotest-14.example.com:80 failed, IP: 172.30.246.32:8080, ready: false, error: unexpected status code: want 200, got 503 (depth: 0)","commit":"2edfadf","knative.dev/controller":"istio-ingress-controller","knative.dev/key":"coligotest-14/coligotest2-125","stacktrace":"knative.dev/serving/pkg/network/status.(*Prober).processWorkItem\n\tknative.dev/[email protected]/pkg/network/status/status.go:396\nknative.dev/serving/pkg/network/status.(*Prober).Start.func1\n\tknative.dev/[email protected]/pkg/network/status/status.go:288"}
reported to secvuln team.
sdake
on 12 Aug 2020
Also, do you have istiod 3 replicas at the beginning of the test? Is istiod configured with CPU limit disabled (or have sufficient CPU)? It is known istiod CPU throttling may lead to slow config update.
Also do you have any pilot_xds_eds_reject in your log?
@howardjohn any thoughts? The team indicated some endpoints are missing on 1 of the 3 gws and recovered automatically after ~30 mins or restart istiod.
linsun
on 12 Aug 2020
Look at pilot_proxy_queue_time, pilot_push_triggers, pilot_proxy_convergence_time. All are on the grafana dashboard. 1.6.7 fixed a critical bug around endpoints getting stuck, may try that
 howardjohn
on 12 Aug 2020
howardjohn
on 12 Aug 2020
Thanks @howardjohn ! @lanceliuu can you pls you rerun with 1.7-beta2 or latest 1.6.7+ and collect these metrics? Would be good to ensure ingress gw has 3 replicas and istiod has 3 replicas throughout your test and istiod has sufficient CPU (or no limit).
linsun
on 12 Aug 2020
1.7 beta 3 has the critical bug fix john mentioned and should be available today.
Cheers,
-steve
sdake
on 12 Aug 2020
Yeah and also the CPU/memory stats, and even CPU profile of istiod are helpful: https://github.com/istio/istio/wiki/Analyzing-Istio-Performance. Really just the whole grafana dashboard for pilot if possible...
howardjohn
on 12 Aug 2020
@linsun We did not set limit CPU for istiod. Also we set istiod and both public gateway and private gateway replicas to fixed value of 3.
I have tried 1.6.8 and 1.7.0-rc.1 released today with no luck. This time I recorded some dashboard during the tests.
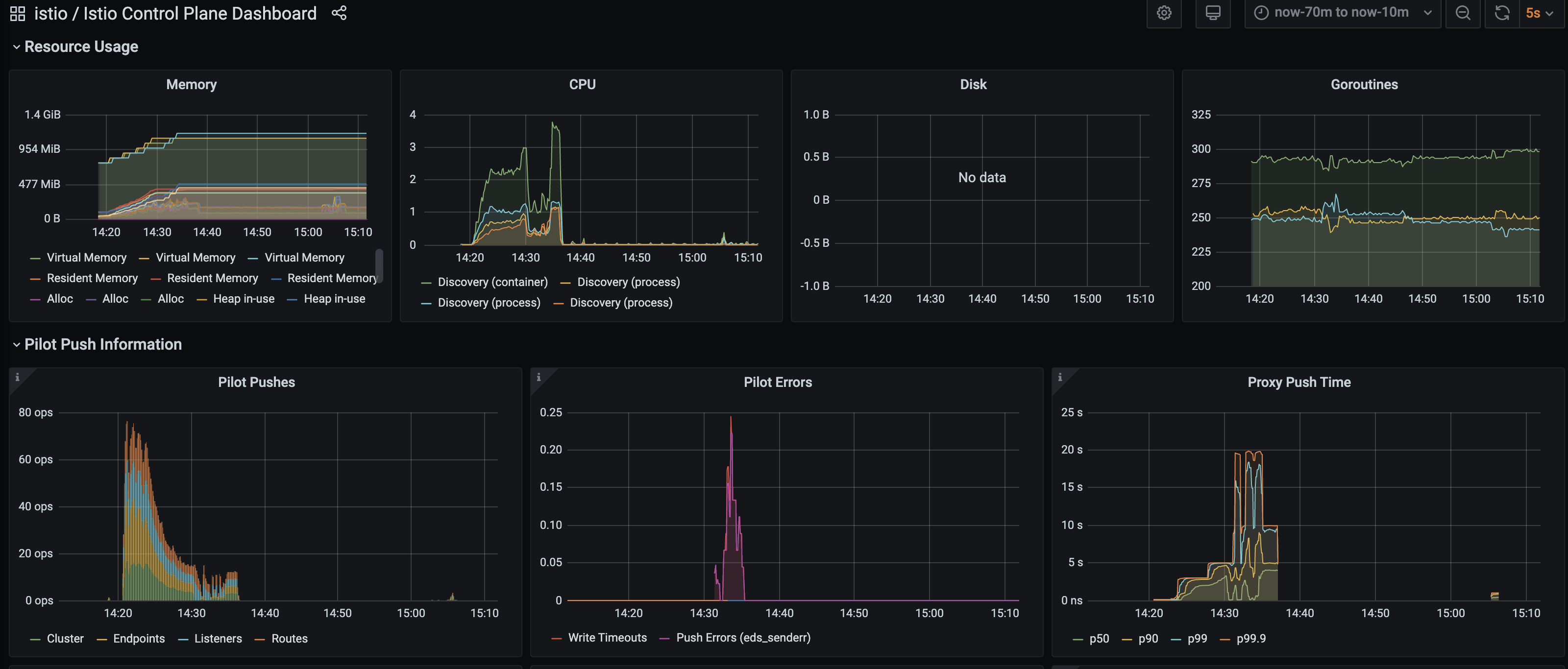
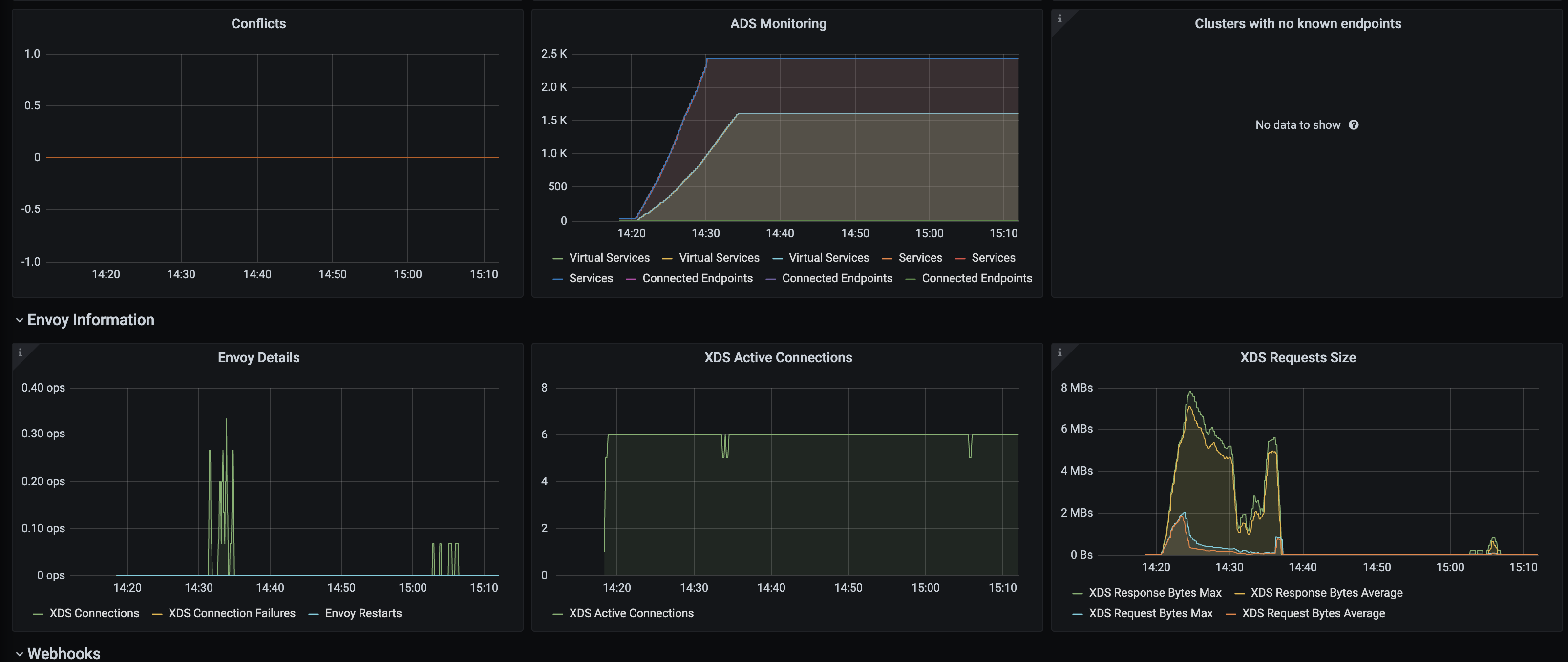
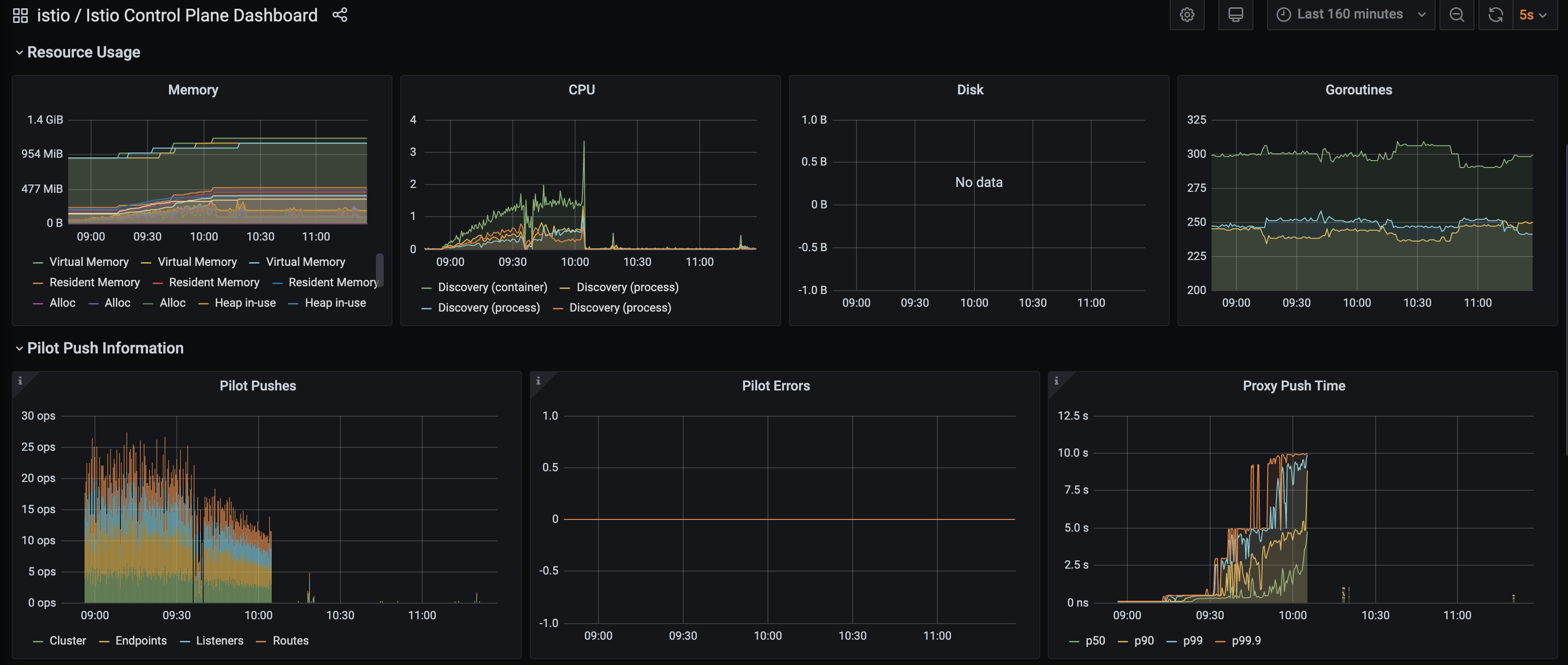
Seems that there did exist some errors for eds_sender. And some small pushes at ~15:05. I believe after the additional push the gateway got configured correctly. I will try to collect the detailed error logs.
lanceliuu
on 13 Aug 2020
Do you have a real use case for creating 2.5k virtual services in 10 minutes? Or just load testing?
howardjohn
on 13 Aug 2020
The use case involves a multitenant knative served from one K8s / Istio control plane. I am not sure specifically on the number of transactions, but the use case is legitimate and I presume the team doing this analysis is looking for the upper scale ends of istio.
As you know, Kubernetes API server has an upper limit on the rate of transactions it can support. I sort of feel like this is a K8s API limitation, and not necessarily an Istio limitation, although during this scale testing pushes fail, and that feels like an Istio problem.
Cheers,
-steve
sdake
on 13 Aug 2020
The reason I ask is the absolutely worst scaling scenario for Istio is what
you are doing - applying a huge amount of config in a short period of time.
Because if you apply 2.5k resources, we first apply 1, then 2, then 3,
...., 2.5k * number of proxies - ends up being 3 million configs sent per
proxy in 10 minutes
On Thu, Aug 13, 2020 at 10:13 AM Steven Dake notifications@github.com
wrote:
The use case involves a multitenant knative served from one K8s / Istio
control plane. I am not sure specifically on the number of transactions,
but the use case is legitimate and I presume the team doing this analysis
is looking for the upper scale ends of istio.As you know, Kubernetes API server has an upper limit on the rate of
transactions it can support. I sort of feel like this is a K8s API
limitation, and not necessarily an Istio limitation, although during this
scale testing pushes fail, and that feels like an Istio problem.Cheers,
-steve—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/istio/istio/issues/25685#issuecomment-673600310, or
unsubscribe
https://github.com/notifications/unsubscribe-auth/AAEYGXKYW5QD5W7PPB7GRALSAQNL3ANCNFSM4PDGLZ3Q
.
howardjohn
on 13 Aug 2020
I thought there was a backoff method in the push code to consolidate requests under high load? Perhaps that was removed.
Cheers,
-steve
sdake
on 13 Aug 2020
There is not exactly backoff (at least not what I consider backoff), but debouncing, in that changes within 100ms together are grouped. However 100ms is very small window so often they are not grouped. We have/are looking into some form of expontential backoff debounce, such that the first change is grouped 100ms, then 200ms, etc. So as many changes come in they become grouped more aggressively. But not yet implemented. PILOT_DEBOUNCE_AFTER=100ms and PILOT_DEBOUNCE_MAX=10s are the current env vars on pilot that can be tweak - the first is the time to wait for grouping, and the latter is max time to wait (ie if I change a config every 10ms, after 10s we will finally let the group go)
howardjohn
on 13 Aug 2020
@howardjohn right thats what i was thinking of - denounce. I'll work with the team to tune the denounce, and if we can find some improvement, perhaps I can assist in an exponential denounce - unless someone is already working on this. I remember this whole section of push code, and its unsuitability early on right when you joined the project 👍
Cheers,
-steve
sdake
on 13 Aug 2020
Relevant PR: https://github.com/istio/istio/pull/24230 that we closed for
now due to lack of time to test it
On Thu, Aug 13, 2020 at 2:43 PM Steven Dake notifications@github.com
wrote:
@howardjohn https://github.com/howardjohn right thats what i was
thinking of - denounce. I'll work with the team to tune the denounce, and
if we can find some improvement, perhaps I can assist in an exponential
denounce - unless someone is already working on this. I remember this whole
section of push code, and its unsuitability early on right when you joined
the project 👍Cheers,
-steve—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/istio/istio/issues/25685#issuecomment-673725373, or
unsubscribe
https://github.com/notifications/unsubscribe-auth/AAEYGXI2PGI3GYGRKEGDPYLSARNBLANCNFSM4PDGLZ3Q
.
howardjohn
on 13 Aug 2020
About the number relationship of Knative services:virtual service:K8s service, for 800 knative service, we only have 1.6k virtual service, FYI.
