Esmvaltool: Issues with the combination of masking and regridding
With the following preprocessor settings I got very strange results:
preprocessors:
mask_regrid_lin2x2:
mask_landsea:
mask_out: sea
regrid:
target_grid: 2x2 (varying)
scheme: linear (varying)
I calculated temporal and spatial means of different models with different preprocessor settings (lin = linear scheme, aw = area_weighted scheme):
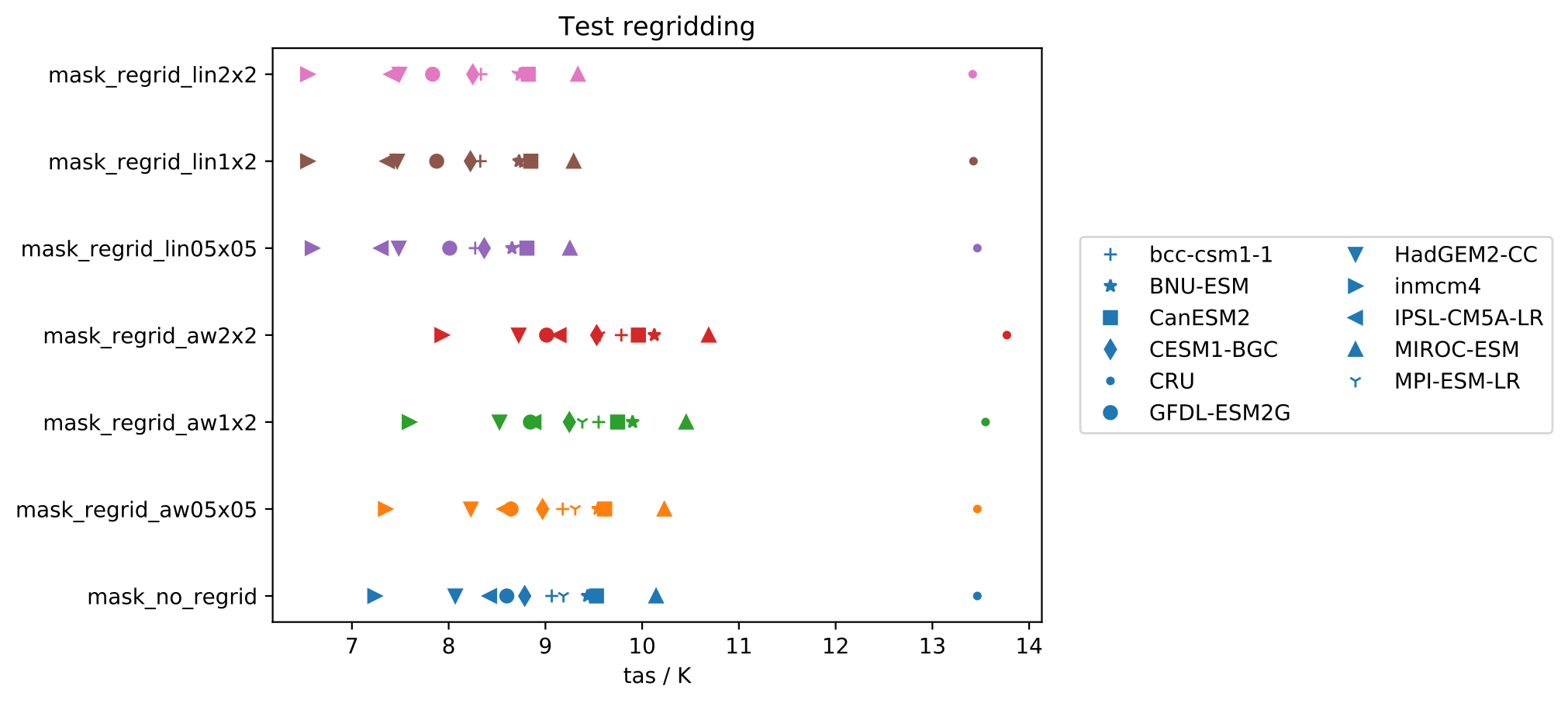
As you can see, the results of the linear regridding are systematically biased to lower temperatures. The preprocessed files look like this, this is the (masked) original file (1.5° x 2° grid):
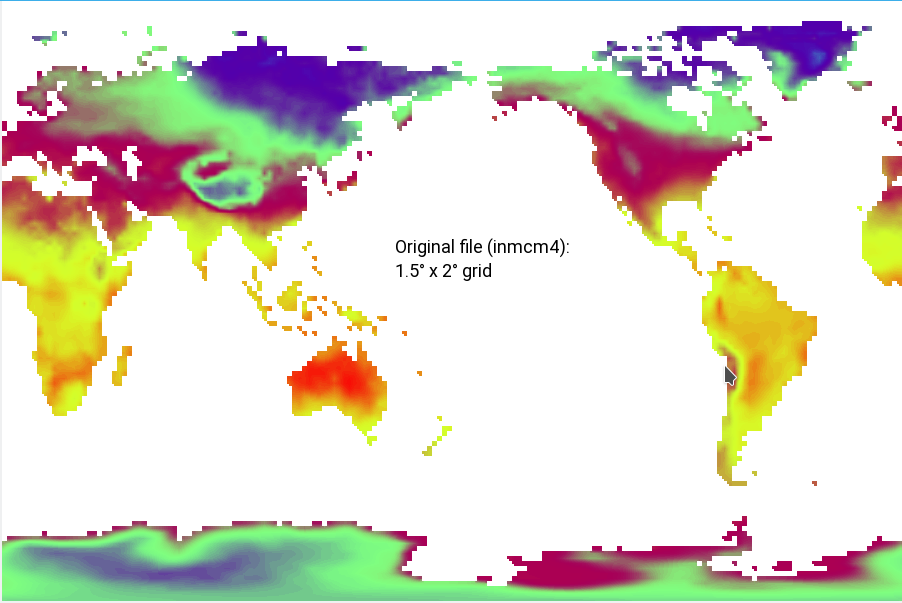
This is the masked file regridded to a 0.5° x 0.5° grid:
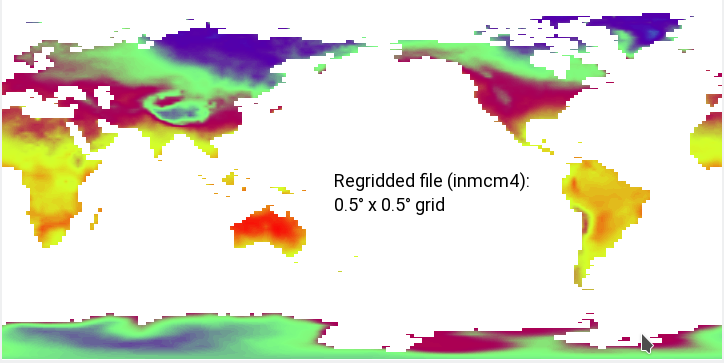
Since the regridding step comes right after the masking, the second picture should be the direct result of the first. I really cannot understand why the regridded file misses so many points (e.g. Indonesia, Northern Canada, Italy, New Zealand, ...), especially when the target grid is a true subset of the original grid (a 0.5° x 0.5° grid should fit perfectly in a 1.5° x 2° grid).
Can anyone explain this or am I missing a critical point here? @mattiarighi @valeriupredoi @bouweandela @veyring
P.S. regridding with unmasked works totally fine.
 schlunma
schlunma
All 17 comments
hey Manuel man @schlunma this is a very good study - I am actually very keen on establishing what I call calibration errors i.e. perform a detailed study that gives us the errors from using method X with settings (Y, Z); this won't be easy to perform but will be very useful. Anyway, before I go too much down that rabbit hole - problem at hand is related to iris.cube.regrid and the regridding is done in $PYTHONENV/lib/python3.6/site-packages/iris/analysis/_regrid.py
The code is like this (in iris 1.13, lives at line 314 in _regrid.py):
for index in np.ndindex(tuple(iter_shape)):
index = list(index)
index[x_dim] = index[y_dim] = slice(None)
src_subset = src_data[tuple(index)]
interpolator.fill_value = mode.fill_value
data[tuple(index)] = interpolate(src_subset)
if isinstance(data, ma.MaskedArray) or mode.force_mask:
