Openrefine: GREL cross function should support lookup by numbers and other datatypes (date, boolean, etc.)
Is your feature request related to a problem or area of OpenRefine? Please describe.
The GREL cross function only works for string values at the moment. It could also support numbers (int, long). Looking up by floating point number is probably not a great idea because of rounding errors.
Describe alternatives you've considered
The cross function could directly convert values to string (in its index, and in its first argument).
Additional context
Suggested in #2456.
 wetneb
wetneb
All 28 comments
I think that cross() should support any type (possible, easy) of value. Boolean would be pretty important, and date, time, datetime could also be useful.
Is there a big cost to doing them? I think that should guide our choice.
Regards, Antoine
 antoine2711
on 25 Mar 2020
antoine2711
on 25 Mar 2020
The PR #2468 already allows for any cell value to be used in cross.
wetneb
on 25 Mar 2020
@afkbrb: we have a bug in our code.
If I do this:
cross(cells.fakeIndex.value + 1, "TEST-CrossFunc_v3-4", "Col1_NumberInt")[0].cells.rowName.value
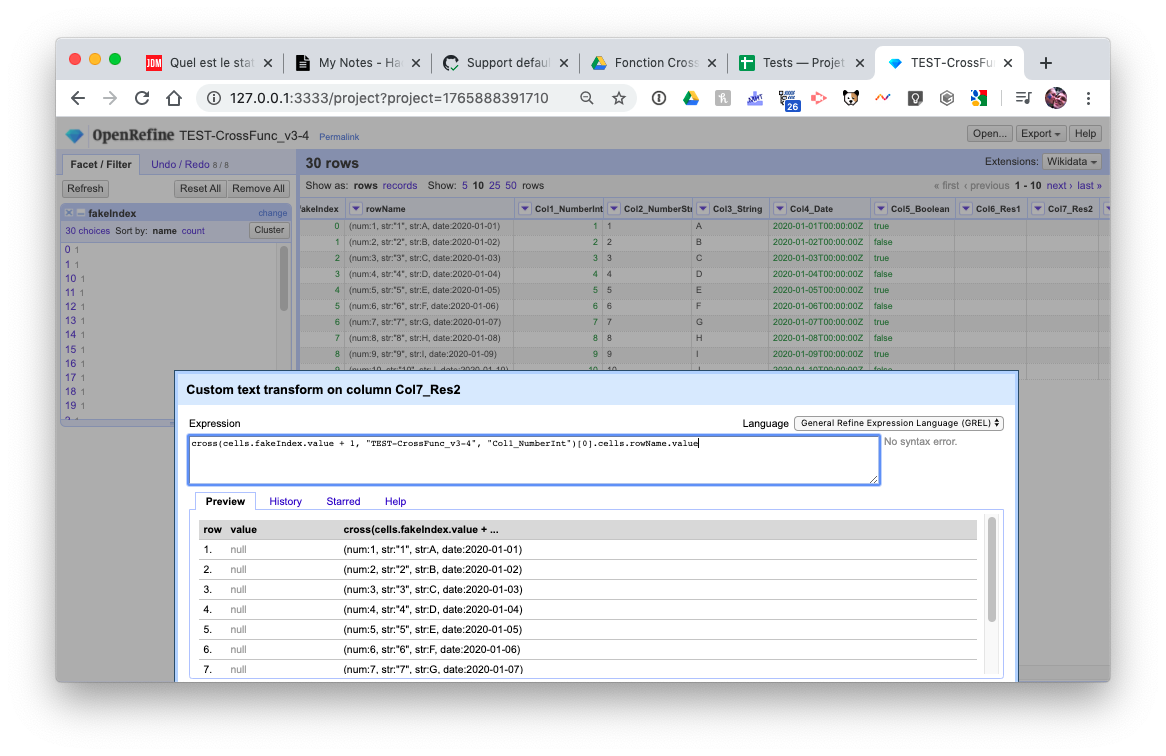
Everything is good.
