Openrefine: Behaviour of date, number and boolean values in a test/list facet is inconsistent
Version of OpenRefine used (Google Refine 2.6, OpenRefine2.8, an other distribution?):
Tested on OpenRefine 2.8 & 3.0 beta, but suspect the same behaviour is in earlier versions of OR as well
Current behaviour
There are a variety of scenarios - some described here:
Create a 'text facet' on a column that contains date values (i.e. as dates, not strings)
Try selecting rows by clicking the date value in the facet
See that no rows are selected (and in 2.8 at least an additional value appears in the facet)
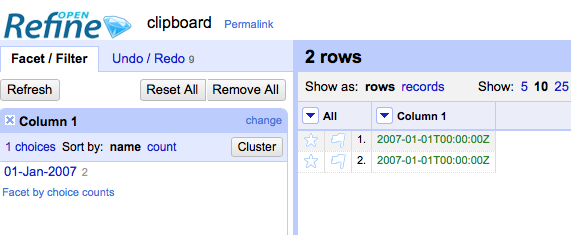
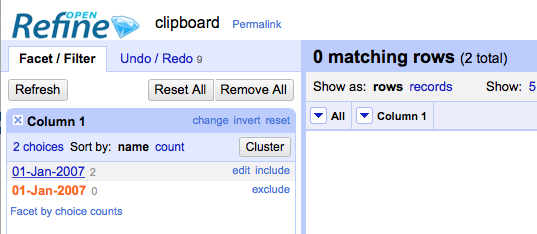
Create a column containing non-string values and strings that have the same visible value - e.g.:
true -> boolean
"true" -> string
Look at the facet and see the "count" is the number you would expect if you treated the string and non-string values as being equivalent.
Try selecting the value in the facet - see only the rows containing either the non-string, or only the string values are selected (which set are selected depends on the order of the cells in the project)
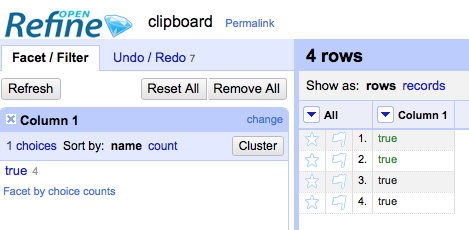
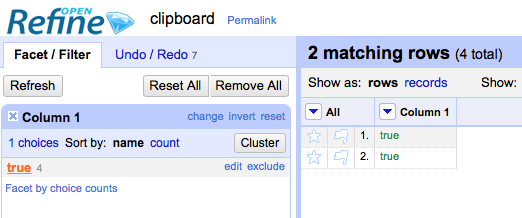
This latter behaviour also effects numbers and dates
If you are allowed and are OK with making your data public, it would be awesome if you can include the data causing the issue or a URL pointing to where the data is (if your concerned about keeping your data private, ping us on our mailing list):
Expected Behaviour:
There is a fundamental question here of how date, number and boolean values should be treated in text/list facets. They are currently counted as if they are equivalent to strings, and also if you try to use 'mass edit' they are treated as if they are the same as the equivalent string (e.g. in the example above do an edit from the facet and the boolean true and the string "true" would both be changed in the project.
I think trying to treat objects as equivalent to some strings in this situation is probably a bad idea. I can see two options
1) Similarly to how timeline/number facets treat other values OR could simply not include the non-string values in the facet and have a checkbox as to whether they are included in the filter or not - see
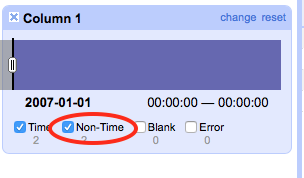
2) Similar to how nulls/empty strings are handled in text facets, we could have a bucket facet value for "dates", "numbers", "booleans" which would allow the user to select the set of boolean values but not see counts of true vs false (a further boolean facet would be needed to see that)
3) Dates, Booleans and Numbers could be included in the facet but as separate values in the facet - so all boolean true are grouped and counted separately to all string "true"
These are not necessarily exclusive options - we could implement them in combination
These are my views - please make suggestions for other behaviours or indicate which of the 3 I've listed individually or in combination would make most sense to you
@thadguidry @ettorerizza (feel free to ping others to get feedback)
 ostephens
ostephens
All 26 comments
@ostephens
TL:DR; "trying to treat objects as equivalent to some strings in this situation is probably a bad idea."
Correct @ostephens , it is a bad idea.
You probably need to know this history....
Facets were always designed to be Datatype specific....the exception to the rule was the Text Facet.
