Openrefine: Columnize by key/value column causes misalignment of columns
Importing data from several data sets with version 2.7, gives a result like this:
Column1;Column2
SourceFile1;2
SourceFile1;3
SourceFile1;-1
SourceFile2;3
SourceFile2;4
SourceFile2;6
SourceFile3;-3
SourceFile3;4
SourceFile3;1
When applying "Columnize by key/value column to Column1, the expectation is to get something like this:
SourceFile1;SourceFile2;SourceFile3
2;3;-3
3;4;4
-1;6;1
but instead, the following result is obtained:
SourceFile1;SourceFile2;SourceFile3
2;;
3;;
-1;3;-3
;4;4
;6;1
 belm104
belm104
All 27 comments
@ettorerizza you said on the ML that it is clearly a bug - do you know if there is any documentation anywhere explaining what this function is really supposed to do? From my understanding after reading the source code, it seems that this function just expects the initial data to be ordered by final row in the result, as follows:
Column1;Column2
SourceFile1;2
SourceFile2;3
SourceFile3;-1
SourceFile1;3
SourceFile2;4
SourceFile3;6
SourceFile1;-3
SourceFile2;4
SourceFile3;1
 wetneb
on 26 Jul 2017
wetneb
on 26 Jul 2017
Also pinging @ostephens who took part to the discussion on the mailing list.
wetneb
on 26 Jul 2017
Note that I said I thought this was a bug - I'm not 100% sure, but it behaves in a manner different to what I would expect. However, I can't find any documentation that says how it is meant to work, so all I can say is that it doesn't work in the desired manner. I don't know if this is the intended manner or not, although it seems unlikely for the following reasons:
My view is that at the moment the order of the data changes how the transpose function works - and that this is not expected (at least by me!). I'd expect Columnize by key/value to work the same no matter the order of the data initially, because the keys and values are the same whatever order is used.
At the moment using the same function on:
Column1;Column2
SourceFile1;2
SourceFile2;3
SourceFile3;-1
SourceFile1;3
SourceFile2;4
SourceFile3;6
SourceFile1;-3
SourceFile2;4
SourceFile3;1
Gives a different outcome to using it on
Column1;Column2
SourceFile1;2
SourceFile1;3
SourceFile1;-3
SourceFile2;3
SourceFile2;4
SourceFile2;4
SourceFile3;-1
SourceFile3;6
SourceFile3;1
This is particularly problematic in that the first ordering gives the desired outcome, while the second ordering does not, BUT there is no way to sort the second data set to be like the first data set - which means you cannot trivially solve this issue by re-sorting the data.
It also seems like a bug because I cannot think of a situation where the desired result would be to have the values in the second and third columns shifted down.
 ostephens
on 26 Jul 2017
ostephens
on 26 Jul 2017
@ostephens I agree it is confusing! (And I did understand that you were not sure it was a bug - my first comment was for @ettorerizza.) Here is how I understand the logic of the code.
It wants to support input cases like this one:
Key,Value
merchant,Katie
fruit,apple
price,1.2
fruit,pear
price,1.5
merchant,John
fruit,banana
price,3.1
which is (correctly) transposed to
merchant,fruit,price
Katie,apple,1.2
,pear,1.5
John,banana,3.1
(We insert a blank cell in the merchant column to create a record.)
To support this kind of input, the code needs to assume that the first column it encounters (here, SourceFile1) is the primary key. Then, for every other (key,value) pair (the ones that are not primary keys), OpenRefine assigns the pair to the last primary key it has encountered. This implies that the function is order-sensitive and explains the output @belm104 obtained.
