Notepad-plus-plus: A web link is not processed if it contains Cyrillic
A web link is not processed if it contains Cyrillic.
Notepad++ v7.8.6 (32-bit)
Build time : Apr 21 2020 - 15:17:06
Path : I:\Tools_Servis\TextCode\NPP++\npp.7.8.6.bin\notepad++.exe
Admin mode : ON
Local Conf mode : ON
OS Name : Windows 7 Home Premium (64-bit)
OS Build : 7601.0
Plugins : ComparePlugin.dll DSpellCheck.dll Explorer.dll HexEditor.dll HTMLTag_unicode.dll ImgTag.dll JSMinNPP.dll LocationNavigate.dll mimeTools.dll MultiClipboard.dll NativeLang.dll NppConverter.dll NppExport.dll NppMarkdownPanel.dll NppSnippets.dll PreviewHTML.dll ShtirlitzNppPlugin.dll Tidy2.dll VisualStudioLineCopy.dll WebEdit.dll WindowManager.dll XMLTools.dll _CustomizeToolbar.dll

 andrecool-68
andrecool-68
All 101 comments
URL processing has been undergoing change in recent versions of N++.
Can you retest in 7.8.9 and see if it is the same as you described above in that version?
 sasumner
on 29 Jul 2020
sasumner
on 29 Jul 2020
@sasumner
The latest version has exactly the same behavior

I give an example of how to handle web links AkelPad editor

andrecool-68
on 29 Jul 2020
NPP uses the following RegEx which needs to be changed:
URL_REG_EXPR "[A-Za-z]+://[A-Za-z0-9_\\-\\+~.:?&@=/%#,;\\{\\}\\(\\)\\[\\]\\|\\*\\!\\\\]+"
BTW, a . at the end is interpreted as part of the URL which, obviously, is wrong.
This is a task for @guy038 the RegEx master. :)
 Yaron10
on 29 Jul 2020
Yaron10
on 29 Jul 2020
So, not any kind of new problem relating to the change to URL displaying, but rather a long-standing thing...that there are probably other issues already open for.
sasumner
on 29 Jul 2020
@sasumner I noticed this error only today
andrecool-68
on 29 Jul 2020
So, not any kind of new problem relating to the change to URL displaying, but rather a long-standing thing
Not related to the new hotSpot.
that there are probably other issues already open for.
Possibly. :)
Yaron10
on 29 Jul 2020
I would vote for making the URL regex changeable via settings dialog.
No matter what regex change one would come up with now, sooner or later someone will come along who wants it different.
Having it changeable will solve it forever. Maybe with a warning in the settings, like if you do stupid things expect it to work stupidly to avoid getting issues like: once I change the url regex to .* npp is slow.
 Ekopalypse
on 29 Jul 2020
Ekopalypse
on 29 Jul 2020
No matter what regex change one would come up with now, sooner or later someone will come along who wants it different.
I don't know enough about the issue.
If that is the case (and I assume it is if you say so), your suggestion is very good.
I do know that Visual Studio, Gmail and other editors interpret URLs correctly even if they contain non-Latin characters and/or certain characters (e.g. .) at the end.
Yaron10
on 29 Jul 2020
Replacing
#define URL_REG_EXPR "[A-Za-z]+://[A-Za-z0-9_\\-\\+~.:?&@=/%#,;\\{\\}\\(\\)\\[\\]\\|\\*\\!\\\\]+"
with
#define URL_REG_EXPR "(http|ftp|https)://([\\w-]+(?:(?:\\.[\\w-]+)+))([\\w.,@?^=%&:/~+#-]*[\\w@?^=%&/~+#-])?"
solves the following cases:
https://github.com/notepad-plus-plus/notepad-plus-plus.
(https://github.com/notepad-plus-plus/notepad-plus-plus)
https://www.rnids.rs/национални-домени/регистрација-националних-домена
https://www.morfix.co.il/שלום
Feel free to test, improve and submit a PR.
RegEx source: https://stackoverflow.com/questions/6038061/regular-expression-to-find-urls-within-a-string
Yaron10
on 30 Jul 2020
@Yaron10 - this would restrict urls to start with http, ftp and https only, but IANA define a lot more. And maybe in two weeks, month, ... even more?
Ekopalypse
on 30 Jul 2020
@Ekopalypse,
As I wrote: I don't know enough about the issue.
Feel free to improve. :)
Yaron10
on 30 Jul 2020
but IANA define a lot more
Which may be why we currently have:
#define URL_REG_EXPR "[A-Za-z]+://...
Of course in the IANA link I also see some numbers, -, and probably some other non (?i)a-z
sasumner
on 30 Jul 2020
@Yaron10 :-) and we've come full circle - I vote for ... :-)
Ekopalypse
on 30 Jul 2020
@Ekopalypse,
Well, I vote for it too. :)
Still, I suppose the current RegEx can be modified to solve the . and ) issues.
Yaron10
on 30 Jul 2020
Only a opinion thrown in here, because I observe URL problems for a while know. There are two parts of the problem, completely independent of each other:
- Detection of URLs,
- Displaying and highlighting detected URLs.
Until now, I did only get involved in the second part of the problem. I did never care about the detection.
But, whenever I read about problems with that, the question occurs to me: Is a Regex expression really the right way to detect URLs? From inside C++ program code? Since you didn't manage to solve this for years, I would say: no. Is it so difficult to write a simple parser for it? I wonder, why no one ever seemed to have the idea to do this. And before you make this Regex configurable, you should consider, that there may be other solutions than a Regex expression for it. See #3353, #5029 and #7791 also. _Edit:_ and #3912.
 Uhf7
on 1 Aug 2020
Uhf7
on 1 Aug 2020
@Yaron10
I tried your new regex expression, but there must be more to it. If I simply replace URL_REG_EXPR, no link is detected anymore. So I assume, you have modified a setting like "enable super special regex expressions", or you use an own regex library, or a plug-in or something? Can you check this?
Uhf7
on 1 Aug 2020
@Uhf7,
You're using your modified SciLexer.dll with which links are not detected.
Using the original SciLexer.dll, links are interpreted as expected.
See https://github.com/notepad-plus-plus/notepad-plus-plus/issues/8588#issuecomment-666702474.
This may explain the significant size difference between the original DLL and yours.
Can you build your modified SciLexer.dll with the same settings as the original (and upload it)?
Alternatively, in "enable super special regex expressions" do you mean a setting in building SciLexer.dll?