# NB. np.ma.getmaskarray returns an array of `False` if
# `src_subset` is not a masked array.
src_mask = np.ma.getmaskarray(src_subset)
interpolator.fill_value = mode.mask_fill_value
mask_fraction = interpolate(src_mask)
new_mask = (mask_fraction > 0)
if np.ma.isMaskedArray(data):
data.mask[tuple(index)] = new_mask
elif np.any(new_mask):
# Set mask=False to ensure we have an expanded mask array.
data = np.ma.MaskedArray(data, mask=False)
data.mask[tuple(index)] = new_mask
so the interpolation is done on slices and if the source data is masked then the interpolation is done separately for the mask of the slice -- my question is how accurate is this masked interpolation and could it be the root cause of such disappearances of large bodies of land? Two suggestions: one trivial: test with iris 2.0 and another not so trivial: try regridding coarser grids to smaller (but still coarser than your current target grid) and go down incrementally to see where you start missing large chunks of land.
I am afraid we need iris input here and I know just the guy: @bjlittle
 valeriupredoi
on 30 Aug 2018
valeriupredoi
on 30 Aug 2018
Tested iris 2.0, got the same results.
schlunma
on 30 Aug 2018
valeriupredoi
on 30 Aug 2018
wait - actually I have assumed you are masking with an fx file, is this a Natural Earth mask?
valeriupredoi
on 30 Aug 2018
Only for the observations CRU (which is alright, I think because the source is already on a very fine grid). The models (should) use fx files.
schlunma
on 30 Aug 2018
I found a solution for non-masked input files. If I regrid the dataset and the fx_file before masking and apply the mask after that, the results are totally fine. However, this is apparently not possible for already masked input data (e.g. land- or ocean-only variables).
It could work for those variables where we can define a "reasonable" fill value, for example for nbp (land-atmosphere carbon flux) it is reasonable to assume a flux of 0 at ocean grid points. In this case, we could remove the mask by settings those fill values to 0, regrid this file and apply the (regridded) mask after that.
Unfortunately, this is no general solution to this problem, but would it be possible to swap masking and regridding for unmasked input files?
schlunma
on 1 Oct 2018
@schlunma If you suspect this is a bug in iris, can you please check if it has been reported already on the iris issue tracker? If yes, please create a link in this issue so we can track progress. If no, please create an issue on the iris github page.
 bouweandela
on 2 Oct 2018
bouweandela
on 2 Oct 2018
Well, I don't think this is a bug of iris.
For (bi)linear regridding, the preprocessor needs the 4 closest grid points to calculate the new grid point. If at least one of them is a missing value, the new grid point is also set to a missing value (there is no other reasonable thing to do). Therefore, grid points close to the coast will be missing, which is a big problem for smaller islands or narrow peninsulas.
Thus, the only thing we can do is swapping the order of regridding and masking. As I already said, this is not suitable for already masked input files, for which it may be possible to define a "reasonable" fill value, unmask the file, perform the regridding and eventually mask the file again.
schlunma
on 2 Oct 2018
Thanks for clarifying that.
bouweandela
on 2 Oct 2018
Guys, this issue needs more investigation and a possible correction in the
interpolator - masking after regridding is not a sound operation because
the mask and the model hold the same information that is changed after
regridding, and applying a mask on it will result in systematic errors due
to the grid alteration - it becomes an apples on oranges situation
Dr Valeriu Predoi.
Computational scientist
NCAS-CMS
University of Reading
Department of Meteorology
Reading RG6 6BB
United Kingdom
On Tue, 2 Oct 2018, 10:50 Bouwe Andela, notifications@github.com wrote:
Thanks for clarifying that.
—
You are receiving this because you were assigned.