1 Knative service will create 2 virtualservice as below (we only use blue-ingress as we only use knative-serving/cluster-local-gateway knative-serving/knative-ingress-gateway)and 3 K8s services
k get vs -n e8e8f528-4b9a
NAME GATEWAYS HOSTS
bluex-ingress [knative-serving/cluster-local-gateway knative-serving/knative-ingress-gateway] [bluex.e8e8f528-4b9a bluex.e8e8f528-4b9a.dev-serving.codeengine.dev.appdomain.cloud bluex.e8e8f528-4b9a.svc bluex.e8e8f528-4b9a.svc.cluster.local] 17h
bluex-mesh [mesh] [bluex.e8e8f528-4b9a bluex.e8e8f528-4b9a.svc bluex.e8e8f528-4b9a.svc.cluster.local]
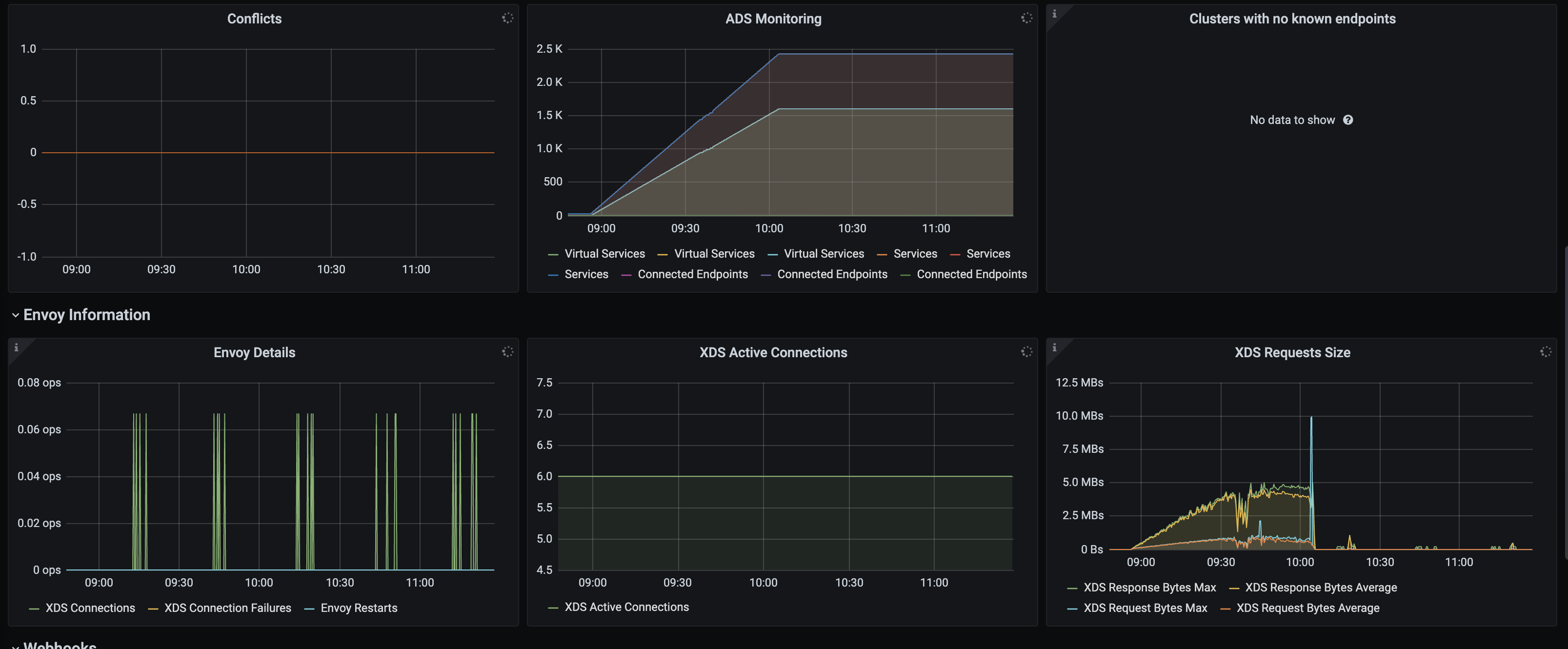
Here is another test which is our typical tests as I described at the beginning of this issue. We create 800 ksvc sequentially with 5s interval. Which takes roughly ~1hr for the whole 1600 virtual service to be created.
We found the similar result, but there are NO errors in dashboard the pilot errors. From the checking for of endpoints in envoy we can tell that the endpoint configs are missing in pod istio-ingressgateway-6d899bb698-5fvg6 and istio-ingressgateway-6d899bb698-qckqf for ksvc coligotest-9 which stuck for >20minutes. Notice that from the dashboard
Pilot Pushes there are small peaks at 10:15 and 11:15, which should get the missing endpoints configured correctly.
cluster-local-gateway-6d697dfd57-2l6wp:
172.30.137.186:8012 HEALTHY OK outbound_.80_._.coligotest1-239-tx42v.coligotest-9.svc.cluster.local
172.30.137.186:8012 HEALTHY OK outbound|80||coligotest1-239-tx42v.coligotest-9.svc.cluster.local
172.30.192.179:8012 HEALTHY OK outbound_.80_._.coligotest1-239-tx42v.coligotest-9.svc.cluster.local
172.30.192.179:8012 HEALTHY OK outbound|80||coligotest1-239-tx42v.coligotest-9.svc.cluster.local
172.30.246.51:8012 HEALTHY OK outbound_.80_._.coligotest1-239-tx42v.coligotest-9.svc.cluster.local
172.30.246.51:8012 HEALTHY OK outbound|80||coligotest1-239-tx42v.coligotest-9.svc.cluster.local
172.30.252.179:8012 HEALTHY OK outbound_.80_._.coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:8012 HEALTHY OK outbound|80||coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:8022 HEALTHY OK outbound_.8022_._.coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:8022 HEALTHY OK outbound|8022||coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:9090 HEALTHY OK outbound_.9090_._.coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:9090 HEALTHY OK outbound|9090||coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:9091 HEALTHY OK outbound_.9091_._.coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:9091 HEALTHY OK outbound|9091||coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
cluster-local-gateway-6d697dfd57-8hznw:
172.30.137.186:8012 HEALTHY OK outbound_.80_._.coligotest1-239-tx42v.coligotest-9.svc.cluster.local
172.30.137.186:8012 HEALTHY OK outbound|80||coligotest1-239-tx42v.coligotest-9.svc.cluster.local
172.30.192.179:8012 HEALTHY OK outbound_.80_._.coligotest1-239-tx42v.coligotest-9.svc.cluster.local
172.30.192.179:8012 HEALTHY OK outbound|80||coligotest1-239-tx42v.coligotest-9.svc.cluster.local
172.30.246.51:8012 HEALTHY OK outbound_.80_._.coligotest1-239-tx42v.coligotest-9.svc.cluster.local
172.30.246.51:8012 HEALTHY OK outbound|80||coligotest1-239-tx42v.coligotest-9.svc.cluster.local
172.30.252.179:8012 HEALTHY OK outbound_.80_._.coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:8012 HEALTHY OK outbound|80||coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:8022 HEALTHY OK outbound_.8022_._.coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:8022 HEALTHY OK outbound|8022||coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:9090 HEALTHY OK outbound_.9090_._.coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:9090 HEALTHY OK outbound|9090||coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:9091 HEALTHY OK outbound_.9091_._.coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:9091 HEALTHY OK outbound|9091||coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
cluster-local-gateway-6d697dfd57-kfx6g:
172.30.137.186:8012 HEALTHY OK outbound_.80_._.coligotest1-239-tx42v.coligotest-9.svc.cluster.local
172.30.137.186:8012 HEALTHY OK outbound|80||coligotest1-239-tx42v.coligotest-9.svc.cluster.local
172.30.192.179:8012 HEALTHY OK outbound_.80_._.coligotest1-239-tx42v.coligotest-9.svc.cluster.local
172.30.192.179:8012 HEALTHY OK outbound|80||coligotest1-239-tx42v.coligotest-9.svc.cluster.local
172.30.246.51:8012 HEALTHY OK outbound_.80_._.coligotest1-239-tx42v.coligotest-9.svc.cluster.local
172.30.246.51:8012 HEALTHY OK outbound|80||coligotest1-239-tx42v.coligotest-9.svc.cluster.local
172.30.252.179:8012 HEALTHY OK outbound_.80_._.coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:8012 HEALTHY OK outbound|80||coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:8022 HEALTHY OK outbound_.8022_._.coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:8022 HEALTHY OK outbound|8022||coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:9090 HEALTHY OK outbound_.9090_._.coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:9090 HEALTHY OK outbound|9090||coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:9091 HEALTHY OK outbound_.9091_._.coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:9091 HEALTHY OK outbound|9091||coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
istio-ingressgateway-6d899bb698-5fvg6:
172.30.252.179:8012 HEALTHY OK outbound_.80_._.coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:8012 HEALTHY OK outbound|80||coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:8022 HEALTHY OK outbound_.8022_._.coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:8022 HEALTHY OK outbound|8022||coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:9090 HEALTHY OK outbound_.9090_._.coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:9090 HEALTHY OK outbound|9090||coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:9091 HEALTHY OK outbound_.9091_._.coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:9091 HEALTHY OK outbound|9091||coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
istio-ingressgateway-6d899bb698-c48jm:
172.30.137.186:8012 HEALTHY OK outbound_.80_._.coligotest1-239-tx42v.coligotest-9.svc.cluster.local
172.30.137.186:8012 HEALTHY OK outbound|80||coligotest1-239-tx42v.coligotest-9.svc.cluster.local
172.30.192.179:8012 HEALTHY OK outbound_.80_._.coligotest1-239-tx42v.coligotest-9.svc.cluster.local
172.30.192.179:8012 HEALTHY OK outbound|80||coligotest1-239-tx42v.coligotest-9.svc.cluster.local
172.30.246.51:8012 HEALTHY OK outbound_.80_._.coligotest1-239-tx42v.coligotest-9.svc.cluster.local
172.30.246.51:8012 HEALTHY OK outbound|80||coligotest1-239-tx42v.coligotest-9.svc.cluster.local
172.30.252.179:8012 HEALTHY OK outbound_.80_._.coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:8012 HEALTHY OK outbound|80||coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:8022 HEALTHY OK outbound_.8022_._.coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:8022 HEALTHY OK outbound|8022||coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:9090 HEALTHY OK outbound_.9090_._.coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:9090 HEALTHY OK outbound|9090||coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:9091 HEALTHY OK outbound_.9091_._.coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:9091 HEALTHY OK outbound|9091||coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
istio-ingressgateway-6d899bb698-qckqf:
172.30.252.179:8012 HEALTHY OK outbound_.80_._.coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:8012 HEALTHY OK outbound|80||coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:8022 HEALTHY OK outbound_.8022_._.coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:8022 HEALTHY OK outbound|8022||coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:9090 HEALTHY OK outbound_.9090_._.coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:9090 HEALTHY OK outbound|9090||coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:9091 HEALTHY OK outbound_.9091_._.coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
172.30.252.179:9091 HEALTHY OK outbound|9091||coligotest1-239-tx42v-private.coligotest-9.svc.cluster.local
I think the missing of endpoint configs contributes the unexpected peak values in the following chart. We have not seen this in releases prior to release 1.6.
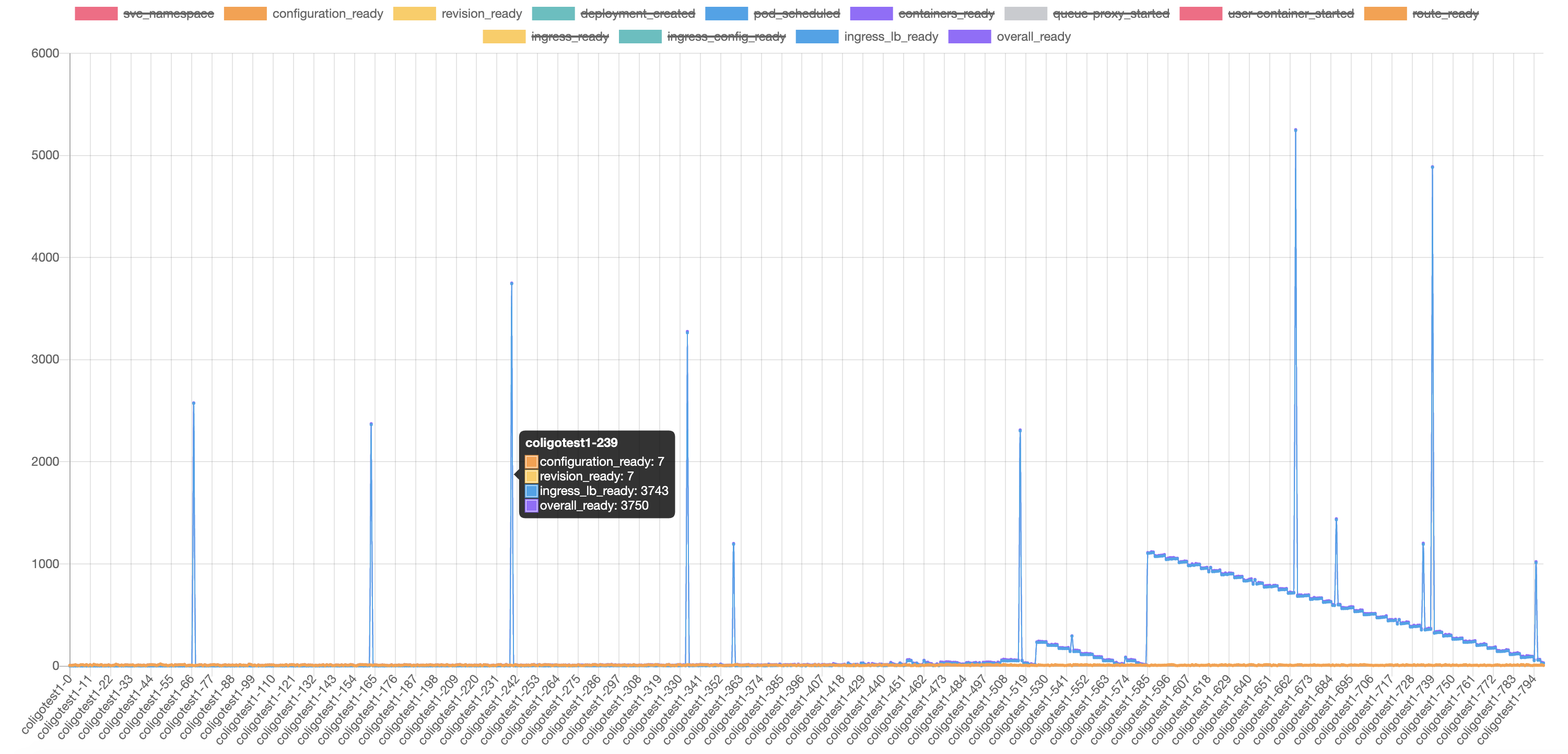
lanceliuu
on 14 Aug 2020
@howardjohn and @sdake Thank you for your response, could please explain more about debouncing ? The problem we found is istio EDS does not discover some kube services and config into envoy, which causes peak blue point in above diagram. Does debouncing relate with EDS to discover kube services ?
I think we should focus why istio EDS does not discover some kube services.
For your question about load, @zhanggbj and @lanceliuu already response you. Our target is creating 800 ksvc sequentially with 5s interval for each (1 knative serivce == 2 istio virtural services + 3 kube services). It takes 4000s for 1.6k istio virtual services and 2.4k kube services, these resource istiod need to discover and config into gateway. In this load, we see problem of istiod EDS does not discover some kube services. More load (e.g. 2.4 kube services in 10 mins), more easier to see the problem for debug purpose.
Do you think it is reasonable load for istio, 4000s for 1.6k istio virtual services and 2.4k kube services
Please see detail in above comment. Thank you.
ZhuangYuZY
on 14 Aug 2020
@ZhuangYuZY the total load is reasonable (istio can scale to millions or atleast that is the goal?) of endpoints. The issue you see is that you are pushing a lot of config all at once.
The denounce, which is configurable only by environment variable, permits the batching of EDS incremental pushes. When you add 1 service, then wait 5 seconds, then add another service, ech additional service will result in a re-push of the entire config. the denounce is meant to batch multiple changes into one blob so there is less network activity (at the cost of higher synchronization times).
If you are willing to run an experiment, I'd like to see what happens with the original load test where you spam 800 kvcs, but with a denounce time set to something a little more reasonable for that load. It would be great to do this for multiple denounce times so we can test one of the PRs we have to fix this particular use case.
I'd like to test a denounce of 200msec, 400msec, 800msec, 1600msec, 3200msec, 6400msec, 10000msec.
I know its a lot of testing, but by doing so, we can confirm that the exponential backoff we have for the denounce code would work.
Then you or I can test the actual patch. I am still working on reproducing your test case with knative.
@howardjohn did tell me he would be willing to add this to the scale testing every release (IIUC, please correct me if not John) - if we could produce a test case that is knative-free. IOW depends on no third party applications except possibly golang to run the test cases. I am working on such a test case here: https://github.com/sdake/knative-perf. There is no go code yet, I just want to see if I can create about 800 vs plus about 800 workloads every 1-2 seconds and see how Istio performs.
Cheers,
-steve
sdake
on 14 Aug 2020
I have produced a systemwide profile on one of 15 virtual machines running the knative 1..800 workflow with 5-second intervals.
The results are in an SVG format. Wider = more CPU utilization.
There is a SVG attached which is a a flame graph created with flame graph
MAKE SURE TO DOWNLOAD LOCALLY, tar -xzvf file.tar.gz - then open the svg in your web browser to take a look around at the worker node performance.
Cheers,
-steve
sdake
on 16 Aug 2020
Test with lastest release 1.7.0, seems that the same issue exists.
