@ktsaou @paulfantom @gmosx @l2isbad
Please review https://netdata-doc.readthedocs.io/en/latest/README-Template/
It's supposed to be a standard template for all plugin READMEs that I will be parsing to include in the generated parts of the docs
 cakrit
cakrit
All 56 comments
How can I see a raw markdown version of this file?
 paulfantom
on 14 Oct 2018
cakrit
on 14 Oct 2018
paulfantom
on 14 Oct 2018
cakrit
on 14 Oct 2018
Please also understand the link to the contributing guidelines (i.e. read the PR section in the proposed Contributing.md in #4146
cakrit
on 14 Oct 2018
What is the purpose of this readme? It looks like mixing user docs with developer docs and like something which be very quickly outdated during development. Good example is Makefile entry which doesn't help in plugin development and can change frequently (not mentioning that it will be outdated when we move away from autoconf).
paulfantom
on 15 Oct 2018
It's mandatory documentation for any plugin to help users and devs. The parts relevant to users will appear on generated pages for users, the devs need the whole thing. With a given structure I can write scripts to grab any part I need for any purpose. E.g. to create a list of all pulython plugins or of all web plugins etc.
cakrit
on 15 Oct 2018
As a dev I don't need all this. But I am no longer a plugin maintainer so probably @Ferroin and @l2isbad vote would be more meaningful.
paulfantom
on 15 Oct 2018
How should we name them? Plugins or modules?
template for plugins
[Module Name]
module is confusing for people. I suggest plugin.
 ilyam8
on 15 Oct 2018
ilyam8
on 15 Oct 2018
@cakrit
how about to add metrics/measurements ?
ilyam8
on 15 Oct 2018
Both ideas good.
Plugins it is
Can you suggest a template for the measurements? E.g. name, period, what appears on the web URL after the hash tag, short description perhaps?
Will also remove the lines on Makefile from the top table.
cakrit
on 15 Oct 2018
The config entry stuff should probably be non-optional and reference what file the plugin/module uses for it's configuration.
Also, the stuff referencing the config and makefile that's been pulled from the new plugin checklist can be dropped, it's irrelevant to end-user documentation and only matters for people developing _new_ plugins (where neither item is optional, you need the makefile entry for the plugin to get installed, and you need the config entry so people have a config template to work with).
Other than that, looks good to me.
 Ferroin
on 15 Oct 2018
Ferroin
on 15 Oct 2018
Can you suggest a template for the measurements?
Good question, we need to think about it.
And we need alarms description (or link to module alarm conf file) for module/plugin.
ilyam8
on 15 Oct 2018
Ok, look at it now, I used the nginx python module for an in-file example.
https://github.com/cakrit/netdata-doc/blob/master/source/md/README-Template.md
- Unfortunately I haven't read enough about how alarms work to be able to explain the preconfigured alarm.
- I added a draft table for the metrics, please suggest a final update so we can close this.
cakrit
on 15 Oct 2018
Guys, plugins are talking to netdata, modules are data collection modules of plugins.
If we call everything plugin, it will be confusing even for us.
 ktsaou
on 15 Oct 2018
ktsaou
on 15 Oct 2018
@cakrit
Why do we need Dev Notes ? User doesn't need it imo. All these TODOs and explanations of cryptic code should be in code.
ilyam8
on 16 Oct 2018
From my perspective as a developer and as external observer, my opinion is that first of all the hierarchy plugin --> modules is the best. Also, looking through the wiki pages, there is inconsistency about how you calling the custom made plugins. In some cases you call them external plugins and in other cases python/node modules etc. ex (https://github.com/netdata/netdata/wiki/External-Plugins , https://github.com/netdata/netdata/wiki/How-to-write-new-module ). From my perspective the best approach is to have consistency through all the project.
Adding to that, as @l2isbad mentions it will be good to know in that documentation what metrics a plugin/module exposes and the description of those, especially for the users this will be great.
For last but not least, the more information you give about the project the better it is, either by having a documentation just for developer and other for users or by integrated them in one. The reason for this is because, anyonem that wants to use netdata, will be more prone to use it if he see the work that you have done guys and he will be more trustful towards your project.
 ktheodosiou
on 16 Oct 2018
ktheodosiou
on 16 Oct 2018
From my perspective as a developer and as external observer, my opinion is that first of all the hierarchy plugin --> modules is the best
Yes!
but nobody (except @ktsaou and me) calles them modules...
Plugin strikes again
ilyam8
on 16 Oct 2018
but nobody (except @ktsaou and me) calles them modules...
I try, I'm just not consistent about it.
Ferroin
on 16 Oct 2018
@konstheod is right. We have to be consistent, no matter what the users and contributors do.
So, as far as we are concerned, there are netdata plugins and their modules.
I have tried to move all relevant documentation of plugins inside the repo: https://github.com/netdata/netdata/tree/master/collectors
Please help. For example the README.md of https://github.com/netdata/netdata/tree/master/collectors/python.d.plugin is neither consistent, nor complete.