Reply to this email directly, view it on GitHub
https://github.com/ESMValGroup/ESMValTool/issues/593#issuecomment-426215377,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AbpCo1D5dvcfp4UYEiWCaMEbXO2aSeqKks5ugzb2gaJpZM4WTCW4
.
valeriupredoi
on 2 Oct 2018
@schlunma this is a rather serious problem - I have just run masking+regridding for a small region (Japan) and I do notice a significant bias when regridding on a masked map (see the attached pdf). Bottom line is that if we compare the map region with the same map region but regridded on an equivalent grid (so in effect, no actual grid alteration, but the interpolation was still applied), we notice an increase by 0.3 degrees of the mean temperature in the region and and increase by 13% of the masked pixels. Whereas this could be called calibration error (the interpolator is not ideal!) it is rather high!
ProblemsRegriddingWithMask.pdf
valeriupredoi
on 3 Oct 2018
ahaa! good news -- cube.regrid(tgt_cube, scheme=iris.analysis.Nearest(extrapolation='mask')) gives much more accurate results ie close to ideal: no regridding we have 134100 masked pixels, scheme=linear gives 164700, and __Nearest__ gives 129600 and the maps look almost identical. The mean temperatures still differ by 0.19 degrees but that's better than 0.3 as above - @schlunma could you maybe rerun your tests with this type of scheme? If you are happy(er) with the results I propose we use this type of scheme --
valeriupredoi
on 3 Oct 2018
I have actually realized that scheme: nearest is pointing to scheme=iris.analysis.Nearest(extrapolation='mask') as it is in _regrid.py so that should be the optimal horizontal regridding interpolation method, probably the best for masked data - @schlunma have you tested with it in your initial tests? Provided it's still crap, we may have to regrid the model and the mask and then apply the mask to the model as you well pointed out, but I fail to see why this order of operations would give less errors than model+mask than regrid -- the errors from regridding a masked dataset are dominated by the interpolation running on a mask, so whether you apply the mask first, then regrid or regrid a mask then apply it should introduce the same errors methinks
valeriupredoi
on 4 Oct 2018
Very interesting to hear V.! Unfortunately I will not be able to test this until Monday in two weeks, I'll keep you updated.
Well, the order does matter if the mask file is not masked itself (like sftlf) but only tells you where to mask (e.g. mask all values with stflf > 50%). In this case, masking after regridding is way better than the other way round, because the problem only occurs if the regridder has to deal with missing values, which sftlf does not have.
schlunma
on 4 Oct 2018
ah how silly of me, true that - I forgot that that mask is not actually a boolean mask but rather floats! correct, in that case, it really does and the issue is the missing values or better said how the interpolator makes its way through them. let's see if you get (hopefully much) better results with nearest as my tests show (hopefully Japan is not pulling a trick on me :grin: )
valeriupredoi
on 4 Oct 2018
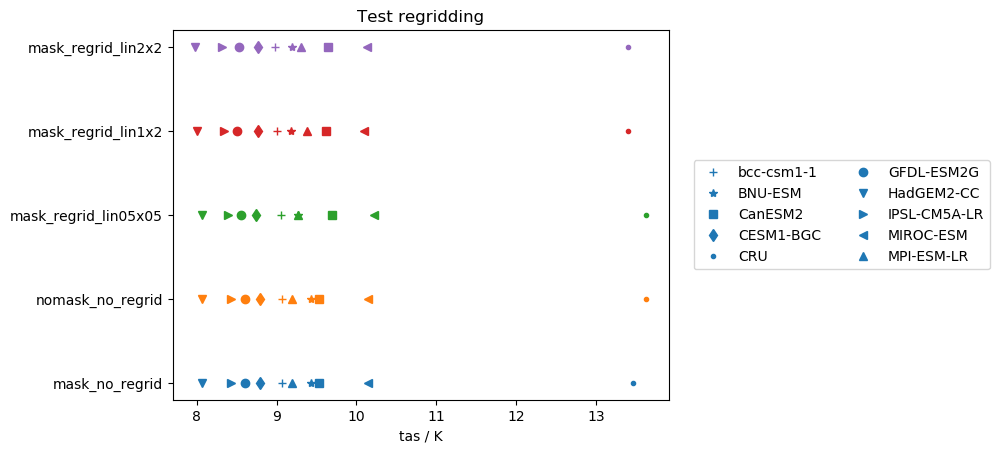
I was finally able to test some stuff. Here are some of my findings for the global mean values of several models/observations (notes: CRU is already masked, near: nearest scheme, lin: linear scheme, aw: area_weighted scheme, mask: ocean masked out):
nearestscheme:
Works really good for unmasked files (except for GFDL-ESM2G...maybe this model has a very specific grid?) and for several masked datasets (some models show small biases).linearscheme:
Performs good for mean values on unmasked data independently of the target grid. However, performs very poorly on masked files (but again not dependent on model/target grid).area_weightedscheme:
Very similar tolinearscheme, but performance on masked files is highly dependent on the target grid.