Istio version/configuration
Istio Deployment Images:
cluster-local-gateway:["istio-proxy","docker.io/istio/proxyv2:1.7.0"]
istio-ingressgateway:["istio-proxy","docker.io/istio/proxyv2:1.7.0"]
istiod:["discovery","docker.io/istio/pilot:1.7.0"]
Istio Deployment Resource Request/Limits:
cluster-local-gateway:["istio-proxy",{"limits":{"cpu":"2","memory":"4Gi"},"requests":{"cpu":"1","memory":"1Gi"}}]
istio-ingressgateway:["istio-proxy",{"limits":{"cpu":"2","memory":"4Gi"},"requests":{"cpu":"1","memory":"1Gi"}}]
istiod:["discovery",{"requests":{"cpu":"300m","memory":"200Mi"}}]
Test summary
service coligotest1-540/coligotest-1 not ready and skip measuring
service coligotest1-560/coligotest-1 not ready and skip measuring
service coligotest1-298/coligotest-8 not ready and skip measuring
service coligotest1-408/coligotest-17 not ready and skip measuring
-------- Measurement --------
Total: 800 | Ready: 796 Fail: 4 NotFound: 0
Service Configuration Duration:
Total: 7385.000000s
Average: 9.277638s
- Service Revision Duration:
Total: 7344.000000s
Average: 9.226131s
- Service Deployment Created Duration:
Total: 7344.000000s
Average: 9.226131s
- Service Pod Scheduled Duration:
Total: 4.000000s
Average: 0.005025s
- Service Pod Containers Ready Duration:
Total: 6109.000000s
Average: 7.674623s
- Service Pod queue-proxy Started Duration:
Total: 1672.000000s
Average: 2.100503s
- Service Pod user-container Started Duration:
Total: 1447.000000s
Average: 1.817839s
Service Route Ready Duration:
Total: 115371.000000s
Average: 144.938442s
- Service Ingress Ready Duration:
Total: 107833.000000s
Average: 135.468593s
- Service Ingress Network Configured Duration:
Total: 151.000000s
Average: 0.189698s
- Service Ingress LoadBalancer Ready Duration:
Total: 107682.000000s
Average: 135.278894s
-----------------------------
Overall Service Ready Measurement:
Total: 800 | Ready: 796 Fail: 4 NotFound: 0
Total: 115371.000000s
Average: 144.938442s
Median: 16.000000s
Min: 4.000000s
Max: 784.000000s
Percentile50: 16.000000s
Percentile90: 542.500000s
Percentile95: 634.500000s
Percentile98: 695.000000s
Percentile99: 749.000000s
Raw Timestamp saved in CSV file /tmp/20200827224434_raw_ksvc_creation_time.csv
Measurement saved in CSV file /tmp/20200827224434_ksvc_creation_time.csv
Visualized measurement saved in HTML file /tmp/20200827224434_ksvc_creation_time.html
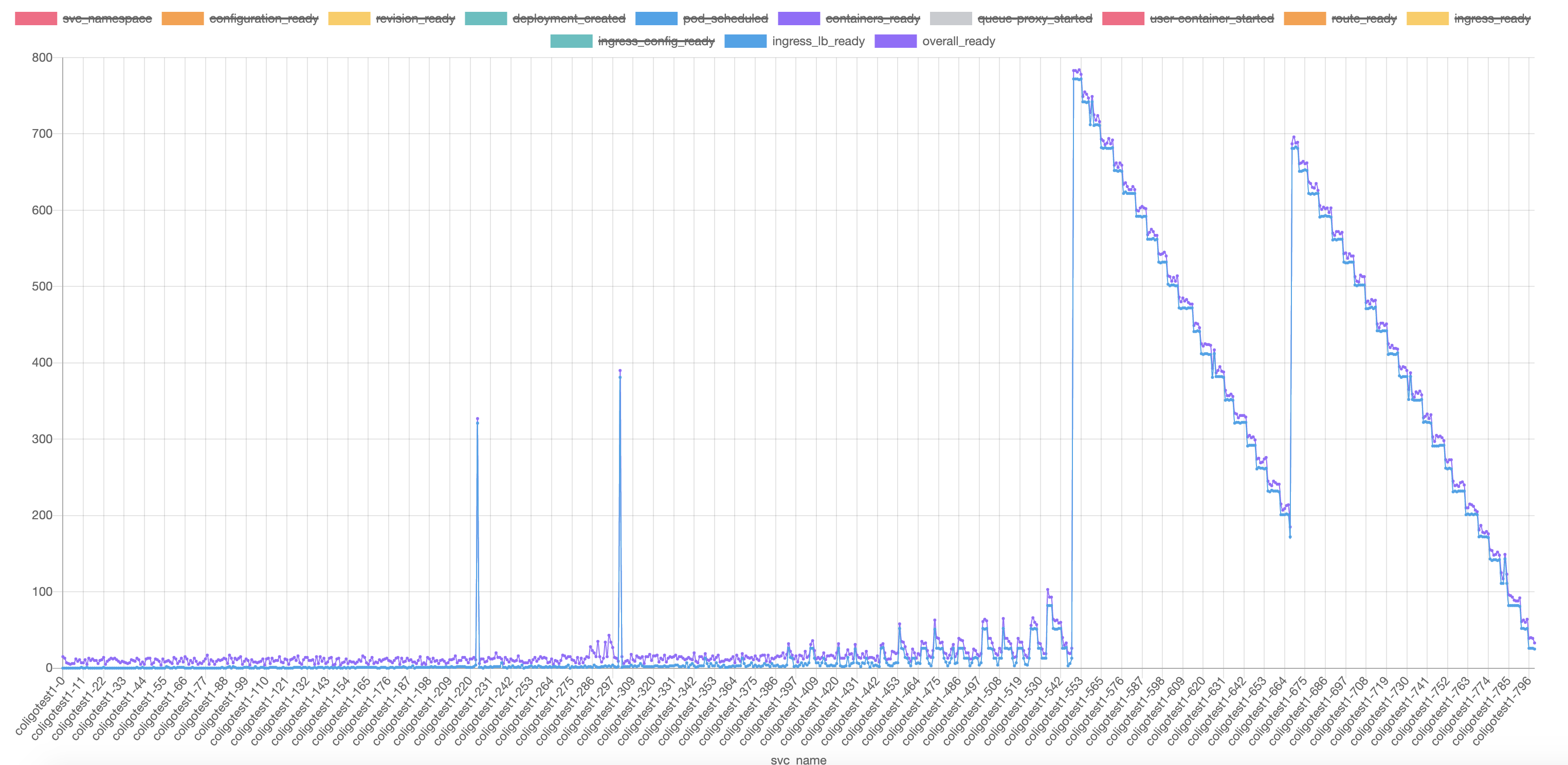
Notice that there are still four ksvc does not get ready, so they will contribute 4 more peaks in the chart. The endpoint missing issue still exists.
lanceliuu
on 28 Aug 2020
Inorder to reproduce using kperf I post some parameters I am using during the test:
- Create 20 namespaces:
for i in {1..20}; do
kubectl create ns coligotest-$i
done
- Generate workload
./kperf service generate -b 1 -c 1 -i 5 --minScale 1 --nsPrefix "coligotest-" --nsRange 1,20 -n 800 --svcPrefix coligotest-
- After all 800 ksvcs get ready, start measurement
./kperf service measure --nsrange 1,20 --prefix coligotest- --nsprefix coligotest
The result should be generated with a static html report and several csv files
- Clean up
./kperf service clean --nsPrefix "coligotest-" --nsRange 1,20 --svcPrefix "coligotest-"
Thanks for the reproduction instructions. I don't believe this problem is environmental, although I did notice the server where my Kubernetes control plane node was requesting 50ghz of cpu, but only able to obtain 33ghz (my nodes only have 33ghz of cpu - dual xeon 16 core @ 2.1ghz).
Here is what I've got in my environment:
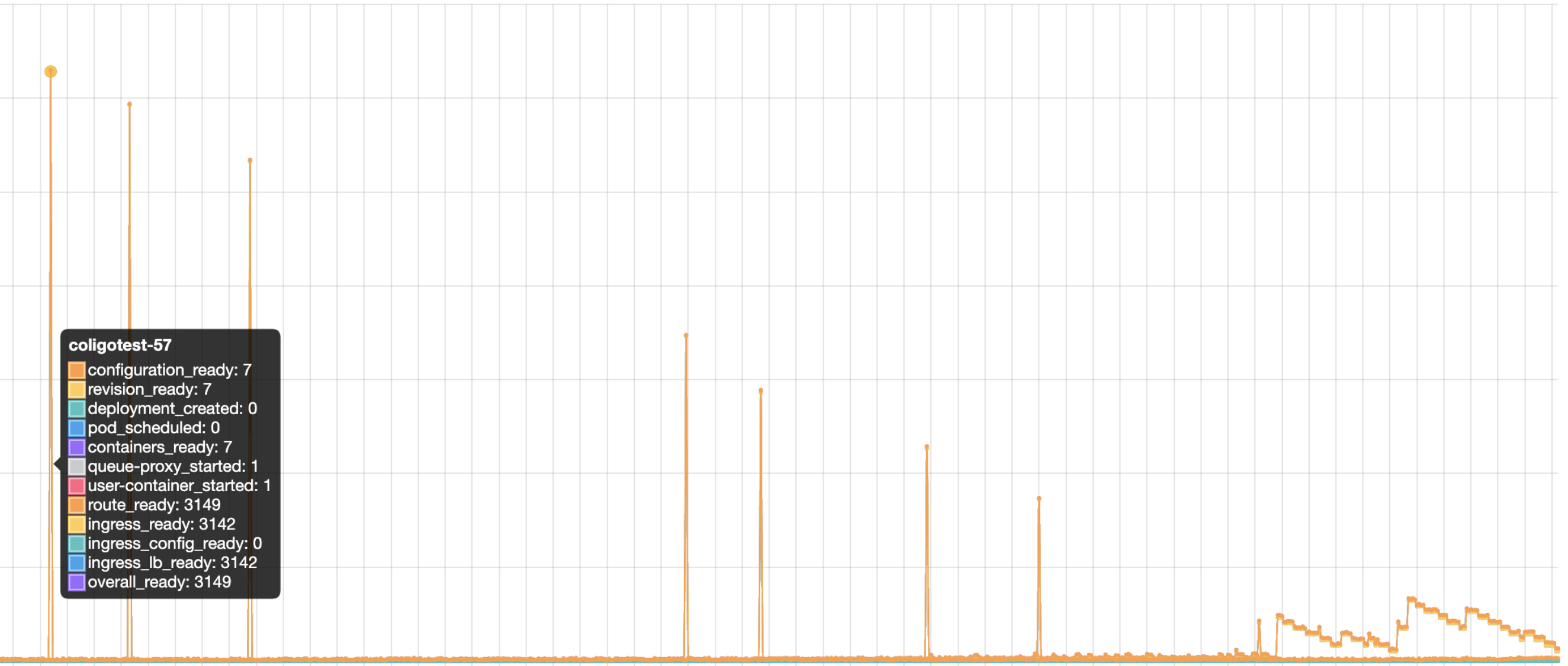
I have a few questions (and suggestions for improvements).
- can you define the unit on the y axis (msec, seconds, hours, days, etc)
- can you define how ingress_lb_ready is calculated
- can you define and show the function entry points where ingress_lb_ready is calculated to help speed up my understanding of this benchmark and knative?
- can you document all of the metrics in a document.
Cheers,
-steve
sdake
on 28 Aug 2020
This is a problem: https://github.com/istio/istio/issues/23029#issuecomment-683234340
sdake
on 29 Aug 2020
with the fixes in https://github.com/istio/istio/issues/23029 I am able to reproduce the similar result as @sdake posted. The individual spikes are gone and I think It is a valid fix. Thank you 👍 .
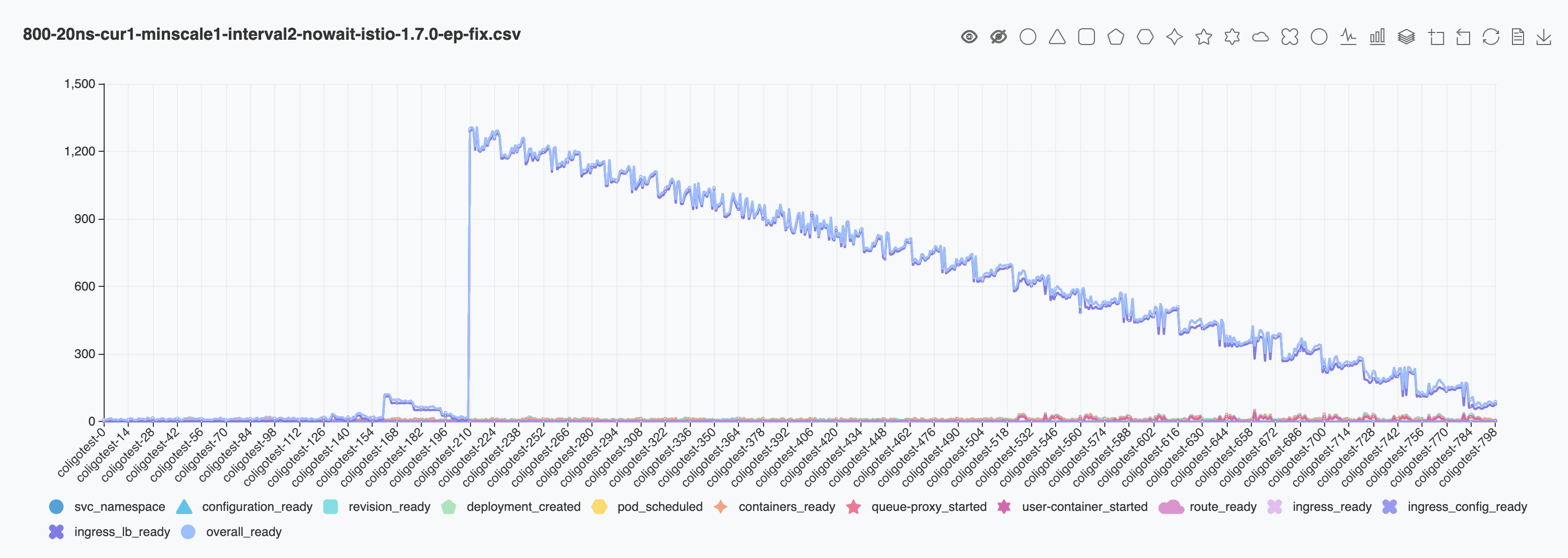
I think we can now focus on the sudden increasing after 200 ksvcs. It should be another unknown issue and I will try to collect more logs.
lanceliuu
on 1 Sep 2020
pprof protos attached. 2 = first 10 minutes, 3 = second 10 minutes of benchmark.
pprof.pilot-discovery.samples.cpu.002.pb.gz
pprof.pilot-discovery.samples.cpu.003.pb.gz
sdake
on 1 Sep 2020
pb2 flame graph:
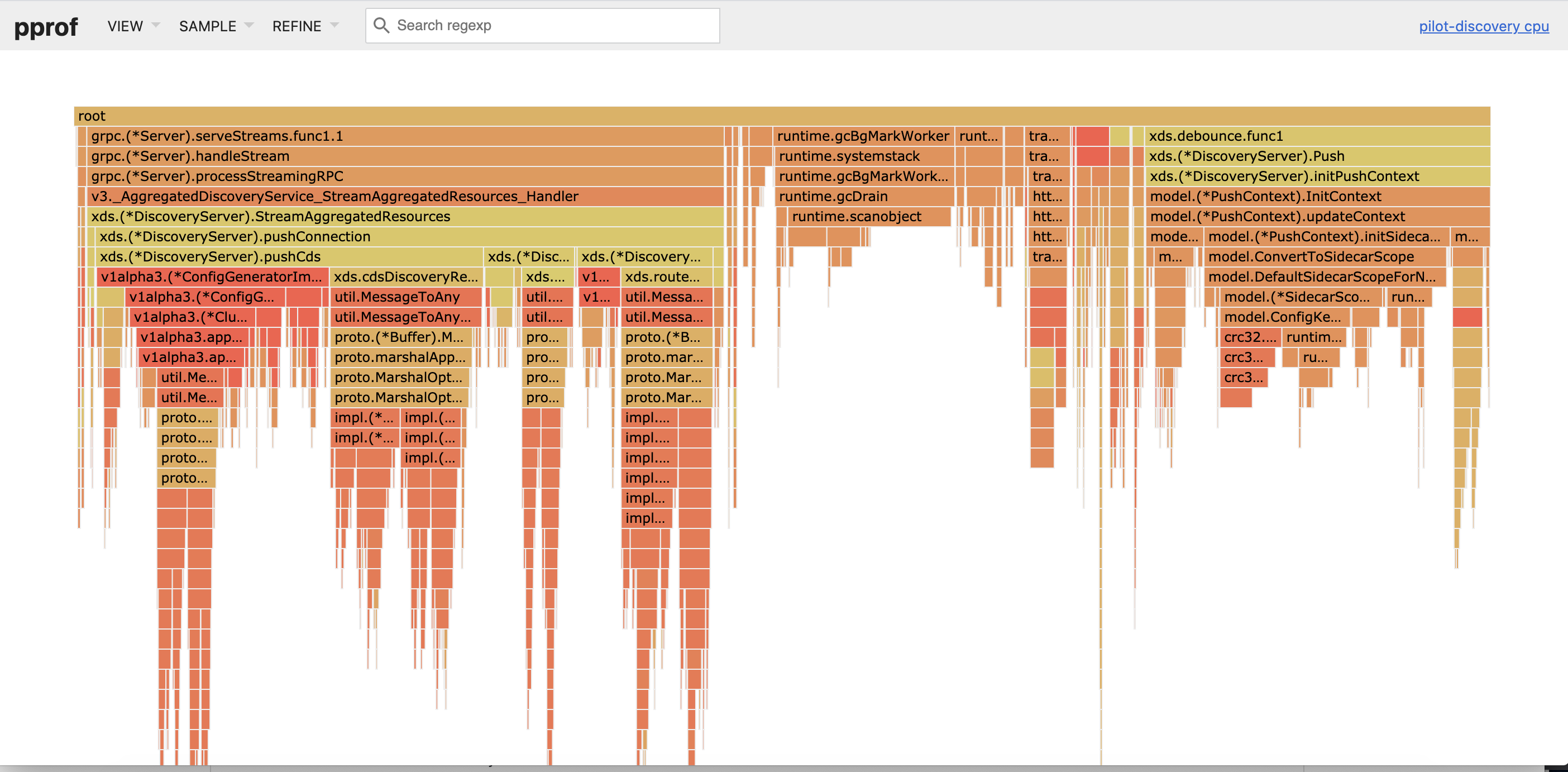
pb3 flame graph:
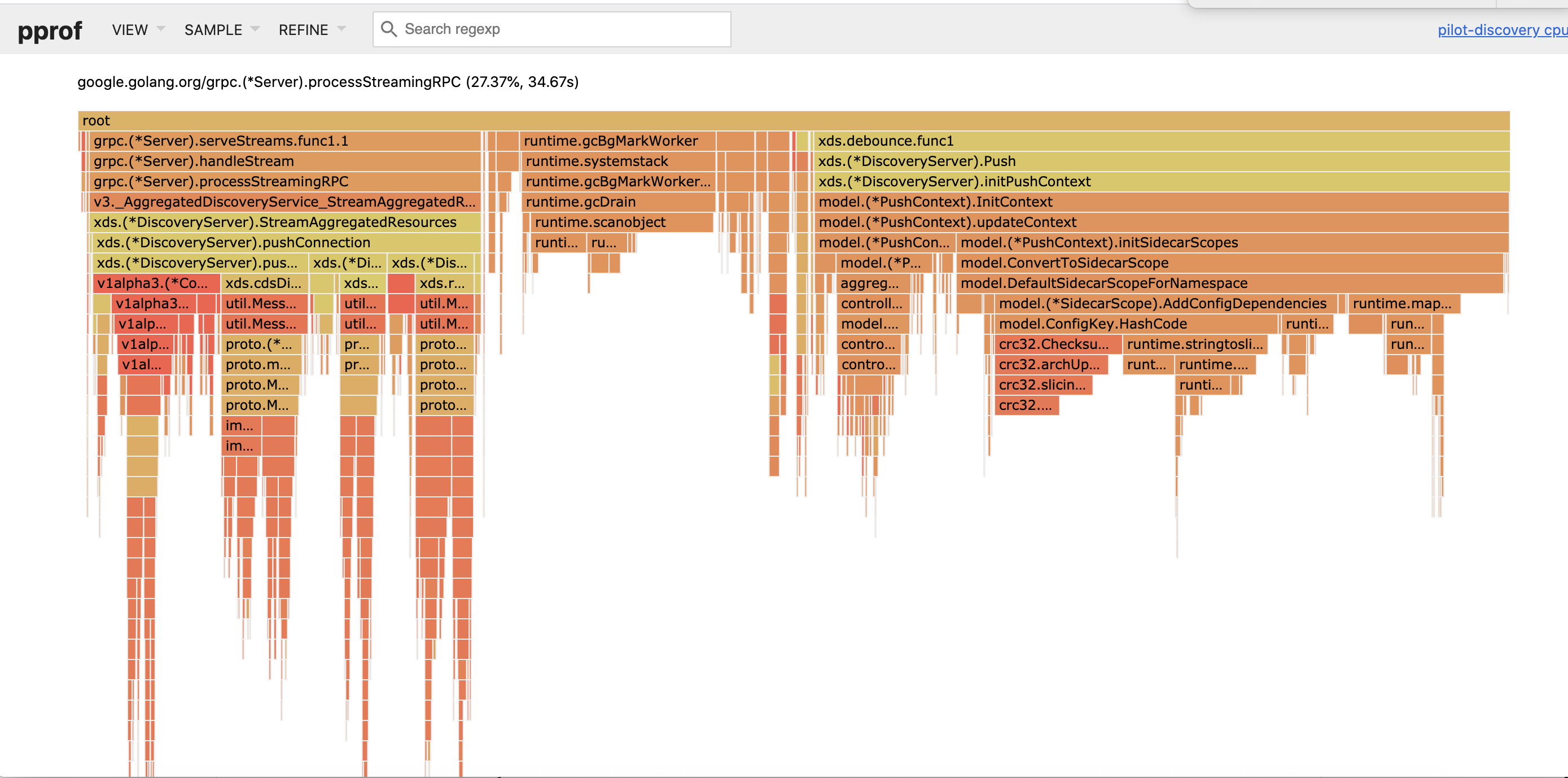
sdake
on 1 Sep 2020
What is an acceptable delay for new VS being created? Obviously we want it to be as fast as possible but we need to be realistic so we can make the appropriate compromises
howardjohn
on 1 Sep 2020
@howardjohn was running on my cluster today and modified the debounce. This is something I wanted to try after the endpoint missing problem was solved yesterday, but hadn't got to it.
