Istio: Envoy shutting down before the thing it's wrapping can cause failed requests
Hey folks,
We're seeing some brief issues when deploying applications, we've narrowed it down to the fact that under a normal shutdown process, both envoy and the application it is wrapping get their SIGTERM at the same time.
Envoy will drain and shut down, but if the other application is still doing anything as part of its shutdown process, and attempts to make an outbound connection AFTER envoy has shut down, it'll fail because the IPTables rules are sending traffic to a non-existent envoy. For example:
- envoy and application1 get SIGTERM
- envoy drains, there are no connections at the moment so this is almost instant
- application1 tries to tell application2 that it's going offline, because that's what it does, and that fails as theres now no envoy
I've a rather hacky work around, and that is we add a lifecycle hook to istio-proxy, which blocks the shutdown until there are no other tcp listeners (thus, half heartedly ensuring our other service has terminated before envoy starts to terminate).
containers:
- name: istio-proxy
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "while [ $(netstat -plunt | grep tcp | grep -v envoy | wc -l | xargs) -ne 0 ]; do sleep 1; done"]
I guess this kind of falls into the lifecycle conversations we've been having recently (in https://github.com/istio/istio/issues/6642), and it highlights how we need to give consideration to both startup, and shutdown in order to have non-service impacting deployments when using the default kubernetes RollingUpdate when using Istio.
I'm wondering if you can think of a nicer that this could be accommodated. Basically envoy needs to stay up until the thing its wrapping has exited. A process check would be better still because the above hack only works when application1 is exposing a tcp listener - but istio-proxy cannot see the process list of the other containers (unless you can think of some way to do this?).
Karl
 Stono
Stono
All 65 comments
if k8s supported container dependencies, it would be a lot easier..
 rshriram
on 17 Jul 2018
rshriram
on 17 Jul 2018
Crosslinking https://github.com/istio/istio/issues/7665 as they're both related to seamless rollouts
Stono
on 6 Aug 2018
I've got a related feature request on k8s that I just linked. It's starting to feel like k8s needs container dependencies.
 nmittler
on 7 Aug 2018
nmittler
on 7 Aug 2018
This issue has been automatically marked as stale because it has not had activity in the last 90 days. It will be closed in the next 30 days unless it is tagged "help wanted" or other activity occurs. Thank you for your contributions.
![stale[bot] picture](https://avatars3.githubusercontent.com/in/1724?v=4&s=40) stale[bot]
on 6 Nov 2018
stale[bot]
on 6 Nov 2018
We handle this in the most hacky way possible...
Our istio-proxy has a preStop hook which fires this script:
#!/bin/bash
set -e
echo "Exit signal received, waiting for all network connections to clear..."
while [ $(netstat -plunt | grep tcp | grep -v envoy | wc -l | xargs) -ne 0 ]; do
printf "."
sleep 3;
done
echo "Network connections cleared, shutting down pilot..."
exit 0
Basically waits for any non envoy ports to stop listening before envoy itself shuts down.
Stono
on 26 Nov 2018
I feel like envoy (or rather the whole proxy) should stay up until all connections it proxies are drained (or the terminationGrace expires). That'd automatically keep it up until the downstream application has shut down itself.
Also related #10112
 markusthoemmes
on 11 Jan 2019
markusthoemmes
on 11 Jan 2019
OK, looking to get this closed out. To summarise the various issues I have seen w.r.t. this...
In Kubernetes, all containers in a pod are sent SIGTERM at the same time. This means Envoy often gets killed before the application it is serving. This causes the following issues:
- Any open TCP connections (inbound and outbound) with the application get severed when Envoy terminates.
- Any new outbound TCP connections that may be required by the application to clean up after itself are unable to be created because Envoy has been terminated.
Here are a couple of potential solutions mentioned across various similar issues:
Call Envoy's /healthcheck/fail endpoint on SIGTERM, wait for Envoy to drain or Kube grace period (whichever comes first).
Depending on how we configure the HTTP filter, this will cause the terminating Envoy to start returning 503s to indicate that it is draining. The client's outlier detection should then boot it out of the load balancing pool.
Things this solves:
- Prevents any new inbound requests when terminating.
- If all connections are terminated within the Kube grace period then there will be no severed connections.
