Spinalcordtoolbox: Packaging
We rely on a separate shell script (install_sct) to take care of installation. Ideally, we would publish SCT on PyPI and install using pip. (Alternatively, we could choose conda or distribution-specific package managers, but for now this issue focuses on pip.)
Current blockers
- [ ]
torch+cpu: The lighter CPU version of PyTorch is not on PyPI, so we currently rely on--find-linksto install, butsetup.pymakes it difficult to install packages from non-PyPI sources.
- More background context: https://github.com/spinalcordtoolbox/spinalcordtoolbox/issues/1526#issuecomment-674330466
- PyTorch issue for missing PyPI version: https://github.com/pytorch/pytorch/issues/26340,
- Pip discussion for the
--find-linkslimitation: https://github.com/pypa/pip/issues/5898#issuecomment-674329661
- [ ]
sct_download_data: Some of SCT's dependencies (model files, datasets) can't be included in SCT due to their size. We have our own download manager to install these dependencies, but currently it must be invoked manually insideinstall_sct.
- We can't use a
setup.pypost-installation hook because of https://github.com/spinalcordtoolbox/spinalcordtoolbox/issues/1526#issuecomment-812241357 - We're exploring packaging the dependencies into their own
pippackages in https://github.com/spinalcordtoolbox/spinalcordtoolbox/issues/2669 and https://github.com/spinalcordtoolbox/spinalcordtoolbox-data-template/pull/1.
- We can't use a
Other TODOs
- [ ]
version.txt: We should consider moving this toversion=insidesetup.py. - [ ]
requirements.txt: This isn't really arequirements.txtfile. Its purpose is closer toinstall_requires=insidesetup.py. - [ ]
requirements-freeze.txt: For stable releases, we include a second (stricter) requirements file generated bypip freezeat the time of release. Our installer checks for the presence of this file, and if it's there, it's used instead ofrequirements.txt.
- We can keep this, but simply distribute the file separately, and let the user decide if they want the frozen versions of all dependencies based on their use case.
- [ ]
$PATH: Currently,install_sctmodifies the user's PATH to make CLI scripts available to be run from anywhere. We would have to verify if apipinstall successfully accomplishes the same thing (console_scripts).
 zougloub
zougloub
All 46 comments
EDIT: Hidden because the information is outdated.
Pending issues:
version.txtissue (something should be underspinalcordtoolbox/)- Launcher (which helps mostly for MPI) should be optional by default
- frozen requirements (prevents installation along other libraries that would require newer versions)
- requirements are split between pip and conda, the default should be all-pip with the installer doing its custom thing
- dataset storage (either bundle sct_example_data / sct_testing_data or provide API to download it?)
zougloub
on 8 Aug 2018
I wonder what's the status on this. pip does most of the work in ./install_sct now. We still need to use sct_download_data to get the bin/ folder and the pre-trained models.
I am leaning towards trying to package the contents of bin/ and the models folders with pip. Then we could version them in one place (requirements.txt), would be integrated in the python system, and would have access to pypi's mirrors, and we wouldn't have to maintain our own package manager. See #2669.
If we also did some work to write an up-to-date setup.py (or maybe the improved pyproject.toml?) then installing should just be pip install ..
 kousu
on 21 Apr 2020
kousu
on 21 Apr 2020
Just a note on some research I stumbled into:
Right now pip install . does not install the package, and python setup.py build will make a broken package, because all the dependencies are declared in requirements.txt. A common hack (used by e.g. https://github.com/neuropoly/axondeepseg) to glue the two together ((in contravention of python's supposed "there should be one obvious way to do it") is to read the requirements.txt file into setup.py. But I would just put the requirements in setup.py directly and forget about requirements.txt. Either way, I believe we need to something about it if we're going to be packagable.
However there is a snag to this migration. We're depending on torch+cpu now (#2715 -- because it's sooo much smaller) but that is not on pypi; instead it's over at https://download.pytorch.org/whl/cpu/torch_stable.html, which is a pip install --find-links URL. So to make the install reproducible, we put this URL into our requirements.txt:
The snag: setup.py doesn't support --find-links; it also doesn't support --extra-index-url, which is the same as --find-links but over the pypi protocol instead of basic HTTP+HTML. It _used to_ support dependency_links but that's gone now (https://github.com/pypa/pip/issues/6162, https://github.com/pypa/pip/issues/4187) without any upgrade path -- the only upgrade path is to point at a prebuilt .whl, or a specific source code, which does not work for us because we use wheels with platform-specific compiled extensions in them. --find-links handles this fine: it knows how to choose between
- https://download.pytorch.org/whl/cpu/torch-1.5.0%2Bcpu-cp27-cp27m-linux_x86_64.whl
- https://download.pytorch.org/whl/cpu/torch-1.5.0%2Bcpu-cp35-cp35m-win_amd64.whl
- https://download.pytorch.org/whl/cpu/torch-1.5.0-cp36-none-macosx_10_9_x86_64.whl
- ...
according to the platform it is on.
There's environment markers but there's only 80% compatible with the naming format used by wheels..and --find-links handles this fine already! And so did dependency_links!
Summarized at https://github.com/pypa/pip/issues/5898#issuecomment-674329661.
The New Thing Since Sliced Bread is pyproject.toml which I've seen..in.places that you maybe can specify your dependencies there too, but that isn't actually covered in that spec, and the rest of it is not at all ready for production use yet, IMO. And even if that is the way of the future, I still doubt they'll support --find-links there (pypa took out the previous iteration of this feature, dependency_links without telling anyone: https://github.com/pypa/pip/issues/6162).
As I see it we can either:
- advocate for pytorch to publish
torch+cpuon pypi? - give up on packaging and publishing to pypi and stick with telling people to
pip install -r requirements.txt && pip install . - switch back to the full 700MB
torchinstall
I think option 1 is the only long term solution. We should start talking to pytorch now to get the gears turning if we want to be able to make pip install spinalcordtoolbox work.
--
While I'm here, let me write down that we can also shorten option 2. If requirements.txt contains just
# install this package
-e .
# ... the rest of the dependencies
(the -e is because that's what what we currently do:
; we could split it up into a requirements.txt and
# requirements-user.txt
.
-r requirements.txt
# requirements-dev.txt
-e .
- r requirements.txt
but this is all kind of terrible.
)
kousu
on 15 Aug 2020
I think option 1 is the only long term solution. We should start talking to pytorch now to get the gears turning if we want to be able to make pip install spinalcordtoolbox work.