Each plugin should have its own documentation about adding modules to it. Then we should have some generic information for adding new data collectors to netdata (module or plugin), probably here: https://github.com/netdata/netdata/tree/master/collectors
Information about adding external plugins (not modules), should go here: https://github.com/netdata/netdata/tree/master/collectors/plugins.d
The idea is to embed the relative information into the source tree. All these README.md files will automatically be pulled to documentation.
ktsaou
on 16 Oct 2018
Just change name from plugins to collectors and we are consistent even with directory schema.
paulfantom
on 16 Oct 2018
Just change name from plugins to collectors and we are consistent even with directory schema.
Based on what I understand now and after reading more carefully some of the docs:
python.d is properly described as one of the following (depending which document you read)
- "external collection orchestrator plugin"
- "external collection skeleton plugin"
- "external collection modular plugin" -
I prefer the term "modular plugin" myself.
nginx would then be an "external collection module" that utilizes an "external collection modular plugin"
@ktsaou shouldn't we call graphite or prometheus "backend plugins" then?
Each plugin should have its own documentation about adding modules to it.
This should be: "Each _modular_ plugin should"... ? freeipmi will never have modules. The statement applies to BASH, node.js, python modular plugins.
- I'm creating two separate README templates for our collectors:
- Collector modules
- Collector plugins
- I'm not sure if I can manage a template or modular plugins as well (obviously with a section on adding modules to them). I'll give it a shot, but I may not know enough to make them consistent and complete right now.
Then we should have some generic information for adding new data collectors to netdata (module or plugin), probably here: https://github.com/netdata/netdata/tree/master/collectors
This one will be a merge of
https://github.com/netdata/netdata/tree/master/collectors/README.md
and
https://github.com/netdata/netdata/wiki/External-Plugins
Getting on with it.
cakrit
on 16 Oct 2018
external collection orchestrator plugin
People don't remember things which have more than 3 parts (that's why most abbreviations have 3 letters), so 4 word naming schemas are mouthful and won't be remembered which will just create more confusion.
via wikipedia:
In computing, a plug-in (or plugin, add-in, addin, add-on, addon, or extension) is a software component that adds a specific feature to an existing computer program.
So according to that definition our modules are plugins and our "plugins" are plugins. And almost everything is a module/plugin in netdata as this project adopts modular programming principles. For me we have two choices:
1) Fix docs and stick to current naming schema (which is confusing for new contributors)
2) Make everything a plugin, like:
- python.d collector plugin
- nginx python.d plugin (if it is written in non-C language it must be external)
- proc internal plugin
- X Y plugin, where Y is a netdata plugin type (collector, health, backend...) and X is a subset (nginx, graphite...)
Such naming schema can be easily converted to ToC where you just traverse a tree backwards to name a plugin:
├── collectors
│ └── python.d
├── python.d
│ ├── nginx
│ └── sensors
├── internal
│ └── proc
└── Y
└── X
Such naming convention is future proof, easily converts to a documentation and at least partly relates to our directory schema
paulfantom
on 16 Oct 2018
I'm sticking with Costas' structure and naming for now. You will never see the full four words anywhere.
Gents, I think that the following two are ready. I don't even think we need much discussion on how we capture the "metrics", which in fact are just the "CHART" lines that we'll see from the module or plugin. I took the mandatory parts of the "CHART" input lines that must exist in all collectors and I added one more column for "options". Please see the two templates and let me know if you're ok with them.
I think that to add them to netdata, we'd need to put both under the collectors directory, probably with different names than the ones I gave them. Feel free to be the godfather (i.e. suggest names)
https://netdata-doc.readthedocs.io/en/latest/README-Collector-Plugin-Template/
https://github.com/cakrit/netdata-doc/blob/master/source/md/README-Collector-Plugin-Template.md
https://netdata-doc.readthedocs.io/en/latest/README-Collector-Module-Template/
https://github.com/cakrit/netdata-doc/blob/master/source/md/README-Collector-Module-Template.md
cakrit
on 16 Oct 2018
Correction regarding my answer to this:
Then we should have some generic information for adding new data collectors to netdata (module or plugin), probably here: https://github.com/netdata/netdata/tree/master/collectors
https://github.com/netdata/netdata/tree/master/collectors/README.md
will say how to add new _internal plugins_ i.e. anything that does NOT use plugin.d. For external plugins, it will link to
https://github.com/netdata/netdata/tree/master/collectors/plugins.d/README.md
This is the one I'm merging with
https://github.com/netdata/netdata/wiki/External-Plugins
cakrit
on 16 Oct 2018
https://github.com/netdata/netdata/tree/master/collectors/plugins.d/README.md
updated with content from External-Plugins in #4414
cakrit
on 16 Oct 2018
I find the term module extremely overloaded.
Also the .d postfix is very confusing (it sounds like daemon to me, not orchestrator)
Btw, the term orchestrator is also not very accurate, maybe such plugins could be called Proxy or as suggested above just Plugin (or MetaPlugin, or something).