Is it so difficult to write a simple parser for it?
Searching for a better RegEx the other day, I've come across this idea.
We're looking forward to your next PR.
Yaron10
on 1 Aug 2020
@Yaron10,
you are right, with the original SciLexer.dll from 7.8.9 your regex expression works.
With the Appveyor build, it doesn't. Here, only the original regex expression works. So there is an unnecessary difference between the Appveyor build and the original build, which should be fixed someday.
Thank you, now I can run your regular expression against my parser.
_Edit:_ My own build of SciLexer.dll too doesn't accept the "new" regex syntax, there must be a trick.
Uhf7
on 1 Aug 2020
My own build of SciLexer.dll too doesn't accept the "new" regex syntax, there must be a trick.
Please share if you figure it out.
Thank you.
Yaron10
on 1 Aug 2020
Ok, did some reasearch and found this community discussion from 2017 which links to this github issue.
And a new regex (?-s)[A-Za-z][A-Za-z0-9+.-]+://[^\s]+?(?=\s|\z) has been proposed.
But then it was closed with comment: requirement could not be fulfilled.
But from my limited regex knowledge I assume it does fulfill the requirements.
I did a test and it looks like it finds what needs to be found.

Ekopalypse
on 1 Aug 2020
I'm not one to play regex golf, but the regex @Ekopalypse mentions just above seems a bit, well, confuscated. This would seem to cover it, and be simpler (although I did no testing):
(?i-s)[a-z][a-z0-9+.-]+://\S+?(?=\s|\z)
Normally, it doesn't matter, but if changing something this "important", it should be done so that someone in the future doesn't have to puzzle about why it was made "overcomplicated".
Note also that neither of these 2 regex handle the case of a URL wrapped in parentheses/brackets/etc. correctly; examples:
(http://www.google.com)<--- it will include the)in the match; obviously won't include the([http://www.google.com]<--- it will include the]in the match; obviously won't include the[etc., such as
{and}
People (including me!) like to put URLs in parentheses; currently I have to remember to do it this way:
( http://www.google.com ) <--- note space before h and after m
Perhaps ) and friends are valid in a URL, and thus nothing can be done about this situation.
Another point: Is there no Unicode possibility _before_ the :// in URLs?
sasumner
on 1 Aug 2020
The ) and . at the end are important to me too.
Yaron10
on 1 Aug 2020
The ) and . at the end are important to me too.
That means you would NOT want them included in the URL, correct?
sasumner
on 1 Aug 2020
That means you would NOT want them included in the URL, correct?
Correct.
Perhaps ) and friends are valid in a URL, and thus nothing can be done about this situation.
I hope that is NOT correct. :)
Yaron10
on 1 Aug 2020
@sasumner
Is there no Unicode possibility before the :// in URLs?
No, according to https://tools.ietf.org/html/rfc3986#section-3.1, to quote
3.1. Scheme
...
scheme = ALPHA *( ALPHA / DIGIT / "+" / "-" / "." )
...
and according to https://tools.ietf.org/html/rfc2234#section-6.1
...
ALPHA = %x41-5A / %x61-7A ; A-Z / a-z
...
DIGIT = %x30-39
; 0-9
...
Ekopalypse
on 1 Aug 2020
@Yaron10, I can now build a SciLexer.dll which accepts your regular expression. And, absolute surprise, it doesn't use the Scintilla-build-in regex functions, but the regex functions from the boost library. This seems to be, because you regex acrobats can never be satisfied with standard regular expressions.
The mechanism is, that Scintilla provides a class for regex operations, which can be left as it is or be overridden with own regex functions. The code to do this is contained in \scintilla\boostregex\BoostRegExSearch.cxx.
To add the boost regex stuff to the project, you have to have the boost library installed on your computer. I downloaded a precompiled version from https://sourceforge.net/projects/boost/. Then, you have to add the source files from the scintilla\boostregex\ directory to your project, drag and drop worked for me. Then follow the error messages of the compiler, until it can build everything. You need:
- to add an additional include file directory, where the
boost\regex.hppcan be found. - to add an additional library file directory, where the .lib file can be found, which fits to your compiler and to your architecture/debug/release settings. The name of the library needed can be read from the compiler error log.
After you can build it, you have to turn it on by defining the preprocessor symbol SCI_OWNREGEX, and that's it. If you hate _deprecation_ warnings, you can define _SILENCE_ALL_CXX17_DEPRECATION_WARNINGS.
By the way, I'm happy that the standard regular expression used for URL's here comes out with the regex syntax naturally provided by the original SciLexer.dll.
Uhf7
on 1 Aug 2020
@Uhf7,
Thank you for the detailed guide.
Too much work for an amateur like myself. I'll wait for the next NPP release which should include the DLL with boost.
Yaron10
on 1 Aug 2020
@Yaron10 look at this ones (They don't get through your regular expression):
- Seen in #5029: . . . URL (e.g., https://en.wikipedia.org/wiki/Saw_(2003_film))?
- Seen in #3912: . . . https://duckduckgo.com/?q=windows+delete+"GameBarPresenceWriter.exe"
Uhf7
on 1 Aug 2020
Yes, we're looking forward to your parser. :)
BTW, the second link is not interpreted correctly here (in your post) either.
Yaron10
on 1 Aug 2020
I did a test to see if there is a performance impact and it seems that this
[[:alpha:]][[:alnum:]+.-]+://\S+
is ~3% faster than the one currently used and has the advantage to find unicode letters as well.
Finding and marking 10.000 urls took, with pythonscript on my machine, 0.45 seconds.
I assume pure C++ can do this much faster and 10.000 urls in a document should be unusual.
Ekopalypse
on 1 Aug 2020
Here are the first results of my new URL parser.