Things this doesn't solve:
- There is no concept of waiting until it's finished draining in Envoy (https://github.com/envoyproxy/envoy/issues/2920), we would need to contribute this.
- This is an HTTP filter so would not handle all TCP cases.
- This prevents any outbound requests needed for application clean up during this time as well.
Client side Envoy removes idle connections to endpoints dropped from EDS
Things this solves:
- No severed connections.
- Ability to create new connections during application clean up.
Potential issues:
- This would need to be done all in Envoy.
- May be difficult or not possible with Envoy's architecture? (speculation).
Wait for Kubernetes to add sidecar container lifecycles.
See this proposal.
tl;dr: pod lifecycle will change to this:
- Init containers start
- Init containers finish
- Sidecars start
- Containers start
- Containers sent SIGTERM
- Once all Containers have exited: Sidecars sent SIGTERM.
So once the application is terminated Envoy will start sending 503s anyway and trigger client outlier detection.
Things this solves:
- No severed connections.
- Ability to create new connections during application clean up.
Potential issues:
- No idea when this is likely to be implemented.
- Only solves for Kube environments.
 liamawhite
on 21 Jan 2019
liamawhite
on 21 Jan 2019
cc @hzxuzhonghu @elevran @ZackButcher @lizan @costinm @duderino @rosenhouse
liamawhite
on 21 Jan 2019
Call Envoy's /healthcheck/fail endpoint on SIGTERM, wait for grace period, Kube SIGKILLs.
+1
 hzxuzhonghu
on 21 Jan 2019
hzxuzhonghu
on 21 Jan 2019
Call Envoy's /healthcheck/fail endpoint on SIGTERM, wait for grace period, Kube SIGKILLs.
+1
 donina
on 21 Jan 2019
donina
on 21 Jan 2019
Until envoy itself supports a "wait until done" kind of behavior, could we use @Stono's hack above to find out when envoy is done? Waiting until the terminationGrace is over can be a loooooong time.
markusthoemmes
on 21 Jan 2019
Yeah you don't wanna wait until termimationGracePeriod has passed as some of our apps have multiple hours on the off chance they're hitting a batch half way through - but the vast majority of the time they are not. We would want the shutdown to be as fast as possible so as not to slow down rollingUpdates.
Stono
on 21 Jan 2019
When to actually terminate would be left up to choice, there's nothing stopping you from terminating it if after 30 seconds Envoy is still draining.
liamawhite
on 22 Jan 2019
It's just the way the suggestion said to "wait for the termination period"
I read that as it'll wait for the whole duration regardless
On Tue, 22 Jan 2019, 8:15 am Liam White <[email protected] wrote:
When to actually terminate would be left up to choice. There's nothing
stopping you from terminating if, after 30 seconds, Envoy is still draining
you can just kill it anyway.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/istio/istio/issues/7136#issuecomment-456308144, or mute
the thread
https://github.com/notifications/unsubscribe-auth/ABaviZ5AvC3yDPbj9H-CHmKPyA8TzO4Tks5vFsiMgaJpZM4VQSVS
.
Stono
on 22 Jan 2019
Will do some better English 🙃
liamawhite
on 22 Jan 2019
Haha sorry, just wanted to be super clear
On Tue, 22 Jan 2019, 8:29 am Liam White <[email protected] wrote:
Will do some better English 🙃
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/istio/istio/issues/7136#issuecomment-456311973, or mute
the thread
https://github.com/notifications/unsubscribe-auth/ABavibFAF916S8DTO12PyjcVXT4rgOLiks5vFsvdgaJpZM4VQSVS
.
Stono
on 22 Jan 2019
Can both
Call Envoy's /healthcheck/fail endpoint on SIGTERM, wait for Envoy to drain or Kube grace period (whichever comes first).
and
Client side Envoy removes idle connections to endpoints dropped from EDS
be done? They seem orthogonal and addressing slightly different aspects.
 elevran
on 22 Jan 2019
elevran
on 22 Jan 2019
If I recall correctly, On Cloud Foundry we’ve implemented a variant where we have the server side Envoy rotate the TLS cert on its ingress listener, to become a bad cert. That causes clients to reject the backend when attempting new connections, while preserving existing connections that are draining. It has the advantage of working for non-HTTP protocols.