👍 would you mind get the ball rolling and post an issue on their website (if there isn't any already, which would be surprising?)
 jcohenadad
on 15 Aug 2020
jcohenadad
on 15 Aug 2020
They're on it: https://github.com/pytorch/pytorch/issues/26340
kousu
on 15 Aug 2020
Ah but https://github.com/python-poetry/poetry/issues/1391#issuecomment-654291218
Why the hell isn't a big project like PyTorch published on a PEP-conform index? I opened an issue (pytorch/pytorch#26340) some time ago -- so far without any concrete reaction.
kousu
on 15 Aug 2020
I kind of think torch is going to leave us in the lurch here. Their focus is on cloud-scale computing efforts to push the frontier of ML, not single user workstations.
I figured out a very stupid workaround. I haven't tested it but it might work:
torch@https://download.pytorch.org/whl/cpu/torch-1.5.0%2Bcpu-cp36-cp36m-win_amd64.whl; python_implementation=="cpython" && python_version~="3.6" && sys_platform == "windows" && platform_machine == "x86_64"
torch@https://download.pytorch.org/whl/cpu/torch-1.5.0%2Bcpu-cp37-cp37m-win_amd64.whl; python_implementation=="cpython" && python_version~="3.7" && sys_platform == "windows" && platform_machine == "x86_64"
torch@https://download.pytorch.org/whl/cpu/torch-1.5.0%2Bcpu-cp38-cp38m-win_amd64.whl; python_implementation=="cpython" && python_version~="3.8" && sys_platform == "windows" && platform_machine == "x86_64"
torch@https://download.pytorch.org/whl/cpu/torch-1.5.0-cp36-none-macosx_10_12_x86_64.whl; python_implementation=="cpython" && python_version~="3.6" && sys_platform == "darwin" && platform_relase ~= "16.7.0" && platform_machine == "x86_64"
torch@https://download.pytorch.org/whl/cpu/torch-1.5.0-cp37-none-macosx_10_12_x86_64.whl; python_implementation=="cpython" && python_version~="3.7" && sys_platform == "darwin" && platform_relase ~= "16.7.0" && platform_machine == "x86_64"
torch@https://download.pytorch.org/whl/cpu/torch-1.5.0-cp38-none-macosx_10_12_x86_64.whl; python_implementation=="cpython" && python_version~="3.8" && sys_platform == "darwin" && platform_relase ~= "16.7.0" && platform_machine == "x86_64"
# btw platform_release gives the kernel version on darwin, so it doesn't directly map to the OS release numberings used
torch@https://download.pytorch.org/whl/cpu/torch-1.5.0%2Bcpu-cp36-cp36m-linux_x86_64.whl; python_implementation=="cpython" && python_version~="3.6" && sys_platform == "linux" && platform_machine == "x86_64"
torch@https://download.pytorch.org/whl/cpu/torch-1.5.0%2Bcpu-cp37-cp37m-linux_x86_64.whl; python_implementation=="cpython" && python_version~="3.7" && sys_platform == "linux" && platform_machine == "x86_64"
torch@https://download.pytorch.org/whl/cpu/torch-1.5.0%2Bcpu-cp38-cp38m-linux_x86_64.whl; python_implementation=="cpython" && python_version~="3.8" && sys_platform == "linux" && platform_machine == "x86_64"
Okay so here's the deal: until if or when https://github.com/pytorch/pytorch/issues/26340 happens, we're going to have to instruct users to install the packaged SCT like this:
pip install -f https://download.pytorch.org/whl/cpu/torch_stable.html spinalcordtoolbox
PyPA insists this is a security measure, about user consent: https://github.com/pypa/pip/issues/5898#issuecomment-674457168. I am behind respecting user consent but their position seems a bit inconsistent; the current pip install -r requirements.txt sidesteps it neatly, and they don't seem concerned about that. In fact, we could write:
# install.txt
-f https://download.pytorch.org/whl/cpu/torch_stable.html spinalcordtoolbox
spinalcordtoolbox@git+https://github.com/neuropoly/spinalcordtoolbox.git@master
And instruct people to install via
pip install -r https://github.com/neuropoly/spinalcordtoolbox/blob/master/install.txt
But I'm going to not worry further about this for now. This is still a future plan at this point.
kousu
on 16 Aug 2020
We could also aim to get packaged in conda. In fact I would say we should aim to do both. git-annex has this nice page showing all the places its packaged: https://git-annex.branchable.com/install/; conda is on there, along with each other distro's package manager(s), and I think that's Very Friendly.
kousu
on 16 Aug 2020
Re: torch-cpu issues, because we're using a conda environment for our SCT install, is there any reason we can't use conda install pytorch torchvision cpuonly -c pytorch (Select conda, Python, None here) to solve this?
Currently we're pip install-ing everything within our conda environment, but... conda is conda for a reason!
 joshuacwnewton
on 17 Aug 2020
joshuacwnewton
on 17 Aug 2020
If we went that route we would never be able to get pip install spinalcordtoolbox to work. We would have to only be conda install -c conda-forge spinalcordtoolbox. ...
But I'm getting more and convinced that conda has their game together much more than PyPA. For example, they have declarative packaging manifests that can cover any dependency, not just python ones. If we just declared for conda that would solve #2669 much more elegantly: we could write a conda package for each of our non-python dependencies and get them built and distributed reliably.
(and while we're floating ideas, we'd have all the same features if we declared for nix, which @bcdarwin could help us with)
You've used conda a lot more than me: would that involve replacing pip install -r requirements.txt with conda somethingsomething? Is there a conda equivalent to pip install -e?
kousu
on 17 Aug 2020
You've used conda a lot more than me: would that involve replacing
pip install -r requirements.txtwithconda somethingsomething? Is there a conda equivalent topip install -e?
in the old days, we used to have some dependencies installed with pip, and other with conda, e.g.:
https://github.com/neuropoly/spinalcordtoolbox/blob/9e155bd75aa21515e899ac0d15402dcbc080272b/install/requirements/requirements.sh
jcohenadad
on 18 Aug 2020
Maybe we won't end up using this but I just learned about https://github.com/chriskuehl/dumb-pypi
It's a static site generator for PyPI servers. I am all for this. It means we could deploy our own PyPI with our own software on it without "polluting" the main one.
kousu
on 16 Dec 2020
I was hesitating to be downloading pypi files or creating one from scratch when it was question of providing an installation means for those who don't have pypi connectivity (in great countries like Iran or China), had also explored crazy stuff like providing root CAs for hacked conda mirrors (!) but ended up not doing any of it. If conda is not used anymore it may be viable to be able to create a pypi repo in some situations (eg. SCT courses with poor internet connectivity).
zougloub
on 17 Dec 2020
Good references on real world python packaging: https://blog.ionelmc.ro/2014/06/25/python-packaging-pitfalls/, https://blog.ionelmc.ro/2014/05/25/python-packaging/
Maybe these are out of date by now?
kousu
on 30 Dec 2020
As part of this we should get rid of this section of code: https://github.com/neuropoly/spinalcordtoolbox/blob/3dfd4f81f9e4364dab4d94894ea687a625dbdea5/spinalcordtoolbox/utils/sys.py#L274-L292
its only purpose is to serve the 6 or so isct_* apps that we are currently packaging as sct_download_data -d binaries_linux or sct_download_data -d binaries_osx.