As far as I can tell, this is a reasonable assumption. The input format @belm104 had to deal with seems rather uncommon. There could potentially be an option to switch between the two behaviours, but I suspect the current behaviour is useful for some users too (including myself actually)…
wetneb
on 26 Jul 2017
@belm104 your asking for something that doesn't apply to normal patterns. There's no notation or pattern or hint or key that could tell OpenRefine that the values need to be aligned a certain way other than the key column. The function only takes 1 KEY column and 1 VALUE column and converts the KEYs into columns... and then bins the values under each column. That's it. Its pretty dumb and simple and extremely useful.....but not for your case that you describe. And the expectation you described is an antipattern to my eyes. Its possible that your use case was a constant Ordinal value of 3 ? Since you have 3 rows for every key ? If that's your use case, then the correct function is actually Transpose. Choose your Column 2 to Transpose with a value of 3. But again, I still don't know if that's the pattern your actually trying to work with or not.
@wetneb is correct. We designed the Columnize and Transpose functions for simple cases. I.E. David and I never intended to have full Excel like Pivot Table functionality with them...although we wanted to get there by perhaps having a separate matrix dialog show on a new browser tab...and that did come up during conversations that would provide Pivot Table like functionality with more advanced features ... but it was on our long range plans that we discussed privately and never got worked on. But that has nothing to do with the expectaton of @belm104 and their use case which I still don't understand.
I would document the current behavior of Columnize (keys will be converted to columns and values for each will be binned under each key) and its intended uses on our wiki, but also note to users that its limited in functionality and not intended for full Pivot Table like functionality as found in Excel, and ETL tools.
 thadguidry
on 26 Jul 2017
thadguidry
on 26 Jul 2017
@thadguidry I still don't understand why @belm104 is an anti pattern since they have the same data, just in a different order?
ostephens
on 26 Jul 2017
Calling that an "anti-pattern" might be a bit strong: OpenRefine users rarely get to choose the dirty formats they have to deal with, I think. So all dirty formats are legitimate: some of them are just not covered by OpenRefine's cleaning capabilities.
@thadguidry it would be wonderful if you had some time to improve the docs on this subject! After all, we cannot blame @belm104 for reporting a non-bug, since the function does not seem to be documented anywhere…
wetneb
on 26 Jul 2017
I'm happy to improve the docs in this area
ostephens
on 26 Jul 2017
I've split the documentation question into a separate issue - I'm happy to take that one
