Openrefine: XML import merges records together
_Original author: iainsproat (September 22, 2010 10:02:42)_
Imported a small Xml file but the project, attached, can not be displayed in the browser. The browser complains of unresponsive script on various lines of project-bundle.js (lines 52, 29, 40 & 109 have been indicated at various stages).
The unresponsive script seems to be happening after the GET response for /scripts/views/data-table/column-header.html
_Original issue: http://code.google.com/p/google-refine/issues/detail?id=137_
 tfmorris
tfmorris
All 33 comments
_From [email protected] on September 28, 2010 04:46:40:_
Iain, I can't import the project attached. It appears to be corrupted. Could you export just the data?
tfmorris
on 15 Oct 2012
_From iainsproat on September 28, 2010 08:20:20:_
Attached is the original data file I imported.
ClinicalTrials.gov only outputs in individual xml files (see issue #131), so I had an external script stitch them into a single xml file.
tfmorris
on 15 Oct 2012
_From [email protected] on September 28, 2010 19:18:38:_
I can repro the bug, although I haven't figured out how to fix it. Exporting the data as HTML table works--all the records seem to be there. But inside Refine, only the first 2 records are shown. I guess the JSON stream got cut off? Which is weird because that would cause a syntax error.
tfmorris
on 15 Oct 2012
_From tfmorris on November 27, 2010 22:14:19:_
Attached is a smaller version of the file which should make debugging a little easier.
Part of the problem was the multi-line text elements were confusing the parser, but I've just committed a change that should fix that piece. It's still splitting a single record into multiple rows when it shouldn't be. I'll take a look and see why.
As an aside, I think the reason the browser goes berserk is that it's trying to deal with a large number of null cells. Fixing the project import will probably solve this, but someone who's got stronger Javascript fu than I might want to take a look at whether there's another problem lurking there.
tfmorris
on 15 Oct 2012
_From tfmorris on October 14, 2011 18:49:13:_
I think I've figured out what the problem is here. The column groups for this XML fragment are getting computed incorrectly:
Refine is currently computing three column groups from this: lead_sponsor (2 columns), collaborator (2 columns), and sponsor (all 4 columns). This last group is triggering unnecessary row dependencies when there is no collaborator element.
I'm tempted to say that column groups which consist of nothing but other groups, without any individual ungrouped columns of their own should be eliminated, but it's a fairly critical piece of code, so I want to look at it a little more closely.
p.s. I suspect the reason for the sluggish browser performance is that it was trying to deal with the entire file at once since the monster second record effectively disabled the paging.
tfmorris
on 15 Oct 2012
_From tfmorris on October 27, 2011 00:04:03:_
Reversing course, I now think that perhaps we should be computing row->record dependencies directly since we have that information from the parse. We know what the path to the top level element is and, by definition, all rows that we create during the parse of its children are part of the same record.
Visually the column groups look like this:
Col # 2222333344445555
Sponsor group SSSSSSSSSSSSSSSS
Lead/Collab CCCCccccLLLLllll
The three groups are group S, group Cc, and group Ll.Note that the columns have been reordered with the Collaborator columns before the Lead columns. Group S is the problematic one. Since the Collaborator sponsors are optional, that means that the "key" column # 2 can be blank for a top level record, causing it to get merged with the previous record (the algorithm searches back for a row with a non-blank "key" cell if any of the cells in the column group are non-blank).
Group S is a real column group (consisting solely of other column groups), but since we don't appear to use column groups for anything, I'm not sure what value it has.
I think there are two options here:
- Eliminate column groups which consist solely of other column groups from the dependency analysis
- Compute row dependencies using a different method than column groups (eg use the tree structure directly from the parse).
Opinions?
tfmorris
on 15 Oct 2012
_From tfmorris on October 28, 2011 19:56:34:_
This is fixed, at least well enough for this example, with r2347. The cell data counts weren't getting updated before sorting the column groups, causing them all to be zero which meant data rich columns weren't getting place where Refine needed them to be for the key column.
I think there's still an underlying issue where the current counting strategy can get fooled into choosing the wrong column. For example if Column A is mandatory but never has more than a single value and Column B values are optional, but high frequency (e.g. 50% of the records, but every record has 3 values, giving it 1.5x the number of cells as column A), then column B will get chosen in preference to column A.