FWIW, I kind of like Pawel's suggestion.
 gmosx
on 17 Oct 2018
gmosx
on 17 Oct 2018
On a related note, why is the BASH 'orchestrator' called charts.d instead of e.g. bash.d? Also very confusing.
gmosx
on 17 Oct 2018
The only confusing part about plugin/modules is that some times the collection of the metrics is been done from the plugin and some times from the modules. So, another proposal is to call them plugin and subplugins, if that doesn't destroy your structure.
ktheodosiou
on 17 Oct 2018
plugins/sub-plugins also works... I think we should also replace the .d postfix with something more descriptive.
gmosx
on 17 Oct 2018
@gmosx The charts.d name appears to largely be a historical artifact. It was the first modular plugin created (some of the stuff now in the core actually started life as charts.d modules).
Not 100% certain why the .d postfix was chosen, but it's pretty normal to use it on UNIX systems to signify a directory containing components used for whatever the rest of the name is. You can easily see this in /etc on most UNIX systems (/etc/init.d, /etc/rc.d, /etc/logrotate.d, /etc/xinetd.d, plus a number of others) where it's used to signify a directory containing configuration fragments that get parsed together as a file.
Also, I actually prefer the term 'module' for stuff. That's really how the Node.js and Python plugins actually work, they treat the individual collectors as modules, which they load and run.
Ferroin
on 17 Oct 2018
"where it's used to signify a directory containing configuration fragments that get parsed together as a file." But we don't have "configuration fragments parsed together" in this case.
Also re the term 'module'. If there were e.g. golang plugins, the notion of module is something different, so the analogy breaks. Again, 'module' is extremely overloaded (e.g. https://en.wikipedia.org/wiki/Module_(mathematics)). Moreover, how (currently) Node.js/Python plugins work is an implementation detail that may change and should not affect the 'interface' (i.e. naming).
Finally, 'modular plugin' sounds strange, a plugin is already something modular.
gmosx
on 17 Oct 2018
This has turned into a conversation on naming and structure, which is not blocking to finalizing the README templates. I have two things that I would like suggestions on, so I can do a PR to add them:
Charts section:
Are we ok with it? I was thinking of an alternative way to do it, which is to put the actual CHART output of the plugin/module. I don't know enough to be able to get these lines right now, but it might be easier for the contributors to add those than to work with the painful markdown table structure.Where to put them and how to name them, given the _current structure_
- Option 1: One directory under collectors, called either doc, or templates. e.g.
collectors/doc/Plugin-README-Template.md
collectors/doc/Module-README-Template.md
- Option 1: One directory under collectors, called either doc, or templates. e.g.
- Option 2: Directly under collectors, perhaps same exact naming as Option 1.
- Option 3:
- README-Template.md under collectors
- 3 copies of README-Template.md under each of the 3 "orchestrator plugin" directories: python.d.plugin, node.d.plugin, charts.d.plugin. This would eliminate two entries from the top table: "Modular Plugin" and "Prog. Language", as they are specified by the directory itself. It would also enable us to tailor each of the three module README templates to the particular orchestrator plugin, if we choose to.
cakrit
on 17 Oct 2018
Charts section:
Are we ok with it? I was thinking of an alternative way to do it, which is to put the actual CHART output of the plugin/module. I don't know enough to be able to get these lines right now, but it might be easier for the contributors to add those than to work with the painful markdown table structure.
I do think having an actual list of the metrics instead of something like a screenshot here is good. If desired, I can throw together a wrapper that will auto-generate the tables for this for the Python modules, it largely comes down to some simple dictionary parsing and string formatting, and would probably be at most a few dozen lines of code.
Where to put them and how to name them, given the current structure
I think option 3 sounds best, largely because of the ability to fine-tune the design to fit the orchestrator plugin.
Ferroin
on 17 Oct 2018
I can throw together a wrapper that will auto-generate the tables for this for the Python modules
That would be cool. You could just append the result to all python module readmes with the ## Charts header and we would only need to clean up the few that already have charts or metrics mentioned. I'll see how many other parts we can auto generate as well, certainly a few of the params in the first table will be easy. I will do something similar for bash modules and check the node.js ones
cakrit
on 17 Oct 2018
@cakrit OK, I'll look into getting that done at some point within the next week or so. I assume we want the resultant script somewhere public (either in the eventual docs repository, or the main Netdata repository)?
Ferroin
on 18 Oct 2018
I agree that a few names like charts.d is now out of focus, but this will be a complicated change. There is another one: charts.d.plugin uses *.chart.sh modules, pyhton.d.plugin uses *.chart.py modules, but node.d.plugin uses *.node.js modules. They should be *.chart.js or we should change chart part completely.
Anyway, as I said, migrating to new names for these is not something that important now. So, we can postpone them.