But if I do this:
cross(cells.fakeIndex.value, "TEST-CrossFunc_v3-4", "Col1_NumberInt")[0].cells.rowName.value
_(with the only difference being the first argument is cells.fakeIndex.value and not cells.fakeIndex.value + 1)_
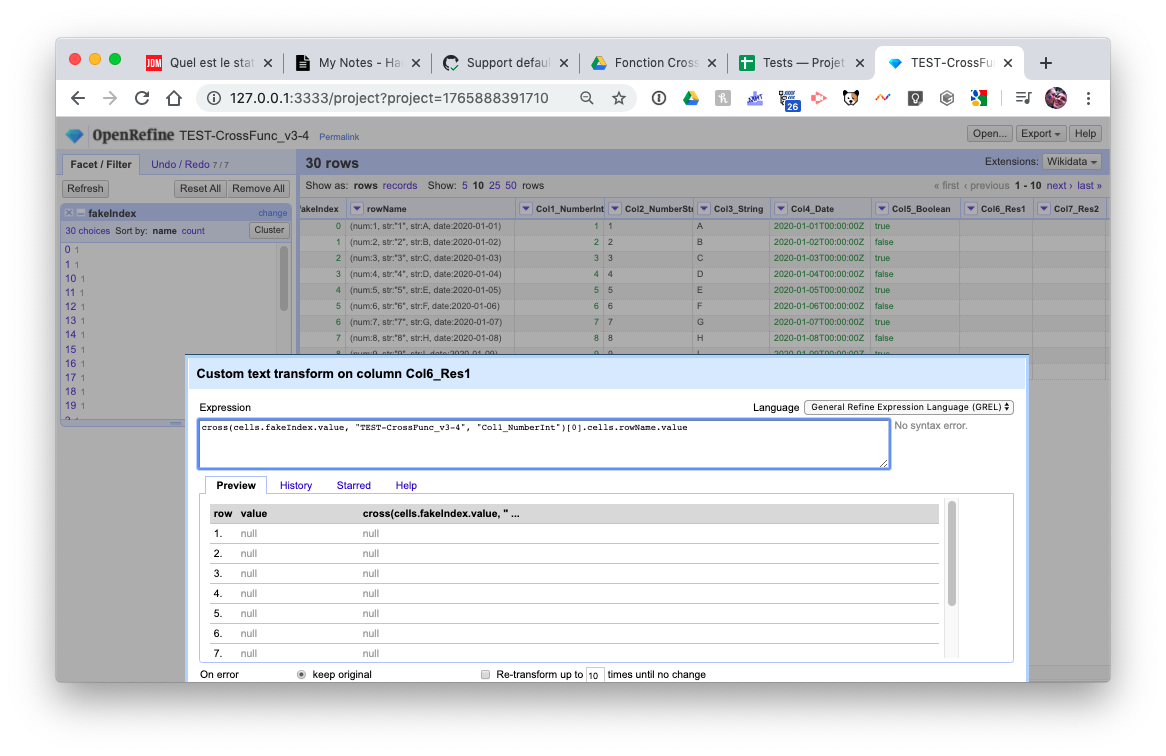
In the last example, ONLY the first row should return null. All the other rows should return the same thing as the example 1 (it should only be offset by 1…). Can you please check this weird thing?
@thadguidry: since this is a bug in code that is in the master branch, but not in v3.3, should I reopen this Issue with this new problem, or should I create a new issue? (I'd rather not, it really concerns this Issue).
Regards,
Antoine
antoine2711
on 19 Apr 2020
I cannot comment on that bug. cross() has now been changed from how it worked for the past 10 years. It might be overloaded now and in my opinion breaking our philosophy, but I don't know yet until the its documented better. Let me know when you have something documented on how its supposed to work now, then I and others in the community will be happy to test...until then we cannot test something that isn't properly designed and documented yet.
 thadguidry
on 19 Apr 2020
thadguidry
on 19 Apr 2020
Keep in mind, I'm not really complaining. :-) I'm happy to see progress and experimentation, even on our master branch. I'm sure we will get something right and where everyone is comfortable either with cross() or an additional GREL function for row index particulars if we feel cross() has become overloaded. So...let's continue to experiment and document and give complete examples of before/after so everyone has a very clear understanding of the new cross(). Thanks!
thadguidry
on 19 Apr 2020
Keep in mind, I'm not really complaining. :-)
Well, then, let me complain about the bug we now have in our master branch, a problem that take precedence on future enhancement. I will stop working on #2504, Reopen this #2461, look and we will, hopefully with the skills of @afkbrb, fix this bug.
At the same time, I will build a complete project, with tests of different datatypes, some successful, and some failing on purpose just to make sure they fail. Kind of test case at a user level. I think you call that integration tests?