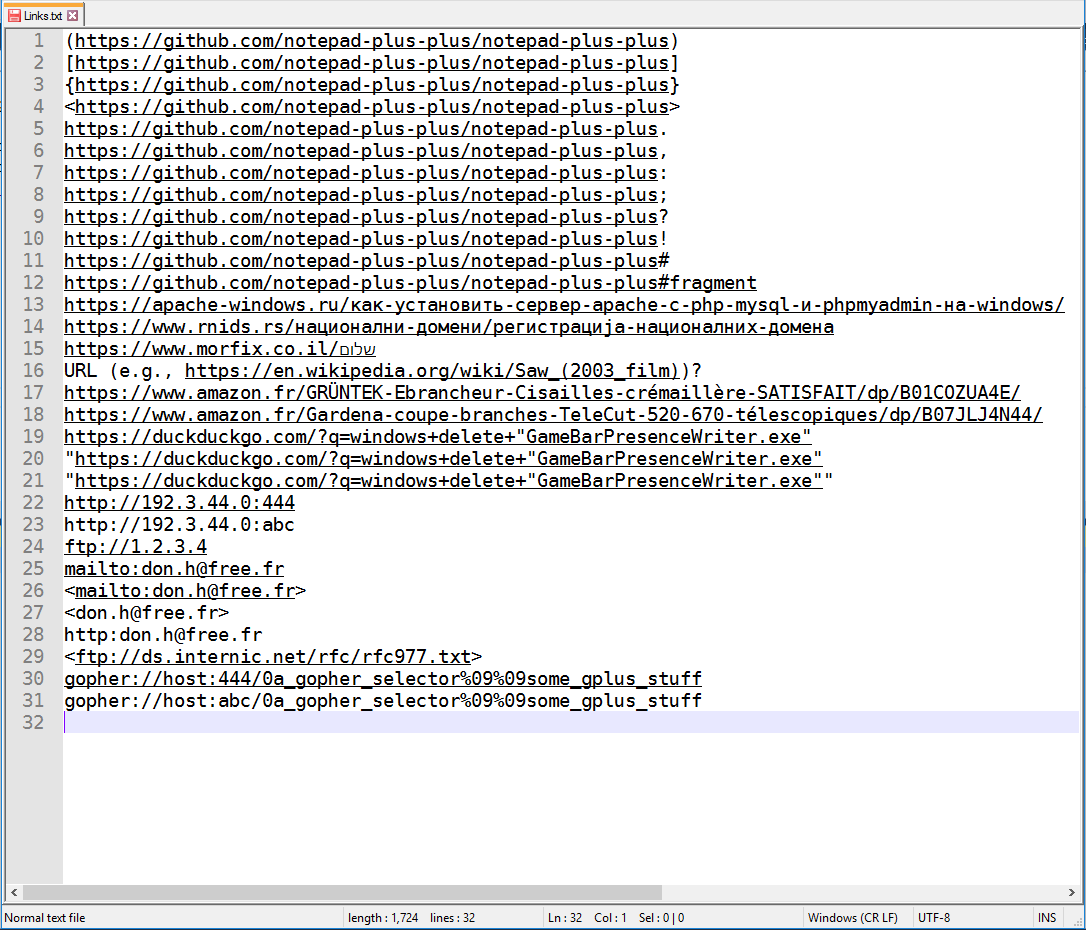
It works without regular expressions. I use the Windows function InternetCrackUrl for the link detection, so I don't need to think about how an URL looks like. And I have some code to clean up the endings, because InternetCrackUrl selects too much also.
I'm in the phase of optimizing it, so if you have a bad example, then please post it here.
Uhf7
on 2 Aug 2020
Nice. My favorite is the one shown on line 16! :-)
sasumner
on 2 Aug 2020
@Uhf7,
It looks great.
My favorite is line 21. :)
Can you test the following two lines?
view-source:chrome://browser/skin/browser.css
github.com
Thank you.
Yaron10
on 2 Aug 2020
@Yaron10,
both lines are not detected as URL. The second one would never be. The first one is interesting.
We are speaking about custom URL schemes here, which can be installed. Every software seems to do it, mostly unknown to the user. I have far more than 200 URL schemes registered on my system.
The first problem is, that I don't want to trigger the most of them inadvertently. bingmaps:, bingnews:, callto:, daap:, iTunes.AssocProtocol.daap:, I don't know, what the most of them actually do. On the other hand, some of them may be useful for some users, things like acrobat:, FirefoxURL:, git:, chrome: (which I cannot find on my system) and others.
The second problem is, that every scheme has it's own syntax, they expect different parameters after the :. The InternetCrackUrl function parses the standard URLs good enough to make a qualified decision, but the custom schemes cannot be parsed. The regex expression currently used accepts any name as an URL scheme (except those, which contain minus or dot signs, from which are many installed on my system). And then it assumes, that every scheme has the same syntax as the http scheme. This is actually not correct, not even for ftp:.
What can be done? My favorite proposal would be, only to accept the following standard schemes: http:, https, ftp: and mailto:. I would initially exclude all other standard schemes like file: and socks: and vbscript:. Then we get a fast parser and URL links from which everyone knows what they do.
If this should not be enough, we need a configuration list in Notepad++, which says, which custom schemes should be marked as URL. This schemes would then not be parsed, which means, that everything from the : to the next white space belongs to that custom URL link.
What I wouldn't do, is to check the Registry for custom scheme names or start to build some Ole mechanisms to try to parse custom schemes. Reasons: too complicated, too slow, and too dangerous: There are so many schemes silently waiting to be triggered.
Uhf7
on 3 Aug 2020
What can be done? My favorite proposal would be, only to accept the following standard schemes: http:, https, ftp: and mailto:. I would initially exclude all other standard schemes like file: and socks: and vbscript:. Then we get a fast parser and URL links from which everyone knows what they do.
For my personal use this is perfectly fine.
@Ekopalypse, what do you think?
The second one would never be.
And www.github.com?
Thank you.
Yaron10
on 3 Aug 2020
And www.github.com?
This is highlighted here for the www. Perhaps most e-mail software does it too, but the MS VC++ environment does it not.
And, it is not detected as an URL by InternetCrackUrl. Of course, because it is none.
If you want to produce a clickable URL, you need the URL scheme name before it. For Windows, this URL scheme name specifies actually the software to use. The Internet Explorer (or Firefox or Chrome or whatever) has registered itself to the http: und https: and ftp: schemes. The Outlook mail software (on my system, only as example) has registered itself to to the mailto: scheme, and so on. What Notepad++ does, after the link is clicked, is to tell the Windows Shell to execute the URL, and the Windows Shell looks for the software that is registered for the URL scheme and executes this.
I think, the function is not designed to emphasize any web address simply mentioned in a text, but to make it easier to follow dedicated references, which should state the complete URL address then.
Uhf7
on 3 Aug 2020
:+1:
Thanks again.
Yaron10
on 3 Aug 2020
@Yaron10
Personally I do not have any preferences but I agree with @Uhf7 that the standard schemes should be supported only.