We should also drop this one
We should instead be adding the location of all our tools to PATH at install time. My current best plan is to package them as python packages, so that they get installed to the python environments's bin/ folder, whether that's ~/.local/bin or $VENV/bin/.
kousu
on 7 Jan 2021
https://nitter.net/dustyweb/status/1353459955861434368#m
https://tracker.debian.org/pkg/guix
Guix has made it into Debian Unstable! This means Debian users can use Guix as a "userspace" package manager now! tracker.debian.org/pkg/guix
This is really wonderful! Debian and Guix both care deeply about reproducibility.
This could be a big win for user freedom on both
Many important otherwise-FOSS applications are only available via black-box containers assembled from a mess of incompatible specific-language package managers. This is terrible.
However, Guix can be used to set up dev environments which are reproducible in userspace
For a long time this disconnect happened b/c distros that care about buildability/reproducibility were disconnected from new dev environments, which were done in userspace package managers.
But Guix comes with something like a universal virtualenv: "guix environment"!
Lots of people have good reason to run Debian. But now they can use Guix for dev, too!
And what is packageable for Guix tends to be packageable for Debian and vice versa.
Thus this could be a path out from one of the biggest problems user freedom faces: unbuildable software.
Guix is essentially the same idea as nix. Different language/format/etc but the big idea is: install everything in distinct virtualenvs that are allowed to share other virtualenvs as dependencies.
It's the best of both worlds: reusable libraries, efficient updates, but pinned dependencies.
I think one or the other is the best packaging target we can aim for. it's better than distributing via conda, better than giving out black-box docker images. The fact that you can apt-get install guix now means we could be accessible, reliably, to 99% of our users.
The trouble with pip install spinalcordtoolbox is that we need to include a lot of non-python code, which pip can only handle with gymnastics. My current plan is still to make that work for this year, but in 2 or 3 years I think we should seriously consider guix. Plus anything packaged with guix should be translatable to .deb and .rpm and flatpak and whatever because it actually specifies the complete set of dependencies fully and in a way that tools can handle.
kousu
on 25 Jan 2021
On a whim, I decided to take another stab at trying to download the data/binaries as a pip post-install step. (This was a blocker @Drulex encountered in his experiments on his aj/pip-only-install branch. He had a working solution going for sdists, but not for wheels.)
I ended up finding a relevant issue requesting this feature: https://github.com/pypa/packaging-problems/issues/64. It's filled with discussion over whether wheels should even provide a post-install hook. I then restarted discussion explaining our use-case (https://github.com/pypa/packaging-problems/issues/64#issuecomment-812051467), and as a result there's been a lot of good back and forth today from PyPA folks and devs.
The ultimate conclusion was that post-install hooks are not recommended and won't be supported any time soon. Instead we should be using either manual post-install step (e.g. asking users to run something like sct_download_data --all). Or, if we absolutely need automation, we should run a check in the package-level __init__.py to download the data on first import.
I agree with this, and found their reasoning compelling. I'm especially taken by the ideas in https://github.com/pypa/pip/issues/5898#issuecomment-674457168.
[...] brought along with it a rash of issues where "pip install " would depend on an unknownable set of servers outside of just their configured locations. This caused a number of problems, most obviously in locked down environments where accessing a service required getting a hole punched in a firewall, [...]
Basically, a user should be in charge of where they download files from, it should not be something under someone else's control.
I like the idea of giving the user transparency + control over where/when we download things. (We've even run into issues before where a user was unable to download data/binaries due to their location, and it broke their installation as a result.) So, I think I'm in favor of decoupling the download step from the installation process once we're able to go the pip route.
joshuacwnewton
on 2 Apr 2021
If we do decide to separate data downloading from installation, @zougloub mentioned a very interesting library called Pooch. It does a lot of what we've been trying to do with data (sct_download_data, test data validation, etc.)
Though, I'm getting a bit off topic from the main issue now (#1526), which is more about packaging + pip installation for SCT. The pytorch-cpu issues are the main roadblock here, and data-related planning can come after.
joshuacwnewton
on 2 Apr 2021
For pytorch+cpu, one slight modification to https://github.com/neuropoly/spinalcordtoolbox/issues/1526#issuecomment-674582208 could be:
# Install spinalcordtoolbox + torch
pip install spinalcordtoolbox[gpu]
# Install spinalcordtoolbox + torch+cpu
pip install spinalcordtoolbox[cpu] -f https://download.pytorch.org/whl/cpu/torch_stable.html
Corresponding setup.py
# setup.py
setup(
name='spinalcordtoolbox',
install_requires=requirements, # Non-PyTorch requirements
extras_require={
'gpu': [
'torch==1.5.0',
'torchvision==0.6.0'
],
'cpu': [
'torch==1.5.0+cpu',
'torchvision==0.6.0+cpu'
],
},
)
If only default extras were a thing... Then we would be able to do something like this:
# Install spinalcordtoolbox + torch
pip install spinalcordtoolbox
# 'cpu' would install torch+cpu, but also override the default 'torch' extra
pip install spinalcordtoolbox[cpu] -f https://download.pytorch.org/whl/cpu/torch_stable.html
I also came across light-the-torch, which was created as a drop-in pip replacement to address the pytorch distribution issues. I'm not sure it's applicable for us, but it's interesting to see the lengths people will go to try to address this.
joshuacwnewton
on 3 Apr 2021
Hey this is cool research. Thanks a lot for diving in. It feels like a life-preserver thrown off the ship!
ltt is not the way I would prefer to solve this, but :+1: to seeing the lengths people will go. I keep coming back to that post you showed me which explains that python has long just not been ready to handle packaging large codebases with lots of compiled extensions.
The genesis of Conda came after Guido van Rossum was invited to speak at the inaugural PyData meetup in 2012; in a Q&A on the subject of packaging difficulties, he told us that when it comes to packaging, "it really sounds like your needs are so unusual compared to the larger Python community that you're just better off building your own" (See video of this discussion)
I am still going to push pip as far as we can. Some standard is better than no standard.