Cc @emalm to keep me honest.
 rosenhouse
on 22 Jan 2019
rosenhouse
on 22 Jan 2019
@luksa Set to P1 to address remaining CNI issues #11366
 munrodg
on 19 Feb 2019
munrodg
on 19 Feb 2019
I think I had a relevant discussion in another issue(https://github.com/istio/istio/issues/12183#issuecomment-475537762).
Even if the sidecar envoy collocated to the terminating app container stopped gracefully, the other envoys sending traffic to the terminating pods can still see errors. That's because there's no practical way to make the terminating pod/sidecar to wait until the "client" envoy notices and stops sending traffic to it, in this world of eventual consistency.
My current thought is that, we need to add certain length of prestop sleeps to every sidecar. Hard-coding the length of prestop sleeps like #12342 won't work, especially if we have to do that for all the istio proxy containers across the mesh though.
 mumoshu
on 22 Mar 2019
mumoshu
on 22 Mar 2019
@mumoshu In most cases you can. Because once you start to delete the pod, it will be removed from the endpoint list then no more requests are being sent to this termination pod. After certain time(30s, 40s), Envoy finish processing the lingering request, then it can be shut down.
For persistent connections, the problem exists regardless whether you are using istio or not.
 iandyh
on 22 Mar 2019
iandyh
on 22 Mar 2019
@iandyh Thanks again for your response! And sorry, I'm still trying to understand.
Because once you start to delete the pod, it will be removed from the endpoint list then no more requests are being sent to this termination pod
Doesn't this take some time, in the order of a second, or a few in a high-load condition? In that case I think we still need a short, explicit prestop sleep.
Some more context - My understanding was that, even though the downstream envoy had drain_connections_on_host_removal turned on, it has no way other than retrying e.g. http requests on bad statuses(like described in https://github.com/istio/istio/issues/12183#issue-416201861) when the downstream envoy have not yet heard of removed endpoints via xDS. And we can let envoy retry only idempotent requests like GETs.
For persistent connections, the problem exists regardless whether you are using istio or not.
I was thinking that the above statement applies regardless of a connection is persistent or not. However, my intuition says here is the thing I may have misunderstood...
mumoshu
on 22 Mar 2019
Doesn't this take some time, in the order of a second, or a few in a high-load condition? In that case I think we still need a short, explicit prestop sleep.
yes, this can be easily produced during high load.
I was thinking that the above statement applies regardless of a connection is persistent or not. However, my intuition says here is the thing I may have misunderstood...
For persistent connection, the retry it's inevitable.
iandyh
on 23 Mar 2019
- When envoy starts there is a short delay until first configuration is been pushed from pilot.
- Once a pod has been terminated all its endpoints will removed. This will immediately trigger pilot to push new envoy configs.
So I think pod lifecycle have to change to this:
- Init containers start
- Init containers finish
- Sidecars start
- Envoy has to wait until first configuration is been arrived from pilot
- Once all Sidecars have started: Containers start
and back
- Sidecars has to be informed about the upcoming termination
- Envoy has to freeze the configuration to prevent upcoming pushes from pilot caused by removed endpoints
- Once all Sidecars are informed: Containers sent SIGTERM
- Once all Containers have exited: Sidecars sent SIGTERM.
 thomschke
on 29 Mar 2019
thomschke
on 29 Mar 2019
Is there an easy way to stop a running envoy instance from pulling new configs? It's possible to work around the "Sidecars start" phase issue by adding a readiness probe to whatever app is being proxied that checks connections. In the termination phase, the netstat + grep solution is good until a new config comes in and crashes the party.
If it was possible to run a shell command to stop the envoy instance from pulling new configs, Istio users would have a good lifecycle story until something more polished.
 pnovotnak
on 8 Apr 2019
pnovotnak
on 8 Apr 2019
Envoys should stop pulling config when they received SIGTERM. This period of time between stopping accepting new connections and being killed is configurable via the TERMINATION_DRAIN_DURATION_SECONDS env var in Pilot.
liamawhite
on 8 Apr 2019
 shalako
on 11 Apr 2019
shalako
on 11 Apr 2019
The only problem is that the preStop hook prevents SIGTERM (though it could be sent from there?)
pnovotnak
on 15 Apr 2019
They don't prevent it, they just delay it?