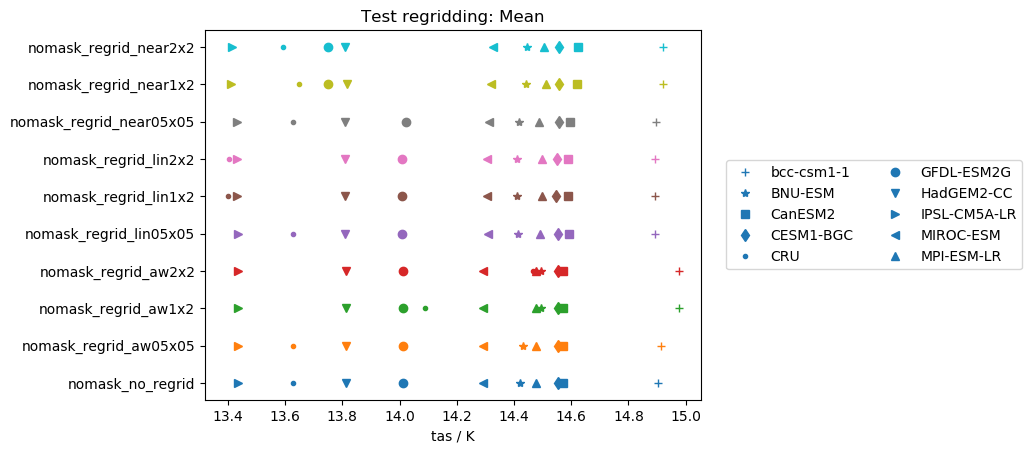
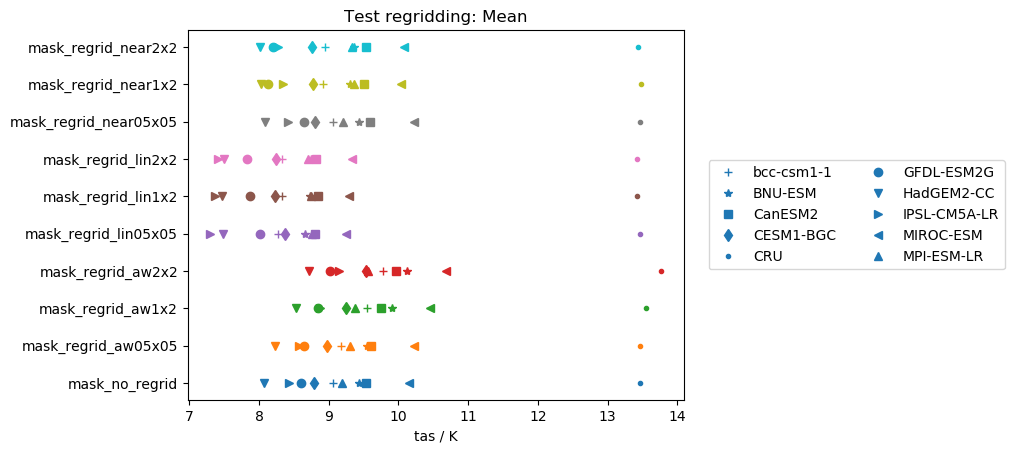
I also performed the same tests on the standard deviations instead of the mean. In this case
This quantity is not conserved by any regridding scheme and highly dependent on the individual model and target grid.