What I wouldn't do, is to check the Registry for custom scheme names or start to build some Ole mechanisms
@Uhf7 - There would be another hurdle you would have to overcome. @donho has mentioned from time to time that he does not like COM code at all. :-)
I think the "future" situation shown in the screenshot by Uhf7 is what the majority of the users is asking for.
Unicode and encasing support, hence this seems to be the perfect solution.
If I should do some tests, with a new npp.exe build, let me know.
Ekopalypse
on 3 Aug 2020
@Ekopalypse,
and anyone else who want to test it, I post my new version of Notepad_plus.cpp here. It contains the two versions of the addHotSpot function, switched with a preprocessor-#if. #if 1 activates the new parser version, #if 0 the classic regex version.
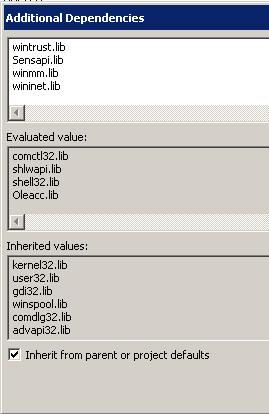
To build it, you have to add wininet.lib to the Linker -> Input -> Additional Dependencies settings.
The code still contains the debug messages for performance measuring. So, the testing goals would be:
- Find a situation, in which the parser version hangs or produces results which are not tolerable,
- Find a situation, in which the parser version is slower than the regex version.
Thank you in advance for helping here, it is best to find negative effects early.
Uhf7
on 4 Aug 2020
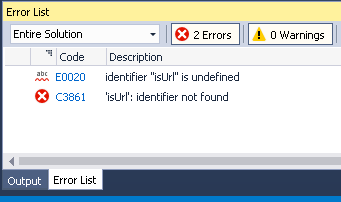
@Uhf7,
I've added wininet.lib but isUrl() is still "undefined".
Yaron10
on 4 Aug 2020
OK. Testing.
Yaron10
on 4 Aug 2020
It contains the two versions of the addHotSpot function
I thought you only modified addHotSpot().
After a quick test:
Links seem to be interpreted as expected.
Do you have ~100 bookmarks in Firefox?
Export them tobookmarks.htmland open it in NPP.
There's a noticeable delay compared to the RegEx.https://en.wikipedia.org/wiki/Saw_(2003_film)
Delete the(2003_film)part and type it manually.
There's a noticeable delay compared to the RegEx.
Yaron10
on 4 Aug 2020
@Yaron10 Thank you for testing.
In my environment, I cannot produce a case where the parser version is slower than the regex version. So please let's investigate this. For performance testing, I used the attached StartPage2500.txt file. It contains 50 lines with 100 URLs each. To stress the addHotSpot() function most, all 50 lines must be visible at once. So I decreased the font size until all 50 lines where visible. Word wrap has to be off for this test. Then I go to the start of the file and type single spaces before the first link. After each space, addHotSpot() is called for link detection. In the debug output window of Visual Studio, the times taken by addHotSpot() are printed out.
On my system, the time needed by the parser is about 0.05 s, the regex version takes about 0.2 s. Can you check this times on your system? If the parser takes significantly more time than regex, please check, if you use the original signed Notepad++ version of the SciLexer.dll and whether you have modified any compiler optimization settings.
Uhf7
on 4 Aug 2020
My first test, switch between buffers using the StartPage and two of my previously used documents, shows that the new solution
is, at least, about 33% faster than the regex based solution
#if 0 #if 1
0.313040 0.217684 <- StartPage2500.txt
0.277459 0.183328 <- StartPage2500.txt
0.003358 0.002211 <- test_new_regex_1.txt
0.002967 0.001006 <- test_new_regex_1.txt
0.002984 0.001292 <- test_new_regex_2.txt
0.003955 0.000973 <- test_new_regex_2.txt
Will do the required tests later today.
Ekopalypse
on 4 Aug 2020
STR 1 (major):
Download these files.
Word-Wrap ON.
Font size decreased to the smallest.
_Select all files and drag & drop them into NPP._
-- It takes NPP some 2 or 3 seconds (!) to open them.
_Close All._
-- Significant and clearly noticeable time to close.
_Open Recently Closed File (Ctrl+Shift+T)._
-- Clearly noticeable time to re-open.
_Have all 5 files open and switch between tabs._
-- NPP Tab Bar disappears for a ~1 second (!).
_Scroll up and down the documents._
-- High CPU, slow scroll.
STR 2 (minor):
https://en.wikipedia.org/wiki/Saw_(2003_film)
Delete the (2003_film) part and re-type it manually.
-- It takes some time for the underline to appear.
Can you check this times on your system?
I've never used the Debugger.
if you use the original signed Notepad++ version of the SciLexer.dll
No difference between the original DLL and the new one.
and whether you have modified any compiler optimization settings.
None.
A minor issue with the new SCI_SETINDICATORCURRENT (not related to RegEx vs. Parser).
Copy a link with the EOL (or multiple links with the EOL of the last one).
Paste it in a new document.
-- No underline until you hover over the link.
Yaron10
on 4 Aug 2020
@Yaron10, Thank you for your test and test files, you satisfied my request to find a situation, in which the parser version is slower than the regex version. Now I have something to optimize.
@Ekopalypse Thank you too, I wonder why the the parser version is slower on your system than on mine, although the regex version takes quite the same time as on my system as on yours (for the StartPage2500.txt file). But I will focus now on the Test1.html provided by @Yaron10, which slows down the parser version significantly (0.6 seconds instead of the 0.05 s of the regex version, and this for the first 50 lines only).
Uhf7
on 4 Aug 2020
@Uhf7,
Thank you for your work. :+1:
Yaron10
on 4 Aug 2020
OK, I optimized it. For the first 50 lines of Test1.html the parser version needs now only 0.005 seconds instead of 0.6 seconds before. I hope, that this speed enhancement I believe to see here jumps over to your system at least partially.
Uhf7
on 4 Aug 2020
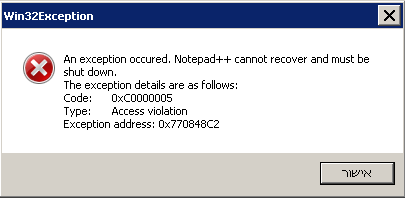
Good news and bad news.
I opened the files, scrolled up and down, switched between tabs, closed and re-opened them.
It seemed to be even better than the RegEx version: faster scrolling and lower CPU.