Here is the information I was able to gather after John sorted out the problem:
Istio sends state via XDSv3 to Envoy about the state of the mesh. The endpoint state is incremental, however, the route state is not. When sending full route state , 400mbit/sec network is used on 1 physical node, and on the other 2, 1 mbit is used. I speculate this creates overload. There is a default debounce timeout of 100msec. The debounce timer works by sending the XDS state to every envoy after the debounce timer has expired. At default value (100msec), the debounce timer with this workload generates 400mbit of network traffic. At a more reasonable value of 1s, the network consumes about 1mbit for the singular node, and for other nodes, 0-10kbit(!). Envoy does not correctly handle overload situations, it appears. The simple solution is to set the debounce timer to something more reasonable. The max debounce timer is 10 seconds for a full push by default. Here are my settings:
./istioctl install -f istio-minimal-operator.yaml --set values.pilot.env.PILOT_DEBOUNCE_AFTER=1s --set values.pilot.env.PILOT_DEBOUNCE_MAX=10s --set values.pilot.env.PILOT_ENABLE_EDS_DEBOUNCE=true --set values.gateways.istio-egressgateway.enabled=false --set values.gateways.istio-ingressgateway.sds.enabled=true --set hub=docker.io/sdake --set tag=kn2 --set meshConfig.accessLogFile="/dev/stdout"
kubectl apply --filename https://github.com/knative/serving/releases/download/v0.17.0/serving-crds.yaml
kubectl apply --filename https://github.com/knative/serving/releases/download/v0.17.0/serving-core.yaml
kubectl apply --filename https://github.com/knative/net-istio/releases/download/v0.17.0/release.yaml
which presents the graph:
the values can go lower, by increasing PILOT_DEBOUNCE_AFTER up to 10s. Too long a delay, and the services will not register. I recommend keeping the max where it is, at 10s.
Thanks @howardjohn.
If everyone is satisfied with this result, please, close and comment.
Cheers,
-steve
sdake
on 2 Sep 2020
Here are some test results with tuning for PILOT_DEBOUNCE_AFTER parameter. I tested using PILOT_DEBOUNCE_MAX = 10s
- PILOT_DEBOUNCE_AFTER = 1s
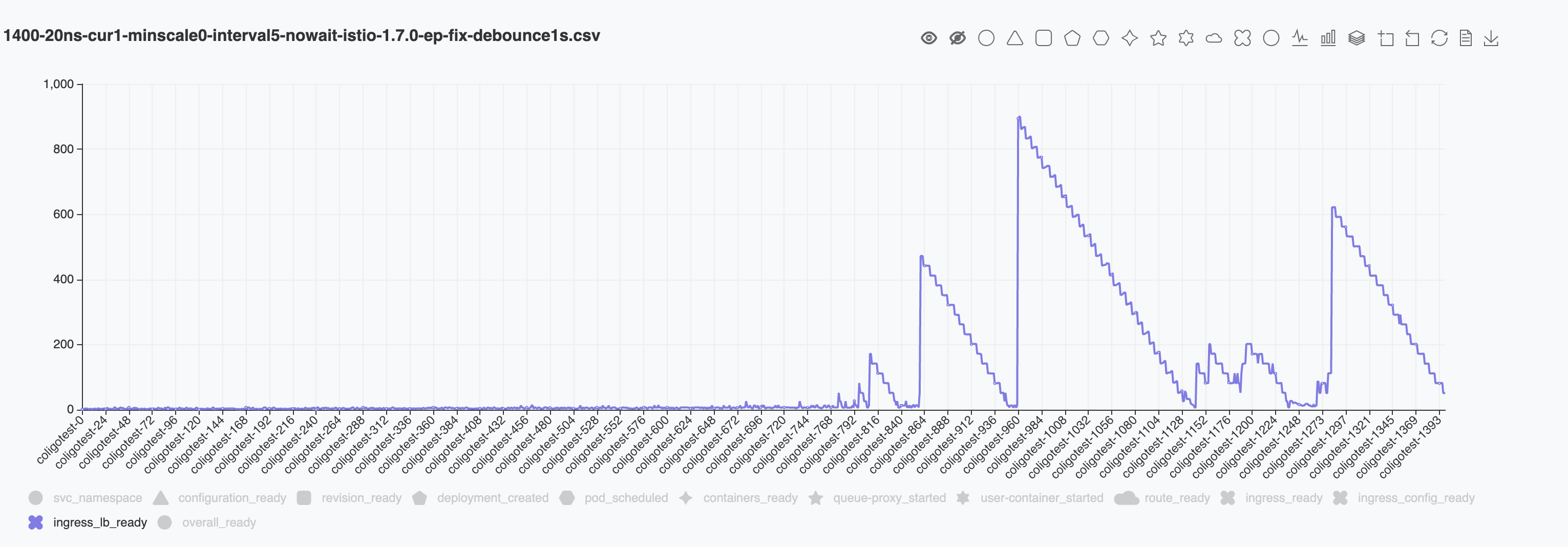
the 1st round I tested with a total of 800 ksvcs, the result is as following. The result is a lot better compares to the default value 100ms. There are no sudden jumps around ~200 indices. But I noticed the ready time increases to ~50s at the end of test. So I did another test to increase the total ksvc count to 1400.
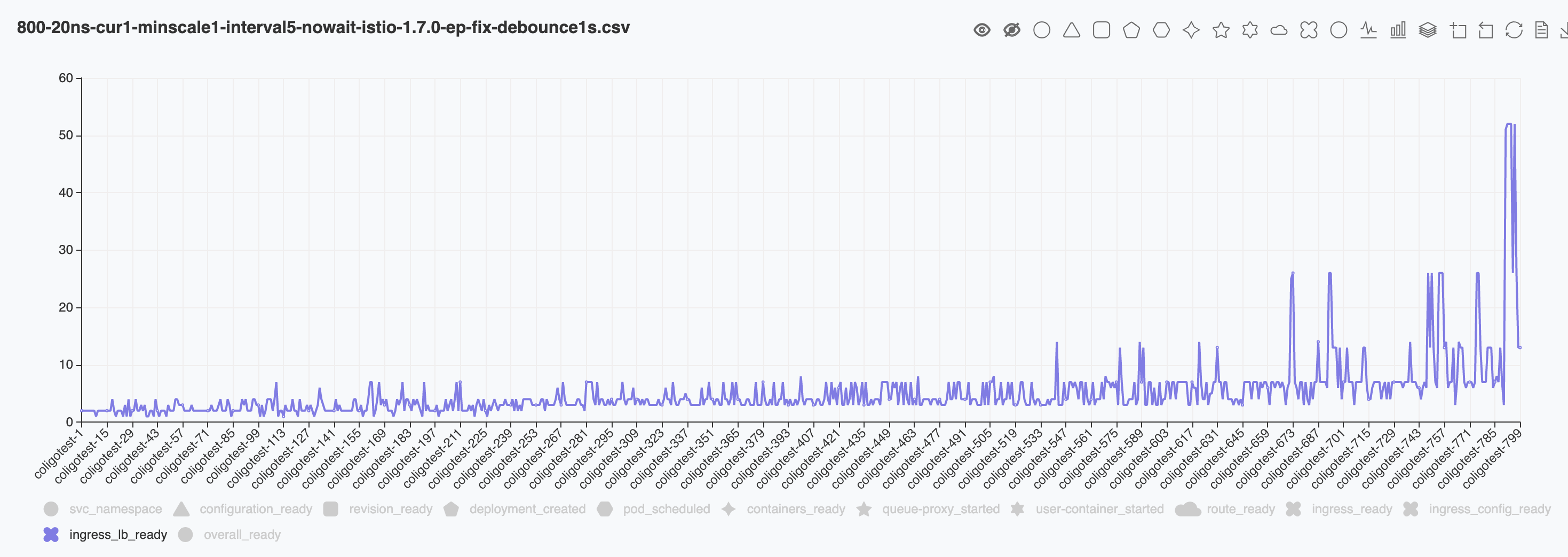
We can tell that the similar sudden jumps happens after index 800. So I assume that the longer PILOT_DEBOUNCE_AFTER will alleivate the stress for configuring envoy. But it will not solve the issue completely.
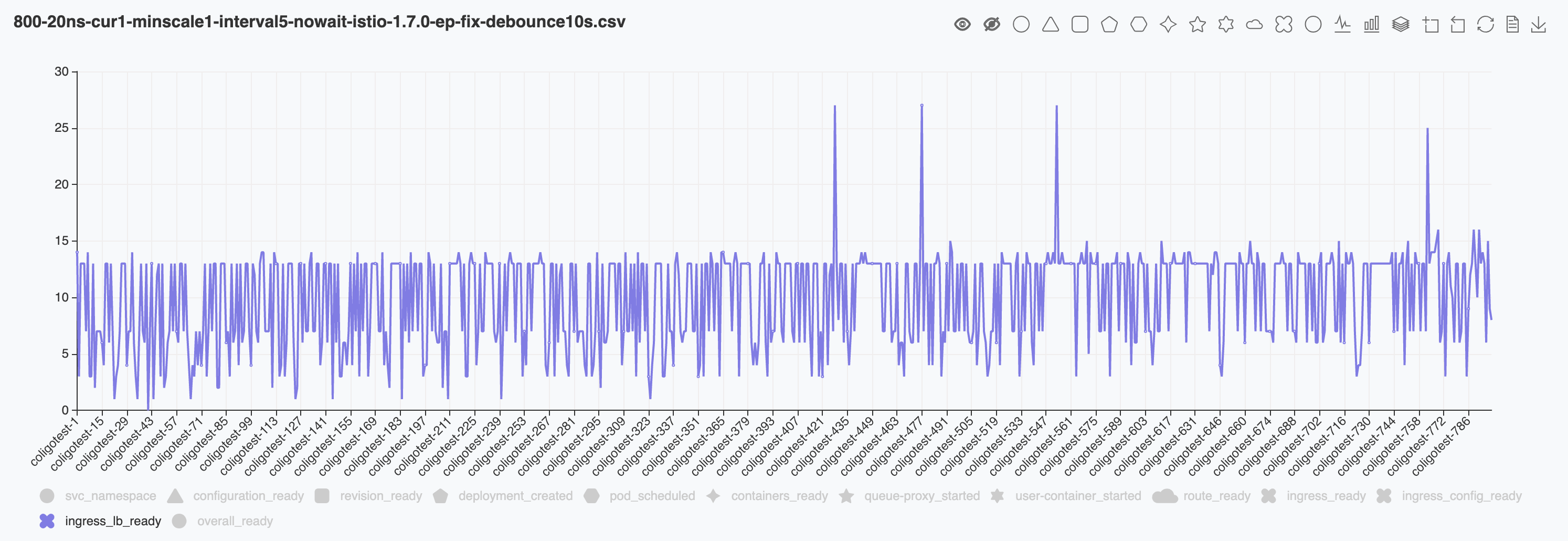
- PILOT_DEBOUNCE_AFTER = 10s
The first round tests for 800 ksvcs most of the ready time is around 13s. Which is the first probe after 10s in knative.
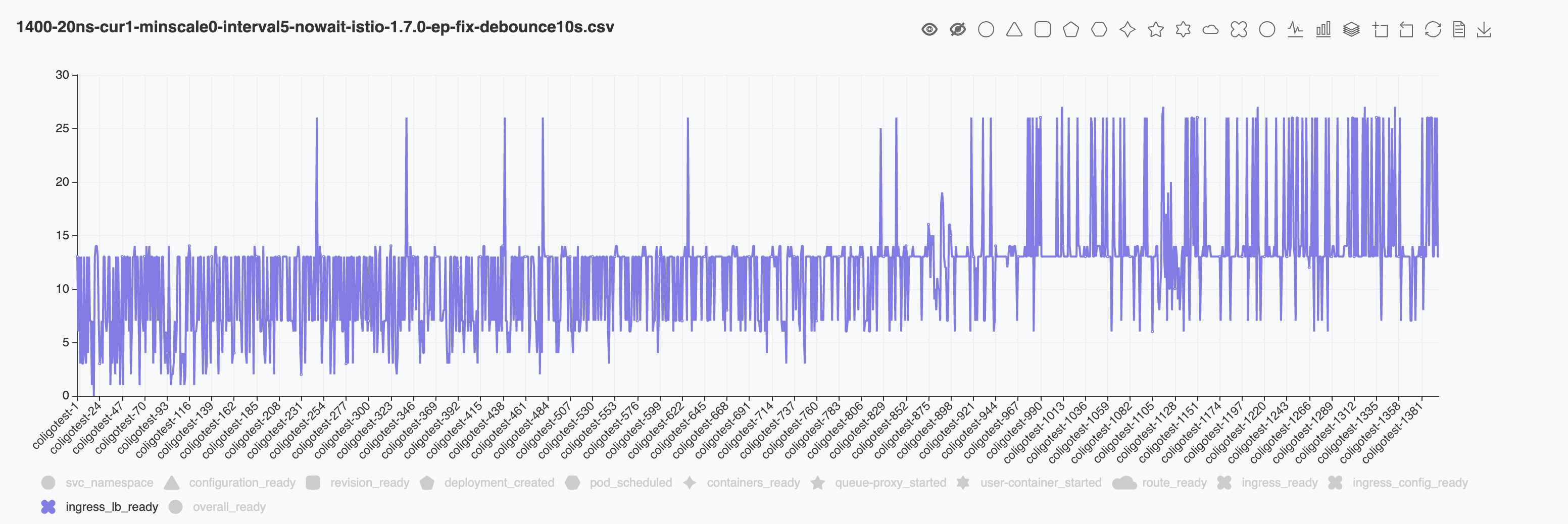
Below is the result for total 1400 ksvcs. With the debounce time setting to 10s the result after 800 became stable again. I suspect that as the total ksvc count grows, we will hit the sudden increasing again.
lanceliuu
on 4 Sep 2020
I agree PILOT_DEBOUNCE_AFTER = 10s is too long, e.g. at least 10s for first service to be alive/pingable. I would think 1s or 2s is a more reasonable number.
@lanceliuu Does the above result contain the endpoint fix from @hzxuzhonghu?
linsun
on 4 Sep 2020
@lanceliuu good analysis. What is your total scale objective with Knative?