ostephens
on 26 Jul 2017
@wetneb @ostephens Well, you make me doubt, and you are right : The behavior of this function was exactly the same in Google Refine 2.5.
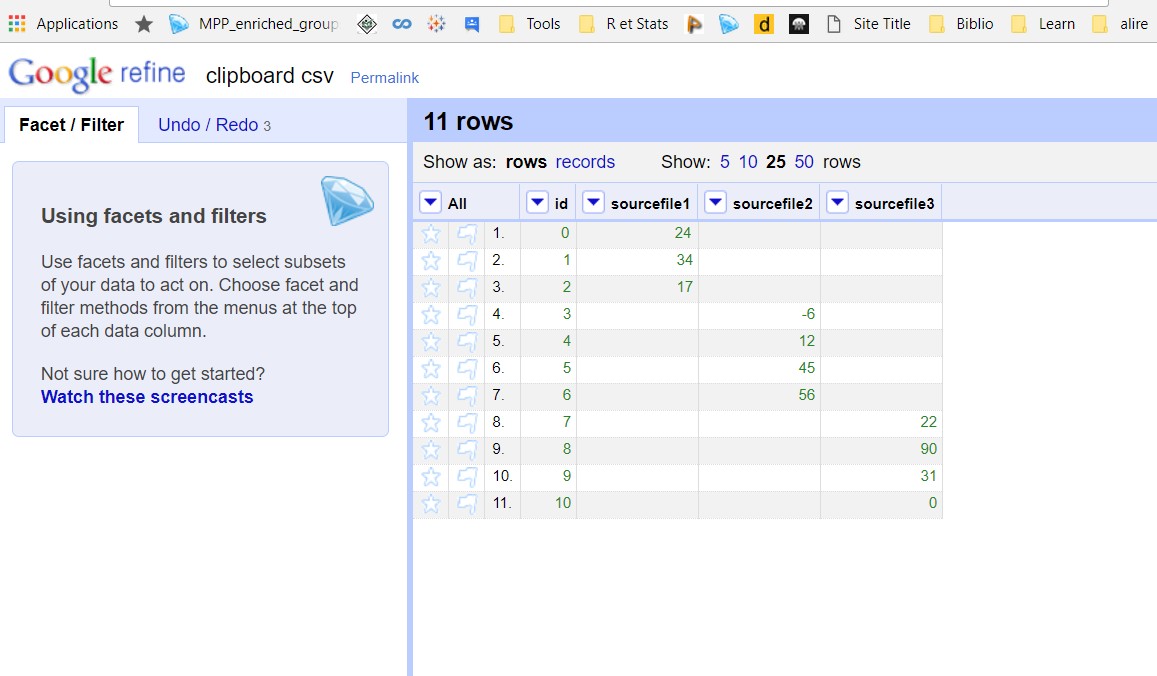
I maintain the word "bug", but let's say that the bug seems to go back to the origins of the functionality. Now that I think about it, I have never seen it work as I wanted. That is, as the "gather" and "spread" functions of the R's tidyr package. And maybe that's why I never used it. :/
File used 👍
Column 1,Column 2
sourcefile1,24
sourcefile1,34
sourcefile1,17
sourcefile2,-6
sourcefile2,12
sourcefile2,45
sourcefile2,56
sourcefile3,22
sourcefile3,90
sourcefile3,31
sourcefile3,0
 ettorerizza
on 26 Jul 2017
ettorerizza
on 26 Jul 2017
ALL - Often we have this idea of transposing our messy data from denormalized fashion to another more normalized form where that form is of the concept of Record Rows or "relatedness". When I say antipattern, I am talking not about the dataset we have in Column1 and Column2...but the dataset we WANT from it like a row -1;6;1
@belm104 has some expectation of what their Row or Record Row needs to be for some reason, and I am trying to understand that need, but do not see it clearly. Let me explain further...
Taking @belm104 's original use case data of those 2 columns:
Column1;Column2
SourceFile1;2
SourceFile1;3
SourceFile1;-1
SourceFile2;3
SourceFile2;4
SourceFile2;6
SourceFile3;-3
SourceFile3;4
SourceFile3;1
In other words, I have yet to hear WHY they need a row in the form of
2;3;-3
or
-1;6;1
HOW are 2 and 3 and -3 ... related ?
HOW are -1 and 6 and 1 ... related ?
HOW do I tell a machine like OpenRefine that they are related ? Do I use a Key ? Which Key ? Do I use Ordinal numbering ? If so, then which columns and how should we sort that prior to transpose ?
thadguidry
on 26 Jul 2017
@thadguidry Well she just wants to have her rows in the expected form she gave us, because she knows it is the shape that makes sense for her dataset… That is a legitimate need! This function just cannot do that at the moment. And 2, 3 and -3 are indeed related because of their relative position to the first row with the same key. It's legitimate to expect something like OpenRefine to pick that up…
I was saying that "anti-pattern" sounds a bit too strong to me because in the ears of a coder it almost sounds like an insult but I am sure you did not mean that!! :-)
wetneb
on 26 Jul 2017
@wetneb Look again.
Column1;Column2
SourceFile1;2
SourceFile1;3
SourceFile2;3
SourceFile3;-3
2 and 3 are "related"... -3 is not
thadguidry
on 26 Jul 2017
@thadguidry I think we all understand what is going on here now, my comment was just about language, really! :-) Just want to make sure our users feel welcome here and keep filing such good bug reports.
wetneb
on 26 Jul 2017
@wetneb we welcome users always. But me saying antipattern does not reflect any negativity.