That behavior goes way back to pre 1.0 days actually. And your scenarios I just tested on 2.6 alpha 2
The Datatypes other than Text, those Facets always excluded rows that were not of the given Datatype...so yeah, folks would miss rows of data, and that was expected. In fact, that's why David added for me the value.type() I.E., it wasn't a bug, but a design choice to restrict Facet handling, otherwise, as you see, things get unwieldy trying to deal with different Datatypes within one process or operation, its not impossible, but we always thought that folks would like to work in layers, even with deducing the Datatype. For those folks with less precise needs, the Text Facet worked as it flattened and converted everything toString and presented what you had, even null/blank cells.
In OpenRefine, my opinion would be to continue to keep Facets as being Datatype specific in their handling or evaluation of data except for Text Facet. Just as we always have.
It may also be better to just add more Datatype Facets to account for various Datatypes or new one's we introduce, for instance my Json Datatype suggestion.
We are definitely missing a real Boolean facet and also the Type evaluation for a Boolean value.type() https://github.com/OpenRefine/OpenRefine/blob/master/main/src/com/google/refine/expr/functions/Type.java
Yes, we could enhance Facets to have mini-filters (datatype buttons underneath,etc.) themselves to expose more/less rows by using value.type() against them. But that kind of UI work, might be better served by focusing first on "the Beast", going to a new UI and separating Front/Backend ops and then making beautiful Facets. But don't let me stop you from enhancing the current state of things.
Hope that helps ?
 thadguidry
on 23 Jun 2018
thadguidry
on 23 Jun 2018
Thanks @thadguidry.
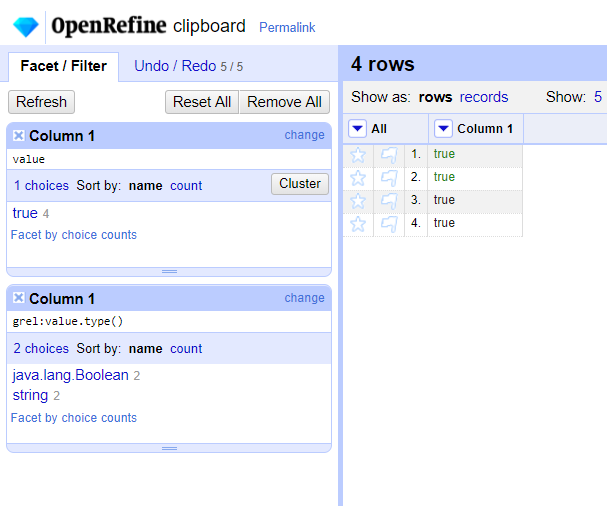
I actually like that the Text facet includes non-string values - it is sometimes very convenient (and I don't find the UI on the number and timeline facets that good).
I think my preference is (3) - so actually what we have is a proper 'list' facet - essentially it would work like the current text facet in general, but handle non-string values more intelligently. I'll have a play and maybe post a proposed approach here with some mock ups of how it would work and see if others have views as well.
ostephens
on 23 Jun 2018
@ostephens A "Facet Type" in the menu would easily solve this kind of case, wouldn't it?
 ettorerizza
on 23 Jun 2018
ettorerizza
on 23 Jun 2018
@ettorerizza a type facet would allow you to filter the data set by type of course, and a type facet seems like a good idea.
However I think we still need to look at the behaviour of the text facet. To “count” four values, and mass edit four values but only select 2 of those values makes no sense to me
I think we need the text/list facet to treat non strings in a consistent way
ostephens
on 23 Jun 2018
@ostephens "I think we need the text/list facet to treat non strings in a consistent way"
...and that consistent way is done by tackling "The Beast" , where a column index for Values As Text, is kept and where the Text Facet looks to that column index.
Didn't our current data structure already keep internally or have that kind of index when the Text Facet is built ? I've forgotten, perhaps its just an index of Objects. so might need an index of Strings. but I really thought we were already doing that internally somewhere..."making a copy". @jackyq2015 might know more.
thadguidry
on 23 Jun 2018
@thadguidry I'm trying to understand what is the most sensible consistent behaviour here that we should aim for. It seems from what you say, you would like to see the values treated consistently as strings within the context of a text facet? So if we have data:
[date 20170101T00:00:00Z]
20170101T00:00:00Z
Then this should result in a facet:
20170101T00:00:00Z (2)
And selecting the value in the facet would filter to both rows. Is that correct? Have I understood your preference for how it should work?