On my end, I found this which seems to underscore a lot of the trouble we're all having figure out packaging: https://stackoverflow.com/questions/58753970/how-to-build-a-source-distribution-without-using-setup-py-file. In short, contradicting "Special cases aren't special enough to break the rules. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it.", there's currently 4 major competing packaging systems for python (maybe 5 or 6 if you add conda and pipx) and to make everyone happy they a. refused to make a decision, instead deciding to solve it by indirection, adding pyproject.toml that lets you specify the system to use b. there's a lot of infighting anyway.
But also from that, I learned that we can drop setup.py and requirements.txt entirely in favour of pyproject.toml if we use
pip install build
python -m build --wheel --sdist
The template from one of pip's busiest maintainers at https://github.com/jaraco/skeleton/ shows having all of setup.cfg, setup.py, pyproject.toml and tox.ini (for testing). I think that's pretty ridiculous. Their setup.py is just a placeholder:
#!/usr/bin/env python
import setuptools
if __name__ == "__main__":
setuptools.setup()
which is only there so you can say python setup.py bdist_wheel. python -m build --wheel is the vetted replacement for python setup.py bdist_wheel. (I would expect there to be a pip build command; afterall, pip install can install from source, creating an identical install as if installing from a .whl off pypi, so it can do builds, but I haven't found (yet?) a way to get it to output a .whl we can redistribute.)
kousu
on 3 Apr 2021
unf nevermind. You can't get away with just a single pyproject.toml file yet. It's pretty hard to find working samples of pyproject.toml (one of the reasons I and I think most of the python scene is still pretty skeptical about it) but I did try this one:
[kousu@requiem t]$ ls -l
total 16
-rw-r--r-- 1 kousu kousu 842 Apr 3 18:01 pyproject.toml
[kousu@requiem t]$ cat pyproject.toml
[project]
name = "infer_pyproject"
version = "0.1.0"
description = "Create a pyproject.toml file for an existing project."
authors = [
"Martin Thoma <[email protected]>"
]
license = "MIT"
readme = "README.md"
python = "^3.6"
homepage = "https://github.com/MartinThoma/infer_pyproject"
repository = "https://github.com/MartinThoma/infer_pyproject"
documentation = "https://github.com/MartinThoma/infer_pyproject"
keywords = ["packaging", "dependency", "infer", "pyproject.toml"]
classifiers = [
"Topic :: Software Development"
]
# Requirements
[dependencies]
Click = "^7.0"
[dev-dependencies]
black = { version = "^18.3-alpha.0", python = "^3.6" }
[scripts]
poetry = "infer_pyproject.cli:main"
[build-system]
requires = [
"setuptools >= 35.0.2",
"setuptools_scm >= 2.0.0, <3"
]
build-backend = "setuptools.build_meta"
[kousu@requiem t]$ python -m build --wheel
Collecting setuptools_scm<3,>=2.0.0
Using cached setuptools_scm-2.1.0-py2.py3-none-any.whl (20 kB)
Collecting setuptools>=35.0.2
Using cached setuptools-54.2.0-py3-none-any.whl (785 kB)
Installing collected packages: setuptools-scm, setuptools
Successfully installed setuptools-54.2.0 setuptools-scm-2.1.0
running egg_info
creating UNKNOWN.egg-info
writing UNKNOWN.egg-info/PKG-INFO
writing dependency_links to UNKNOWN.egg-info/dependency_links.txt
writing top-level names to UNKNOWN.egg-info/top_level.txt
writing manifest file 'UNKNOWN.egg-info/SOURCES.txt'
reading manifest file 'UNKNOWN.egg-info/SOURCES.txt'
writing manifest file 'UNKNOWN.egg-info/SOURCES.txt'
Collecting wheel
Using cached wheel-0.36.2-py2.py3-none-any.whl (35 kB)
Installing collected packages: wheel
Successfully installed wheel-0.36.2
running bdist_wheel
running build
installing to build/bdist.linux-x86_64/wheel
running install
running install_egg_info
running egg_info
writing UNKNOWN.egg-info/PKG-INFO
writing dependency_links to UNKNOWN.egg-info/dependency_links.txt
writing top-level names to UNKNOWN.egg-info/top_level.txt
reading manifest file 'UNKNOWN.egg-info/SOURCES.txt'
writing manifest file 'UNKNOWN.egg-info/SOURCES.txt'
Copying UNKNOWN.egg-info to build/bdist.linux-x86_64/wheel/UNKNOWN-0.0.0-py3.9.egg-info
running install_scripts
creating build/bdist.linux-x86_64/wheel/UNKNOWN-0.0.0.dist-info/WHEEL
creating '/home/kousu/src/neuropoly/sysadmin/infersent-data-model1/t/dist/tmplc6ui5k_/UNKNOWN-0.0.0-py3-none-any.whl' and adding 'build/bdist.linux-x86_64/wheel' to it
adding 'UNKNOWN-0.0.0.dist-info/METADATA'
adding 'UNKNOWN-0.0.0.dist-info/WHEEL'
adding 'UNKNOWN-0.0.0.dist-info/top_level.txt'
adding 'UNKNOWN-0.0.0.dist-info/RECORD'
removing build/bdist.linux-x86_64/wheel
[kousu@requiem t]$ ls -l
total 16
drwxr-xr-x 3 kousu kousu 4096 Apr 3 18:01 build
drwxr-xr-x 2 kousu kousu 4096 Apr 3 18:01 dist
-rw-r--r-- 1 kousu kousu 842 Apr 3 18:01 pyproject.toml
drwxr-xr-x 2 kousu kousu 4096 Apr 3 18:01 UNKNOWN.egg-info
and it still does the same even with the latest pip
[kousu@requiem t]$ pip3 install --user pip==21.0.1
Collecting pip==21.0.1
Downloading pip-21.0.1-py3-none-any.whl (1.5 MB)
|████████████████████████████████| 1.5 MB 3.1 MB/s
Installing collected packages: pip
Successfully installed pip-21.0.1
[kousu@requiem t]$ ~/.local/bin/pip3 --version
pip 21.0.1 from /home/kousu/.local/lib/python3.9/site-packages/pip (python 3.9)
[kousu@requiem t]$ ~/.local/bin/pip3 install .