I'm happy to see progress and experimentation, even on our master branch. I'm sure we will get something right and where everyone is comfortable either with
cross()or an additional GREL function for row index particulars if we feelcross()has become overloaded.
Yes, we might have to choose a crossIndex(iValue, iProject), though I hope not, but that is in the scope of #2504, so it's not a bridge we have to « cross » yet… ;-)
So... let's continue to experiment and document and give complete examples of before/after so everyone has a very clear understanding of the new
cross(). Thanks!
Sure will! I will open a discussion with @ostephens about documenting what we have in the master branch that is not in v3.3, as to know what direction he wants me to take.
Regards,
Antoine
antoine2711
on 19 Apr 2020
It's called negative testing. https://en.wikipedia.org/wiki/Negative_testing
hahaha, you and your puns!
thadguidry
on 19 Apr 2020
Also we have a long standing tradition. "You break it...you fix it" :-)
thadguidry
on 19 Apr 2020
Also we have a long standing tradition. "You break it...you fix it" :-)
I also abide by that rule, but truth be told, it's mostly out of well placed pride… ;-)
antoine2711
on 19 Apr 2020
@antoine2711 That bug was caused by the different types of "value" and "value + 1". The type of "value" can sometimes be Integer, while the type of "value + 1" is always Long.
 afkbrb
on 19 Apr 2020
afkbrb
on 19 Apr 2020
@antoine2711 That bug was caused by the different types of "value" and "value + 1". The type of "value" can sometimes be Integer, while the type of "value + 1" is always Long.
So, how did you fix it? If it's a number of anytype, always try to convert & match?
Regards,
Antoine
antoine2711
on 19 Apr 2020
So, how did you fix it? If it's a number of anytype, always try to convert & match?
Yes, I think we should always convert Integer to Long for the lookup.
afkbrb
on 19 Apr 2020
So, how did you fix it? If it's a number of anytype, always try to convert & match?
Yes, I think we should always convert Integer to Long for the lookup.
I think that 1.000 should match 1. Is this also possible? A.
antoine2711
on 19 Apr 2020
I think that 1.000 should match 1. Is this also possible?
It's possible, but performing a lookup on float/double is not a good idea. I think if a user wants to do the lookup on a target column of float/double, he should get it normalized to int/long first.
afkbrb
on 19 Apr 2020
Umm, this is breaking our philosophy. We let users control this behavior through smart controls. Automatically converting something without the user knowing is not what we want.
Notice I said "without the user knowing". We could think about a 4th boolean argument or a brand new crossover command that has the ring to it of "crossing over" or changing/converting things.
thadguidry
on 19 Apr 2020
Automatically converting something without the user knowing is not what we want.
Here we are just talking of converting a temporary value to do or not a match. We'd only match numbers with numbers.
Number management is already internal and hidden for the user. I don't even think we have functions to convert from integer to double or floating other than clever hacks, do we?
Even our type() function will return the same for integer, double and float. What we see here in this problem is internal Java type, not OR type.
It's possible, but performing a lookup on float/double is not a good idea. I think if a user wants to do the lookup on a target column of float/double, he should get it normalized to int/long first.
The thing is that we do not have tools for that, neither anyway for the user to flag this issue, other than clever hacks, and even that, I'm not sure…
Well, always more details than first anticipated. In all accounts, I think we are doing our job here, and a little of thinking time will be required. Let's see what @wetneb think of that…
Regards,
Antoine
antoine2711
on 19 Apr 2020
History lesson: We have tools for that. It's called OpenRefine's String functions. It's not a problem when its all Strings. :-) That was a design decision early on with OpenRefine so that users had great control on the data...treat most transforms with Text for exactness. Which is why cross() traditionally just worked on Strings. When someone needed "exactness" they just converted a column to Text (String) and used match() or cross() or whatever GREL function needed. Then if they needed Numbers and control on formatting of them, we had other functions and menu options (some during export as well). So there were more workflow steps for a user.
What we are beginning to change in our functions for OpenRefine, as I see it, is saving the user those extra workflow steps with functions that do 2 or more things in 1 go. I'm fine with that, but that is a different handling to how OpenRefine worked piecemeal and we just need to be careful and create really good tests.
thadguidry
on 19 Apr 2020
I'm fine with that, but that is a different handling to how OpenRefine worked piecemeal and we just need to be careful and create really good tests.