ostephens
on 24 Jun 2018
@ostephens No, you misunderstood. Do not do any fancy conversions for the Text Facet. We never did that before. When I said that Text Facet was the exception to the rule... I meant that the Text Facet back then would only deal with String Datatypes. It would actually still display in the Facet, a Datetype and its Count correctly, along with String Datatypes, but the rows would never show if you selected the Date Datatype in that Text Facet...since they were not a Text Datatype. Also, back in Google Refine 2.0 r1836, it would still show Dates in a column grid as Black and White color, not Green color. We eventually improved things as time went on. Here is how it looked and worked in Google Refine 2.0 r1836...where in the Text Facet I have selected 1 String Datatype (whose row is showing) and 2 Date Datatype's (whose rows do not show in grid, but only the String Datatype)
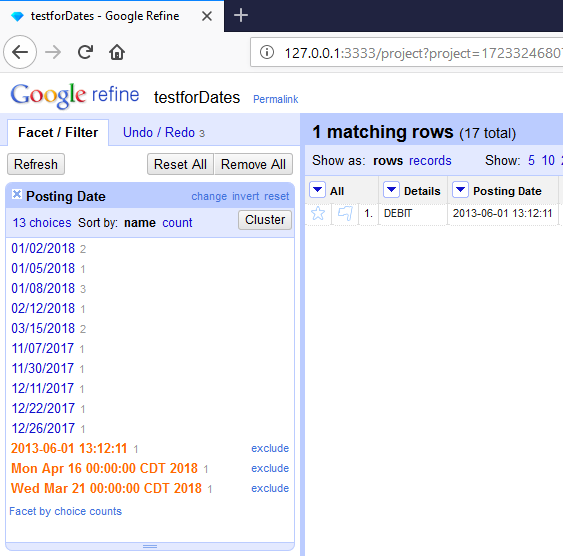
So for the current state we are in now...I would prefer that we have users using different Facets to deal with different data types. For the Date Datatypes still showing in a Text Facet...I would probably not even show them any longer, we did that back in the day as a convenience. But it often confused and we dealt with it on the mailing list.
The Text Facet does not have to show every non-Text Datatype value... only String Datatype values, its a TEXT Facet after all. And I think that is what you are asking us. So my answer is, Change the Text Facet, so that Users can only see String Datatype values. Then you are left wondering..."but what about non-Text Datatype values" ? I would say that you show at the top of the Text Facet something like "non Text Rows" (like we do with Blank and Null) and a Count next to it, which should be warning enough to users that "hey you have some rows in this column that are not of a Text type! Go deal with them somehow with other Facets, etc". And then also add more Facets to deal with those other Datatypes, like Boolean, etc.
For the future, when we go to a new UI, we can take the same backend code and eventually refactor into a smarter multi-Datatype Facet, similar to how Data Wrangler does, and deal with the "non Text Rows" in a much more elegant fashion in a single Facet dialog.
Ask if anything is unclear from above. I want to ensure you get the vision here.... I.E. don't disturb the current Text Facet handling too much...we'll do that later on with more funding and help.
thadguidry
on 24 Jun 2018
Thanks @thadguidry that's very clear. What you are suggesting:
Change the Text Facet, so that Users can only see String Datatype values.
show at the top of the Text Facet something like "non Text Rows" (like we do with Blank and Null) and a Count next to it
This definitely makes sense to me and was the approach I was trying to describe in my Number 2 above:
Similar to how nulls/empty strings are handled in text facets, we could have a bucket facet value for "dates", "numbers", "booleans" which would allow the user to select the set of boolean values but not see counts of true vs false (a further boolean facet would be needed to see that)
So with this method
[date 20170101T00:00:00Z]
20170101T00:00:00Z
Would give the facet
(dates) (1)
20170101T00:00:00Z (1)
I still wonder if there is a role for a mixed type 'list' facet (which is what I was suggesting in (3) above) where
[date 20170101T00:00:00Z]
20170101T00:00:00Z
Would give the facet
[date 20170101T00:00:00Z] (1)
20170101T00:00:00Z (1)
but I think you are probably right that we should keep the Text facet as Text, and then if there should be a mixed type List facet we can look at that as a separate issue
Thanks
ostephens
on 24 Jun 2018
OR's data type is stored at the cell level instead of the column level. It make some sense considering it deal with messy data where you can not expect the data is normalised as one specific type. But allowing set the data type to one cell looks weird. Imaging you have 1M rows data set, it is not feasible to set it one by one. I would recommend something like "preferred data type"(default to text) to the column and when doing the facet, user doesn't have to think about it should facet by text, Boolean or date.
Grouping the cell by data type also looks weird. User then have to go into each data type and fix them one by one. In another words, cannot see/process the whole facet in just one view.
 jackyq2015
on 28 Jun 2018
jackyq2015
on 28 Jun 2018
Thanks for this @jackyq2015. I think the issue of having a data type at column level is different to the question of how to facet on a column which contains a mixed set of data types. It's the latter question that I think we are trying to resolve here.