Regarding .d extension in modular things I agree with @Ferroin they are quite standard in Linux. When sysadmins and devops see this, they expect to the find parts of a modular thing in it.
Regarding the modules name, I don't have a strong opinion about it. A module is a part of something that is modular. So python.d.plugin is modular and its modules are its plugins. I understand the confusion though, since netdata has many layers of plugins.
For example:
apache.chart.pyis a module, a plugin ofpython.d.pluginpython.d.pluginis a module, a plugin ofplugins.d.pluginsplugins.d.pluginis a module, a plugin of thenetdatadaemon
So, in netdata it is common for something (eg python.d.plugin) to be modular by itself (i.e. have its own modules, childs) and at the same time be a module of something else (ie. be a plugin of a parent).
Similar layers of plugins are all over the place.
ktsaou
on 18 Oct 2018
The only confusing part about plugin/modules is that some times the collection of the metrics is been done from the plugin and some times from the modules.
@konstheod this never happens for the same plugin. So any given plugin is either modular, or it is not. This is why I tried to introduce the term plugin orchestrator for the modular ones.
I am open to other ideas of course...
ktsaou
on 18 Oct 2018
README-TEMPLATE.md under collectors/ is nice.
ktsaou
on 18 Oct 2018
@konstheod this never happens for the same plugin. So any given plugin is either modular, or it is not. This is why I tried to introduce the term plugin orchestrator for the modular ones.
btw, we could loose the .plugin extension from plugin orchestrators, like I have done for plugins.d: https://github.com/netdata/netdata/tree/master/collectors
So instead of python.d.plugin we could say python.d.
I think however this will confuse users, since we frequently instruct them to run /usr/libexec/netdata/plugins.d/python.d.plugin.
Note that this is ok of plugins.d because it is just the path before python.d.plugin. So netdata/plugins.d/python.d.plugin reflects the truth. In the first PR I made we had python.d.plugin under plugins.d/ too, but we discussed this a bit and concluded that it is more important for users to have a full list of all data collection plugins than to reflect their internal structure, so I moved all modular plugins at https://github.com/netdata/netdata/tree/master/collectors.
README.md at https://github.com/netdata/netdata/tree/master/collectors/plugins.d still lists the plugins that are modules of plugins.d.
ktsaou
on 18 Oct 2018
Also, regarding the auto-generation of dimension documentation for Python modules, this will only work for some modules. Any dimensions generated at runtime (which unfortunately is about half the modules) won't easily be possible to add. We could look into extending the Python module API a bit to add a table that's simply responsible for documenting the dimensions, but that would require changes to all the existing modules (I could take care of most of that too, but it would take longer).
Ferroin
on 18 Oct 2018
I think documenting charts is more important than dimensions.
The list will be shorter and more meaningful.
ktsaou
on 18 Oct 2018
I'm not really talking about having rigorous documentation of dimensions, but you're not exactly documenting the chart if you don't document what it's charting.
Ferroin
on 18 Oct 2018
I'm not really talking about having rigorous documentation of dimensions, but you're not exactly documenting the chart if you don't document what it's charting.
This is what I meant too. You are not required to document every dimension in detail. Generally, the chart titles indicate which dimensions are included. At least, they should. So if you say this is about bandwidth, you are not required to say it includes 2 dimensions: inbound and outbound.
ktsaou
on 18 Oct 2018
Of course it is not that obvious for every chart...
ktsaou
on 18 Oct 2018
PR #4436 created. Will close this one when the PR is merged.
I created #4438 to get all collector README.md files aligned to the templates.
The python script to generate the table needs to run only once, as part of #4438. The code to generate the table will need to be incorporated to the scripts that we will build #4431.
cakrit
on 18 Oct 2018
Outlining areas of concern mentioned in PR #4436
@l2isbad and @Ferroin I'd appreciate your feedback.
_Dependencies_
| That's it. We need a section with additional configuration for monitored service, maybe with examples. This would be user friendly.
We have both an installation and a configuration section. Specifically regarding the example on nginx, we have the following in the Installation section of the README:
| nginx should have the ngx_http_stub_status_module configured
Indeed, there's some repetition here. I like having the info in the table, because we could write anything at all in the Installation section. A single parameter forces us to be succinct about why I don't see the particular charts.
Indeed, the following is true:
| it should describe whether it is necessary to install additional packages or not
To be a bit picky, this should probably also be included:
| icecast module needs icecast intallation, isc_dhcpd need isc_dhcpd installation?
The prerequisite are not necessarily self-evident from the name of the plugin/module. For the particular cases, perhaps the module only supports specific versions. I would think of it as a quick, user-friendly version of a requirements.txt (e.g. isc_dhcpd version >= X with module y enabled)
I appreciate that the word 'Dependencies' may mean different things to different people. We can also call it Prerequisites or Requirements.
Still, no strong feelings here. If you all agree that we only need this info in the Installation section, I'll ensure to explicitly ask that the particular section addresses all prerequisites.
_Alarms_
| We should have descriptions not code.