Defaulting to user installation because normal site-packages is not writeable
Processing /home/kousu/src/neuropoly/sysadmin/infersent-data-model1/t
Installing build dependencies ... done
Getting requirements to build wheel ... done
Installing backend dependencies ... done
Preparing wheel metadata ... done
Building wheels for collected packages: UNKNOWN
Building wheel for UNKNOWN (PEP 517) ... done
Created wheel for UNKNOWN: filename=UNKNOWN-0.0.0-py3-none-any.whl size=981 sha256=bc7c736883ea2ed1d684c64a2bebfde71f3819ab545075a057e5a0cf3a14415b
Stored in directory: /tmp/pip-ephem-wheel-cache-ttwxpj5h/wheels/8d/f1/d3/c57274a6f4d3b55e097bd1356db25d0ca82b312f3795099dfc
Successfully built UNKNOWN
Installing collected packages: UNKNOWN
Attempting uninstall: UNKNOWN
Found existing installation: UNKNOWN 0.0.0
Uninstalling UNKNOWN-0.0.0:
Successfully uninstalled UNKNOWN-0.0.0
Successfully installed UNKNOWN-0.0.0
But it's broken. And it broke without erroring, it just filled in nulls ("UNKNOWN", "0.0.0") everywhere. So I'm not super impressed with that.
It looks like this is supposed to work, but the spec isn't finished yet. The spec that covers putting everything else into pyproject.toml is only ~8 months old: https://www.python.org/dev/peps/pep-0621/. But even it doesn't cover all the features most projects use, notably, include_package_data and packages = (I have no idea what their plan for those are).
However we can't ignore it and stick with setup.py either because we need to have wheel installed at build-time for reliable installs, but setup_requires is deprecated and pip/setuptools/whatever doesn't check it early enough ((despite it apparently being respected since if I add torch to it the build takes forever, presumably busily downloading the 1GB of pytorch)), to figure out it needs to install wheel too; and without that, it quietly installs using the old format not the new format which is going to cause us headaches if we don't stomp it out. )); so evidently the only way to get pip to reliably install things properly is to use this dummy 2 line pyproject.toml
[build-system]
requires = ["setuptools>=40.8.0", "wheel"]
and stick with setup.py.
kousu
on 4 Apr 2021
I haven't found (yet?) a way to get it to output a .whl we can redistribute.)
durp, it's pip wheel.
...so why does anyone need python -m build?
kousu
on 4 Apr 2021
:laughing: Adding pyproject.toml causes pip install -e . to stop working https://github.com/pypa/pip/issues/7953
Workarounds are:
pip install --user --no-use-pep517 -e .
or add
import site
import sys
site.ENABLE_USER_SITE = "--user" in sys.argv[1:]
or just
import site, sys; site.ENABLE_USER_SITE = True
to setup.py.
This doesn't show up in CI or docker or in virtualenvs, only if you're developing in your plain homedir which I guess is out of fashion these days :(
kousu
on 4 Apr 2021
https://github.com/pypa/warehouse/issues/7852 -> we're not the only ones needing to distribute large binaries as part of python projects. I agree with this person that we should be using pip if we can; I don't like the ntlk.download(); but it seems unavoidable when datasets get so large.
kousu
on 4 Apr 2021
I haven't found (yet?) a way to get it to output a .whl we can redistribute.)
durp, it's
pip wheel....so why does anyone need
python -m build?
I figured it out:
Because, probably among a million other nuisances, pip wheel makes 4 copies of the product. build only makes 2: the staging copy and the zipped copy. It's at least 10 times faster and doesn't risk overrunning your disk nearly as easily.
kousu
on 4 Apr 2021
Experimentally, Pypi has a 1GB limit on files uploaded to it.
Github's is 2GB 100MB but they only tell you that after you've finished uploading, unless you go over 2GB in which case git just drops you; for anything we can't fit on pypi, for packaging data, we can easily use github with direct links, e.g.
extras_require={
'PAM50': [spinalcordtoolbox-data-pam50@https://github.com/neuropoly/spinalcordtoolbox/releases/download/5.2.0/pam50.whl],
This should be able to replace most of sct_download_data.
kousu
on 4 Apr 2021
Experimentally, Pypi has a 1GB limit on files uploaded to it.
Github's is ~2GB~ 100MB but they only tell you that after you've finished uploading, unless you go over 2GB in which case git just drops you; for anything we can't fit on pypi, for packaging data, we can easily use github with direct links, e.g.
extras_require={ 'PAM50': [spinalcordtoolbox-data-pam50@https://github.com/neuropoly/spinalcordtoolbox/releases/download/5.2.0/pam50.whl],This should be able to replace most of sct_download_data.
This works for install_requires too, right? I ask because it might be a bit awkward to have to manually specify every data/binary package (e.g. pip install spinalcordtoolbox[PAM50]).
joshuacwnewton
on 4 Apr 2021
(migrated to https://github.com/neuropoly/spinalcordtoolbox/issues/2669#issuecomment-814103749)
kousu
on 4 Apr 2021
(migrated to https://github.com/neuropoly/spinalcordtoolbox/issues/2669#issuecomment-814104144)
kousu
on 6 Apr 2021
@drulex found us https://www.fatiando.org/pooch/latest/processors.html. It's sct_download_data done cleanly and might be good if we find ourselves with datasets that don't fit into packages.
-- that is, are _too large_ to fit into packages. I think the benefits of using a standard package manager outweigh anything else.
kousu
on 6 Apr 2021
Reminder: we're hacking up PYTHONNOUSERSITE because packaging is hard.
- https://github.com/neuropoly/spinalcordtoolbox/issues/3067
- https://github.com/neuropoly/spinalcordtoolbox/issues/3200
- #3313
if we fix packaging I bet we can remove all lines that touch PYTHONNOUSERSITE.
EDIT: the right solution to get a fully isolated env is to change the conda env's site.py: https://github.com/conda/conda/issues/7173#issuecomment-389190657. It's actually still an open bug with conda. But that would probably still break the way #3200 did; hm; maybe the problem in #3200 is that sct_run_batch is silently running the wrong interpreter; maybe the better solution is to remove $SCT_DIR/python/bin/venv_sct/bin/ from PATH, since we don't want anything but us to be calling; if SCT is installed fully then all the sct_ commands are installed to SCT_DIR/bin/ not $SCT_DIR/python/bin/venv_sct/bin/?
For comparison, virtualenv does this by default, but has --system-site-packages to enable using (read-only) code in $PREFIX=/usr/(local/)?lib and ~/.local/ ((actually, side note: a virtualenv, at least a modern one, symlinks to the system python; so the system python must have some shim code in it that detects if it's in a virtualenv and adjusts sys.path accordingly. ((and the shim seems to operate by detecting the existence of $(dirname $0)/../pyvenv.cfg)). kinda gross :/)). Anyway that is pretty messy; I don't see why they couldn't just set $PYTHONSITE in a little wrapper shell script.