If you take the original 2 column dataset provided at the top of the issue...
and in OpenRefine edit the Column2 cell of "-1" and change to "1"
and then edit the Column2 cell of "1" and change to "-1"
Then you can see how the function works.
But I am still wondering if any of you have an expectation of flattening somehow when Column 1 is sorted as @ostephens example forms ? That's what I am trying to discover here. We might be able to solve that also with another option
thadguidry
on 26 Jul 2017
I was tired and busy last night, so I did not properly examine the problem. Probably also the day I said it was a bug. Thad is obviously right: the behavior of the function "columnize by key-value" makes perfect sense. This will be clearer with a chart:
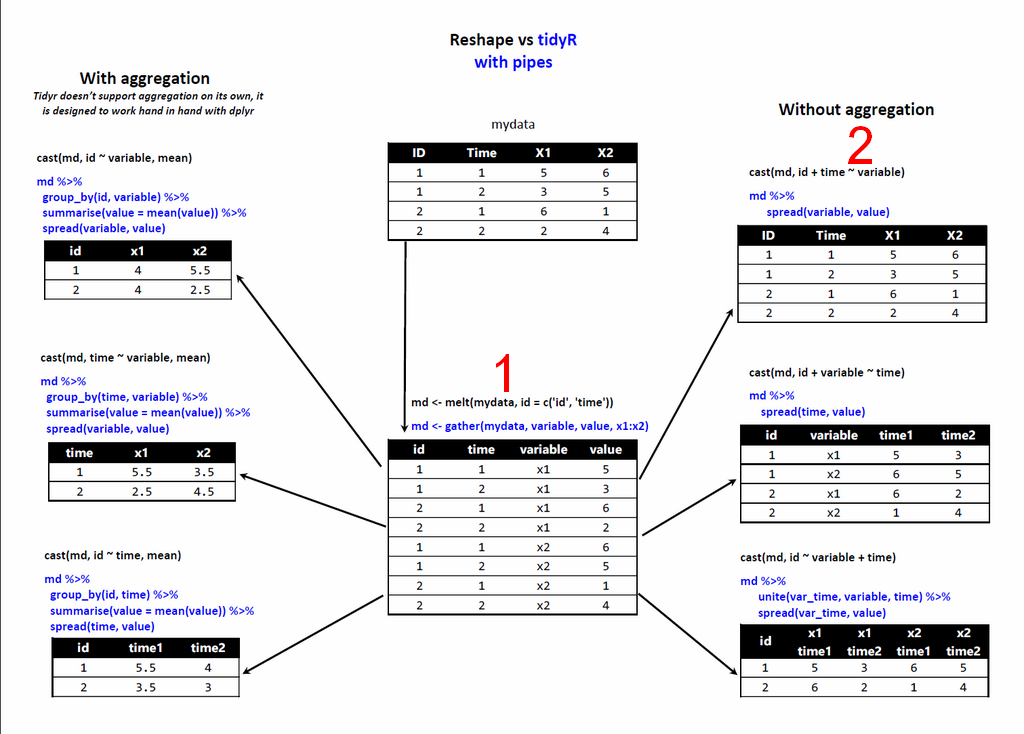
@belm104 has a table like the 1. "Columnize by key-value" will change it to 2. This matches the castfunction of R base, or the spread function in the package tidyr. But the table 2 can not be in a logical way what belm104 want. Here is what the cast function produces if applied to the table we are talking about:
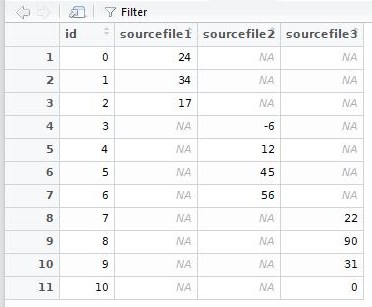
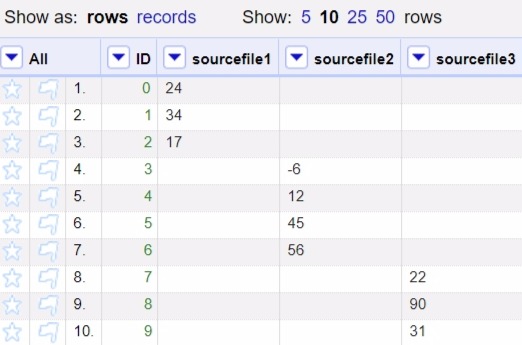
As you can see, it is exactly the same as a "columnize by key-value".