Yes @thadguidry, on that account, it is important to make more tests than we actually do, and even more complex test, kind of user tests. I agree 100%.
In no way do I want to touch current handling of strings in OR, as I understand they have this particular center and higher position. And, I also understand that in OR, for us, a number, be it and integer or a float, is a number.
But we also want to expand to a broader, with schemas, better JSON, better exchange from external sources (.XLSX and gSheets) which all have internal types. In a way, we might want to preserve some of that « metadata » in terms of datatype.
Also, we are called OpenRefine, because we refine data, and datatyping being the purest kind of tagging in a data context, we have to consider some improvements in that regards, as the world evolves and new things become more important.
Now, here's a REAL dilemma. For the cross() function, if we go further down the full string way, could convert to string EVERY datatype before trying to match. Now, that would not break old behavior (just enhance it), and it would fix some of our current problem. But not all, since 1.0 even in a "1.0" string, still wouldn't match "1". It could be the new logic anyway. But, how do you convert a date? Because you and me, we don't do it the same way. And even a boolean… would you consider VRAI for true? Google does if for me, and I'd expect, in a perfect world, that OR respect that and remembers it. But we are now NOWHERE from this, even if one can imagine a realistic path for OR in his head.
The real problem we are facing here, is that OR has no float datatype, nor double or integer, just a general number. I had NEVER read anywhere in the doc, on gGroups or here in GH, about row.index being a double. And franckly, Thad, did you? Do we want our user to start to think about that? « Bonjour la documentation » that it will require. And just imagine me doing all the Issues about that and the logic that it will bring, the (1.0).type() == "float" and so on…
I think we must continue with the current logic that a number is a number, and that 1.00 == 1 (as it is the case with GREL now). And so should match() and cross(). But I'm serious about preconverting everything to string before, if you fell like that's the way, I could live with it, but I think it would be inferior and cost us further down the road.
Regards, Antoine
antoine2711
on 19 Apr 2020
I would go for a silent conversion to string in the column index and cross argument, I think.
wetneb
on 19 Apr 2020
I would go for a silent conversion to string in the column index and cross argument, I think.
But that would only be for cross() with the internal index or every column?
Regards, Antoine
antoine2711
on 19 Apr 2020
I don't understand your question, sorry!
wetneb
on 19 Apr 2020
I don't understand your question, sorry!
Well, @wetneb, let me summarise the situation as I see it in the angle of this particular problem.
- We went from a
cross()function that would get data based on a column or values and do a string match. So, in most occasion, when you had another datatype then string, you would get no match. - Now, in the master branch, we have code that compare the two based on their datatypes being the same.
- So, for strings, no problem, it behaves like before.
- For boolean, date, and I suspect arrays, this new functionality work well.
- Now, for numbers, it get complicated. If you compare int with int, double with double, or float with float, no problem.
- But, if you compare double with int, the code in master branch does not match. There is already a quick fix and it's really no big deal, neither in concept or doing
- Where it gets tricky, it's when you compare int or double with float that has no decimal. Do you match or not? In our expression preview dialog,
1 == 1.0. But with our code in the master branch, we do not match.
And after, there is another matter (#2504), not directly related, but that raises some others conceptual and philosophical discussions.
For me, the question in the middle of all this is: should 1 == 1.0 match in the cross() function? And, in a more general sense, @thadguidry want to have things be defined. I believe this issue has sent us to an enhanced cross() function, that preserve the old compare behavior of cross() with strings, but that now does a datatype constraint and compare. This is fine almost anywhere, except with float against int or double where 1 == 1.0 does not match.
Regards,
Antoine
antoine2711
on 19 Apr 2020
That is why I would change the cross function for it to convert the value that is being looked up to a string systematically. The column index would also be changed to only have strings as keys (using the same conversion). Is that clear?
This will solve the discrepancy between longs and ints. This will not equate 1.0 and 1, but as we all agree, looking up rows using floating-point numbers is a bad idea.
wetneb
on 19 Apr 2020
So, I'm going to make the change: the type of the value to lookup in the cross function will be ignored, we get a match if and only if two values have the same string representation.
I think this behaviour will make more sense from a user's view.
Do we agree that this is the right behaviour?
afkbrb
on 19 Apr 2020
@afkbrb Yes please. That's the same conclusion that David and I came to 10 years ago when I asked him in chat that I needed a lookup that worked with everything. :-)
thadguidry
on 19 Apr 2020
I have a question: will we expect a match with "" == ""?