There's also the case where no single column in a column group always has a value (e.g. a column group where either column A OR column B is populated for any given record).
tfmorris
on 15 Oct 2012
_From tfmorris on November 06, 2011 21:14:59:_
Reopening. The theoretical issue that I suspected has been confirmed in the wild by a new XML file received from a commenter on issue #393, so we're going to need a different approach to dealing with column groups.
tfmorris
on 15 Oct 2012
_From tfmorris on November 06, 2011 21:26:19:_
issue #393 has been merged into this issue.
tfmorris
on 15 Oct 2012
_From tfmorris on December 12, 2011 19:56:00:_
Bump all unfinished 2.5 Milestone tags to next release
tfmorris
on 15 Oct 2012
_From emilytgriffiths on April 13, 2012 14:56:10:_
Hello all,
Outside user, working to clean-up someone else's messy server. After importing three .csv files that total 5019 records in length, I delete the the 'file' column as it is not needed. The record count then abates to 1333. I do not have any facets selected. When attempting click around and discover the source of the problem, Firefox tells me that I have an unresponsive script:
http://127.0.0.1:3333/project-bundle.js:7973
And asks me if I wish to continue or not. If I continue, it will eventually ask me again. If I stop the script, it will crash the tab I am running Refine in.
I converted my original .csv files into .tsv format, and reopened them in Refine. This solved my issue.
Quirky little bug with a simple workaround for those of you out there in Userland that are not quite up to speed in programing languages.
tfmorris
on 15 Oct 2012
_From tfmorris on April 13, 2012 16:58:55:_
Since you're working with CSV, not XML, it's clearly not related to this bug. Please feel free to post on Google Refine mailing list if you'd like assistance. It sounds like you probably had a mostly blank initial column in one or more of your CSVs. You can either process it in "row" mode (instead of "record" mode) or shuffle the columns around so it's not an issue.
tfmorris
on 15 Oct 2012
_From [email protected] on June 11, 2012 11:24:57:_
Could someone provide a pointer on how does the record detection exactly work? Is it import-time, or runtime? Where can I find the code responsible for this?
When I provide a properly structured xml, it merges some of the records into one, but I can't see any features that distinguish those records from the others... I'd like to look at the source of the problem, but currently have no idea where to look.
I'm attaching the offending xml.
Thanks
tfmorris
on 15 Oct 2012
_From tfmorris on June 12, 2012 20:15:51:_
Clicking the rev above that I used to repair part of the problem (r2347) will get you in the right ballpark. The XML and JSON importers are in the "tree-shaped" importer family.
ImportColumnGroup is the class which manages the column groups that are used to determine dependent rows/records. Anything that references it is probably involved. TreeImportUtilities and XmlImportUtilities have methods which are used with this.
Hope that helps get you started. Let us know on the dev list if you have any questions.
tfmorris
on 15 Oct 2012
_From iainsproat on September 28, 2010 08:20:20:_
Attached is the original data file I imported.
ClinicalTrials.gov only outputs in individual xml files (see issue #131), so I had an external script stitch them into a single xml file.
tfmorris
on 15 Oct 2012
_From tfmorris on October 27, 2011 00:04:03:_
Reversing course, I now think that perhaps we should be computing row->record dependencies directly since we have that information from the parse. We know what the path to the top level element is and, by definition, all rows that we create during the parse of its children are part of the same record.
Visually the column groups look like this:
Col # 2222333344445555
Sponsor group SSSSSSSSSSSSSSSS
Lead/Collab CCCCccccLLLLllll
The three groups are group S, group Cc, and group Ll.Note that the columns have been reordered with the Collaborator columns before the Lead columns. Group S is the problematic one. Since the Collaborator sponsors are optional, that means that the "key" column # 2 can be blank for a top level record, causing it to get merged with the previous record (the algorithm searches back for a row with a non-blank "key" cell if any of the cells in the column group are non-blank).
Group S is a real column group (consisting solely of other column groups), but since we don't appear to use column groups for anything, I'm not sure what value it has.
I think there are two options here:
- Eliminate column groups which consist solely of other column groups from the dependency analysis
- Compute row dependencies using a different method than column groups (eg use the tree structure directly from the parse).
Opinions?
tfmorris
on 15 Oct 2012
_From tfmorris on October 28, 2011 19:56:34:_
This is fixed, at least well enough for this example, with r2347. The cell data counts weren't getting updated before sorting the column groups, causing them all to be zero which meant data rich columns weren't getting place where Refine needed them to be for the key column.