But then - after ~ a minute of testing - NPP crashed when I tried to switch from one tab to another.
Yaron10
on 4 Aug 2020
@Yaron10, Thank you for testing again.
It's overall good news, because the technique as such seems to work. I forgot some lines in the code, making it crash, I hope I fixed this now. I included some assertions to catch these things earlier in debug mode.
If anyone wants to test my current version, here is the source file again:
Notepad_plus.zip
In the meantime, I will check some other things you mentioned above.
Uhf7
on 4 Aug 2020
@Uhf7,
I won't be by my PC today. I'll try it tomorrow.
Thank you.
Yaron10
on 5 Aug 2020
I did some test and this are the outcomes
The first test used @Yaron10 html testfiles.
I loaded this and switched to each buffer. (10x means i activated each single buffer 10 times)
old: new:
10x
took:3.442019288 took:2.2873665279999997
took:1.6390006000000028 took:1.0401238300000006
took:1.6148316949999995 took:0.9945766760000003
took:1.6141832469999997 took:1.0550754480000002
took:1.5928958120000019 took:1.0486466409999995
1000x
took:339.515453738 took:225.518268965
took:166.90924375499998 took:109.38663718800001
While doing the 1000x test I monitored RAM and CPU usage using sysinternals vmmap tool, maximum was nearly the same.
Second test was to create urls with the whole range of usable unicode characters, which worked but then I discovered
that some characters are not underlined if these are at the end of the url. Like http://www.google.de/? and others.
And that if you copy and paste urls only the last got an underline.
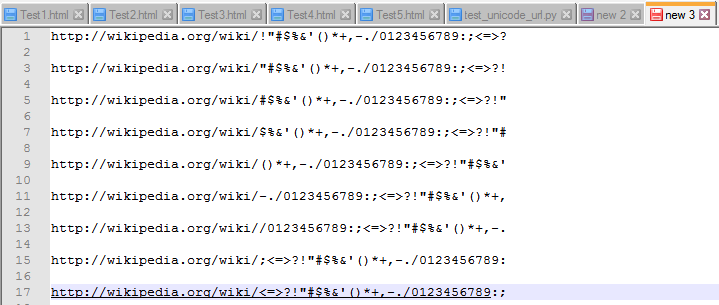
After moving the mouse to the link the others got the underline as well.
About the second test I'm thinking to rotate the generated url and check if the complete url is marked with the indicator but
I'm not sure if this is worth doing it. Maybe they are just not valid urls - but I haven't found any information that urls are not
allowed to end with certain characters.
Ekopalypse
on 5 Aug 2020
@Ekopalypse With your excellent testing on this, I really should finish up my PR for 7735 and turn you loose on that! :-)
sasumner
on 5 Aug 2020
@sasumner - do it!! :-D
Ekopalypse
on 5 Aug 2020
@Ekopalypse , Thank you for the detailed testing, at least the new addHotSpot() seems not to slow down Notepad++ on your system. I can reproduce the copy/paste problem on my system too, but this has nothing to do with addHotSpot() itself, I believe. This can be shown in this way:
- Open the modified (and not maximized) Notepad++ over Visual Studio, so that the debug output window of Visual Studio is visible under Notepad++.
- Paste a bunch of links into the edit window of Notepad++. A message is displayed in the debug window of Visual Studio stating the time consumed by
addHotSpot(). And, only the last URL is underlined in the edit window of Notepad++. - Then move the text cursor in Notepad++. All URLs are underlined now, without
addHotSpot()being called again.
So I conclude, addHotSpot() did the URL detection while the first call, and the different look of the first URLs immediately after the paste is an update problem. I'm already searching for it.
I discovered that some characters are not underlined if these are at the end of the url. Like http://www.google.de/? and others.
This was one of the main goals of this effort, to solve #3353 and #5029. And of course, actually those ending characters are allowed in URLs, but they are filtered away in E-Mail programs and other text editors, and in this portal too.
The rules for the filtering I used here are (see removeUnwantedTrailingCharFromUrl):
- remove unwanted single chars:
.,:;?!# - remove unwanted closing parenthesis, if there is a matching opening counterpart in the URL.
- remove unwanted quotes, if there is a matching quote in the URL.
The goal of this is, to display "sanely" formed URLs correctly, it may not work on URLs constructed completely arbitrary.
Uhf7
on 6 Aug 2020
@Uhf7,
No crashes. :+1:
The scrolling is significantly faster and the CPU is significantly lower on my machine.
Were you able to consistently reproduce the crash with your Notepad_plus v2?
Regarding the Copy/Paste issue:
As I wrote in https://github.com/notepad-plus-plus/notepad-plus-plus/issues/8634#issuecomment-668541115 (last section): it's not related to RegEx vs. Parser but to SCI_SETINDICATORCURRENT.
I remembered today that I had encountered a similar issue with NPP old addHotSpot.
I can't reproduce it now.
Another minor issue (existed in older NPP versions as well):
Hover over a link.
Wheel-scroll down (the hand-cursor is on another link).
-- The first link is still in "hover-state".
If I replaceINDIC_FULLBOX with INDIC_TEXTFORE - would it somehow be possible to display the underline on hover?
if (r)
{
pView->execute(SCI_SETINDICATORCURRENT, URL_INDIC);
pView->execute(SCI_SETINDICATORVALUE, indicFore);
pView->execute(SCI_INDICATORFILLRANGE, startEncoded + startPos, lenEncoded);
}
Just curious: why is it needed to add pView->execute(SCI_SETINDICATORCURRENT, URL_INDIC); here?
Thank you.
Yaron10
on 6 Aug 2020
Another issue with the parser (exists also with the RegEx I suggested; does NOT exist with NPP RegEx).
Insert a Unicode character in the www part.
-- The line is parsed as a link.
Yaron10
on 6 Aug 2020
Were you able to consistently reproduce the crash with your Notepad_plus v2?
I can make a file which crashes v2 according to the error I found. This file containes a line http://xxx, where there are 10000 'x' characters instead of three. The many characters are necessary to "safely" access bad memory, in reality, the crash can occur earlier.
The reason for the crash were the missing code lines at the end of isUrl in v2. So if isUrl returned false, then the length of the last URL found was used instead of of the remaining characters to the end of the buffer. In the example constructed, the remaining characters to the end of the buffer are zero, and the last URL is 10k long, so it crashes v2 quite certainly.