And, if so, would then null == "" also?
Regards,
Antoine
antoine2711
on 19 Apr 2020
"" (empty string) is considered blank
null is no longer considered blank, and no longer equivalent to ""
@ostephens added the new logic a few OpenRefine versions ago. We have this exposed now as separate customized facets additionally:
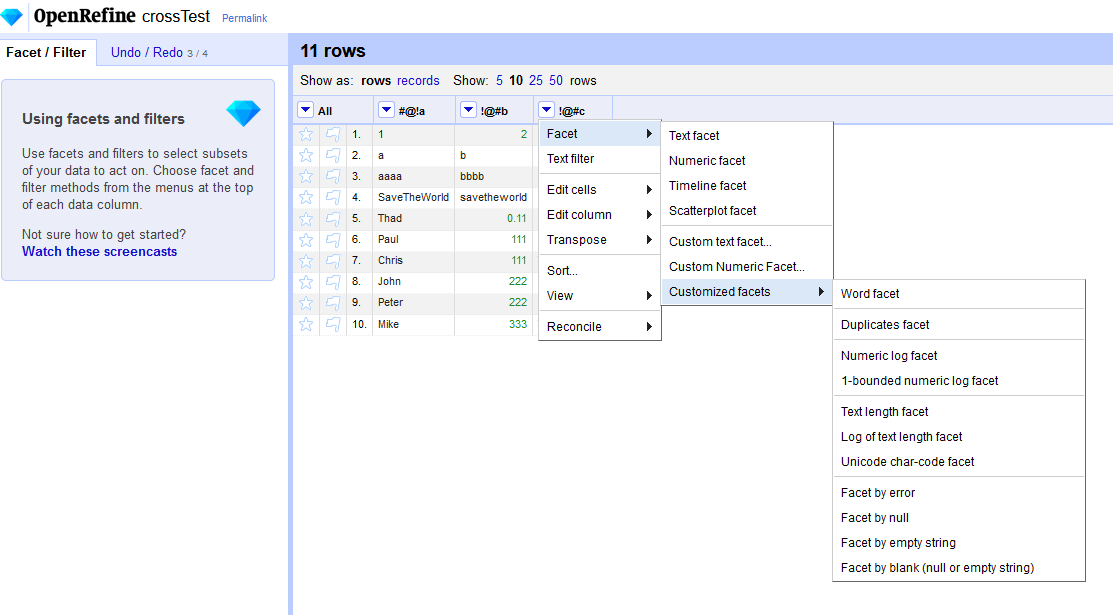
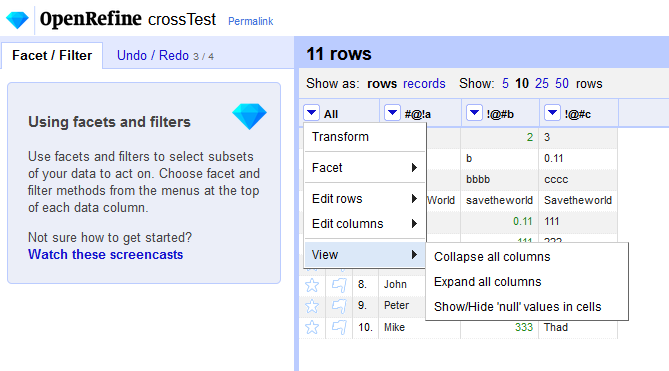
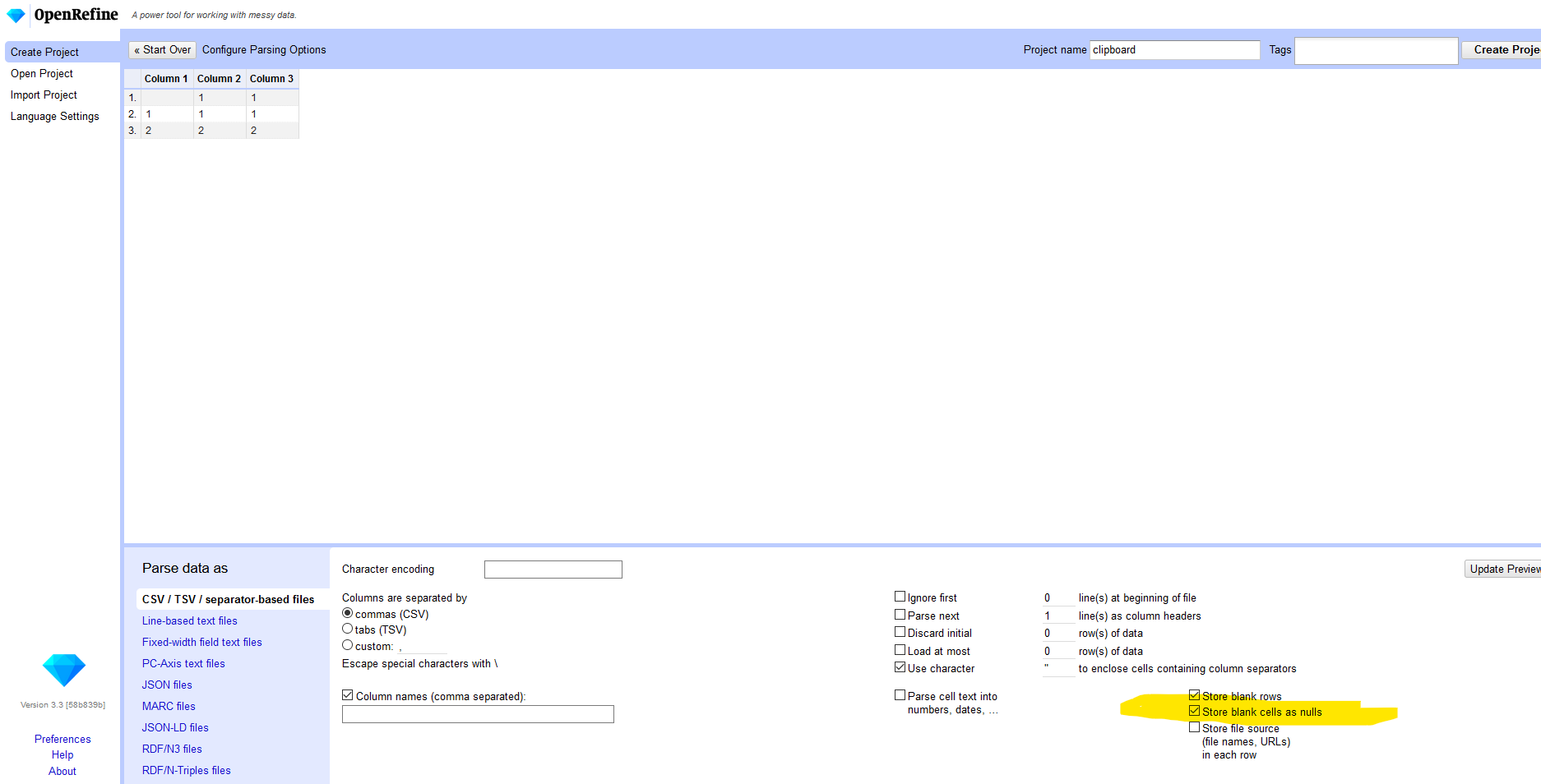