Of course, it's just that as I said before in this thread, I haven't read enough about how alarms work to be able to explain the nginx preconfigured alarm. If someone can help me explain how "The only preconfigured alarm makes sure nginx is running", the code will be removed.
_Charts_
| type id depends on job name
From what I understood from a recent conversation with Costas, "job name" is the second column: "name". When it is empty (as in the particular example), netdata takes the id and uses that for a name. So it's not the other way around. Plus, we may have modules with both an id and a name
| nginx_local is wrong
Please help here, because I don't get this one. The code says nginx_local.
| Who needs that table? (user has no clue what is family, context, charttype)
Actually, all these things affect the UI and some of them appear exactly the same way there. I can convert the column names to links to the place in collectors/plugin.d/README.md where each parameter is explained. That README will need a modification to make the sections linkable of course, but that should cover it.
cakrit
on 23 Oct 2018
Indeed, there's some repetition here. I like having the info in the table, because we could write anything at all in the Installation section. A single parameter forces us to be succinct about why I don't see the particular charts.
Agreed. Having some concrete info about what is needed on both the Netdata side and the monitored application without having to go into the level of detail that installation or setup instructions might helps people who already know how to configure things, but just don't know what components are necessary.
Still, no strong feelings here. If you all agree that we only need this info in the Installation section, I'll ensure to explicitly ask that the particular section addresses all prerequisites.
I think there should be info about this in the install section, _but_ I also think that info should be summarized in the general plugin description. In both cases it should differentiate between what's needed for the module to run and what is needed on the monitored service/system/device for it to actually collect data.
Ferroin
on 24 Oct 2018
Updated PR #4436.
cakrit
on 24 Oct 2018
type id depends on job name
example (module __nginx__):
# 2 jobs
local:
param: value
remote:
name: my_server
param: value
each job has:
- module name (__module_name__.chart.py)
- job name (__local__ or __remote__)
- job override name (__my_server__ in remote, _name_ param)
case 1, job has override name:
- type.id = module_name + "_" + override_name (nginx_my_server)
case 2, job has no override name:
- type.id = module_name + "_" + job_name (nginx_local, nginx_remote)
special case, job has no override name + it's a 1 job config:
- type.id = module_name (nginx)
like
# only 1 job, `local` is not used in job_name
local:
param: value
So using nginx instead of nginx_something is correct.
ilyam8
on 25 Oct 2018
I recommend:
- add readme for a few more modules to see if the suggested template fits well. (_nginx_ is easy one, 4 charts total, no dynamic charts)
- maybe survey some users makes sense (readme is for them, isn't it?)
I am personally (as a user) don't like charts format - big unreadable table.
What information do you want to convey to users? List of charts? A simple list wll do (chart name, chart description).
If the goal is to provide a detail info about charts (but still the question is why does the user need it? how it is useful for him?) then current version is OK. Keep in mind that user (in 99% of the cases) doesn't want to know details and doesn't need to (incremental or not, etc).
ilyam8
on 25 Oct 2018
If someone can help me explain how "The only preconfigured alarm makes sure nginx is running"
I think we need a list of preconfigured alarms without details. "The only preconfigured alarm makes sure nginx is running" means it monitors service availability, nothing more.
Maybe others have different opinion on level of details.
ilyam8
on 25 Oct 2018
- Removed the alarm code from nginx
- Removed the "live demo" link, due to https://github.com/netdata/netdata/issues/4394#issuecomment-432883501 . I talked about it with @ktsaou and I will use the "context" to get the info I need from js to dynamically include charts in the html documentation instead.
- Removed four of the columns from the Charts table (type.id, name, char type and options). I'm not sure if I will need to use "family" in the html doc, but I definitely need the context to be there.
@l2isbad please review and approve the PR so we can close this.
cakrit
on 29 Oct 2018
Adding below @ktsaou 's suggestion:
Example of what I have in mind:
nginx
INTRO: be accurate - describe what exactly this module collects info about
Collect metrics from nginx web servers using their stub_status plugin. It supports all versions of nginx.
How it works
HOW: be accurate - describe how this works
This module connects directly to one or more nginx servers and uses their stub_status plugin to collect all the metrics exposed.
What is collected
CHARTS: describe them. This is what triggers expectations. A screenshot would be better. A live dashboard fragment would be best.
Information presented here MUST be available on the dashboard by modifying
dashboard_info.js. There is no point to have here more information compared to the dashboard.Ideally, the info should be entered just once. For example, the user could describe each dimension in a yaml file and this yaml file could be turned into
dashboard_info.jsand added here. The list of charts and their dimensions could be extracted directly from the plugin using the same methodology our test framework could use to test the plugin.
Of course we need to discuss this a bit.