ettorerizza
on 27 Jul 2017
Still trying to get my head around this. Some of the discussion above makes sense to me. @thadguidry's point about not being able to do the transpose if there is no relationship between the values and the keys. However, I'm still not clear on the Sorting issue.
At the risk of introducing more confusion, I've done a further example to try to make the issue I'm grappling with clear:

If I use "Transpose->Columnize by key/value columns" with (obv.) KEY COL as the key column and VALUE COL as the value Column I get the expected result:
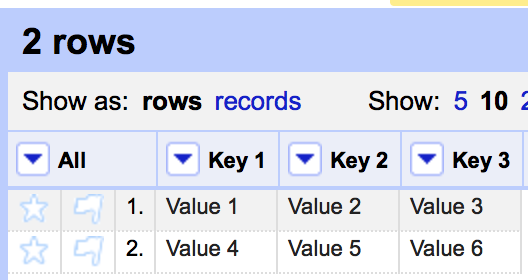
However, if before I transpose I do a sort on the KEY COL and reorder permanently to get this as my starting point:
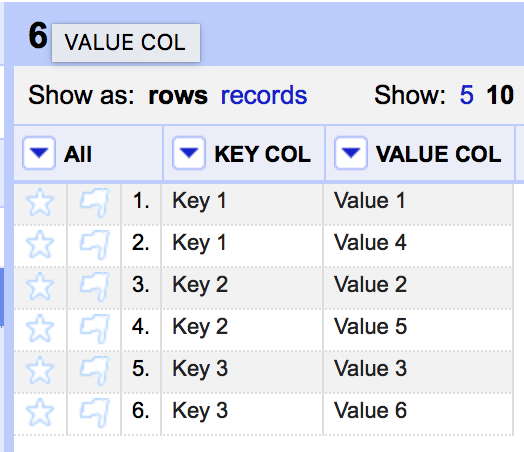
Then I use "Transpose->Columnize by key/value columns" with (obv.) KEY COL as the key column and VALUE COL as the value Column I get the result:
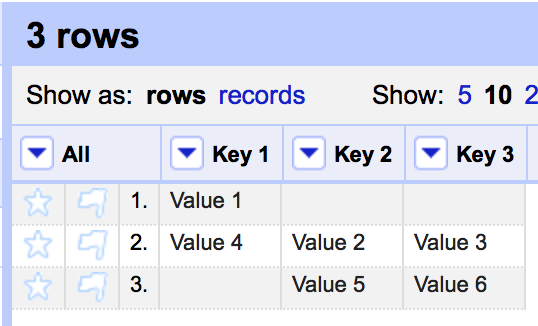
This is not the result I was expecting, and seems to have been caused purely by the order of the data in KEY COL.
I feel like I'm missing something here - apologies for extending this conversation - I just can't quite get my head around why this sort order changes the outcome in this case.
ostephens
on 28 Jul 2017
@ostephens Yes, as explained above, this function requires indeed its input to be listed in a particular order.
The code assumes that the first key it encounters (here, Key 1) is the primary key in the resulting table (in other words, the first column). Then, for every other (key,value) pair (the ones with Key 2 and Key 3), OpenRefine assigns the key-value pair to the last primary key it has encountered.
So, let us do manually what the algorithm does.