We shouldn't be changing this inside SCT itself.
EDIT: https://github.com/neuropoly/spinalcordtoolbox/pull/3339
kousu
on 6 Apr 2021
Replying to @kousu's comment here: https://github.com/spinalcordtoolbox/spinalcordtoolbox/issues/3163#issuecomment-814390093
version.txtshould be justsetup(..., version=...)IMO, which we can read back withimportlib.metadata.distribution('spinalcordtoolbox').version. That's the py3k way to do that afaict.
This is doable!
And
requirements-freeze.txtconflicts with making a pip-installable package because it forces you topip install -r requirements.txtand you can't use list SCT as a dependency in other software that way -- not without copying ourrequirements-freeze.txtinto your app.
requirements-freeze.txt is for the benefit of our non-developer users, so that they can install a specific version of SCT and trust that the results are are reproducible no matter when they install it.
But, you're right, there's a probably a better way of doing this once SCT is pip installable. One idea could be to stop including requirements-freeze.txt inside the package, but instead distribute a versioned requirements.txt file alongside each GitHub Release.
That way, if someone wants to install a specific version of SCT with pinned dependencies, they can download the file from the Release page and pip install -r requirements-X.Y.Z.txt into a venv. And because it's a GitHub-specific file, the main package on PyPI would be unaffected.
And actually why do we need a release branch anyway?
The main difference, I think, between release and master is that:
requirements-freeze.txtis only present inrelease, so it's included the downloads from the Release page (but nowhere else).version.txtisdevonmaster, but has a version number onrelease.
But, I agree that release might not be necessary if we do things as described above.
joshuacwnewton
on 7 May 2021
Something curious to possibly look into: The pbr package.
I came across this interesting StackOverflow post while trying to reason about version.txt above. The interesting part is this:
Probably you would observed that the version is not stored at all in the repository. PBR does detect it from Git branches and tags.
But it also does things like auto-generating a changelog (oops).
joshuacwnewton
on 7 May 2021
I've been staring hard at the pytorch-cpu problem, and the more I look, the more I get the sense we'll be waiting a very long time... The problems seem intractable on both the pip and PyTorch sides of things.
Given that, I wanted to prod at the base assumption we've been operating under all this time. In https://github.com/pypa/pip/issues/5898#issuecomment-674329661, @kousu said:
pytorch's pypi version is very large: it includes all the fancy GPU code needed for training neural network6s, and that, compiled, is about 600MB. That's way too much to ask our users to install, and it's too much even to ask CI to install.
Is it really too much to ask, though?
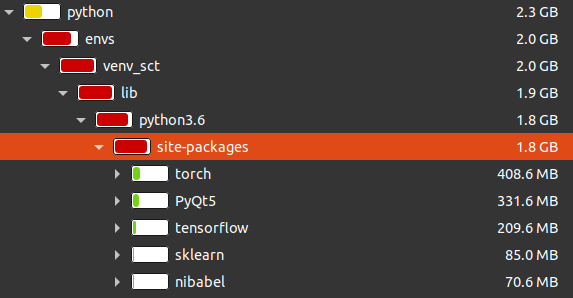
The
python folder in our installation directory is already 2.3GB
Using the full versions of
torch and torchvision increases this from 2.3GB to 3.3GB
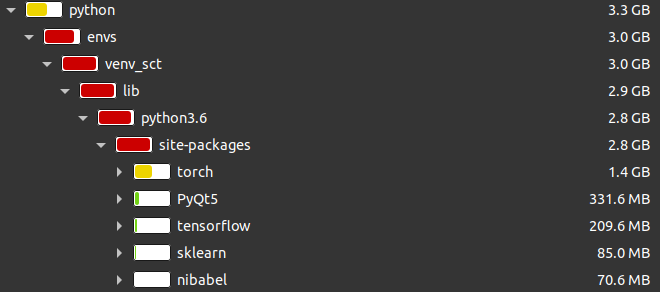
Some other thoughts:
- Our users typically work with large multi-subject datasets in professional research contexts (i.e. less likely to be using consumer-grade computers or small hard drives).
Other medical imaging software packages such as FSL, ANTs, minc-toolkit, etc. take up several GBs when installed.
ivadomedalso depends on the fulltorch. So, it might not be that much of a surprise to users that SCT has multi-GB installation too.
Size comparison for projects in my repository folder

- With the steadily decreasing costs of hard drives, perhaps a multi-GB installation isn't as much of a downside as it used to be.
- We can include instructions in our installation page for how to manually install
torch+cpu. We could even provide tworequirements.txtfiles alongside each stable release: One with-ffortorch+cpu, and one with fulltorch. That way, if disk usage _is_ an issue, the user can set up their virtualenv with the version most suitable for their situation.
Given all of this, would a switch to using the full torch by default be noticeable to our specific userbase? (In other words, do the costs still outweigh the benefits?)
_(And, since @kousu has also been working on the data/model/binary packaging, I believe switching to full torch would remove the last blocker for a pip install. If so, the timing might work out so that SCT v6.0.0 can be used for 2 big changes: a pip-installable SCT _and_ a Tensorflow-free sct_deepseg.)_
joshuacwnewton
on 16 May 2021
Thank you for your insights in https://github.com/spinalcordtoolbox/spinalcordtoolbox/issues/1526#issuecomment-841825285 @joshuacwnewton . These are not unreasonable arguments indeed. My take on this is, is that if we can "easily" solve the pytorch-cpu installation then we should do it, otherwise let's not waste too much time on this and opt for full pytorch installation. And we can leave the issue open so when/if the issue is fixed (by others) in the future, we can switch to pytorch-cpu
jcohenadad
on 16 May 2021
The
pythonfolder in our installation directory is already 2.3GB
This is already far too large. I want to cull it, not assume that's the status quo and grow it.
Can we shrink PyQt5? Qt has always been designed as a bunch of sub-libraries you can pick and choose from; oh, and also, https://pypi.org/project/PyQt5/5.15.4/#files is much smaller than https://pypi.org/project/PyQt5/5.11.3/#files; just installing the latest brought only 200MB instead of 300MB.
Using the full versions of
torchandtorchvisionincreases this from 2.3GB to 3.3GB
That's still a ~50% increase!
Our users typically work with large multi-subject datasets in professional research contexts (i.e. less likely to be using consumer-grade computers or small hard drives).