- Active Connections (context
nginx.connections, unitsconnections)
active, the number of currently active connections
- Requests Rate (context
nginx.requests, unitsrequests/s)
requests, the rate requests are handled
- Active Connections by Status (context
nginx.connection_status, unitsconnections)
reading, the number of connections nginx is currently reading fromwriting, the number of connections nginx is currently writing toidle, the number of currently idle connections
- Connections Rate (context
nginx.connect_rate, unitsconnections/s)
accepted, the number of connections acceptedhandled, the number of connections handled
Installation
Give users a clear picture on what they need to run this module.
This module is part of python.d.plugin, so it runs everywhere python.d.plugin runs.
Other than that, this module does not have any additional dependencies.
Configuration
There are two parts that may need to be configured:
configure the nginx web server to be monitored
Describe what the monitored application needs to get monitored
The nginx web server to be monitored must have the stub_status plugin enabled. To enable it follow the documentation of your distribution, or the official nginx documentation.
Give the user a way to verify he/she has configured the monitored application properly
To verify your nginx is capable to enable this module, run:
# nginx -V 2>&1| grep -o http_stub_status_module
http_stub_status_module
If you don't have this output, you need to install a different package of nginx with stub_status available.
To verify your nginx server has its stub_status plugin enabled, run the following on the server you installed netdata:
# curl -Ss 'http://localhost/stub_status'
Active connections: 229
server accepts handled requests
53423861 53423861 188627409
Reading: 0 Writing: 1 Waiting: 228
The URL may be different, depending on the location of your nginx server and its configuration.
configure the nginx data collection module
netdata configuration is hierarchical - mention the parents:
This module is part of python.d.plugin and it uses URLService:
- Generic configuration guidelines for python.d.plugin modules.
- Generic configuration guidelines for URLService modules.
specific instructions for this module:
The following are additional configuration directives this module accepts.
To edit the module configuration, run /etc/netdata/edit-config python.d/nginx.conf.
For each nginx web server to be monitored there must be a section, like this:
{NAME}:
url: '{URL}'
where:
{NAME}is anything you want to name this web server. Check valid job_names for picking a valid name.{URL}is the URL the nginx web server exposes itsstub_statusplugin metrics.
Multiple such sections may be added, one for each nginx server to be monitored.
stock netdata configuration
what netdata should be able to do, without any configuration:
The default configuration shipped with netdata has this module enabled. The default configuration auto-detects an nginx web server running on localhost and listening on port 80, with stub_status enabled.
Platform notes:
Distro|Version(s)|Auto-Detected|Manual Actions Required
:---:|:---:|:---:|:---:|
Ubuntu|18.04|yes|-
Centos|7|yes|-
RHEL|7.5|yes|-
Alpine|3+|no|enable stub_plugin for nginx by editing /etc/nginx/nginx.conf and setting this and that. If this section is very long, add another section bellow with the information required.
Troubleshooting
Make sure the nginx server exposes the metrics by fetching the nginx URL by hand, using curl.
If curl works, but netdata fails to collect metrics, check the general troubleshooting guidelines of python.d.plugin modules.
Alarms
alarm configuration should be moved to the module directory, so that everything about the module is together.
Netdata's default configuration actives an alarm per nginx server monitored that checks that the nginx web server is alive.
Example:
 live alarm status.
live alarm status.
See Also
People will come here looking for ways to monitor their
nginx. Give them the alternatives.
- collect metrics from nginx+ servers.
- monitor web server
access.logfiles and extract performance metrics using the web_log module. - monitor any process, using apps.plugin.
cakrit
on 30 Oct 2018
Questions on the example:
- How come the current dashboard_info.js only has context for nginx.connections and nginx.requests? Does this mean we won't show the other two? Haven't set up an nginx to test it...
- I got confused regarding where I should edit the config:
To edit the module configuration, run /etc/netdata/edit-config python.d/nginx.conf
enable stub_plugin for nginx by editing /etc/nginx/nginx.conf
- I'm missing the metadata that I'd need to put it in the right place (e.g. Category: Web, perhaps sub-category). That can got to the yaml.
- I'll have to think about how generating part of the README from the yaml will work (i.e. what the process will be for the contributor, what will be committed in github vs what will be generated by a build command etc.)
Top Priority Tasks:
- [ ] Define the yaml format
- [ ] Design and agree on the collector documentation process
- [ ] Implement the first version of the process (with READMEs only)
Next set of Tasks:
- [ ] Move alarm configs to the module directory
- [ ] Script to generate the individual dashboard_info.js files from yaml
- [ ] Update makefiles to generate the big dashboard_info.js
- [ ] Script to create the static htmls
cakrit
on 30 Oct 2018
- How come the current dashboard_info.js only has context for nginx.connections and nginx.requests? Does this mean we won't show the other two? Haven't set up an nginx to test it...