I think there's still an underlying issue where the current counting strategy can get fooled into choosing the wrong column. For example if Column A is mandatory but never has more than a single value and Column B values are optional, but high frequency (e.g. 50% of the records, but every record has 3 values, giving it 1.5x the number of cells as column A), then column B will get chosen in preference to column A.
There's also the case where no single column in a column group always has a value (e.g. a column group where either column A OR column B is populated for any given record).
tfmorris
on 15 Oct 2012
_From tfmorris on November 06, 2011 21:14:59:_
Reopening. The theoretical issue that I suspected has been confirmed in the wild by a new XML file received from a commenter on issue #393, so we're going to need a different approach to dealing with column groups.
tfmorris
on 15 Oct 2012
_From tfmorris on November 06, 2011 21:26:19:_
issue #393 has been merged into this issue.
tfmorris
on 15 Oct 2012
Is this what might be causing my json import not to give all records an index?
 eswright
on 19 Jul 2017
eswright
on 19 Jul 2017
@eswright I suspect it might. I have run into the same problem today actually.
 wetneb
on 19 Jul 2017
wetneb
on 19 Jul 2017
Any suggestions on how to rebuild a record index? All my data is parsed but just a bunch of records are merged into one.
eswright
on 20 Jul 2017
@eswright Hi Eric, yeah, we have a bug in our column counting strategy, as @tfmorris hinted at above, and its never been found yet because of our lack of time, sorry about that. But for now, you could just MANUALLY parse the data by selecting the upper most outer record set element visually with the Json Importer...then you'll get some rows...and then manually parse those with Add new column using GREL parseJson() function as our Wiki has a few recipes and examples. That will probably get you by for now with nice record rows. Hopefully we can find time to work on this issue more by the end of the year. Having more example data that causes the issue would be EXTREMELY HELPFUL ! If you can upload your JSON file somewhere and email me the link, then I can analyze more for you.
 thadguidry
on 20 Jul 2017
thadguidry
on 20 Jul 2017
@thadguidry Here is an example dataset:
https://figshare.com/articles/GRID_release_2017-07-12/5203408
(the file where I observed the problem is "grid.json")
wetneb
on 20 Jul 2017
@eswright Thanks Eric. We got the linked file you sent privately to us. Yeah, I see a problem, where not all the objects in the large array get created in OpenRefine 2.7 release. I've sent this to @jackyq2015 as well. Stay tuned over the next few weeks while we work on the issue and a fix.
@wetneb Thanks Antonin, that file will help us also !
thadguidry
on 21 Jul 2017
@jackyq2015 I'd say this needs to be our highest priority issue at the moment, it looks like we're throwing away records of data during import. (or not parsing them out) Not good.
thadguidry
on 21 Jul 2017
Those file provided are huge. I can see the column count issue and it's hard to debug. can somebody provide a minimum data set on which can reproduce this problem? or this issue only happens when have large data set like this?
 jackyq2015
on 22 Jul 2017
jackyq2015
on 22 Jul 2017
@jackyq2015 Here is a much smaller file where the same problem appears: the source file contains eight records, OpenRefine merges some of them and obtains only four.
http://pintoch.ulminfo.fr/49a768ad87/grid_small.json
wetneb
on 22 Jul 2017
@wetneb Tried this file. it generated a project with 63 columns and 63 rows in row mode. But I did not see the missing rows. The problem I see is that the column and data are messed up. I think for that big file where appeared to import partially may due to the "record mode"?
I need to find out what exactly the issue before I can fix it.
jackyq2015
on 2 Aug 2017
Hi @jackyq2015. In rows mode all is fine indeed, but when you switch to records mode you will see that some records are merged together.