If I replace INDIC_FULLBOX with INDIC_TEXTFORE - would it somehow be possible to display the underline on hover?
Scintilla provides only a limited variety of highlighting indicators. The reason for this, is, as I believe, that the indicators are designed to overlay syntax highlighting. The possible styles are described in ScintillaDoc.html, near SCI_INDICSETSTYLE.
Short story: If you underline the indicator, you can change the color of the underline, but not the color of the text. That's why URLs are underlined only if not hovered right now. Perhaps we can extend Scintilla someday to overcome it.
Just curious: why is it needed to add pView->execute(SCI_SETINDICATORCURRENT, URL_INDIC); here?
Because SCI_INDICATORFILLRANGE uses it as input parameter. SCI_INDICATORFILLRANGE fills the current indicator (set by SCI_SETINDICATORCURRENT, with the indicator value, set by SCI_SETINDICATORVALUE.
Insert a Unicode character in the www part. -- The line is parsed as a link.
Seems to be OK to me, there is no rule that the host name in the URL must begin with _www_.
The other points (wheel scroll and copy/paste) I still investigating.
Uhf7
on 6 Aug 2020
Thank you for the detailed explanation.
I can make a file which crashes v2 according to the error I found.
...
Scintilla provides only a limited variety of highlighting indicators.
...
The other points (wheel scroll and copy/paste) I still investigating.
:+1:
Because SCI_INDICATORFILLRANGE uses it as input parameter. SCI_INDICATORFILLRANGE fills the current indicator (set by SCI_SETINDICATORCURRENT, with the indicator value, set by SCI_SETINDICATORVALUE.
My question was why it was needed again?
I built it without that line in the loop and didn't notice any difference.
Seems to be OK to me, there is no rule that the host name in the URL must begin with www.
Yes, it's interpreted as a link here on GitHub too.
But double-clicking such a line in NPP does not open it in your default browser.
Minor, let's leave it as it is.
Yaron10
on 6 Aug 2020
@Yaron10,
Thank you, you are right. Now I see it. It's no need to call SCI_SETINDICATORCURRENT within the loop, because it is already called before the loop. Similar the SCI_SETINDICATORVALUE call. I will move this one to before the loop too.
Uhf7
on 6 Aug 2020
:+1:
Thank you for your time and work.
Yaron10
on 6 Aug 2020
@Uhf7 - thx for clarification. I see, it never occurred to me as I haven't to copy multiple lines of urls before :-)
@Yaron10 - as you've stated that there is no underline and mine had the last line underlined I mentioned it, but it seems both are originated from the same source.
Concerning the SETINDICATORCURRENT call - be aware that especially this function is also used by different plugins.
If you use it outside of the loop it might happen that it get reset while calling SCI_INDICATORFILLRANGE.
As for removing characters - are we sure that we are not corrupting any valid urls?
I have no experience, e.g. is http://www.whaterver.com/?abc# the same as http://www.whaterver.com/?abc or does the latter produce a warning/error page? If it is the same, can someone force the first version to be used over the second?
I understand the desire, for example, to remove the punctuation point but would find it strange if my documentation links in the code stopped working because a character was removed at the end.
Just some thoughts.
Ekopalypse
on 6 Aug 2020
as you've stated that there is no underline and mine had the last line underlined I mentioned it, but it seems both are originated from the same source.
:+1:
Concerning the SETINDICATORCURRENT call - be aware that especially this function is also used by different plugins.
If you use it outside of the loop it might happen that it get reset while calling SCI_INDICATORFILLRANGE.
Can another command be executed while addHotSpot is being executed?
If it can, can't it be executed in the loop between SETINDICATORCURRENT and SCI_INDICATORFILLRANGE?
Yaron10
on 6 Aug 2020
Can another command be executed while addHotSpot is being executed?
In a multithreaded application, yes it can. PythonScript is suffering from it.
can't it be executed in the loop between SETINDICATORCURRENT and SCI_INDICATORFILLRANGE?
In the current code, I don't think so. If between those calls another thread would be advised to do something then yes.
Ekopalypse
on 6 Aug 2020
@Ekopalypse,
I don't think we remove too much. Yes, an URL can contain closing parenthesis without opening counterparts, but there is not much advantage in highlighting the closing ')' of such URLs, compared to the negative effect on URLs enclosed in '(' ')'. And: MS Visual Studio removes closing parenthesis from the end, regardless, whether they occur in the URL or not, that seems to be even worse.
Concerning '?' and '#': This would be empty queries and empty fragments, not needed either in a meaningful URL. Those are removed by MS Visual Studio too, if they are alone at the end of an URL. They are not removed, if there is any non-punctuation character after it. It is like this in MS Visual Studio too (the parser does the same):
http://www.whatever.com/?abc - ?abc is kept.
http://www.whatever.com/? - ? is removed.
http://www.whatever.com/#abc - #abc is kept.
http://www.whatever.com/# - # is removed.
http://www.whatever.com/#. - #. is removed.
http://www.whatever.com/f;.# - ;.# is removed.
http://www.whatever.com/f;.#abc - ;.#abc is kept.
The goal is, that most meaningful URLs go through the parser, and that the meaningful URLs don't become useless, because some additional characters are typed behind them. Some very special cases of URLs may get lost here, but the win is greater than the loss, I guess.
Uhf7
on 6 Aug 2020
In the current code, I don't think so. If between those calls another thread would be advised to do something then yes.
Can you clarify it please?
In the current code and within the loop, can another thread interfere and change SETINDICATORCURRENT?
Yaron10
on 7 Aug 2020
First, I have very limited c++ knowledge thus I'm not certain what npp does under the hood.
But if we take, for example, the code you posted earlier
if (r)
{
pView->execute(SCI_SETINDICATORCURRENT, URL_INDIC);
pView->execute(SCI_SETINDICATORVALUE, indicFore);
pView->execute(SCI_INDICATORFILLRANGE, startEncoded + startPos, lenEncoded);
}
if between pView->execute(SCI_SETINDICATORCURRENT, URL_INDIC); and pView->execute(SCI_INDICATORFILLRANGE, startEncoded + startPos, lenEncoded); is a chance that another thread gets executed than it is possible that this thread can reset
the current indicator. When does this happen. For example if scintilla runs in one thread and npp in another. Or if npp executes those calls asynchronously or npp calls code in another thread or ...
I'm the wrong person to answer if this is really the case - I can just tell, that this happens for plugins already.
Ekopalypse
on 7 Aug 2020
@Ekopalypse,
Thank you.