Stono
on 16 Apr 2019
Hey, we here at Monzo have open sourced our solution to this sequencing problem:
https://github.com/monzo/envoy-preflight
The idea is, it's a wrapper around your main application, which ensures it starts after envoy is live, and shuts down envoy when its done. You'll still need to prevent sigterms from reaching envoy.
 jackkleeman
on 18 Apr 2019
jackkleeman
on 18 Apr 2019
This is nice. Although, we would need some extra work to support this with Istio. This would have to drive pilot-agent instead of Envoy in Istio cases and we don't yet have an endpoint to enable this.
liamawhite
on 18 Apr 2019
Would be happy to help. Specifically are you missing the quitquitquit endpoint?
jackkleeman
on 20 Apr 2019
Quitquitquit is definitely there, I hit it in my custom scripts
On Sat, 20 Apr 2019, 12:28 pm Jack Kleeman, notifications@github.com
wrote:
Would be happy to help. Specifically are you missing the quitquitquit
endpoint?—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/istio/istio/issues/7136#issuecomment-485097466, or mute
the thread
https://github.com/notifications/unsubscribe-auth/AALK7CPYO5PTFHYB3OAQD23PRL46JANCNFSM4FKBEVJA
.
Stono
on 20 Apr 2019
@Stono When you kill the Envoy process I would expect pilot-agent to create a new Envoy process. Is this not the case? or does it not matter because the pod terminates almost instantaneously?
liamawhite
on 22 Apr 2019
@liamawhite no it doesn't appear to create a new envoy process!
Stono
on 4 Jun 2019
pilot-agent only recreates the process in some cases -- not sure exactly which but I know if you pkill envoy it won't but pkill -9 envoy will
 howardjohn
on 12 Jun 2019
howardjohn
on 12 Jun 2019
@howardjohn This is a good finding, it seems envoy will exit with 0 when receives SIGTERM, but this is absolutely not what we want,. If envoy exits, pilot-agent should restart it unless pod is terminating.
hzxuzhonghu
on 25 Jun 2019
@johnholiver @hzxuzhonghu this may be a bug, but we critically depend on the fact that pilot-agent doesn't restart envoy right now!
Should you fix it, please also implement https://github.com/istio/istio/issues/15041 at the same time or I have 20+ cronjobs that will start failing.
Stono
on 25 Jun 2019
Let me take it.
hzxuzhonghu
on 25 Jun 2019
As the use case exist: when pod existing, app may need to communicate with outside. I would suggest allowing setting grace time before agent terminate envoy.
hzxuzhonghu
on 28 Jun 2019
@Stono thx for the prestop hack, works like a charm!
 viktorvoltaire
on 5 Sep 2019
viktorvoltaire
on 5 Sep 2019
@Stono thx for the prestop hack, works like a charm!
No probs :-)
Stono
on 8 Sep 2019
Is there some recipe on how to add preStop hook to auto-injected istio-proxy sidecar?
 rvora
on 13 Sep 2019
rvora
on 13 Sep 2019
@rvora sidecar configuration is from a configmap which can be changed in the installation templates.
iandyh
on 13 Sep 2019
Thanks @iandyh. And when Istio is upgraded, our changed configmap will not be overridden?
rvora
on 13 Sep 2019
@andraxylia why was this moved to 1.4? As far as I know there are no short term fixes for this
howardjohn
on 15 Sep 2019
@rvora It depends on how your upgrade process work. In our case, we always apply the patch before installing/upgrading.
iandyh
on 17 Sep 2019
@hzxuzhonghu any update on the status of this issue? The workaround that @Stono shows here may stop working if using Istio 1.3's distroless images.
 tcnghia
on 17 Sep 2019
tcnghia
on 17 Sep 2019
@tcnghia FYI #11485
hzxuzhonghu
on 19 Sep 2019
@hzxuzhonghu I tried with 1.2.6 and 1.3.0 and still saw the issue.