Check this:
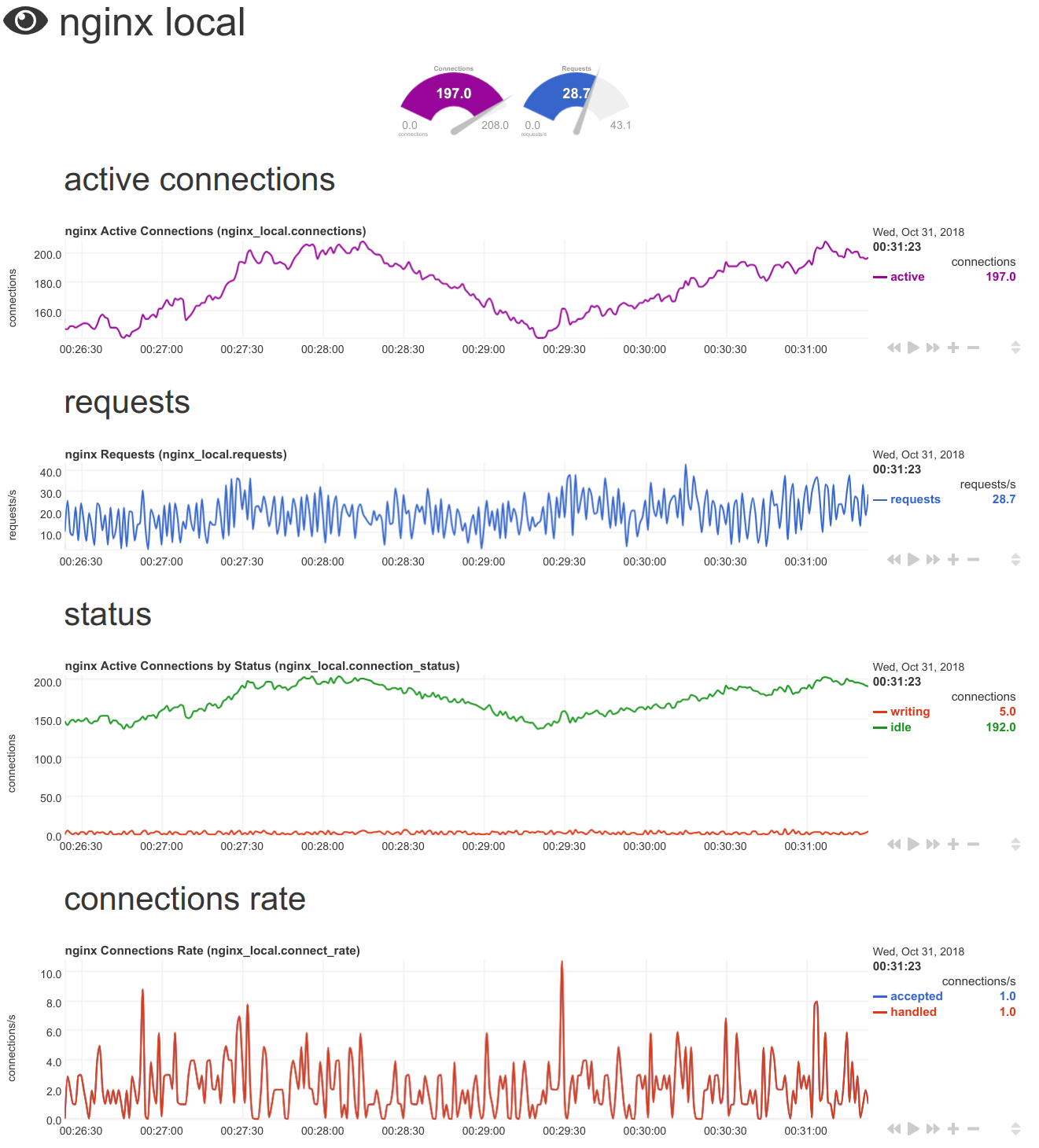
It is here: http://registry.my-netdata.io/#menu_nginx_local_submenu_requests
So, dashboard_info.js currently sets:
The icon - it is here: https://github.com/netdata/netdata/blob/9f681f10af1128a93f14df6ad4061485300dbc37/web/gui/dashboard_info.js#L297-L301
The colors of the 2 charts, here: https://github.com/netdata/netdata/blob/9f681f10af1128a93f14df6ad4061485300dbc37/web/gui/dashboard_info.js#L1325-L1337
Select the charts/dimensions that are shown at the top of section as gauges (the
mainheadsas shown above).
It does not add any content. It just beautifies the existing.
- Does this mean we won't show the other two?
no. We just don't alter anything for the other 2.
- I'm missing the metadata that I'd need to put it in the right place (e.g. Category: Web, perhaps sub-category). That can got to the yaml.
Yes, I thought about this too. It should be somewhere, but this is just a technicality we need to group the modules.
- I'll have to think about how generating part of the README from the yaml will work (i.e. what the process will be for the contributor, what will be committed in github vs what will be generated by a build command etc.)
We have to discuss this with @paulfantom . It is quite restricting to require everything to be supplied by the contributor by hand, especially when we can automate it easily.
