Test-infra: AWS CNCF Account seems to have lost quota
We're seeing a lot of kops failures, because it appears that the AWS account under which the tests run no longer has the quota it previously had, at least in most regions.
We seem to have zero quota for t2.mediums in most regions, although we still have quota in e.g. ap-northeast-2
 justinsb
justinsb
All 20 comments
cc @mattlandis
 krzyzacy
on 6 Nov 2018
krzyzacy
on 6 Nov 2018
Taking a look.
Where do you see the limit changes? Is this through a dashboard, API or is it inferred from instance launch failures?
From what I can see we should still have the ability to launch 480 on-demand t2 instances in most regions (PDX) for example. We are still using On-demand right? I know we had talked about moving to having the reserved pool to help mitigate launch issues.
I'll open a support ticket to see if they can be of any help.
 mattlandis
on 6 Nov 2018
mattlandis
on 6 Nov 2018
/cc
 idvoretskyi
on 6 Nov 2018
idvoretskyi
on 6 Nov 2018
@mattlandis probably knows this, but there's an API for monitoring limits, but it's only available on Business or Enterprise support.
See https://docs.aws.amazon.com/awssupport/latest/user/Welcome.html for more.
There's examples for setting up monitoring at https://github.com/awslabs/aws-limit-monitor if we don't already have something.
 randomvariable
on 6 Nov 2018
randomvariable
on 6 Nov 2018
@justinsb could this be the reason behind Kops failures in release blocking since this morning https://testgrid.k8s.io/sig-release-master-blocking#kops-aws-master? We also had Go lang v1.11.2 update go in this morning.
 AishSundar
on 6 Nov 2018
AishSundar
on 6 Nov 2018
Kops tests are happy again in release dashboard.. not sure if it was indeed quota related or some other transient issue that hit it.
AishSundar
on 6 Nov 2018
I'm looking in the EC2 console:
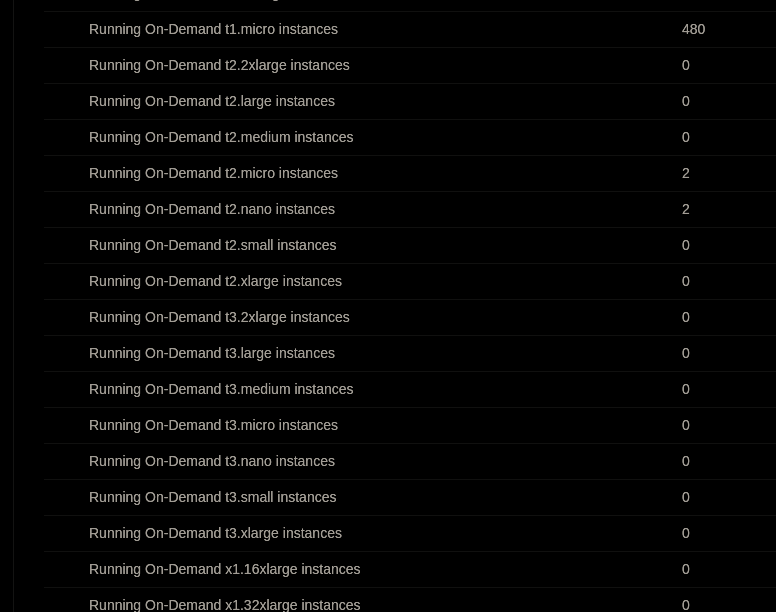

That's in us-east-1. kops defaults to t2.mediums for nodes (in regions where they are available), so I think this limit must have changed (or we've changed the kops default - but I don't think that is the case).
We do have quota in some regions, and we randomly choose a region, so that's likely why the kops AWS jobs are flaky right now (a real flaky job :-) ).
The "smoking gun" is that if you look in the full build log, you can see only one instance (the master) when kops is deleting resources. Normally you would expect to see nodes also:
...
I1106 16:06:57.231] iam-role masters.e2e-kops-aws.test-cncf-aws.k8s.io masters.e2e-kops-aws.test-cncf-aws.k8s.io
I1106 16:06:57.232] iam-role nodes.e2e-kops-aws.test-cncf-aws.k8s.io nodes.e2e-kops-aws.test-cncf-aws.k8s.io
I1106 16:06:57.232] instance master-us-west-2c.masters.e2e-kops-aws.test-cncf-aws.k8s.io i-0ef538c94e908e749
I1106 16:06:57.232] internet-gateway e2e-kops-aws.test-cncf-aws.k8s.io igw-0ce2106c0a0d6b6a8
I1106 16:06:57.232] keypair kubernetes.e2e-kops-aws.test-cncf-aws.k8s.io-a4:44:93:63:d1:46:cf:75:92:ff:3a:37:96:28:f8:c9 kubernetes.e2e-kops-aws.test-cncf-aws.k8s.io-
...
Can we check our support level on the AWS account and add per-account & per-region limit monitoring to Velodrome? I have a bit of spare capacity to help out.
randomvariable
on 6 Nov 2018
I've cut a ticket to get a limit of 480 t2.medium (and t3.medium) instances in all regions.
mattlandis
on 6 Nov 2018
cc @countspongebob
idvoretskyi
on 6 Nov 2018
Bringing in @d-nishi and @gyuho to get this fixed. My understanding is we have another account that we need to switch to for testing.
mattlandis
on 6 Nov 2018
/assign @d-nishi
@justinsb @krzyzacy @idvoretskyi @AishSundar -- please cc me when these things happen. I will need few days to take care of this. can I get a deadline from one of you?
 d-nishi
on 7 Nov 2018
d-nishi
on 7 Nov 2018
/sig aws
d-nishi
on 7 Nov 2018
Looks like it is (now) only these regions: us-east-1, us-east-2, us-west-2
I'll send a PR to exclude them, for now.
justinsb
on 9 Nov 2018
@idvoretskyi @spiffxp @justinsb -- this will be completed by Friday end of day. Might need a day or two to take effect.
I got the approval and added enough credits to cover current expenses and add buffer.
/cc @countspongebob
d-nishi
on 14 Nov 2018
@d-nishi thanks!
idvoretskyi
on 15 Nov 2018
credits have been applied to the account id you sent via email @idvoretskyi
please check and confirm.
d-nishi
on 17 Nov 2018
Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle stale
 fejta-bot
on 15 Feb 2019
fejta-bot
on 15 Feb 2019
It's solved now, please open a new issue if this will happen again.
/close
idvoretskyi
on 20 Feb 2019
@idvoretskyi: Closing this issue.
In response to this:
It's solved now, please open a new issue if this will happen again.
/close
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
 k8s-ci-robot
on 20 Feb 2019
k8s-ci-robot
on 20 Feb 2019
Related issues
 cjwagner
·
3Comments
cjwagner
·
3Comments
 chaosaffe
·
3Comments
chaosaffe
·
3Comments
 Aisuko
·
3Comments
Aisuko
·
3Comments
 lavalamp
·
3Comments
lavalamp
·
3Comments
 spzala
·
4Comments
spzala
·
4Comments
Most helpful comment
@idvoretskyi @spiffxp @justinsb -- this will be completed by Friday end of day. Might need a day or two to take effect.
I got the approval and added enough credits to cover current expenses and add buffer.
/cc @countspongebob