Cheers,
-steve
sdake
on 4 Sep 2020
by the way - current the debounce is static, so you get the issue of fixed 10s on new config. However, I doubt there is a real world scenario where you apply a 1400 kservices in a row with a 1s delay. In reality, users apply maybe a couple at once, then have periods of inactivity. Envoy only is overloaded when we flood it with a bunch of new ones at once. We can easily add dynamic backoff such that the first config will take 100ms, then the second 1s, then the 10th 10s, etc. This way for the 99.99% case its very fast, and for people running synthetic tests we don't see spikes where envoy gets overloaded.
howardjohn
on 4 Sep 2020
A few comments on this.
The testing here is e2e knative tests. While this is useful for knative its not great for our own testing, since it requires a massive cluster, takes a super long time to test, and we cannot isolate delays that are from knative and delays that are from Istio. To replicate this in Istio terms, I wrote a tool to do essentially the same test, but with pure Istio: https://github.com/howardjohn/pilot-load#ingress-prober.
The test will create a virtual service at a given interval, and immediately start probing the ingress and recording the TTL (time from VS creation until it is applied).
Some findings:
At no point in any of the testing here, or in the Knative tests, is Istiod under load. The delays can be 100% attributed to Envoy being slow to apply the configuration sent to it. This doesn't mean its Envoy's "fault" necessarily - we may be sending it updates too quickly, sending inefficient config, etc.
100ms interval, 1k routes create, Istio master
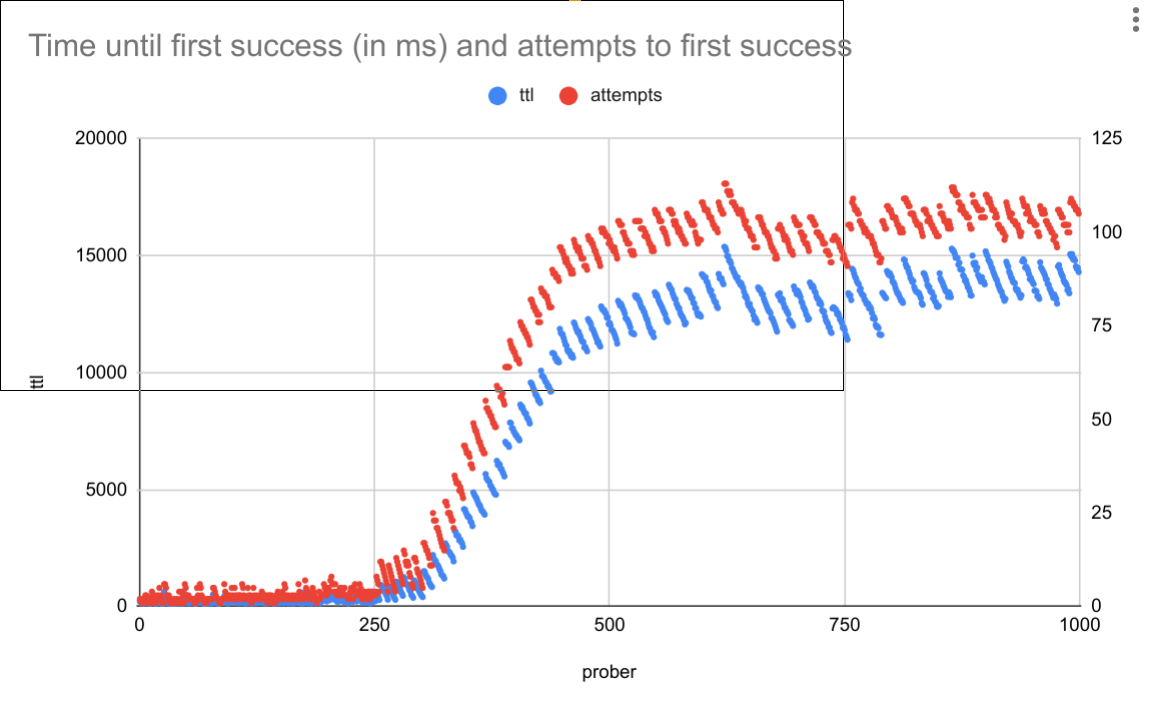
Here we can see after ~250 VS, things start degrading and peak at 15s until ready. The "sawtooth" pattern occurs because Envoy is getting stuck, so the first VS after it gets stuck takes the longest time, then eventually it catches up and batches the next one.
- 100ms, 15k routes, Istio master with 5s debounce
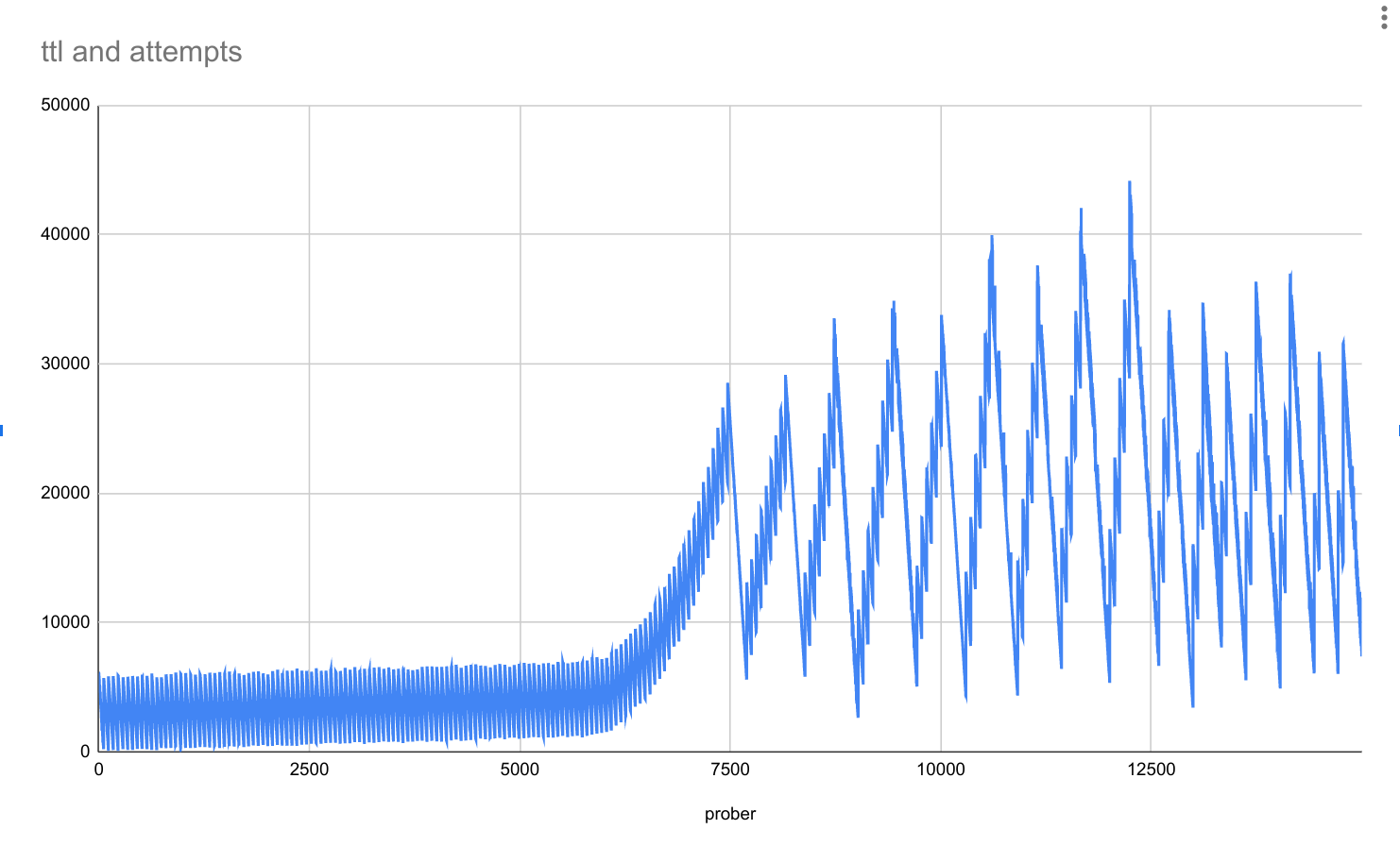
Here we see similar successful results as above increasing the debounce. Two important notes here are that even at low load, there is a 5s delay, which is a bad UX. Additionally, we can see the performance does degrade eventually, around 6k routes. It should be noted that 6k routes is a lot.
- Next I added some new code that will apply backpressure on Envoy. The debounce logic is untouched (ie debounce for 100ms).
Below is the original run and the new code overlayed:
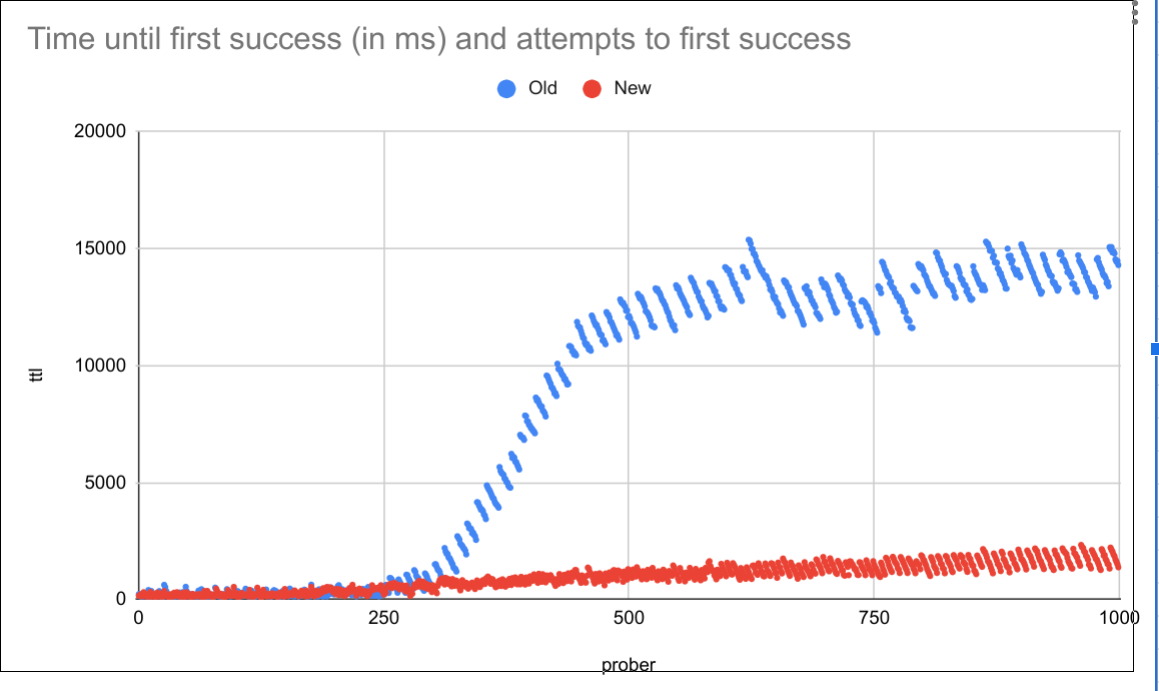
This also appears to scale linearly with large number of routes:
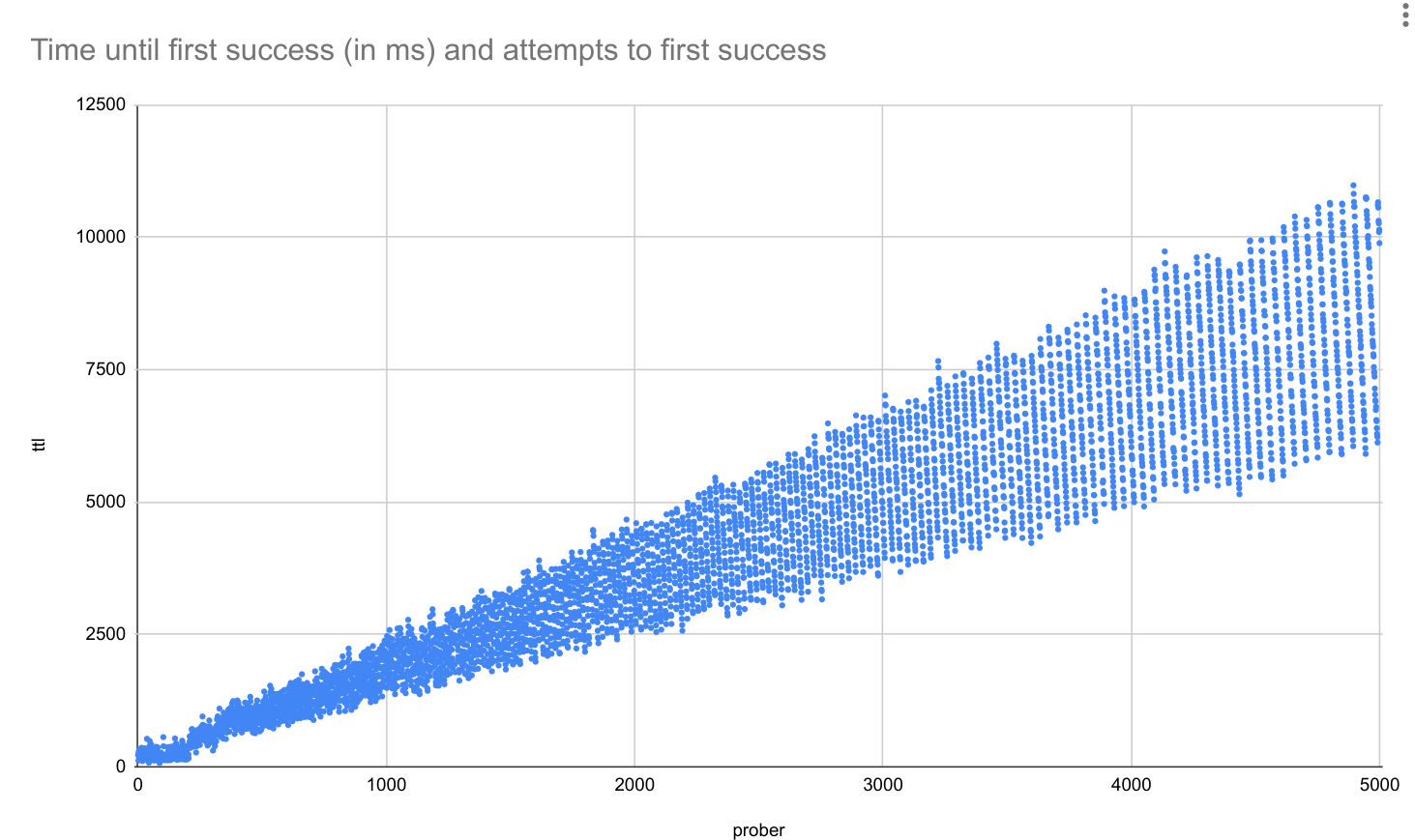
With the changes above I am pretty sure we are pushing the limits of Envoy and improvements will not be made without switching to delta_xds
For good measure, scaling to 15k routes: (ignore the weird results around 10k, it was a bug in the test code)
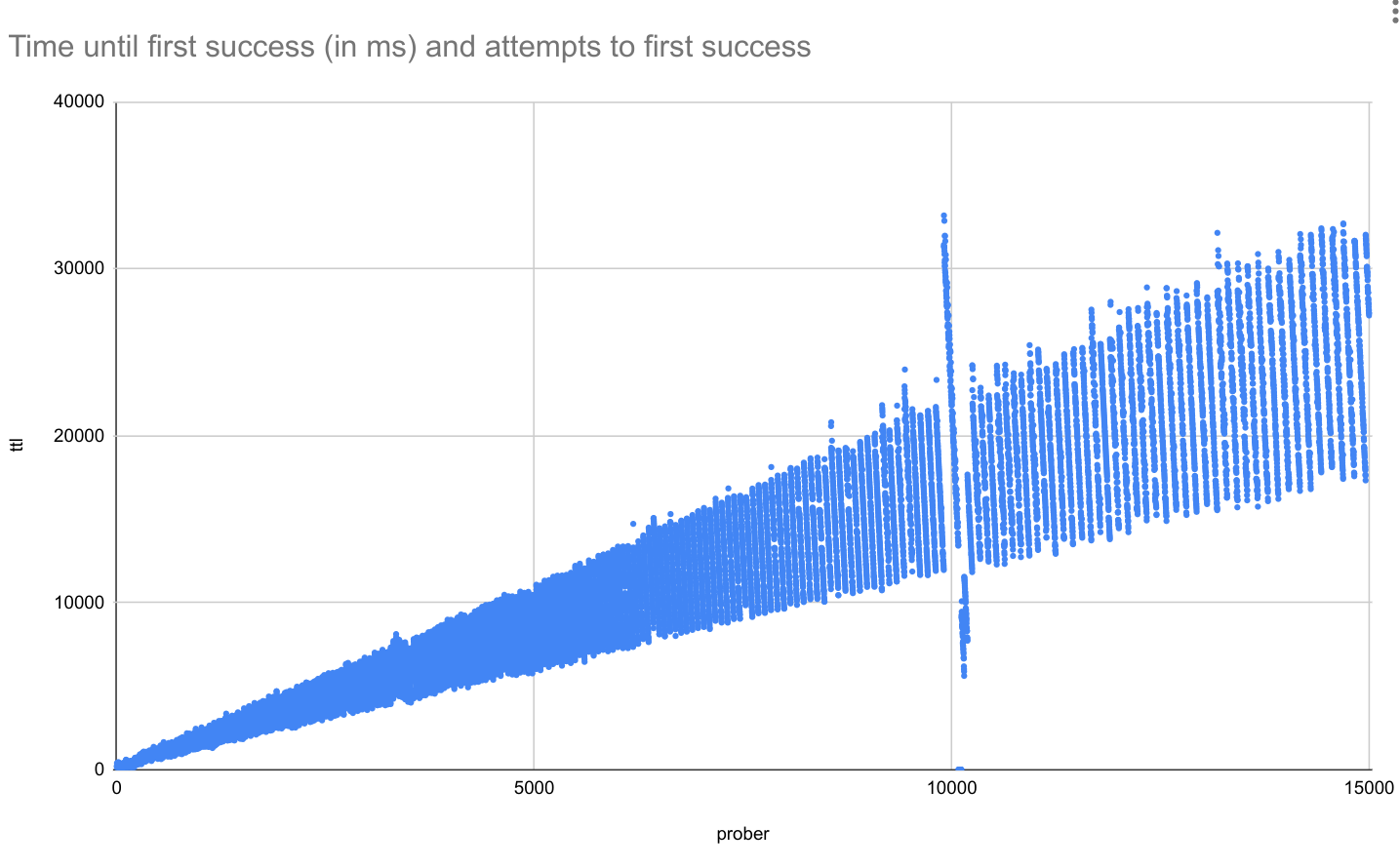
howardjohn
on 5 Sep 2020
@howardjohn @sdake @linsun
Our test case is creation 1 knative service ( trigger 2 VS, 3 kube svc created) per 5 sec, total 1000 kn service is our target. And our target is no salability issue for knative service creation, ingress lb time < 15 s. Now we have to config to 10s to meet the target, but impact is the first kn service also need ~10s to get ready, which is bad ux.