I think it's easy to skip smaller users when it seems like mainframes are popular. But not everyone is on a mainframe, and I feel strongly they shouldn't have to be. We shouldn't need to be either paying Amazon or Google or be under the umbrella of a well funded research org to be able to benefit from open source; open source is about being able to adapt technology for your uses, not discriminating (too much) by your situation; I want to think open science means about the same thing, and that that's what we're trying to support here.
I think, much like a lot of my working habits (:P), there's a tension where software never actually gets faster despite all the hardware and architecture improvements, because software expands to fill the space allocated to it. And we have to be on guard against that or else we just make super wasteful designs.
Even personally, I can't work on SCT if it's this large. I am already juggling multiple VMs, datasets and other projects. An extra gig can sometimes be the difference between being able to do my work or not, especially because it's not just one gig, it's at least two: the cached copy in ~/.cache/pip and the installed copy. And because we're telling people to use a containerized environment every install is another gig+. Even just installing ivadomed at the same time means I don't have enough space to actually install any datasets for either of them to operate on.
And yeah, I could probably tidy up my system, I could buy more harddrives, I could build a storage NAS in my house and keep my VMs there, but why should I? I don't want to wrestle with SCT.
I wouldn't mind so much depending on the full torch if we were telling people to install it globally or from their OS package manager.
kousu
on 16 May 2021
I think it's easy to skip smaller users when it seems like mainframes are popular. But not everyone is on a mainframe, and I feel strongly they shouldn't have to be. We shouldn't need to be either paying Amazon or Google or be under the umbrella of a well funded research org to be able to benefit from open source; open source is about being able to adapt technology for your uses, not discriminating (too much) by your situation; I want to think open science means about the same thing, and that that's what we're trying to support here.
Well, we wouldn't be completely shutting out these users. It should still be easy enough to install torch+cpu for the people who need it, it just would no longer be the default behavior. I was thinking we would have installation instructions that say something like:
_"By default, the pip installation of SCT depends on the GPU version of PyTorch. However, you can reduce the size of the SCT installation by installing the CPU version of PyTorch instead. PyTorch doesn't provide the CPU version of the package via PyPI, so you will need to install it using
"_
To me, this seems like the best of all worlds... we get the pip install, we offer a Plan B for space-constrained users, and we can be transparent about the fact that the CPU version doesn't come from PyPI (which satisfies the pip dev's concerns in https://github.com/pypa/pip/issues/5898#issuecomment-674457168 about silently fetching packages from non-official sources -- the user gets to opt-in to the PyTorch package index.)
joshuacwnewton
on 16 May 2021
Is this a fair assessment? I wasn't necessarily thinking about mainframes. A 2TB drive is, what, $75... is this out of reach of smaller users? (Maybe I'm out of touch here -- admittedly I'm a bit of a data hoarder, so I've got a lot of 2TB-4TB drives lying about.)
I don't think that's usual.
Well, we wouldn't be completely shutting out these users. It should still be easy enough to install torch+cpu for the people who need it, it just would no longer be the default behavior.
It's easy to make things inaccessible without realizing what you're doing, like adding ledges to sidewalks or using a palette with too much red/green contrast. I bet the more constrained users are the ones who are going to have more trouble with technical work-arounds.
And what about about CI or other pipeline systems? Adding torch will right now slow down our Linux CIs by a minute or two. And say SCT gets archived into some Singularity containers; that means every archived version is now lugging around an extra 800MB of dead weight that will never be used for anything, but needs to be there for integrity checks to pass, simply because the torch people couldn't split up their tool into reasonable subpackages.
kousu
on 16 May 2021
And what about about CI or other pipeline systems? Adding torch will right now slow down our Linux CIs by a minute or two
If SCT becomes pip-installable, then we should gain access to Python dependency caching solutions. I don't think we've ever had access to that because of the nonstandard way SCT installs itself, so I'm not sure we would see a slow down.
Also, IIRC @Drulex's experimentation for a pip install showed a dramatically quicker installation overall. I'll have to double-check the logs.
EDIT: The logs had expired, so I forked and re-ran. The branch is quite out of date, so the test suite fails, but to give a rough estimate, the total runtime is 6m43. If we use dependency caching, we can cut into the 1m45 spent on dependencies, so it might be closer to 5m. That alone would be a big improvement over our current CI times, even in the worst case scenario (i.e. not a slowdown).
joshuacwnewton
on 16 May 2021
It's easy to make things inaccessible without realizing what you're doing, like adding ledges to sidewalks or using a palette with too much red/green contrast. I bet the more constrained users are the ones who are going to have more trouble with technical work-arounds.
I'm very much in support of accessible design. But, if a one-line install command is too technical, then that would call into question the very plan of switching to a pip install, since pip installing SCT necessarily requires users to understand at least the basics of Python packaging (pip, PyPI, requirements.txt, virtualenvs). We were going to have to do at least some teaching, weren't we? :sweat_smile:
We do have the forum, too. So, the users wouldn't be completely left out. I imagine we would save time not having to debug install_sct issues, so I would hope that the time spent helping folks on the forum with pip would even out.