I can send you a repro. We have an integration test that is really good with catching the issue.
tcnghia
on 20 Sep 2019
Could you describe exactly is the issue you see? That fix won't solve ALL issues that might occur here.
liamawhite
on 20 Sep 2019
I have some feedback to share when using a preStop hook with the following code:
preStop:
exec:
command:
- s
- -c
- sleep 20; while [ $(netstat -plunt | grep tcp | grep -v envoy | wc -l | xargs) -ne 0 ]; do sleep 1; done
My k8s deployment has:
terminationGracePeriodSecondsset to600sreadinessProbeset to some HTTP path
When deploying new pods, old pods receive the SIGTERM signal and start to shutdown gracefully. The terminationGracePeriodSeconds will keep the pods around in a Terminating state where we can see that the wrapped container has shutdown but not istio-proxy:
NAME↑ IMAGE READY STATE RS PROBES(L:R)
httpbin kennethreitz/httpbin false Running 0 off:on
istio-init gke.gcr.io/istio/proxy_init:1.1.13-gke.0 true Completed 0 off:off
istio-proxy gke.gcr.io/istio/proxyv2:1.1.13-gke.0 true Running 0 off:on
The wrapped container (httpbin here) is now shut down but the readiness probe setup will continue to send HTTP requests through the istio-proxy resulting in 503 response code:
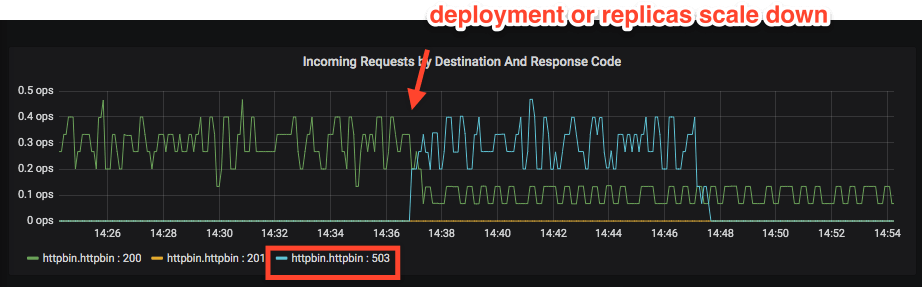
I had enough time to ssh into the running istio-proxy and run its preStop cmd:
istio-proxy@httpbin-66b967d895-fl2df:/$ netstat -plunt | grep tcp
tcp 0 0 0.0.0.0:15090 0.0.0.0:* LISTEN 19/envoy
tcp 0 0 127.0.0.1:15000 0.0.0.0:* LISTEN 19/envoy
tcp 0 0 0.0.0.0:15001 0.0.0.0:* LISTEN 19/envoy
tcp6 0 0 :::15020 :::* LISTEN 1/pilot-agent
Looks like pilot-agent connection will stay open forever which prevents the preStop hook configured on istio-proxy container to shut down properly the container.
I'm currently not sure what's the best approach to solve this issue.
 gottfrois
on 31 Oct 2019
gottfrois
on 31 Oct 2019
@gottfrois what Istio version are you running? I think pilot-agent isn't handling SIGTERM correctly in your case.
liamawhite
on 31 Oct 2019
@liamawhite IIUC the draining logic in pilot-agent won't kick in during a preStop hook, since it relies on the SIGTERM which will occur after the preStop runs. So I guess the preStop would have to manually drain envoy via https://www.envoyproxy.io/docs/envoy/latest/operations/admin#post--drain_listeners? Do you know of any limitations with draining Envoy in this manner? I seem to recall you mentioning that it might only work for HTTP?
nmittler
on 31 Oct 2019
@nmittler drain_listeners was added by @ramaraochavali very recently (week or so maybe?). I think what we can probably do now is to use that draining rather than our original approach of hot restarting with an empty config. So we get SIGTERM, call /drain_listeners, wait X seconds, then exit.
If preStop doesn't send any signal to the app, then the preStop hook would do that
We could also just ship a default preStop hook that does that and then not do anything within pilot-agent?
Would have to test all of this out though, this is just based on my understanding which may not be how it actually behaves
howardjohn
on 31 Oct 2019
Please don't change things in the shutdown!
The example being used above is wrong. A pre stop blocks pilot agent from ever getting the sigint if it runs forever, so of course it will listen forever.
I am on 1.3.3 and confirm pilot agent works exactly as it should do. It isn't broken?