I understand what you mean when you say
Grouping the cell by data type also looks weird
But I'm not sure we've found an approach yet that doesn't have some downside. Based on the discussion in this issue, I see four choices for dealing with the data of different types in a List face:
- Similarly to how timeline/number facets treat other values we could simply not include the dates, booleans, numbers in the facet and have a checkbox as to whether they are included in the filter or not
- Similar to how nulls/empty strings are handled in text facets, we could have a bucket facet value for "dates", "numbers", "booleans" which would allow the user to select the set of boolean values but not see counts of true vs false (a further boolean facet would be needed to see that)
- Dates, Booleans and Numbers could be included in the facet but as separate values in the facet - so all boolean true are grouped and counted separately to all string "true"
- Dates, Booleans and Numbers could be converted to strings for the purposes of faceting and grouped with the equivalent string value
PR #1666 implements (2)
(4) is the closest to the current behaviour, but I think doesn't work well for dates because of the variety of ways a date can be parsed into a string. It could also be a problem for numbers and booleans in some cases, although Booleans and Numbers are different to dates because:
a) They have native representations in JSON so it is easy to know if we have a Boolean or Number in our facet without any additional information
b) They convert to strings in a more consistent manner than dates (although Numbers can vary depending on whether they are LONGs or INTs)
My instinct is against (4) because it involves switching between data types - which seems to me risky behaviour and likely to lead the user astray.
However, I can probably be persuaded that any of the four approaches described here is the right way to go. I implemented approach (2) in PR #1666 because it seemed to be the approach myself @thadguidry and @ettorerizza all felt was reasonable.
@jackyq2015 which do you think would be the best approach out of the 4 described? Or is there another way of approaching this which I've not described that you would prefer?
ostephens
on 2 Jul 2018
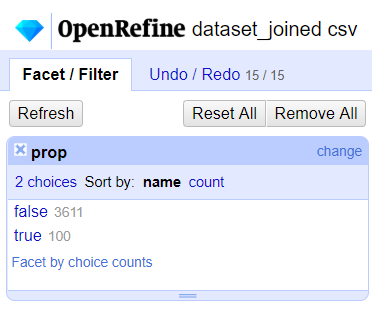
We must find a solution at least for Booleans. The current behavior of OR 3.1 does not allow anymore to use text facet "true vs false", for example to select the first 100 rows of a dataset with row.index < 100. Big breaking change.
OR 3.1
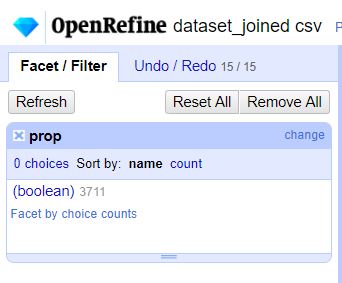
OR 3 and previous
ettorerizza
on 8 Jan 2019
@ostephens yes, but it's a pretty big issue IMHO, especially as the UI was not updated for this facet.
It was a mistake to make this change, we knew it would break things… One way we could have made the move would have been to introduce a new facet ("string facet" instead of "list facet") with the new behaviour.
 wetneb
on 8 Jan 2019
wetneb
on 8 Jan 2019
@ettorerizza you need to add toString() to see the values:
(row.index < 100).toString()
will get the result you want
ostephens
on 8 Jan 2019
In the medium term - I think adding a 'boolean facet' would be the correct solution to make this more straightforward
ostephens
on 8 Jan 2019
The problem is that users have no idea whether their values are stored as booleans or strings - this is something we do not expose (unless they are explicitly looking for it and create a facet to display the type).
wetneb
on 8 Jan 2019
@wetneb I'm not sure I agree that scenario is a problem. If they make a list facet on a column they will see immediately how many boolean values are in there.
I think the more problematic area is the one @ettorerizza demonstrates where the user wants an easy way to get a boolean true/false result in a facet. That used to be simpler than it is now
ostephens
on 8 Jan 2019
Well, now that we have made this change we kind of have to be consistent and add a boolean facet indeed, but I think the end state will be less usable than where we started from. Maybe one way to mitigate this would be to display boolean values in a different color (similarly to the way dates are highlighted), so that it becomes more intuitive for users to pick the right facet (list or boolean) at the first sight.
wetneb
on 8 Jan 2019
I'm happy to look at other approaches - but as always it is difficult to know where to strike the balance between giving the users choice and making those choices for them.
I believe Boolean values already display in green as with dates and numbers
ostephens
on 8 Jan 2019
Ah? Great, I did not realize that.