So, we'll have to wait for @Uhf7's opinion and decision.
Yaron10
on 7 Aug 2020
The only thing I can offer is to try to break it. :-D
Ekopalypse
on 7 Aug 2020
The only thing I can offer is to try to break it.
I suppose @Uhf7 will understand your suggestion. :)
Yaron10
on 7 Aug 2020
@Yaron10, @Ekopalypse,
There is no need to worry here. Everything takes place in the main thread of Notepad++. If another thread would call any SCI_xxx functions concurrently, we would have an unmanageable chaos here already.
Plug-ins export a number of functions, which are called by the main thread of Notepad++. And only during the plug-in function is called, it is allowed to call SCI_xxx functions in turn.
The plug-in function, however, could mandate another thread to call the SCI_xxx functions, like a Python interpreter. But the order of events has to be followed strictly:
- Notepad++ calls the plug-in function (from the Notepad++ main thread),
- The plug-in function does it's work, it can use another thread for it or not,
- The plug-in function returns.
After it returned, no plug-in thread is allowed to do anything in Notepad++ anymore.
Uhf7
on 7 Aug 2020
@Uhf7,
Thank you for the explanation. I've learned something new.
@Ekopalypse,
Thank you for bringing it up.
Just found out that Function List requires SciLexer.dll with boost.
If anyone has built the modified DLL with boost and can upload it, I'd appreciate it.
Yaron10
on 7 Aug 2020
Can you paste the following line in a new document and hover?
"http://*/*","https://*/*"]},"optionalPermissions":{"permissions":[],"origins":[]},"icons":{"24":"English.png"},"iconURL":null,"blocklistState":0,"blocklistURL":null,"startupData":null,"hidden":false,"installTelemetryInfo":{"source":"app-profile","method":"sideload"},"recommendationState":null,"rootURI":"jar:file:///C:/---/Firefox%20New%20Profile/extensions/%7B7773111b-4bc8-4a99-b37f-5672f6cf9825%7D.xpi!/","location":"app-profile"},{"id":"{8883111b-4bc8-4a99-b37f-5672f6cf9825}","syncGUID":"{514b6c31-93fa-45df-a692-aab469d88982}","version":"1.0.1","type":"extension","loader":null,"updateURL":null,"optionsURL":null,"optionsType":null,"optionsBrowserStyle":true,"aboutURL":null,"defaultLocale":{"name":"Toggle Document Fonts","description":"עבור ביו גופני אתרים לגופני מערכת.","creator":null,"developers":null,"translators":null,"contributors":null},
I assume, you are talking about the spaces. I think, an URL must not contain spaces. Spaces have to be coded as %20.
I derived this opinion from https://stackoverflow.com/questions/5442658/spaces-in-urls. This is a perfect entry page to be dragged into endless considerations about what is allowed and what not.
If you mean something else, please tell me. The highlighting on my system stops at the first space after Toggle. And the URL contains correctly coded spaces already in the Firefox%20New%20Profile passage. I don't think it's correct to really parse the quoted sequences and to accept characters, which are not allowed in URLs, between quotes.
Uhf7
on 8 Aug 2020
Without any profound knowledge of the rules - it just seems strange that this line is parsed as a link (until the space after Toggle).
If our reference is MS VS, it's interpreted differently there.
Yaron10
on 8 Aug 2020
@Uhf7,
I'll try to simplify and clarify it: looking at that line, it's obviously not meant to be a link.
Yaron10
on 8 Aug 2020
Yes, I agree that it is not meant as a link.
Although InternetCrackUrl accepts '*' as a host name and any character except whitespace as URL path.
Outlook accepts this kind of character sequence as link too, but only, if it fits in a single line, so I had to cut it after "source". MS VC doesn't accept it, because it doesn't allow double quotes in URLs at all. But the double quotes are contained in the examples in #3912. And my browser accepts them too. So I wouldn't exclude them entirely.
So I will think about a consistent way to exclude most of your interesting example line from URL detection. Thank you for the hint.
Uhf7
on 8 Aug 2020
:+1:
Thanks again for your work.
Yaron10
on 8 Aug 2020
@Uhf7,
Thank you for fixing the Copy/Paste issue. :+1:
Yaron10
on 9 Aug 2020
@Yaron10, @Ekopalypse I revised my parser version to exclude your nice example from being detected completely as URL.
What I changed: I allow quotes only in the query part of the URL. And the query part is scrutinized a little closer and has to be at least similar to the "official" query format (which seems not to be complied with in every case).
If you still want to test, here is my current source file again.
Notepad_plus.zip
Uhf7
on 12 Aug 2020
@Uhf7,
:+1:
Great! Thank you for your work.
Interestingly, Firefox opens https://*/* in a new window instead of a new tab.
Not expecting an explanation. Just sharing.
Yaron10
on 12 Aug 2020
@Uhf7,
Minor: is MAILTO: a legit INTERNET_SCHEME_MAILTO?
Yaron10
on 13 Aug 2020
Yes, mailto: is a standard URL scheme. As is file: too, for example. But I think it is good to restrict the schemes to a few of the standard schemes, which the installed internet browser and the installed e-mail software can handle.
Uhf7
on 13 Aug 2020
@Uhf7,
Just to make sure there's no misunderstanding here: I meant MAILTO: without a following address.
For example: MAILTO: in INTERNET_SCHEME_MAILTO: (in your code) is underlined.
Thank you.
Yaron10
on 13 Aug 2020
@Yaron10,
Now I see it. Thank you again. I'm going to exclude this too.
Uhf7
on 13 Aug 2020
:+1:
Thank you.
Yaron10
on 13 Aug 2020
I did the following modifications:
- Exclude
scheme:alone without parameter string - Forbid underline and digits before URLs. No
abc_http://xxxanymore, no4560http://xxxneither. Although this was allowed in the past and goes through MS VS too, it doesn't feel right. And it is not accepted by Outlook, so at least one software does it like I feel. And I don't know any programming language, where_or0..9are used as delimiters.
If something else should speak against forbidding underline and digits before URLs, I revert this modification.
Uhf7
on 13 Aug 2020
@Uhf7,
Thanks for that too. :+1:
Yaron10
on 13 Aug 2020
Has anyone new strange text passages for me, which should or should not be detected as URL?
Uhf7
on 15 Aug 2020
I'm done. :)
It took some time but the result is great.