For example, we could have a a special mode of python.d.plugin that will just dump a yaml with all the charts and dimensions defined in each module, with probably report if the module is multi- or single- job, its configuration settings, its defaults, etc. All these could be used to automatically build a README.md, a fragment of dashboard_info.js, a JSON fragment to build the nice dashboard we need with all modules (the add-more-charts-to-netdata page), etc. Now, all these have to be done by hand, while most of the info needed is just a repetition.
A solution could be to split it in 2 halfs. One in the repo, one at the hub. or one at the repo, the other at CI posting something at the hub.
Generally makefiles are very good at tracking dependencies between files. So if B depends on A and A has changed, B will be updated too. This means Makefiles (automake, cmake or whatever), could run things under condition. Then the CI could run these too and check that A (source) and B (generated from A and commited into the repo) are actually synchronized. If they are not, CI should exit with error, so the PR will fail.
I don't know. It just seems stupid to write the same info again and again...
If you have better ideas, please talk...
ktsaou
on 30 Oct 2018
My thoughts after looking at the example README.md file for nginx:
- summary and "How it works" are overlapping in content and new contributors will have problems with those
- "What is collected" looks like it could be automated
- "Installation" section is irrelevant as modules are always bundled with the installer. We would probably benefit more from "Requirements" or "Dependencies" section
- Who will write "See Also" or "Troubleshooting" sections? Contributor? Or will there always be a follow-up PR messing our changelog?
- Fragment below is bullshit as nginx can have stub_status in various locations (even official docs say so: http://nginx.org/en/docs/http/ngx_http_stub_status_module.html):
To verify your nginx server has its stub_status plugin enabled, run the following on the server you installed netdata:
# curl -Ss 'http://localhost/stub_status
If we start expecting from contributors to present all options to how to check if something is properly configured instead of only pointing to official docs, then after some time we will have outdated docs and less contributors. Unless we want to limit drive-by contributions, then it is a good way.
I was in favor of small README files tightly coupled with code and targeted at developers/contributors, but I see that development of this took some wrong turn and ended up in creating a lot of data which will be hard to maintain and even create (especially by an external contributor). And the worst part is that one of the most important thing which contributor can easily add and which can simplify bug reproduction - raw data is not even considered to be added anywhere.
From my perspective you are unnecessary complicating things. Those huge readme files would be much nicer as a separate entries in a separate docs repository. Then we can add a daily job (or some webhook magic) to sync docs with main repo, no need to insert autogenerated files into already large repo. Most of the stuff can be either extracted from code files (by parsing) or from autogeneration and just supplemented by developer information stored in smaller .md files.
This is also unnecessary complicating things like an already complicated build system or repository permissions and would probably benefit from decoupling into separate entity.
Also there is an issue of a hub, where will this store documentation? Also in-code? What if in the future we add another repo which would be private, how would people collaborate on those docs?
It starts to look more like creating a doc for the fact of creating a doc. What happened to Agile principles? Why don't we start with something simple, apply it to new contributions, ask for feedback and then build on that instead of figuring out everything possible use case by ourselves? We are obviously biased and won't create a good solution from start, so why is everyone trying to do such?. Additionally creating a huge template for documentation is just off-putting for new contributors due to a fact that not a lot of developers like to write docs and a sheer size of this template. Personally I would just create a PR with a new module/feature and told you to do whatever you want with it after seeing that template.
In the meantime we don't have a lot of documentation (~100 pages) and it wouldn't be that hard to start there and create something that would give a lot of value (actual, good looking, consistent documentation site) with not a lot of effort (going through 100 pages).
One more thing - for some reason people prefer to go to a site to read docs instead of going through code repository and looking for readme files. So why are we so focused on creating full docs in readme files which then will cause problems to generate nice looking site?
Now as for autogeneration from yaml - home-assistant project already does this for their "components" (they have over 1000 of them) and it looks very good and informative. Their docs is one of the reasons why they have such large community around the project.
For example, we could have a a special mode of python.d.plugin that will just dump a yaml with all the charts and dimensions defined in each module, with probably report if the module is multi- or single- job, its configuration settings, its defaults, etc. All these could be used to automatically build a README.md, a fragment of dashboard_info.js
What about the other way round? Manually create YAML file and force module to read that for its configuration, dashboard.js for chart descriptions and later we could use the same file to create documentation. Such YAML file is more or less defined at the beginning of all python modules, so this will also have a benefit of increasing code readability by decoupling static config from code. This will provide a "living" documentation as you will need to write it for code to work.
paulfantom
on 31 Oct 2018
First step to unblock this work is to generate some of the required information from the plugin itself (with any way even a parser). The documentation will be unblocked, while #4685 progresses
cakrit
on 18 Nov 2018
Related issues
 jeremyjpj0916
·
3Comments
jeremyjpj0916
·
3Comments
 BecomeBamboo
·
3Comments
BecomeBamboo
·
3Comments
 dankott
·
3Comments
dankott
·
3Comments
 kenXengineering
·
3Comments
ktsaou
·
3Comments
kenXengineering
·
3Comments
ktsaou
·
3Comments