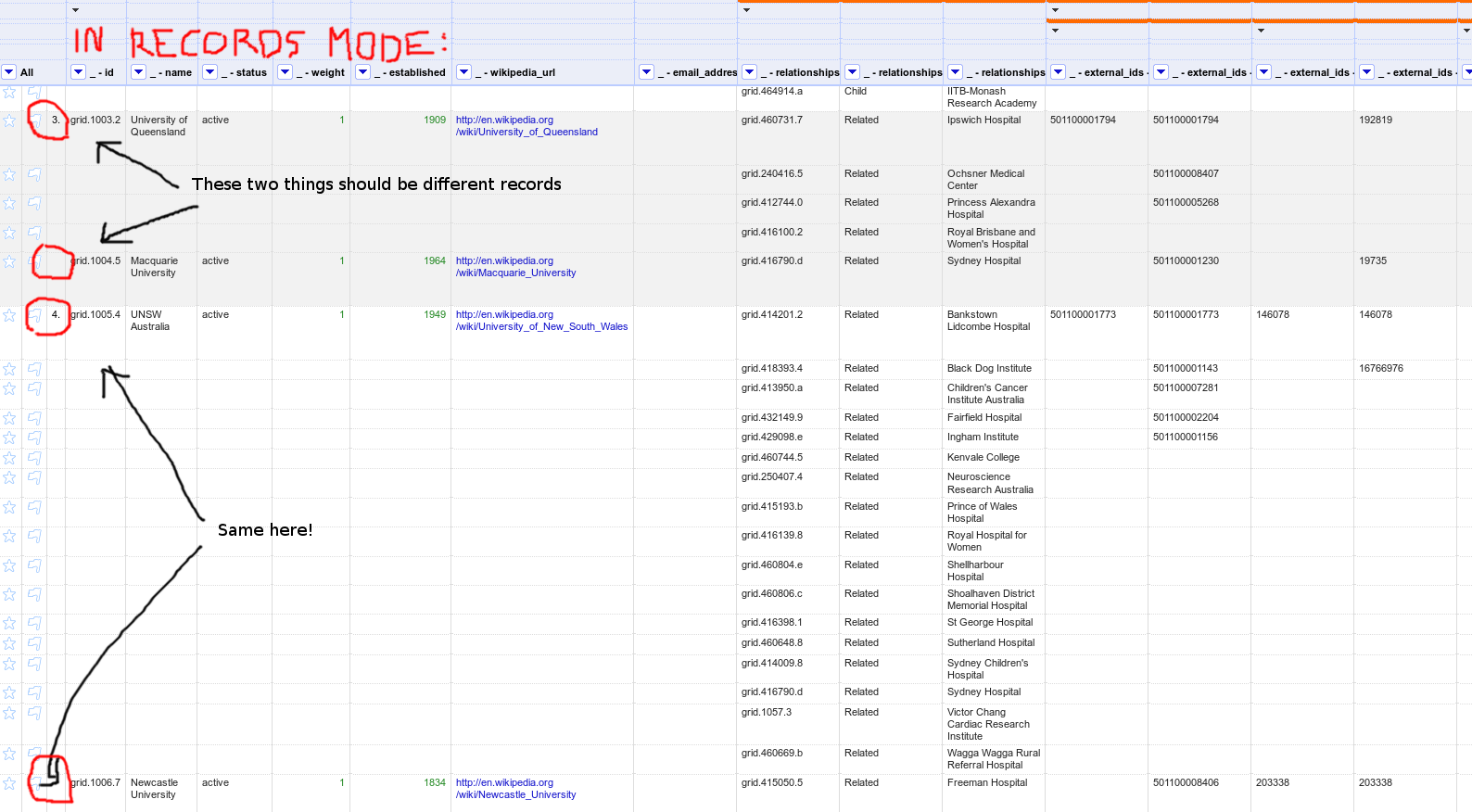
wetneb
on 2 Aug 2017
I think the problem is under records mode OR miscalculate the row dependency under some situation. It causes some root node were flagged as a child node. From the UI aspect, they are merged together. Not found the solution yet. will work out it.
jackyq2015
on 5 Aug 2017
I fixed it. can somebody help to test it from https://github.com/jackyq2015/OpenRefine? If it works as expected, I will create a PR for this. cheers!
jackyq2015
on 13 Aug 2017
@jackyq2015 that's fantastic! It works indeed for my example.
It'd be great to have a test for that (I can help if needed).
wetneb
on 13 Aug 2017
Related issues
 Yuutakasan
·
27Comments
Yuutakasan
·
27Comments
 wentianq
·
50Comments
wentianq
·
50Comments
 paregorios
·
28Comments
paregorios
·
28Comments
 ettorerizza
·
36Comments
tfmorris
·
30Comments
ettorerizza
·
36Comments
tfmorris
·
30Comments
Most helpful comment
I fixed it. can somebody help to test it from https://github.com/jackyq2015/OpenRefine? If it works as expected, I will create a PR for this. cheers!