And I do not think it is high workload, and also we tested default 100ms debounce time with cold time (create 300 kn services, and stop/wait 1 hour, then continue to 100 kn services), we see similar bump of ingress ready time, which means more kn service existing, more ingress ready one for new created kn services.
@howardjohn I think you raised the good point is Are istiod sending inefficient config to envoy ? Or sending too quickly ? Are you going to improve it ? Also you mentioned delta_xds, is it a right way to for istio plan to do ? Thank you.
ZhuangYuZY
on 6 Sep 2020
And our target is no salability issue for knative service creation
This is simply not possible. Please define an upper bound for scale, no system can scale infinity...
Regarding the "10s delay" see my previous comment?
howardjohn
on 6 Sep 2020
Specifically if your goal is to get ingress ready within 15s we should be able to scale up to 10k virtual services. If you need scalability beyond that we will need to implement delta xds which will be a ~6 month effort. Given every other knative Ingress implementation is based on Envoy afaik, I suspect this is the same for all other implementation as well.
howardjohn
on 6 Sep 2020
@ZhuangYuZY knative usage pattern is different than Other service mesh. One single proxy being updated in response to continuous churn in the whole deployment means that delta is the only real solution here.
If 6 months is too long for knative, then I suggest knative operators (google, Ibm, others...) put effort directly into addressing the problem in Istio.
It is being implemented in other places: ex: https://github.com/envoyproxy/go-control-plane/pull/335
 mandarjog
on 6 Sep 2020
mandarjog
on 6 Sep 2020
Specifically if your goal is to get ingress ready within 15s we should be able to scale up to 10k virtual services.
You can check last diagram in https://github.com/istio/istio/issues/25685#issuecomment-687040288, with debouce 10 seconds, ingress ready time is > 15s in 829th kn service creation (create 1 kn service with 5s internal, 1 kn service trigger 2 VS), so when there are 829*2 VS, the ingress ready time is > 15s. Which below your target < 10k virtual service, do you have any suggestion on that?
We do not expect no scalability issue infinity. We expect no obvious scalability within 1k Kn service (2K VS) for short term(now), but more ( > 2k) in long term.
And I can share other knative ingress implementation which all based on envoy. All work better than istio, you may check for reference.
1, kourier, no scalability issue, for same test case, all ingress ready time < 1 sec.
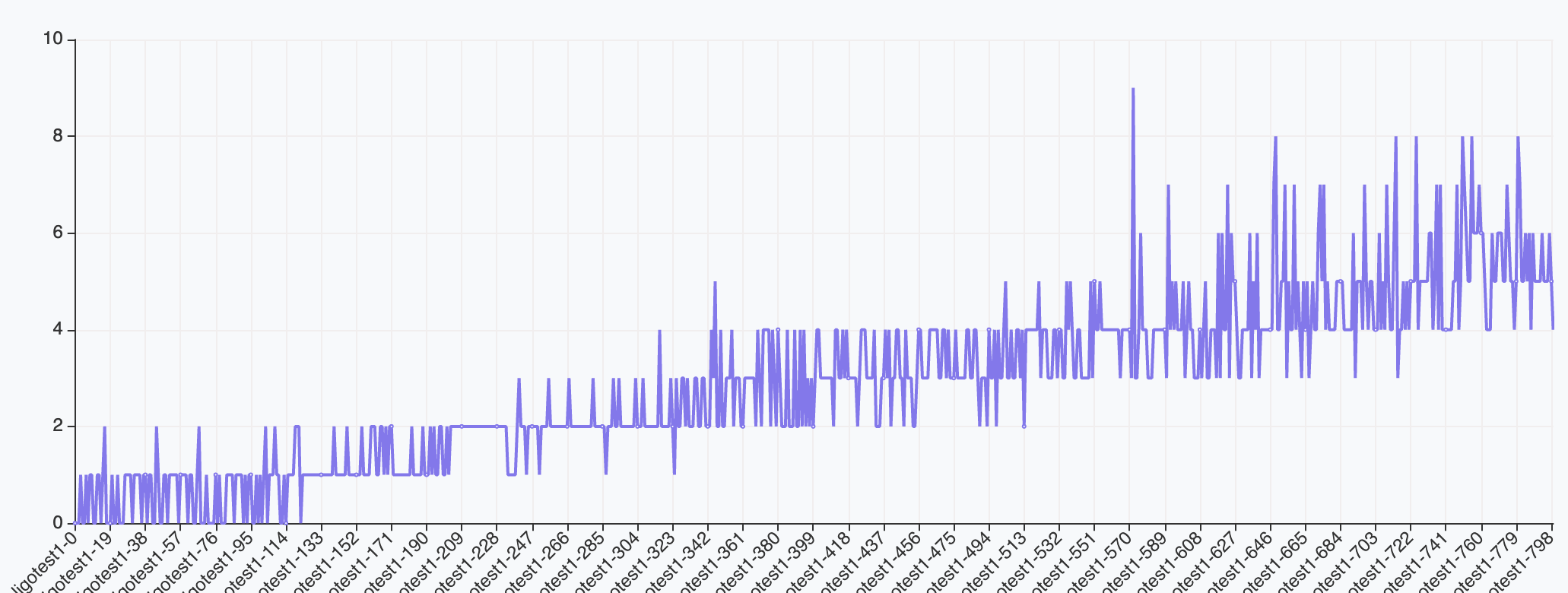
- Contour, there is a little scalability problem, but can be acceptable, 0 ~ 8 for 800 kn services.
@mandarjog Thank you, I will need to talk with team, @linsun @sdake what is comment for implement delta solution ? Thank you.
ZhuangYuZY
on 7 Sep 2020
I am not sure why the focus here is in the denounce change (which we already established is not viable) and delta xds (which is months off) and not the backpressure solution I presented in https://github.com/istio/istio/issues/25685#issuecomment-687453380 which has been shown to meet the scalability concerns goals of
Btw, I would recommend getting more granual testing if possible. For example, the kourier test isn't very useful since it is indicated as "0s" due to rounding error. It's also not a fair comparison as the probing logic is in the same process as the xds control plane which I strongly suspect is biasing the results. Given the config generated by kourier and Istio is essentially equivalent and the back pressure mechanism I have tested should have the optimal timing (since we send envoy config at exactly the rate it can accept it) I suspect kourier results will be no better than this if measured with a consistent benchmark.
howardjohn
on 7 Sep 2020
also if you are happy with kourier's performance than you should not need delta xds. Fundamentally istio and kourier do pretty much the same thing so we can match their performance without delta xds (which they don't implement either)
howardjohn
on 7 Sep 2020
John,
Re the backpressure solution, I had (assumed poorly) that this was part of
your benchmark tool and not something that could be integrated into Istio.
Can you publish a PR and we can go from there? The backpressure results
look great to me, and delta-xds is 6-9 months out at a minimum. This
backpressure PR would benefit all use cases of Istio as well, not just
knative (I suspect).
Cheers,
-steve
On Sun, Sep 6, 2020 at 7:06 PM John Howard notifications@github.com wrote:
also if you are happy with kourier's performance than you should not
need delta xds. Fundamentally istio and kourier do pretty much the same
thing so we can match their performance without delta xds (which they don't
implement either)—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/istio/istio/issues/25685#issuecomment-687978795, or
unsubscribe
https://github.com/notifications/unsubscribe-auth/AAFYRCOVHYMOGZNRVPXBWFTSEQ5YXANCNFSM4PDGLZ3Q
.
sdake
on 7 Sep 2020
@lanceliuu re this investigation of performance. We found a hugely critical bug in Istio that was a regression in 1.6 and 1.7. Thank you for driving that resolution to completion.
Your general request for improving performance isn't really viable until delta-xds is implemented.
That said, in the benchmarks, John has implemented an ARQ (flow control) - and I am refining it:
The ARQ graph looks like this:
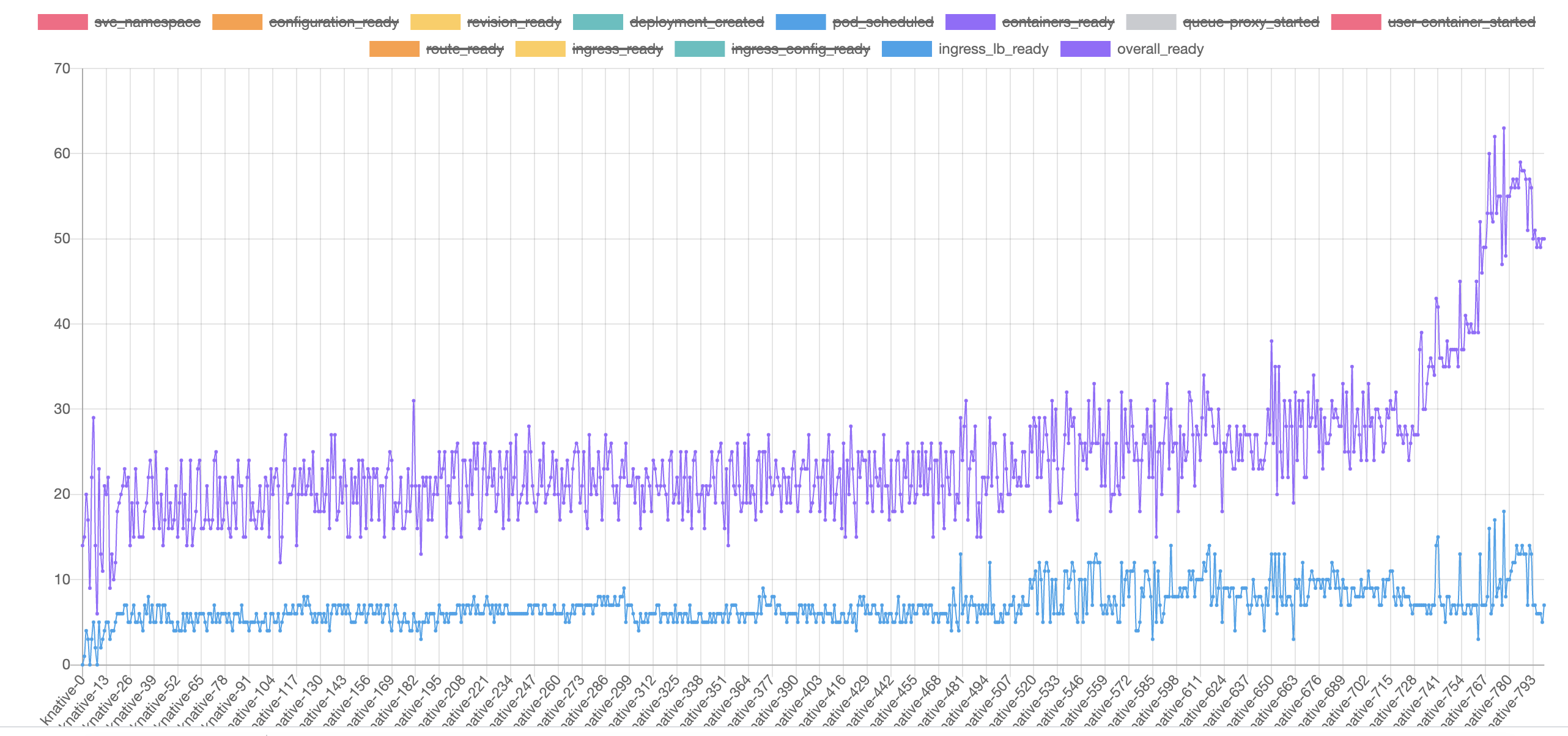
Installation (tag kn15 in hub docker.io/sdake):
sdake@scale-cp:~$ cat kn.sh
#!/bin/bash
# Install Istio and knative
./istioctl install -f istio-minimal-operator.yaml --set values.gateways.istio-egressgateway.enabled=false --set values.gateways.istio-ingressgateway.sds.enabled=true --set hub=docker.io/sdake --set tag=kn15
kubectl apply --filename https://github.com/knative/serving/releases/download/v0.17.0/serving-crds.yaml
kubectl apply --filename https://github.com/knative/serving/releases/download/v0.17.0/serving-core.yaml
kubectl apply --filename https://github.com/knative/net-istio/releases/download/v0.17.0/release.yaml
This graph is with debounce=1s without ARQ:
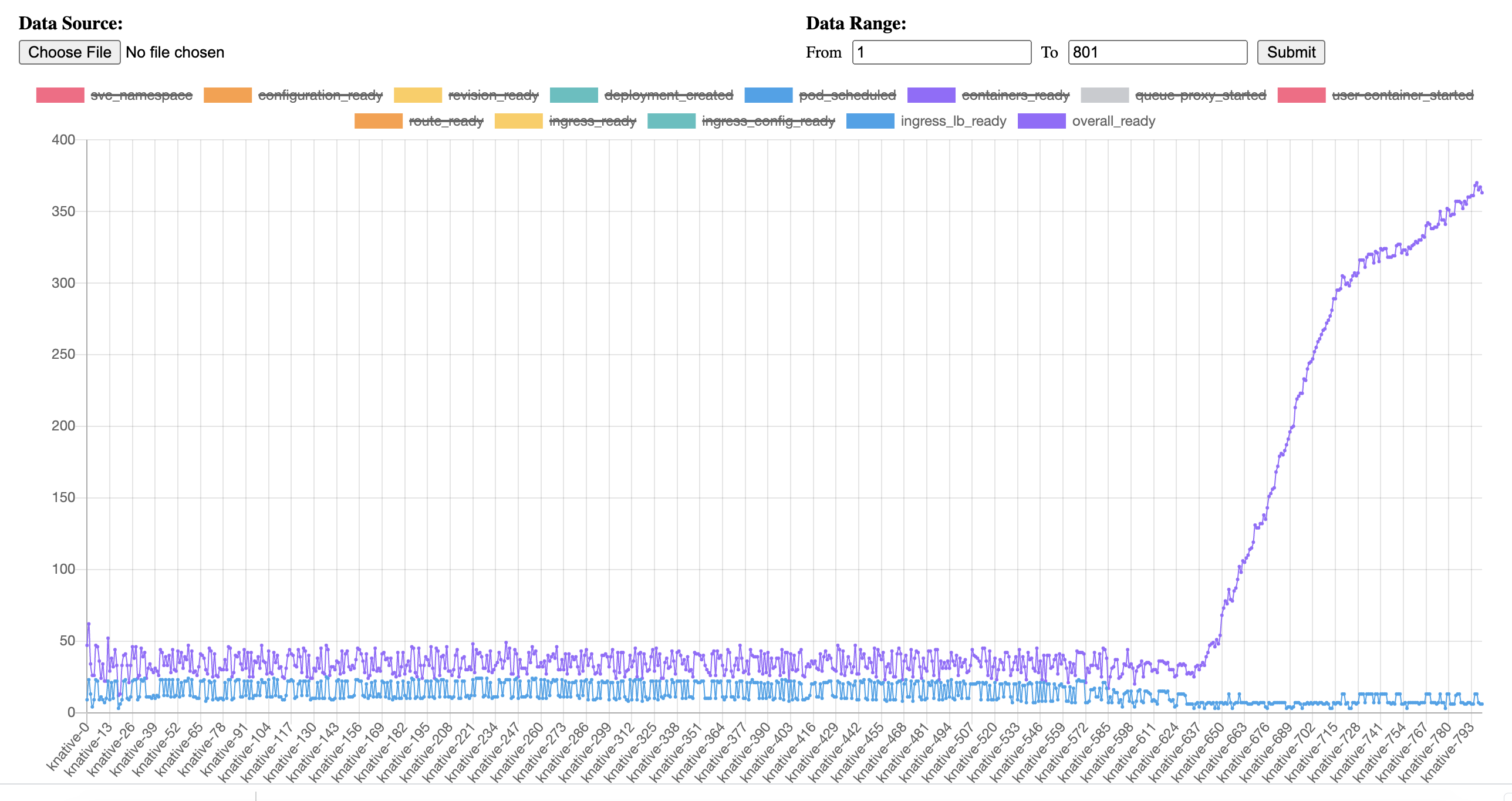
Installation (tag kn16 in hub docker.io/sdake):
sdake@scale-cp:~$ cat kn2.sh
#!/bin/bash
# Install Istio and knative
./istioctl install -f istio-minimal-operator.yaml --set values.pilot.env.PILOT_DEBOUNCE_AFTER=1s --set values.pilot.env.PILOT_DEBOUNCE_MAX=10s --set values.pilot.env.PILOT_ENABLE_EDS_DEBOUNCE=true --set values.gateways.istio-egressgateway.enabled=false --set values.gateways.istio-ingressgateway.sds.enabled=true --set hub=docker.io/sdake --set tag=kn16 --set meshConfig.accessLogFile="/dev/stdout"
kubectl apply --filename https://github.com/knative/serving/releases/download/v0.17.0/serving-crds.yaml
kubectl apply --filename https://github.com/knative/serving/releases/download/v0.17.0/serving-core.yaml
kubectl apply --filename https://github.com/knative/net-istio/releases/download/v0.17.0/release.yaml
In either case, the ARQ or the denounce, what is happening behind the scenes is we are slowing down Istio push performance because Envoy (or the network) can't keep up with the input speed. This causes Envoy to accept many pushes, then queue them, then drain them eventually. I want to try the pilot denounce backoff PR and will publish a graph when I have backported that work into my repo, but feel a sliding window ARQ would be superior to the denounce.