Read the initial table sequentially:
- Read
(Key 1, Value 1). As this is the first row we are reading, we deduce thatKey 1is going to be the primary key in our new table. We create a row containingValue 1in the newly-createdKey 1column. - Read
(Key 1, Value 4). This is a new value for the primary key. We deduce that the record for the primary key previously seen (Value 1) is complete, so we leave the first row as it is (with only a value forKey 1) and create a new row containingValue 4in theKey 1column. - Read
(Key 2, Value 2). We create a new column forKey 2and insertValue 2at the position of the primary key that we have seen last (Value 4). - We keep doing that for the other values: they are all assigned to the last primary key seen,
Value 4.
To understand why such an algorithm is desirable, you can run it on my merchant-fruit-price example above.
So, yes, it is normal that changing the order of the rows beforehand breaks the result.
wetneb
on 28 Jul 2017
@wetneb thank you!
ostephens
on 28 Jul 2017
But when we have an explicit Primary key (unique or composed), the function works exactly as expected and order doesn't matter.
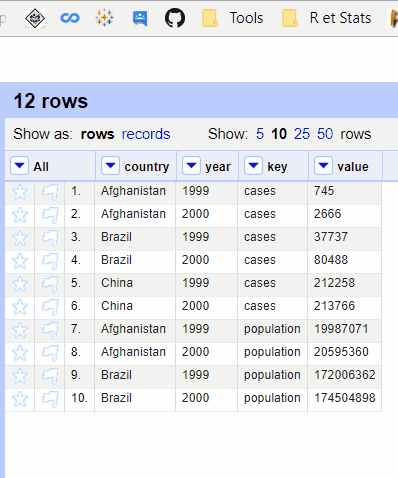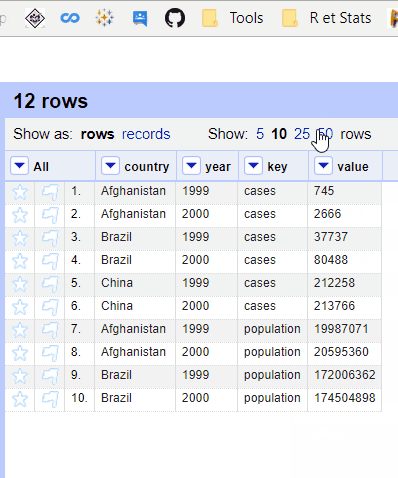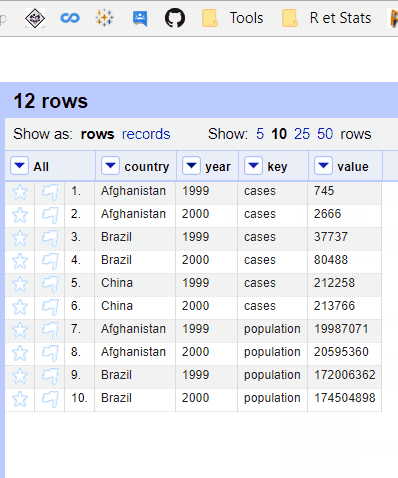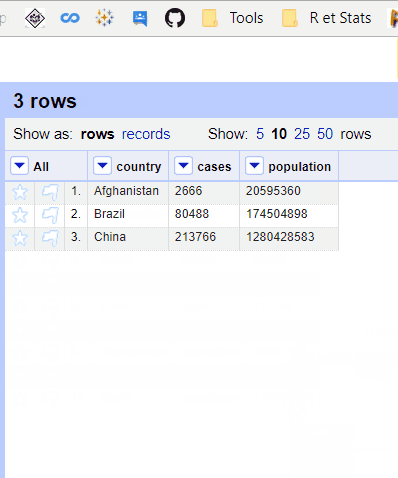
Dataset :
country,year,key,value
Afghanistan,1999,cases,745
Afghanistan,2000,cases,2666
Brazil,1999,cases,37737
Brazil,2000,cases,80488
China,1999,cases,212258
China,2000,cases,213766
Afghanistan,1999,population,19987071
Afghanistan,2000,population,20595360
Brazil,1999,population,172006362
Brazil,2000,population,174504898
China,1999,population,1272915272
China,2000,population,1280428583
ettorerizza
on 28 Jul 2017
@ettorerizza oh, that's good to know, thanks!