Yaron10
on 15 Aug 2020
@Yaron10,
thank you for testing, I will PR the new detection method for URLs soon.
Uhf7
on 15 Aug 2020
@Uhf7,
A minor issue (not related to the parser, but I'd rather bring it up here).
Comment a link in a C++ file.
-- The text is green and the underline is black.

Paste a link in a C++ file.
-- The part after the // is interpreted as a comment.

Paste https://www.youtube.com/watch?v=VmcftreqQ6E&list=PnQIRE5O5JpiLL&index=1 in an XML file.

On hover:

You're not supposed to have un-commented links in such files. But still... A mini-minor issue. :)
Thank you.
Yaron10
on 23 Aug 2020
Yaron10,
this is, because standard indicators are supposed to complement syntax highlighting, not to replace it. So I find it correct, that it becomes multi-colorized while not hovered.
That only a part of the link is displayed blue while hovered, seems to be another Scintilla problem. I will search it as soon as I can. It was there before my modifications, in the INDIC_TEXTFORE style (The explorer link style is a combination of INDIC_TEXTFORE and INIDIC_PLAIN).
But, damage control: On double click, the whole URL is used, and the full box style is not affected by this. And if the URL is syntactically correct in the document, it should be single color anyway.
I bet, that Notepad++ is really the first application, which is using the standard indicators to highlight URLs, although exactly this is recommended in _ScintillaDoc.html_ (search "URL " in it).
Uhf7
on 23 Aug 2020
this is, because standard indicators are supposed to complement syntax highlighting, not to replace it. So I find it correct, that it becomes multi-colorized while not hovered.
:+1:
That only a part of the link is displayed blue while hovered, seems to be another Scintilla problem. I will search it as soon as I can.
Thank you. But I'm not sure it should be worth it (mini-minor issue).
You didn't refer to the first case which is slightly more significant: Comment a link in a C++ file.
Should I assume it's not worth the extra work/code?
Yaron10
on 23 Aug 2020
You didn't refer to the first case which ...
I did mean exactly the C++ example too in the 1st part of my answer: That's syntax highlighting, and the part of the line after // is a comment in C++. There are no URLs in the C++ syntax. And the _https:_ before the comment will make its way into the error list while compiling anyway.
And I see, that the MS VS does it not this way, it prioritizes the URL, but this seems not to be worth of imitation to me.
Uhf7
on 23 Aug 2020
I'm afraid we have a misunderstanding here.
My question is if the underline shouldn't be green too.
If you did understand my question correctly - I apologize.
Yaron10
on 23 Aug 2020
My question is if the underline shouldn't be green too.
No need to apologize. It was so clear to me, that the underline should not be green, that it didn't occur to me to mention it :-).
The underline is always in the default text color. Technically, it is not possible to make the underline color follow the syntax highlighting color.
When not hovered, we have two options:
- Hidden: The URL is shown in the current syntax highlighting.
- Underlined: The URL is shown in the current syntax highlighting, and underlined in default text color.
And: If the underline color would follow the current syntax highlighting color, it wouldn't unite/embrace the link anymore, it would fall apart optically even more in situations shown in your XML example.
Uhf7
on 23 Aug 2020
When not hovered, we have two options:
But then you came up with INDIC_EXPLORERLINK for hover. :)
(So theoretically it can be implemented for "normal-state" as well).
And: If the underline color would follow the current syntax highlighting color, it wouldn't unite/embrace the link anymore, it would fall apart optically even more in situations shown in your XML example.
This is a very good point.
But the two issues are intertwined: if (theoretically) links were excluded from syntax highlighting, the one text color could be applied to the underline too.
Just theoretically.
Thanks again for your work. I appreciate it.
Yaron10
on 24 Aug 2020
@Uhf7,
I've just encountered a slightly more serious issue with INDIC_EXPLORERLINK.
Word-Wrap: ON.
Paste a link in a normal text file.
Make sure the link is wrapped.
Hover.

Should I open a new issue or you'd rather continue the discussion here?
Thank you.
Yaron10
on 25 Aug 2020
@Yaron10,
thank you for testing thoroughly, another interesting effect.
But this is basically the same Scintilla problem as with the hovered, syntax-highlighted links, which become blue only partially. The detection whether the character belongs to a hovered indicator or not doesn't work.
I have a way to solve this filed as https://sourceforge.net/p/scintilla/bugs/2199/. Actually, I wanted to wait for an answer to this, before I create the PR to integrate it in the Notepad++ SciLexer.dll. But I will create it without answer, after an adequate waiting time.
_Edit:_ The 100th comment to this issue, we shouldn't loose the focus here, the whole thing was actually about the cyrillic characters in a link, I have to PR my parser suggestion someday.
Uhf7
on 25 Aug 2020
@Uhf7,
Thank you for the quick fix. :+1:
Hopefully, last post here.
Yaron10
on 25 Aug 2020
Related issues
 ArthurDentDK
·
3Comments
ArthurDentDK
·
3Comments
 marcoatgit
·
3Comments
marcoatgit
·
3Comments
 Zarggg
·
3Comments
Zarggg
·
3Comments
 bveldkamp
·
3Comments
bveldkamp
·
3Comments
 Fabian42
·
3Comments
Fabian42
·
3Comments
Most helpful comment
@Ekopalypse,
I don't think we remove too much. Yes, an URL can contain closing parenthesis without opening counterparts, but there is not much advantage in highlighting the closing ')' of such URLs, compared to the negative effect on URLs enclosed in '(' ')'. And: MS Visual Studio removes closing parenthesis from the end, regardless, whether they occur in the URL or not, that seems to be even worse.
Concerning '?' and '#': This would be empty queries and empty fragments, not needed either in a meaningful URL. Those are removed by MS Visual Studio too, if they are alone at the end of an URL. They are not removed, if there is any non-punctuation character after it. It is like this in MS Visual Studio too (the parser does the same):
http://www.whatever.com/?abc-?abcis kept.http://www.whatever.com/?-?is removed.http://www.whatever.com/#abc-#abcis kept.http://www.whatever.com/#-#is removed.http://www.whatever.com/#.-#.is removed.http://www.whatever.com/f;.#- ;.# is removed.http://www.whatever.com/f;.#abc-;.#abcis kept.The goal is, that most meaningful URLs go through the parser, and that the meaningful URLs don't become useless, because some additional characters are typed behind them. Some very special cases of URLs may get lost here, but the win is greater than the loss, I guess.