Within the next 3 weeks, I want you to make a decision if the performance is sufficient for your needs until Istio 1.10 or 1.11, where delta-xds may make its first appearance. Note we don't make forward-looking statements in this project, so everything here is subject to change and is a bit exploratory and speculative.
In both cases, the istio-minimal-operator.yaml looks like this:
sdake@scale-cp:~$ cat istio-minimal-operator.yaml
apiVersion: install.istio.io/v1alpha1
kind: IstioOperator
spec:
values:
global:
proxy:
autoInject: disabled
useMCP: false
jwtPolicy: third-party-jwt
telemetry:
enabled: false
v2:
enabled: false
addonComponents:
pilot:
enabled: true
prometheus:
enabled: false
components:
ingressGateways:
- name: istio-ingressgateway
enabled: true
- name: cluster-local-gateway
enabled: true
label:
istio: cluster-local-gateway
app: cluster-local-gateway
k8s:
service:
type: ClusterIP
ports:
- name: status-port
port: 15021
targetPort: 15021
- name: http2
port: 80
targetPort: 8080
- name: https
port: 443
targetPort: 8443
On my 15 node 4cpux16gb ram cluster + 8cpux64gb ram for K8s control plane, the graph clearly shows that the tag kn15 with the super experimental ARQ is superior in performance.
Can you please produce charts for your production environment for these two models?
Cheers,
-steve
sdake
on 13 Sep 2020
@sdake and @howardjohn Thank you very much for driving this improvement.
One question, if ARQ(kn15) works well, are you going to PR and merge istio main branch for next release or patch, which is before delta-xds (1.10 or 1.11) ? Thank you.
ZhuangYuZY
on 14 Sep 2020
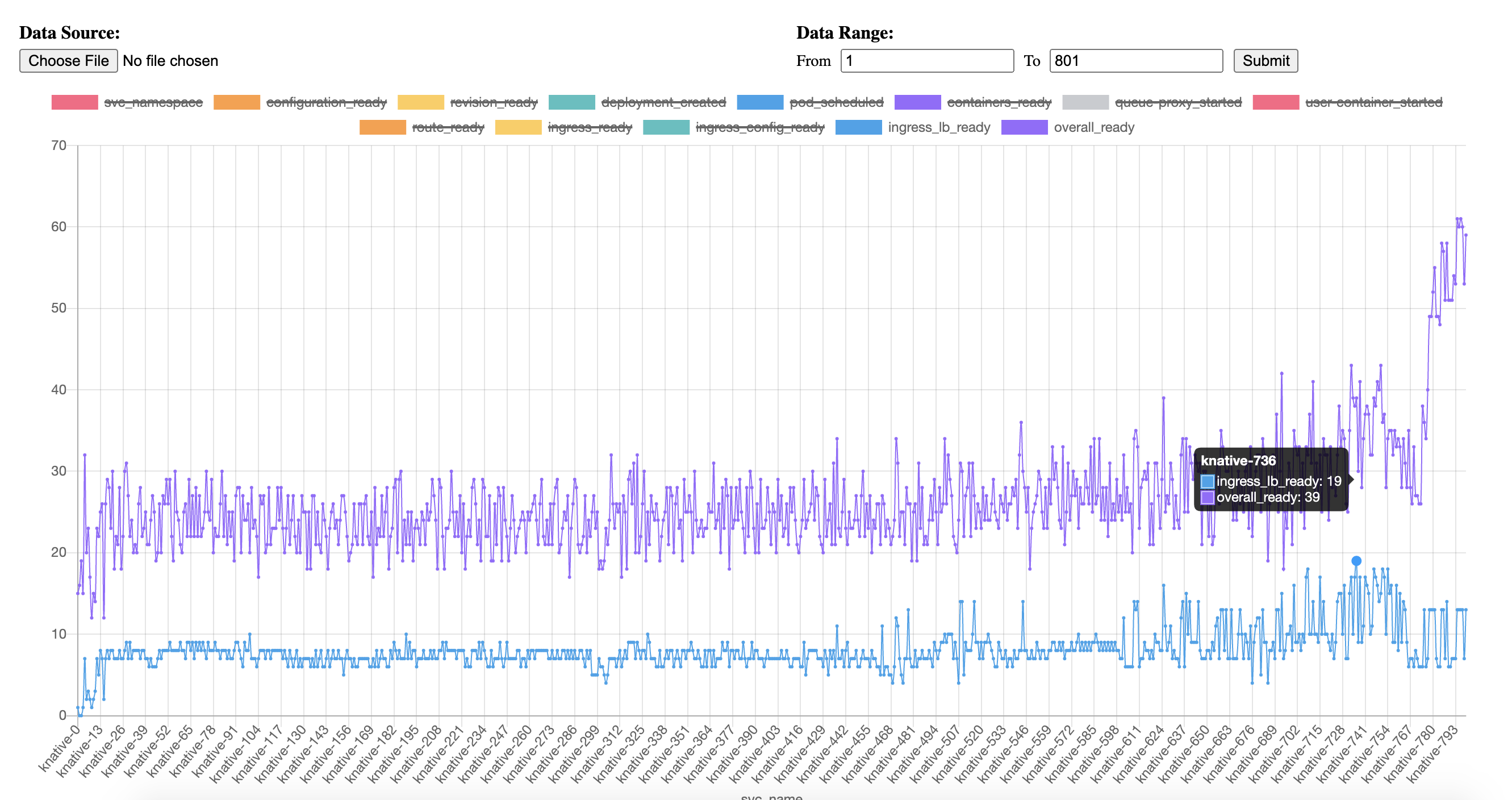
Initial results from PR #27563 using 15 node 4 cpu 16 gig mem node cluster.
sdake
on 26 Sep 2020
hub is docker.io/sdake tag is kna46 if folks wish to test.
Cheers,
-steve
sdake
on 26 Sep 2020
@sdake and @howardjohn Thank you very much for driving this improvement.
One question, if ARQ(kn15) works well, are you going to PR and merge istio main branch for next release or patch, which is before delta-xds (1.10 or 1.11) ? Thank you.
Some variant of the kna46 tag will be used. i expect this PR will make 1.8. For a backport to 1.7, we would have to consult the 1.7 release team. If the code can be hidden by feature flags and disabled by default, then I think a backport to 1.7 is viable although I am not sure how welcome.
Cheers,
-steve
sdake
on 26 Sep 2020
https://github.com/istio/istio/pull/27768
HUB docker.io/sdake tag kn0078 is looking better from a mergability standpoint (IMO) - worth testing.
sdake
on 6 Oct 2020
HI gang. With PR: https://github.com/istio/istio/pull/27687, Istio performs much better. Running the master branch with the 800 services test case on K8s 1.19:
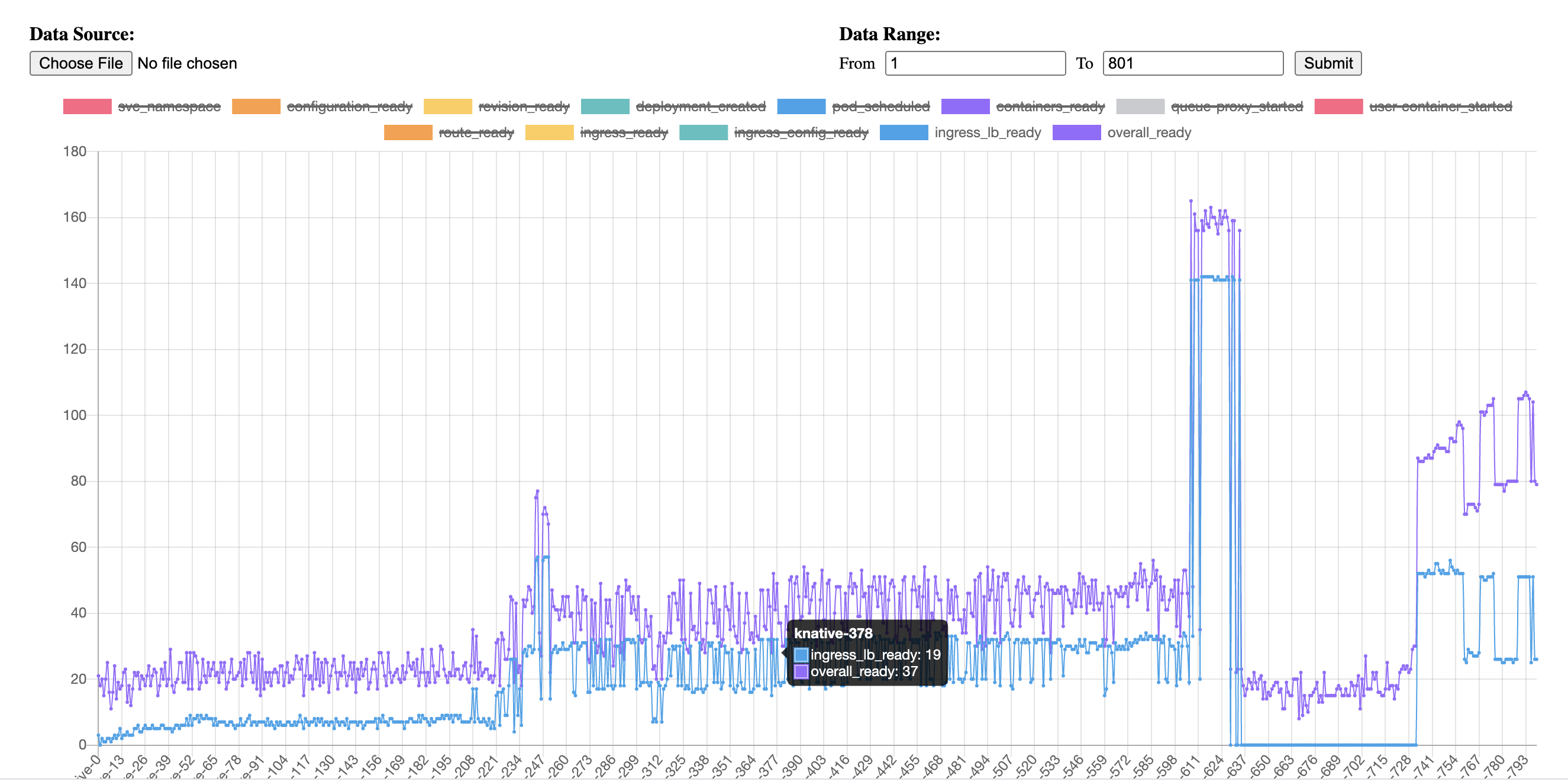
I found this PR has improved the default case, and explains the massive jump at 237+ without flow control. I think flow control is still necessary, although without modifying this value, flow control fails in various ways.
Here is how I set PILOT_XDS_SEND_TIMEOUT:
sdake@scale-cp:~$ cat kn.sh
#!/bin/bash
# Install Istio and knative
./istioctl install -f istio-minimal-operator.yaml --set values.pilot.env.PILOT_XDS_SEND_TIMEOUT=100s --set values.pilot.env.PILOT_ENABLE_FLOW_CONTROL=true --set values.gateways.istio-egressgateway.enabled=false --set hub=docker.io/sdake --set tag=kn0157
kubectl apply --filename https://github.com/knative/serving/releases/download/v0.17.0/serving-crds.yaml
kubectl apply --filename https://github.com/knative/serving/releases/download/v0.17.0/serving-core.yaml
kubectl apply --filename https://github.com/knative/net-istio/releases/download/v0.17.0/release.yaml
I displayed some of the various send metric times .. Note even though the FLOW_CONTROL flag is enabled in the command, it is unimplemented in master so no flow control is running at present.