joshuacwnewton
on 16 May 2021
oh perfect, to underscore my point:
(test3) u108545@rosenberg:~$ pip install tensorflow==1.15.0
Collecting tensorflow==1.15.0
Downloading tensorflow-1.15.0-cp37-cp37m-manylinux2010_x86_64.whl (412.3 MB)
|████████████████████████████████| 412.3 MB 38 kB/s
Collecting google-pasta>=0.1.6
Using cached google_pasta-0.2.0-py3-none-any.whl (57 kB)
Collecting wrapt>=1.11.1
Using cached wrapt-1.12.1.tar.gz (27 kB)
Collecting gast==0.2.2
Using cached gast-0.2.2.tar.gz (10 kB)
Collecting protobuf>=3.6.1
Downloading protobuf-3.17.0-cp37-cp37m-manylinux_2_5_x86_64.manylinux1_x86_64.whl (1.0 MB)
|████████████████████████████████| 1.0 MB 63.6 MB/s
Collecting tensorboard<1.16.0,>=1.15.0
Using cached tensorboard-1.15.0-py3-none-any.whl (3.8 MB)
Collecting numpy<2.0,>=1.16.0
Downloading numpy-1.20.3-cp37-cp37m-manylinux_2_12_x86_64.manylinux2010_x86_64.whl (15.3 MB)
|████████████████████████████████| 15.3 MB 67.8 MB/s
Collecting astor>=0.6.0
Using cached astor-0.8.1-py2.py3-none-any.whl (27 kB)
Collecting absl-py>=0.7.0
Using cached absl_py-0.12.0-py3-none-any.whl (129 kB)
Collecting tensorflow-estimator==1.15.1
Using cached tensorflow_estimator-1.15.1-py2.py3-none-any.whl (503 kB)
Requirement already satisfied: wheel>=0.26 in ./miniconda3/envs/test3/lib/python3.7/site-packages (from tensorflow==1.15.0) (0.36.2)
Collecting keras-preprocessing>=1.0.5
Using cached Keras_Preprocessing-1.1.2-py2.py3-none-any.whl (42 kB)
Collecting termcolor>=1.1.0
Using cached termcolor-1.1.0.tar.gz (3.9 kB)
Collecting opt-einsum>=2.3.2
Using cached opt_einsum-3.3.0-py3-none-any.whl (65 kB)
Collecting grpcio>=1.8.6
Downloading grpcio-1.37.1-cp37-cp37m-manylinux2014_x86_64.whl (4.2 MB)
|████████████████████████████████| 4.2 MB 71.0 MB/s
Collecting six>=1.10.0
Using cached six-1.16.0-py2.py3-none-any.whl (11 kB)
Collecting keras-applications>=1.0.8
Using cached Keras_Applications-1.0.8-py3-none-any.whl (50 kB)
Collecting h5py
Downloading h5py-3.2.1-cp37-cp37m-manylinux1_x86_64.whl (4.1 MB)
|████████████████████████████████| 4.1 MB 59.2 MB/s
Collecting werkzeug>=0.11.15
Using cached Werkzeug-2.0.0-py3-none-any.whl (288 kB)
Requirement already satisfied: setuptools>=41.0.0 in ./miniconda3/envs/test3/lib/python3.7/site-packages (from tensorboard<1.16.0,>=1.15.0->tensorflow==1.15.0) (49.6.0.post20210108)
Collecting markdown>=2.6.8
Using cached Markdown-3.3.4-py3-none-any.whl (97 kB)
Collecting importlib-metadata
Using cached importlib_metadata-4.0.1-py3-none-any.whl (16 kB)
Collecting cached-property
Using cached cached_property-1.5.2-py2.py3-none-any.whl (7.6 kB)
Collecting typing-extensions>=3.6.4
Using cached typing_extensions-3.10.0.0-py3-none-any.whl (26 kB)
Collecting zipp>=0.5
Using cached zipp-3.4.1-py3-none-any.whl (5.2 kB)
Building wheels for collected packages: gast, termcolor, wrapt
Building wheel for gast (setup.py) ... done
Created wheel for gast: filename=gast-0.2.2-py3-none-any.whl size=7538 sha256=88e947aa28809e06b5a93970b3f8cbf6b77fe16454f1adbef5b5ee1b84b710e7
Stored in directory: /home/GRAMES.POLYMTL.CA/u108545/.cache/pip/wheels/21/7f/02/420f32a803f7d0967b48dd823da3f558c5166991bfd204eef3
Building wheel for termcolor (setup.py) ... done
Created wheel for termcolor: filename=termcolor-1.1.0-py3-none-any.whl size=4829 sha256=21710a4e50bf248c2918d4f1b535a5173599720646cc1db14d722c8d083fa913
Stored in directory: /home/GRAMES.POLYMTL.CA/u108545/.cache/pip/wheels/3f/e3/ec/8a8336ff196023622fbcb36de0c5a5c218cbb24111d1d4c7f2
Building wheel for wrapt (setup.py) ... done
Created wheel for wrapt: filename=wrapt-1.12.1-cp37-cp37m-linux_x86_64.whl size=71048 sha256=1db13848785ada2c1d1c23f86499d41c6214a3f7106796a0efb521fffea2a742
Stored in directory: /home/GRAMES.POLYMTL.CA/u108545/.cache/pip/wheels/62/76/4c/aa25851149f3f6d9785f6c869387ad82b3fd37582fa8147ac6
Successfully built gast termcolor wrapt
Installing collected packages: zipp, typing-extensions, six, numpy, importlib-metadata, cached-property, werkzeug, protobuf, markdown, h5py, grpcio, absl-py, wrapt, termcolor, tensorflow-estimator, tensorboard, opt-einsum, keras-preprocessing, keras-applications, google-pasta, gast, astor, tensorflow
ERROR: Could not install packages due to an OSError: [Errno 28] No space left on device
This isn't my laptop, this is one of our computing clusters on campus. I'm trying to get tensorflow installed to debug some things -- not even all of SCT, or pytorch -- and I ran out of space.
(test3) u108545@rosenberg:~$ df -h .
Filesystem Size Used Avail Use% Mounted on
/dev/sda2 439G 416G 423M 100% /
It's all because of trying to use different combinations of large python dependencies:
(test3) u108545@rosenberg:~$ du -x -d 1 -h . | sort -h
4.0K ./duke
4.0K ./test
8.0K ./.conda
8.0K ./.gnupg
8.0K ./.keras
8.0K ./.local
8.0K ./.nv
1.3G ./gpus
1.8G ./.venv
3.7G ./.cache
19G ./miniconda3
26G .
Resources are never infinite!
kousu
on 16 May 2021
Ah, right. Is what's shown there just on your user account? Then that would be duplicated for each user if they're also installing SCT. So, increasing SCT by 1GB (x2 locations, including cache) is effectively increasing usage by 2GB per user, then?
I see your point... :sweat:
(Mind you, this might be more of a Rosenberg-specific issue, given that we also use it for storing datasets. We've discussed this previously in this Slack thread: https://neuropoly.slack.com/archives/CB22YP6K0/p1609968468233600)
joshuacwnewton
on 16 May 2021
Yeah that's just me. I assume other users have other stray venvs floating around with old code sitting idle too.
Sure there's extra scratch disks available but then you need to manage splitting your workload across them carefully. The default is always to install software in $HOME, if not installed at the OS level.
kousu
on 16 May 2021
All that said... unless another option comes along, our choices for moving forward are currently:
install_sct+ ~2GB default size.pip+ ~3GB default size (or ~2GB alternate install size if the user chooses to use--find-links+torch+cpu).
I feel like installation size is kind of a problem with _both_ options. Regardless of which path we go down, we're stuck with a heavy install until some other plan comes along. So, installation size feels a bigger problem that's separate from the packaging decision.
joshuacwnewton
on 16 May 2021
Related issues
jcohenadad
·
22Comments
jcohenadad
·
37Comments
jcohenadad
·
24Comments
 AdiVeeMiami
·
38Comments
AdiVeeMiami
·
38Comments
 gmotzespina
·
34Comments
gmotzespina
·
34Comments