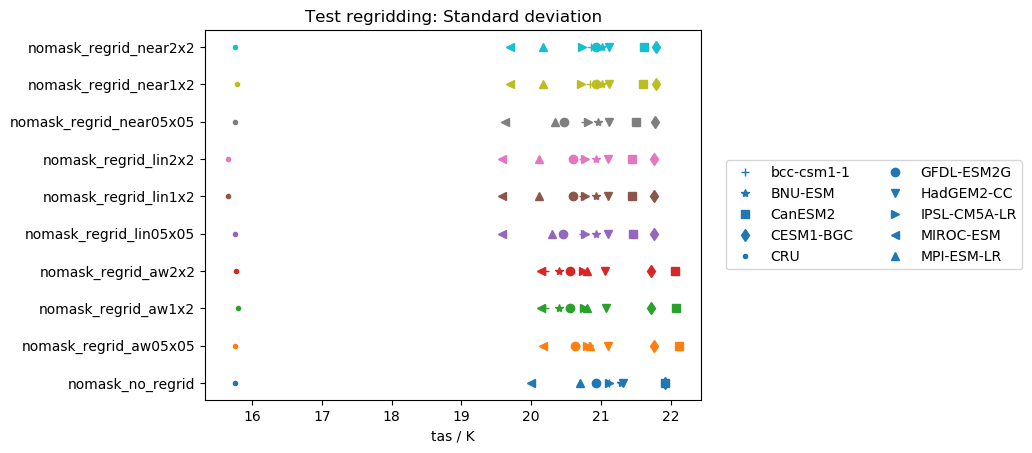
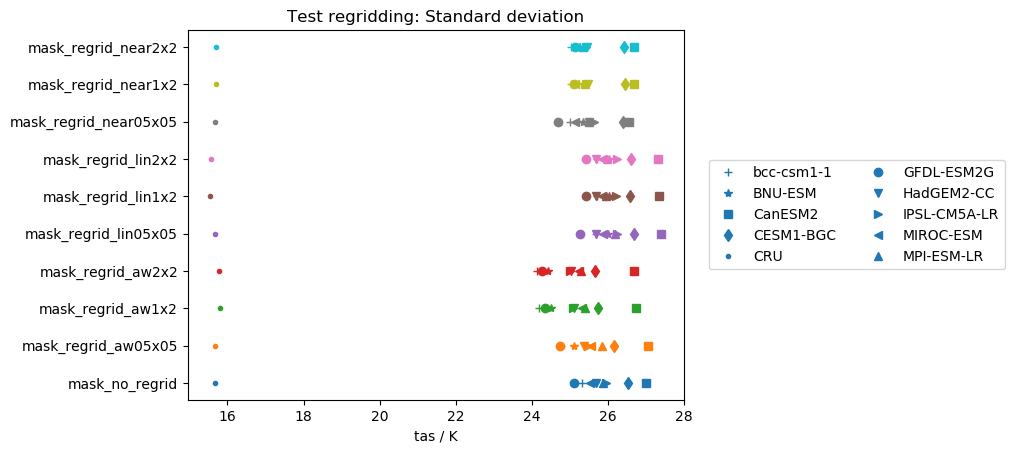
My summary is:
- For the mean of unmasked files, the three schemes perform equally well (except for GFDL-ESM2G in the
nearestscheme. - For the mean of masked files,
nearestis the scheme to go (except for the GFDL-ESM2G issues again). - Standard deviations are not preserved by regridding. It would be really interesting to test this with more statistical measures.
schlunma
on 15 Oct 2018
I suggest to close this: these are intrinsic problems of the regridding procedures and not related to the specific ESMValTool implementation.
Using cdo or any other package you would probably get to the same conclusions, as the algorithms behind them are basically the same.
We have added a comment in the paper that summarize the discussion.
 mattiarighi
on 11 Jun 2019
mattiarighi
on 11 Jun 2019
Related issues
 francesco-cmcc
·
4Comments
bouweandela
·
4Comments
bouweandela
·
3Comments
francesco-cmcc
·
4Comments
bouweandela
·
4Comments
bouweandela
·
3Comments
 jvegasbsc
·
4Comments
jvegasbsc
·
4Comments
 BenMGeo
·
5Comments
BenMGeo
·
5Comments