Envoy SIGTERMed (restarted) in the big spike here:
sdake@scale-cp:~$ kubectl logs --previous -n istio-system cluster-local-gateway-7784d9555d-n2xsm
2020-10-16T01:59:10.399686Z info FLAG: --concurrency="0"
2020-10-16T01:59:10.399726Z info FLAG: --domain="istio-system.svc.cluster.local"
2020-10-16T01:59:10.399733Z info FLAG: --help="false"
2020-10-16T01:59:10.399736Z info FLAG: --log_as_json="false"
2020-10-16T01:59:10.399770Z info FLAG: --log_caller=""
2020-10-16T01:59:10.399774Z info FLAG: --log_output_level="default:info"
2020-10-16T01:59:10.399777Z info FLAG: --log_rotate=""
2020-10-16T01:59:10.399781Z info FLAG: --log_rotate_max_age="30"
2020-10-16T01:59:10.399791Z info FLAG: --log_rotate_max_backups="1000"
2020-10-16T01:59:10.399794Z info FLAG: --log_rotate_max_size="104857600"
2020-10-16T01:59:10.399798Z info FLAG: --log_stacktrace_level="default:none"
2020-10-16T01:59:10.399811Z info FLAG: --log_target="[stdout]"
2020-10-16T01:59:10.399816Z info FLAG: --meshConfig="./etc/istio/config/mesh"
2020-10-16T01:59:10.399819Z info FLAG: --outlierLogPath=""
2020-10-16T01:59:10.399823Z info FLAG: --proxyComponentLogLevel="misc:error"
2020-10-16T01:59:10.399826Z info FLAG: --proxyLogLevel="warning"
2020-10-16T01:59:10.399830Z info FLAG: --serviceCluster="cluster-local-gateway"
2020-10-16T01:59:10.399834Z info FLAG: --stsPort="0"
2020-10-16T01:59:10.399837Z info FLAG: --templateFile=""
2020-10-16T01:59:10.399841Z info FLAG: --tokenManagerPlugin="GoogleTokenExchange"
2020-10-16T01:59:10.399845Z info FLAG: --trust-domain="cluster.local"
2020-10-16T01:59:10.399856Z info Version 1.8-dev-63463ec22531aa3e23234394407c113ac279ba4a-dirty-Modified
2020-10-16T01:59:10.400027Z info Obtained private IP [172.16.25.193 fe80::80b5:a5ff:fe5b:f0b3]
2020-10-16T01:59:10.400128Z info Apply mesh config from file defaultConfig:
discoveryAddress: istiod.istio-system.svc:15012
proxyMetadata:
DNS_AGENT: ""
tracing:
zipkin:
address: zipkin.istio-system:9411
disableMixerHttpReports: true
enablePrometheusMerge: true
rootNamespace: istio-system
trustDomain: cluster.local
2020-10-16T01:59:10.401458Z info Effective config: binaryPath: /usr/local/bin/envoy
concurrency: 0
configPath: ./etc/istio/proxy
controlPlaneAuthPolicy: MUTUAL_TLS
discoveryAddress: istiod.istio-system.svc:15012
drainDuration: 45s
envoyAccessLogService: {}
envoyMetricsService: {}
parentShutdownDuration: 60s
proxyAdminPort: 15000
proxyMetadata:
DNS_AGENT: ""
serviceCluster: cluster-local-gateway
statNameLength: 189
statusPort: 15020
terminationDrainDuration: 5s
tracing:
zipkin:
address: zipkin.istio-system:9411
2020-10-16T01:59:10.401512Z info Proxy role: &model.Proxy{RWMutex:sync.RWMutex{w:sync.Mutex{state:0, sema:0x0}, writerSem:0x0, readerSem:0x0, readerCount:0, readerWait:0}, Type:"router", IPAddresses:[]string{"172.16.25.193", "fe80::80b5:a5ff:fe5b:f0b3"}, ID:"cluster-local-gateway-7784d9555d-n2xsm.istio-system", Locality:(*envoy_config_core_v3.Locality)(nil), DNSDomain:"istio-system.svc.cluster.local", ConfigNamespace:"", Metadata:(*model.NodeMetadata)(nil), SidecarScope:(*model.SidecarScope)(nil), PrevSidecarScope:(*model.SidecarScope)(nil), MergedGateway:(*model.MergedGateway)(nil), ServiceInstances:[]*model.ServiceInstance(nil), IstioVersion:(*model.IstioVersion)(nil), VerifiedIdentity:(*spiffe.Identity)(nil), ipv6Support:false, ipv4Support:false, GlobalUnicastIP:"", XdsResourceGenerator:model.XdsResourceGenerator(nil), WatchedResources:map[string]*model.WatchedResource(nil)}
2020-10-16T01:59:10.401518Z info JWT policy is third-party-jwt
2020-10-16T01:59:10.401595Z info PilotSAN []string{"istiod.istio-system.svc"}
2020-10-16T01:59:10.401686Z info sa.serverOptions.CAEndpoint == istiod.istio-system.svc:15012 Citadel
2020-10-16T01:59:10.401805Z info Using CA istiod.istio-system.svc:15012 cert with certs: var/run/secrets/istio/root-cert.pem
2020-10-16T01:59:10.401933Z info citadelclient Citadel client using custom root: istiod.istio-system.svc:15012 -----BEGIN CERTIFICATE-----
MIIC/DCCAeSgAwIBAgIQHdfSaLljKjP7xHiVYTUmyTANBgkqhkiG9w0BAQsFADAY
MRYwFAYDVQQKEw1jbHVzdGVyLmxvY2FsMB4XDTIwMTAxNjAxNTg1N1oXDTMwMTAx
NDAxNTg1N1owGDEWMBQGA1UEChMNY2x1c3Rlci5sb2NhbDCCASIwDQYJKoZIhvcN
AQEBBQADggEPADCCAQoCggEBAKF+rryWpgQabVS8vc6roKsegGwDt2fInsMmy4u/
tgkZw2IsQGfgi4R/7hy+8rSRu8n32j2gTYU9cSYFcU3mrtqx+cZylcgxCaa63Kxh
k77moW8qVwXa/R7CO7VFegOLguX4m8e5B7b0mHw0pPqDNI158ChcoEjpOvZxqAxT
hHtaDFq9B+DPY38u0zr3jEjFTEMw8HASd9vxdEKrRDJjj2aEiMK9vaQ4t7xw6pk0
+TiWqzr22TIR90L383OCvTSAxquW8EkCmBV5g3E/Onxgx4nyj1WWnFDUEzm35f25
oe65uYjBobTf2qThMoxz6Z1e1UnSYsF9DvETCyD+RAcg59cCAwEAAaNCMEAwDgYD
VR0PAQH/BAQDAgIEMA8GA1UdEwEB/wQFMAMBAf8wHQYDVR0OBBYEFMKwGsGtjksA
uZey1x+qkE1uF6C1MA0GCSqGSIb3DQEBCwUAA4IBAQA5pcZBDK5R6cWbN4YgVi0I
/mcbtdxibsvDe4jXE2LR5/2r39KSb8tf11xLRuA0fmbHS88L+OJt0h8kR8qIqHtC
08O0ZpjFb/UGIjgnRtTak7sM0Ar85webroP+GtUOYysythgje1jqX8xp4zIRrRvX
KdbwXeaVTgtB2lhHY2s3D/X+369scJCR0daMRbGoYhKcThN05VhoOf9BuL4lUiTl
qMl2ip27uTzn5FuT20F2/syJNu6MVHuhWfr/ucahCrK5R4anUzYLCNcgziY4lgAR
uzgzwOQij/UkEv8SjMPVUFE/6LKftb2QWuAVswSGEJtIqocEoIjBVolovgJSMeW8
-----END CERTIFICATE-----
2020-10-16T01:59:10.437110Z info Starting gateway SDS
2020-10-16T01:59:10.540289Z info sds SDS gRPC server for workload UDS starts, listening on "./etc/istio/proxy/SDS"
2020-10-16T01:59:10.540428Z info sds SDS gRPC server for gateway controller starts, listening on "./var/run/ingress_gateway/sds"
2020-10-16T01:59:10.540455Z info xdsproxy Initializing with upstream address istiod.istio-system.svc:15012 and cluster Kubernetes
2020-10-16T01:59:10.540327Z info sds Start SDS grpc server
2020-10-16T01:59:10.540494Z info sds Start SDS grpc server for ingress gateway proxy
2020-10-16T01:59:10.540737Z info xdsproxy adding watcher for certificate var/run/secrets/istio/root-cert.pem
2020-10-16T01:59:10.540896Z info Starting proxy agent
2020-10-16T01:59:10.540959Z info Opening status port 15020
2020-10-16T01:59:10.540982Z info Received new config, creating new Envoy epoch 0
2020-10-16T01:59:10.541006Z info Epoch 0 starting
2020-10-16T01:59:10.612165Z info Envoy command: [-c etc/istio/proxy/envoy-rev0.json --restart-epoch 0 --drain-time-s 45 --parent-shutdown-time-s 60 --service-cluster cluster-local-gateway --service-node router~172.16.25.193~cluster-local-gateway-7784d9555d-n2xsm.istio-system~istio-system.svc.cluster.local --local-address-ip-version v4 --bootstrap-version 3 --log-format-prefix-with-location 0 --log-format %Y-%m-%dT%T.%fZ %l envoy %n %v -l warning --component-log-level misc:error]
2020-10-16T01:59:10.704247Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T01:59:10.762180Z warning envoy main there is no configured limit to the number of allowed active connections. Set a limit via the runtime key overload.global_downstream_max_connections
2020-10-16T01:59:11.930606Z info Envoy proxy is ready
2020-10-16T02:01:32.662217Z warning envoy config StreamAggregatedResources gRPC config stream closed: 0,
2020-10-16T02:01:32.752377Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:01:40.453017Z info sds resource:ROOTCA new connection
2020-10-16T02:01:40.453208Z info sds Skipping waiting for gateway secret
2020-10-16T02:01:40.453539Z info sds resource:default new connection
2020-10-16T02:01:40.453710Z info sds Skipping waiting for gateway secret
2020-10-16T02:01:40.761638Z info cache Root cert has changed, start rotating root cert for SDS clients
2020-10-16T02:01:40.761678Z info cache GenerateSecret default
2020-10-16T02:01:40.762136Z info sds resource:default pushed key/cert pair to proxy
2020-10-16T02:01:41.053775Z info cache Loaded root cert from certificate ROOTCA
2020-10-16T02:01:41.054160Z info sds resource:ROOTCA pushed root cert to proxy
2020-10-16T02:05:50.337840Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.endpoint.v3.ClusterLoadAssignment: context deadline exceeded
2020-10-16T02:05:50.338244Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:05:50.537126Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:05:50.551713Z warn xdsproxy upstream terminated with unexpected error rpc error: code = Unknown desc = missing node ID
2020-10-16T02:05:50.552076Z warning envoy config StreamAggregatedResources gRPC config stream closed: 0,
2020-10-16T02:05:51.339141Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:05:51.354765Z warning envoy config StreamAggregatedResources gRPC config stream closed: 0,
2020-10-16T02:05:51.354302Z warn xdsproxy upstream terminated with unexpected error rpc error: code = Unknown desc = missing node ID
2020-10-16T02:05:51.755568Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:05:51.771284Z warn xdsproxy upstream terminated with unexpected error rpc error: code = Unknown desc = missing node ID
2020-10-16T02:05:51.773622Z warning envoy config StreamAggregatedResources gRPC config stream closed: 0,
2020-10-16T02:05:54.637499Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:06:13.117863Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: context deadline exceeded
2020-10-16T02:06:13.118289Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:06:13.142508Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:06:23.907216Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: context deadline exceeded
2020-10-16T02:06:23.907650Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:06:24.309467Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:06:33.504522Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.endpoint.v3.ClusterLoadAssignment: context deadline exceeded
2020-10-16T02:06:33.505244Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:06:33.805966Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:06:33.821603Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: EOF
2020-10-16T02:06:33.822146Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, EOF
2020-10-16T02:06:33.960974Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:06:48.876198Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: context deadline exceeded
2020-10-16T02:06:48.876862Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:06:49.261012Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:07:01.977933Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.endpoint.v3.ClusterLoadAssignment: context deadline exceeded
2020-10-16T02:07:01.978379Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:07:02.264945Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:07:02.284377Z warn xdsproxy upstream terminated with unexpected error rpc error: code = Unknown desc = missing node ID
2020-10-16T02:07:02.284887Z warning envoy config StreamAggregatedResources gRPC config stream closed: 0,
2020-10-16T02:07:02.557491Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:07:12.701594Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.endpoint.v3.ClusterLoadAssignment: context deadline exceeded
2020-10-16T02:07:12.702022Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:07:12.781184Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:07:12.793431Z warn xdsproxy upstream terminated with unexpected error rpc error: code = Unknown desc = missing node ID
2020-10-16T02:07:12.793853Z warning envoy config StreamAggregatedResources gRPC config stream closed: 0,
2020-10-16T02:07:13.633206Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:07:21.360882Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: context deadline exceeded
2020-10-16T02:07:21.361257Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:07:21.463948Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:07:21.481547Z warn xdsproxy upstream terminated with unexpected error rpc error: code = Unknown desc = missing node ID
2020-10-16T02:07:21.481944Z warning envoy config StreamAggregatedResources gRPC config stream closed: 0,
2020-10-16T02:07:22.130888Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:07:31.700642Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: context deadline exceeded
2020-10-16T02:07:31.700961Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:07:32.195510Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:07:32.206918Z warn xdsproxy upstream terminated with unexpected error rpc error: code = Unknown desc = missing node ID
2020-10-16T02:07:32.207349Z warning envoy config StreamAggregatedResources gRPC config stream closed: 0,
2020-10-16T02:07:32.752441Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:07:42.104987Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.endpoint.v3.ClusterLoadAssignment: context deadline exceeded
2020-10-16T02:07:42.105887Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:07:42.450481Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:07:53.096206Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: context deadline exceeded
2020-10-16T02:07:53.096929Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:07:53.142537Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:08:02.628500Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.endpoint.v3.ClusterLoadAssignment: context deadline exceeded
2020-10-16T02:08:02.628996Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:08:02.796967Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:08:02.808092Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: EOF
2020-10-16T02:08:02.808398Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, EOF
2020-10-16T02:08:03.585190Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:08:10.468927Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: context deadline exceeded
2020-10-16T02:08:10.469354Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:08:10.737844Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:08:23.498743Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.endpoint.v3.ClusterLoadAssignment: context deadline exceeded
2020-10-16T02:08:23.499086Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:08:23.634624Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:08:23.645854Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: EOF
2020-10-16T02:08:23.646124Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, EOF
2020-10-16T02:08:24.457364Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:08:32.011835Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.endpoint.v3.ClusterLoadAssignment: context deadline exceeded
2020-10-16T02:08:32.012211Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:08:32.328237Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:08:32.347338Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.route.v3.RouteConfiguration: EOF
2020-10-16T02:08:32.347873Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, EOF
2020-10-16T02:08:32.532117Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:08:43.348588Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: context deadline exceeded
2020-10-16T02:08:43.349840Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:08:43.767588Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:08:43.783923Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: EOF
2020-10-16T02:08:43.793767Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, EOF
2020-10-16T02:08:44.646502Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:08:54.518489Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: context deadline exceeded
2020-10-16T02:08:54.518956Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:08:54.861155Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:08:54.876616Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.route.v3.RouteConfiguration: EOF
2020-10-16T02:08:54.876913Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, EOF
2020-10-16T02:08:55.426009Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:08:55.438543Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.route.v3.RouteConfiguration: EOF
2020-10-16T02:08:55.438969Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, EOF
2020-10-16T02:08:55.749592Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:09:07.077497Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: context deadline exceeded
2020-10-16T02:09:07.077845Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:09:07.452948Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:09:16.737625Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: context deadline exceeded
2020-10-16T02:09:16.738134Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:09:17.226769Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:09:28.013763Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: context deadline exceeded
2020-10-16T02:09:28.014242Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:09:28.518022Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:09:28.539090Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, EOF
2020-10-16T02:09:28.538501Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: EOF
2020-10-16T02:09:28.665306Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:09:38.342405Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: context deadline exceeded
2020-10-16T02:09:38.343334Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:09:38.452084Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:09:47.903154Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.endpoint.v3.ClusterLoadAssignment: context deadline exceeded
2020-10-16T02:09:47.903629Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:09:48.270553Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:09:55.191934Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.endpoint.v3.ClusterLoadAssignment: context deadline exceeded
2020-10-16T02:09:55.192325Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:09:55.417107Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:10:06.580845Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: context deadline exceeded
2020-10-16T02:10:06.588265Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:10:06.721196Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:10:06.735185Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: EOF
2020-10-16T02:10:06.743370Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, EOF
2020-10-16T02:10:06.753241Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:10:06.765139Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: EOF
2020-10-16T02:10:06.765976Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, EOF
2020-10-16T02:10:07.825729Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:10:07.838217Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: EOF
2020-10-16T02:10:07.838659Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, EOF
2020-10-16T02:10:08.093584Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:10:20.725233Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: context deadline exceeded
2020-10-16T02:10:20.726134Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:10:21.210759Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:10:32.535086Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: context deadline exceeded
2020-10-16T02:10:32.535685Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:10:32.702306Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:10:42.743780Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.endpoint.v3.ClusterLoadAssignment: context deadline exceeded
2020-10-16T02:10:42.747799Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:10:42.871380Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:10:44.883015Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: EOF
2020-10-16T02:10:44.883439Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, EOF
2020-10-16T02:10:44.918183Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:10:55.504787Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.endpoint.v3.ClusterLoadAssignment: context deadline exceeded
2020-10-16T02:10:55.505319Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:10:55.980198Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:10:56.003653Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: EOF
2020-10-16T02:10:56.004313Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, EOF
2020-10-16T02:10:56.705362Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:10:56.718653Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: EOF
2020-10-16T02:10:56.718952Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, EOF
2020-10-16T02:10:58.509699Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:11:08.302624Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: context deadline exceeded
2020-10-16T02:11:08.309887Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:11:08.685218Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:11:22.053007Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.endpoint.v3.ClusterLoadAssignment: context deadline exceeded
2020-10-16T02:11:22.053573Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:11:22.065630Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:11:22.085065Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: EOF
2020-10-16T02:11:22.085492Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, EOF
2020-10-16T02:11:22.888449Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:11:22.903391Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: EOF
2020-10-16T02:11:22.903723Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, EOF
2020-10-16T02:11:23.922501Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:11:23.944882Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: EOF
2020-10-16T02:11:23.945110Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, EOF
2020-10-16T02:11:25.938535Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:11:34.856782Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.endpoint.v3.ClusterLoadAssignment: context deadline exceeded
2020-10-16T02:11:34.857508Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:11:35.268599Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:11:35.284864Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: EOF
2020-10-16T02:11:35.285411Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, EOF
2020-10-16T02:11:36.167629Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:11:36.184562Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: EOF
2020-10-16T02:11:36.185092Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, EOF
2020-10-16T02:11:37.444697Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:11:37.460650Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: EOF
2020-10-16T02:11:37.461317Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, EOF
2020-10-16T02:11:38.378750Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:11:49.352330Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: context deadline exceeded
2020-10-16T02:11:49.352691Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:11:49.693715Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:11:49.716645Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: EOF
2020-10-16T02:11:49.717241Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, EOF
2020-10-16T02:11:50.134543Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:12:01.908816Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: context deadline exceeded
2020-10-16T02:12:01.909203Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:12:01.947033Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:12:11.975901Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: context deadline exceeded
2020-10-16T02:12:11.976231Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, context deadline exceeded
2020-10-16T02:12:12.348237Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:12:12.384905Z error xdsproxy upstream send error for type url type.googleapis.com/envoy.config.listener.v3.Listener: EOF
2020-10-16T02:12:12.385237Z warning envoy config StreamAggregatedResources gRPC config stream closed: 2, EOF
2020-10-16T02:12:13.231978Z info xdsproxy connecting to istiod.istio-system.svc:15012
2020-10-16T02:12:13.256439Z warning envoy main caught SIGTERM
The SIGTERM was caused by the OOMkiller:
State: Running
Started: Fri, 16 Oct 2020 02:12:13 +0000
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
Started: Fri, 16 Oct 2020 01:59:10 +0000
Finished: Fri, 16 Oct 2020 02:12:13 +0000
Hilarious exit code - actually my license plate...
During the test I displayed the push time in milliseconds:
sdake@scale-cp:~$ kubectl logs -n istio-system istiod-66b44bd5cb-m8zxz | grep duration | cut -d: -f 4 | sort -bg | tail -20
5307
5310
5344
5365
5370
5386
5390
5456
5481
5492
5544
5569
5576
5627
5769
5855
5857
5870
6065
6227
clicked wrong button ^^
sdake
on 16 Oct 2020
I am not sure how send timeout is helping here - are we saying some times the config is lost/dropped because of low timeouts?
 ramaraochavali
on 16 Oct 2020
ramaraochavali
on 16 Oct 2020
when the connection is dropped because of the 5 second send timeout, the system falls over. Under heavy services churn, the proxy enters a super-overloaded state where it can take 200-800 seconds to recover - see: https://github.com/istio/istio/issues/25685#issuecomment-668488995.
Yes, that is what I am saying.
sdake
on 17 Oct 2020
These results are better - although ADS continues to disconnect and Envoy OOMs: https://github.com/istio/istio/issues/28192. I do feel like this is the first attempt of a PR that manages the numerous constraints of the protocol implementation

.
sdake
on 22 Oct 2020
Got a profile of envoy during high XDS pushes
envoy.prof.gz
20% of time in MessageUtil::validate
20% of time in MessageUtil::hash
Another 15% in RdsRouteConfigProviderImpl::validateConfig. It looks like this is doing 2x the work as part of RdsRouteConfigSubscription::onConfigUpdate
howardjohn
on 26 Oct 2020
@howardjohn It is great to have PR to fix the issue. What is the target release for this PR ? Thank you.
ZhuangYuZY
on 29 Oct 2020
Related issues
 Stono
·
93Comments
Stono
·
93Comments
 kovalyukm
·
63Comments
kovalyukm
·
63Comments
 hzxuzhonghu
·
96Comments
Stono
·
92Comments
Stono
·
65Comments
hzxuzhonghu
·
96Comments
Stono
·
92Comments
Stono
·
65Comments
Most helpful comment
Here are some test results with tuning for
PILOT_DEBOUNCE_AFTERparameter. I tested usingPILOT_DEBOUNCE_MAX = 10sthe 1st round I tested with a total of 800 ksvcs, the result is as following. The result is a lot better compares to the default value 100ms. There are no sudden jumps around ~200 indices. But I noticed the ready time increases to ~50s at the end of test. So I did another test to increase the total ksvc count to 1400.
We can tell that the similar sudden jumps happens after index 800. So I assume that the longer

PILOT_DEBOUNCE_AFTERwill alleivate the stress for configuring envoy. But it will not solve the issue completely.The first round tests for 800 ksvcs most of the ready time is around 13s. Which is the first probe after 10s in knative.
Below is the result for total 1400 ksvcs. With the debounce time setting to 10s the result after 800 became stable again. I suspect that as the total ksvc count grows, we will hit the sudden increasing again.