Stono
on 31 Oct 2019
To be clear my original issue is not really an istio problem, more of a kubernetes container ordering problem that's just exacerbated by istio. As two containers within the same pod will receive the SIGTERM at the same time, there is no logic around guaranteeing that pilot-agent doesn't exit after your app (and stop accepting new outbound connections) which means that if your application has some shutdown logic which involves creating new connections, they can fail if pilot-agent has already exited (because the iptables rules will be routing it to nothing).
My work around is more of a kubernetes work around, than an istio one, in that i have a prestop hook block the SIGTERM from getting to pilot-agent until (via a relatively crude check) there are no other ports (owned by my application) listening in the pod - as a signal the app has exited. It is by no means perfect and designed to be a stop gap until a better way to handle the problem surfaces.
As a side note, the second a pod is terminated it enters the TERMINATING state which removes it from the service endpoints, and thus eventually consistent downstream envoys sending traffic to it.
If you're getting 10 minutes of 503's, there's something here wrong here that is different to my original post, as that pod shouldn't be getting any traffic at all.
Honestly, so long as pilot-agent and envoy drain their connections correctly (which I believe they do) and envoy will continue to accept new outbound connections during its shutdown phase (which i'm unsure about), there isn't much more that istio can do.
Stono
on 31 Oct 2019
@Stono
Please don't change things in the shutdown!
Just to be clear, you're just warning that people should not to use preStop handlers, right?
I expect you wouldn't be against the change suggested by @howardjohn regarding use of the new envoy drain endpoint, since it would just be a replacement for the current draining logic in the pilot_agent.
nmittler
on 31 Oct 2019
Just against Istio shipping with one by default, we use that pre stop hook to handle container orchestration within a pod.
On Thu, 31 Oct 2019, 17:31 Nathan Mittler, notifications@github.com wrote:
@Stono https://github.com/Stono
Please don't change things in the shutdown!
Just to be clear, you're just warning that people should not to use
preStop handlers, right?I expect you wouldn't be against the change suggested
https://github.com/istio/istio/issues/7136#issuecomment-548429291 by
@howardjohn https://github.com/howardjohn regarding use of the new
envoy drain endpoint, since it would just be a replacement for the current
draining logic in the pilot_agent.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/istio/istio/issues/7136?email_source=notifications&email_token=AALK7COJPUTYBCXIOQ7SQNTQRMI5TA5CNFSM4FKBEVJKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOECYTQZA#issuecomment-548485220,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AALK7CIU5WFKH7XO6SCFPEDQRMI5TANCNFSM4FKBEVJA
.
Stono
on 31 Oct 2019
@Stono sure makes sense. I wouldn't expect this would ever be a default for (I'm sure) a variety of reasons.
nmittler
on 31 Oct 2019
Also I'm struggling to see what we are trying to fix with this convo. Changing to a prestop hook that triggers a drain Vs the current behaviour of catching sigterm and draining doesn't feel like it solves anything?
Unless I'm missing a trick!
There's a few things that I know cause issues:
- upstream envoy stopping accepting connections before downstream envoy is updated with the termination (which is why an arbitrary prestop with a sleep of 10s helps)
- upstream envoy not accepting new outbound connections when shutting down (which is why the hacky wait script helps)
Stono
on 31 Oct 2019
I actually propose closing off this issue and creating new ones for the specific separate issues that people are reporting on here as it's become a bit of a dumping ground for any old shut down/drain/eventual consistency issue 😂
It's over a year old!
Stono
on 31 Oct 2019
Agreed, this issue has overstayed its welcome :).
Karl, do we already have separate issues tracking the specific problems you see?
nmittler
on 31 Oct 2019
Not sure. Will have a hunt around tomorrow and tbh validate what is even still an issue.
Stono
on 31 Oct 2019
@Stono Im running your script and the istio-proxy seems to stay alive, but the connection to my application seem to die anyways after about 1m. Is there something else I need to tweak?
 presidenten
on 23 Apr 2020
presidenten
on 23 Apr 2020
Related issues
 oaktowner
·
73Comments
oaktowner
·
73Comments
 lanceliuu
·
82Comments
hzxuzhonghu
·
96Comments
Stono
·
92Comments
lanceliuu
·
82Comments
hzxuzhonghu
·
96Comments
Stono
·
92Comments
 hamon-e
·
59Comments
hamon-e
·
59Comments
Most helpful comment
if k8s supported container dependencies, it would be a lot easier..