The main problems for me are:
- incompatibility with previous JSON workflows
- breaking change in 3.1 because the UI was not updated everywhere
- frustration for users who will first use a list facet and realize they need a boolean facet (especially if they do not understand this directly and have to look it up / ask a question on the mailing list)
But yeah, a boolean facet would be quite natural now that we have taken this path.
wetneb
on 8 Jan 2019
Would it be a good idea to restore the previous behavior of text facet (ie everything is stringified, as is in a CSV file) and to move the current behavior (OR 3.1) into a new kind of facet, called for example "type facet"?
ettorerizza
on 8 Jan 2019
That is another option, but I would rather call the current behavior "string facet" (I would expect a "type facet" to collect all string values into one facet choice, "(string)").
wetneb
on 8 Jan 2019
Agree with @wetneb
The previous behaviour of the text facet was problematic (as documented above). For example in the previous behaviour a cell with the text string 'true' and a boolean cell or result of 'true' would cluster together but selection did not work (documented above). Not to mention the issues with dates (above).
I think a "type" facet would be helpful, but this isn't what the OpenRefine 3.1 behaviour delivers.
The OpenRefine 3.1 behaviour delivers a "text" (or string) facet - and as with "number" and "date" facets, it doesn't try to blindly convert non-text values into text values - that is left as something the user can choose to do if they want. I feel this brings to consistency to the facet behaviour, although I absolutely acknowledge that this change to behaviour is a breaking change and needs users to amend their previous practices.
ostephens
on 8 Jan 2019
Another approach I suggested above (option "3") when I listed the options was
Dates, Booleans and Numbers could be included in the facet but as separate values in the facet - so all boolean
trueare grouped and counted separately to all string "true"
At the time I said:
I still wonder if there is a role for a mixed type 'list' facet (which is what I was suggesting in (3) above) where
[date 20170101T00:00:00Z]
20170101T00:00:00Z
Would give the facet
[date 20170101T00:00:00Z] (1)
20170101T00:00:00Z (1)
but I think you [was referring to Thad] are probably right that we should keep the Text facet as Text, and then if there should be a mixed type List facet we can look at that as a separate issue
So this would be another option - have a "List" facet which mixes types in a single facet but treats them separately.
ostephens
on 8 Jan 2019
Why do we keep forgetting our design agenda? Perhaps because some of it is always caught up inside issues I guess. But nearly every "enhancement" is a "design discussion". I'm all ears as to where / how we want to keep our design agenda going forward, so that we don't forget these things. Right now it's a bit of Projects / Issues / Google Docs
Regardless, @ostephens and I and @ettorerizza had already agreed on a design going forward, where we would provide many more facets, such as Boolean. We just haven't got there yet. Owen's first pass was to make it clear to users that they are dealing with different TYPES of data. We have that now and it clearly made Ettore think more about his data :-) and that's exactly what we wanted in the first place. (this is in keeping with OpenRefine as a power tool and not doing to many automatic things that hide data nuances to our users) Now we just need more facets or operations to deal with OTHER TYPES of data BESIDES TEXT. (yes Owen, our design forward is to keep Text facet as Text)
For 2019, we need to begin to start on:
design sketches for our new UI around Facets would be most welcome to be put up somewhere. React-based live Facet experiments would be even more welcome so we could play with the fit and feel (and we did this back in the Gridworks/Google Refine days with Google web developers). I just don't know where... Heroku ? (https://github.com/mars/heroku-cra-node)
Since @wetneb has already stated that we need to begin to nail down the UI, to help with the needs of the API and decoupling.
thadguidry
on 8 Jan 2019
@thadguidry I guess that design is an ongoing discussion :)
I'm good to add new facet types and if we create some enhancement issues for them this will put them on the list.
I struggle more with the overall UI design - it's the kind of thing that's beyond my experience to start from scratch - although once there is a framework in place I think I'm pretty good at picking up how things work and can start extending/copying existing work
ostephens
on 8 Jan 2019
Thank you for temporarily fixing this (quoted in #1957 and seen in 3.2 beta) . I am a new user of this tool, was trying to follow the tutorials and came across this problem several times and wrecked my brain questioning myself why i could not follow the lessons. Love this tool by the way...keep up the great work please.
 htwashere
on 10 May 2019
htwashere
on 10 May 2019
Related issues
 dantexier
·
4Comments
thadguidry
·
3Comments
dantexier
·
4Comments
thadguidry
·
3Comments
 stellasia
·
4Comments
stellasia
·
4Comments
 asyrul21
·
3Comments
asyrul21
·
3Comments
 antoine2711
·
3Comments
antoine2711
·
3Comments