wetneb
on 28 Jul 2017
We walk subsequent Rows in the KEY column. So...the order of the KEY column will have an affect. Is that what all the confusion was about with the 4 of you ? I thought that was clear from our code ? Doesn't anyone read our code ? :)
On the serious side, we could probably add more comments in the function, but its already pretty clear just reading all the comments that we have now in KeyValueColumnizeOperation.java doesn't everyone think ?
Also I just noticed this :)
https://github.com/OpenRefine/OpenRefine/blob/master/main/src/com/google/refine/operations/cell/KeyValueColumnizeOperation.java#L219
and what do we do when there's no KEY for a row ? We just copy the row https://github.com/OpenRefine/OpenRefine/blob/master/main/src/com/google/refine/operations/cell/KeyValueColumnizeOperation.java#L154
thadguidry
on 28 Jul 2017
To do : better document this feature.
ettorerizza
on 27 Jul 2019
@ettorerizza think this should go in #1215 - which I totally failed to do when we last discussed this :(
ostephens
on 27 Jul 2019
@ostephens Problem is : who is totally sure how it works? :/
ettorerizza
on 27 Jul 2019
Because this issue was mentioned on twitter, here is a link to the candidate documentation for this feature:
https://docs.openrefine.org/operations/key_value_columnize.html
wetneb
on 9 Jun 2020
The mailing list discussion is here: https://groups.google.com/d/msg/openrefine/XWKVCnZ7__8/Its5228eAQAJ
The current behavior is as intended and the documentation looks good. The typical format that this is designed to work with is something like RIS https://en.wikipedia.org/wiki/RIS_(file_format). Here are two records where each begins with the TY field:
TY - JOUR
AU - Shannon, Claude E.
PY - 1948/07//
TI - A Mathematical Theory of Communication
T2 - Bell System Technical Journal
SP - 379
EP - 423
VL - 27
ER -
TY - JOUR
T1 - On computable numbers, with an application to the Entscheidungsproblem
A1 - Turing, Alan Mathison
JO - Proc. of London Mathematical Society
VL - 47
IS - 1
SP - 230
EP - 265
Y1 - 1937
ER -
There might be an implicit feature request for something along the lines of the Unix paste command or various reshape operations, but since the original poster didn't chime back in with clarification as to whether this was groups of 3 rows or some other shape, it's hard to tell.
I'm going to close this since the documentation is clear now (thanks @wetneb !) and it's unknown what the enhancement request might be.
Please feel free to create a new issue with an enhancement request for additional transposition / reshape operators.
 tfmorris
on 10 Jun 2020
tfmorris
on 10 Jun 2020
Related issues
thadguidry
·
4Comments
 katrinleinweber
·
3Comments
katrinleinweber
·
3Comments
 stellasia
·
4Comments
thadguidry
·
3Comments
stellasia
·
4Comments
thadguidry
·
3Comments
 asyrul21
·
3Comments
asyrul21
·
3Comments
Most helpful comment
But when we have an explicit Primary key (unique or composed), the function works exactly as expected and order doesn't matter.
Dataset :
country,year,key,value
Afghanistan,1999,cases,745
Afghanistan,2000,cases,2666
Brazil,1999,cases,37737
Brazil,2000,cases,80488
China,1999,cases,212258
China,2000,cases,213766
Afghanistan,1999,population,19987071
Afghanistan,2000,population,20595360
Brazil,1999,population,172006362
Brazil,2000,population,174504898
China,1999,population,1272915272
China,2000,population,1280428583