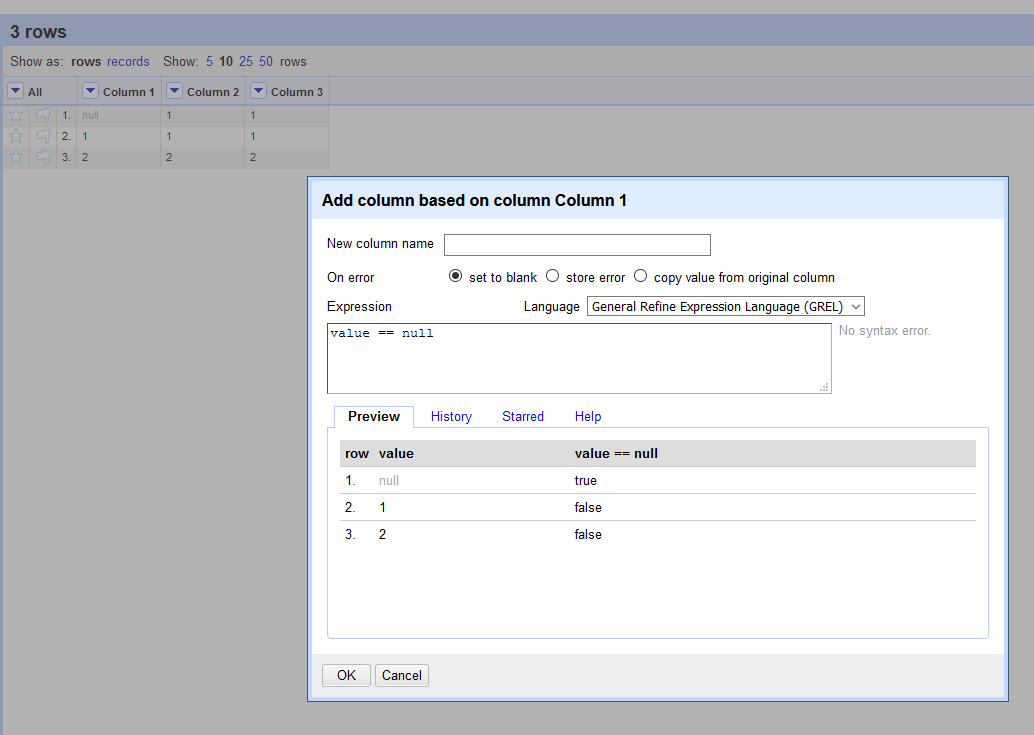
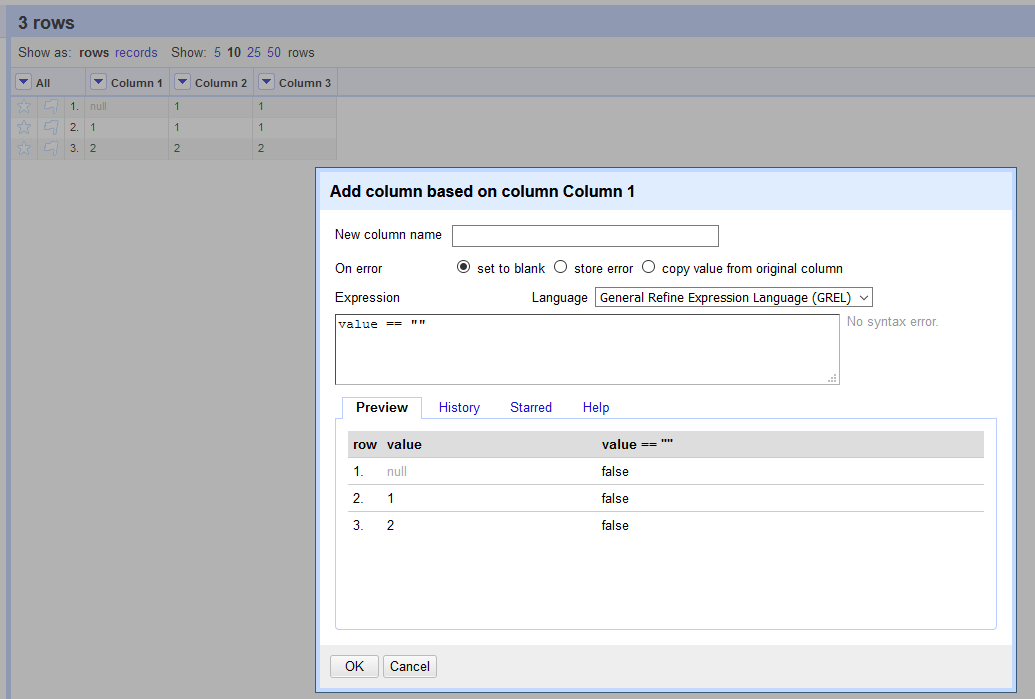
thadguidry
on 19 Apr 2020
Oops! forgot to answer your question!
I have a question: will we expect a match with
"" == ""?No, not matching that expression. (I don't see it as useful? and cross didn't match that as I recall in older versions)
And, if so, would then
null == ""also?No, not matching that expression. (because of inequality now)
thadguidry
on 19 Apr 2020
Related issues
 asyrul21
·
3Comments
thadguidry
·
3Comments
thadguidry
·
4Comments
antoine2711
·
3Comments
asyrul21
·
3Comments
thadguidry
·
3Comments
thadguidry
·
4Comments
antoine2711
·
3Comments
 lapoisse
·
3Comments
lapoisse
·
3Comments
Most helpful comment
""(empty string) is considered blanknullis no longer considered blank, and no longer equivalent to""@ostephens added the new logic a few OpenRefine versions ago. We have this exposed now as separate customized facets additionally: