Celery: AttributeError 'list' object has no attribute 'decode' with redis backend
Checklist
- [X] I have included the output of
celery -A proj reportin the issue.
software -> celery:4.1.0 (latentcall) kombu:4.1.0 py:3.5.2
billiard:3.5.0.3 redis:2.10.5
platform -> system:Linux arch:64bit, ELF imp:CPython
loader -> celery.loaders.app.AppLoader
settings -> transport:redis results:redis://:**@****************
task_ignore_result: True
accept_content: {'pickle'}
result_serializer: 'pickle'
result_backend: 'redis://:********@************************'
task_serializer: 'pickle'
task_send_sent_event: True
broker_url: 'redis://:********@************************'
redis-server version, both 2.x and 3.x
Steps to reproduce
Hello, i'm not sure what can cause the problems and already tried to find a simillar solution, but no luck so far. Therefore opening issue here, hopefully it helps
The issue is described there as well (not by me): https://github.com/andymccurdy/redis-py/issues/612
So far the experience is, its happen in both cases, where backend is and isn't involved (means just when calling apply_async(...))
Exception when calling apply_async()

Exception when calling .get() (also this one has int, instead of list)

Hope it helps
Expected behavior
To not throw the error.
Actual behavior
AttributeError: 'list' object has no attribute 'decode'
Thanks!
 Twista
Twista
All 55 comments
Also, there is a full stack trace, which includes all the parameters

Twista
on 3 Nov 2017
This seems like a race condition in the Redis connection pool from concurrent worker operations. Which worker pool type are you using? I think that if you use the prefork pool you will not run into this issue. Let me know what the outcome is, if you try it.
 georgepsarakis
on 4 Nov 2017
georgepsarakis
on 4 Nov 2017
Hey @georgepsarakis,
thanks for your response, apparently it seems we are running on prefork
when checked output when starting celery (which runs under systemd) i got this output:
-------------- celery@autoscaled-dashboard-worker v4.1.0 (latentcall)
---- **** -----
--- * *** * -- Linux-4.4.0-45-generic-x86_64-with-Ubuntu-16.04-xenial 2017-11-04 20:41:15
-- * - **** ---
- ** ---------- [config]
- ** ---------- .> app: worker:0x7f984dbcce48
- ** ---------- .> transport: redis://:**@**
- ** ---------- .> results: redis://:**@**
- *** --- * --- .> concurrency: {min=3, max=12} (prefork)
-- ******* ---- .> task events: ON
some other info:
- our workers are on different machines then app (which dispatches tasks)
- have 2+ workers all the time (all with same settings below)
- all of them running under systemd (
celery multi start -A ... -E --autoscale=12,3 -Ofair+ some other not so important agruments, all specified asType=forkingservice)
let me know if i can add anything else, would like to help as much as possible to resolve that :)
thanks!
Twista
on 4 Nov 2017
another thing (even thoung i'm not sure if it could be related) - sometimes we get this exception (same setup as above)
File "/usr/local/lib/python3.5/dist-packages/celery/app/base.py", line 737, in send_task
amqp.send_task_message(P, name, message, **options)
File "/usr/lib/python3.5/contextlib.py", line 77, in __exit__
self.gen.throw(type, value, traceback)
File "/usr/local/lib/python3.5/dist-packages/kombu/connection.py", line 419, in _reraise_as_library_errors
sys.exc_info()[2])
File "/usr/local/lib/python3.5/dist-packages/vine/five.py", line 178, in reraise
raise value.with_traceback(tb)
File "/usr/local/lib/python3.5/dist-packages/kombu/connection.py", line 414, in _reraise_as_library_errors
yield
File "/usr/local/lib/python3.5/dist-packages/celery/app/base.py", line 736, in send_task
self.backend.on_task_call(P, task_id)
File "/usr/local/lib/python3.5/dist-packages/celery/backends/redis.py", line 189, in on_task_call
self.result_consumer.consume_from(task_id)
File "/usr/local/lib/python3.5/dist-packages/celery/backends/redis.py", line 76, in consume_from
self._consume_from(task_id)
File "/usr/local/lib/python3.5/dist-packages/celery/backends/redis.py", line 82, in _consume_from
self._pubsub.subscribe(key)
File "/usr/local/lib/python3.5/dist-packages/redis/client.py", line 2482, in subscribe
ret_val = self.execute_command('SUBSCRIBE', *iterkeys(new_channels))
File "/usr/local/lib/python3.5/dist-packages/redis/client.py", line 2404, in execute_command
self._execute(connection, connection.send_command, *args)
File "/usr/local/lib/python3.5/dist-packages/redis/client.py", line 2408, in _execute
return command(*args)
File "/usr/local/lib/python3.5/dist-packages/redis/connection.py", line 610, in send_command
self.send_packed_command(self.pack_command(*args))
File "/usr/local/lib/python3.5/dist-packages/redis/connection.py", line 585, in send_packed_command
self.connect()
File "/usr/local/lib/python3.5/dist-packages/redis/connection.py", line 493, in connect
self.on_connect()
File "/usr/local/lib/python3.5/dist-packages/redis/connection.py", line 567, in on_connect
if nativestr(self.read_response()) != 'OK':
File "/usr/local/lib/python3.5/dist-packages/redis/connection.py", line 629, in read_response
raise response
kombu.exceptions.OperationalError: only (P)SUBSCRIBE / (P)UNSUBSCRIBE / PING / QUIT allowed in this context
we tried to update py-redis (will see, but its just minor one)
any hint is very appreciate :)
Twista
on 8 Nov 2017
@Twista can you try a patch on the Redis backend?
If you can add here the following code:
def on_after_fork(self):
logger.info('Resetting Redis client.')
del self.backend.client
I hope that this will force the client cached property to generate a new Redis client after each worker fork.
Let me know if this has any result.
georgepsarakis
on 11 Nov 2017
Hey, sorry for long response.
Just a followup - we just patched it and will see if it helps. Hopefully soon :)
thanks for help :)
Twista
on 5 Dec 2017
lets us know your feedback
 auvipy
on 21 Dec 2017
auvipy
on 21 Dec 2017
Hi,
I'm experiencing pretty the same issue (using Celery.send_task) and have a related question:
Why, when calling an async task (so the result is not expected), Celery starts to listen a redis publisher (self._pubsub.subscribe(key) called by a signal handler celery/backends/redis.py, line 189, in on_task_call)?
 tomaszhlawiczka
on 24 Dec 2017
tomaszhlawiczka
on 24 Dec 2017
@georgepsarakis unfortunately the patch didn't help. :-(
here is another stack trace:



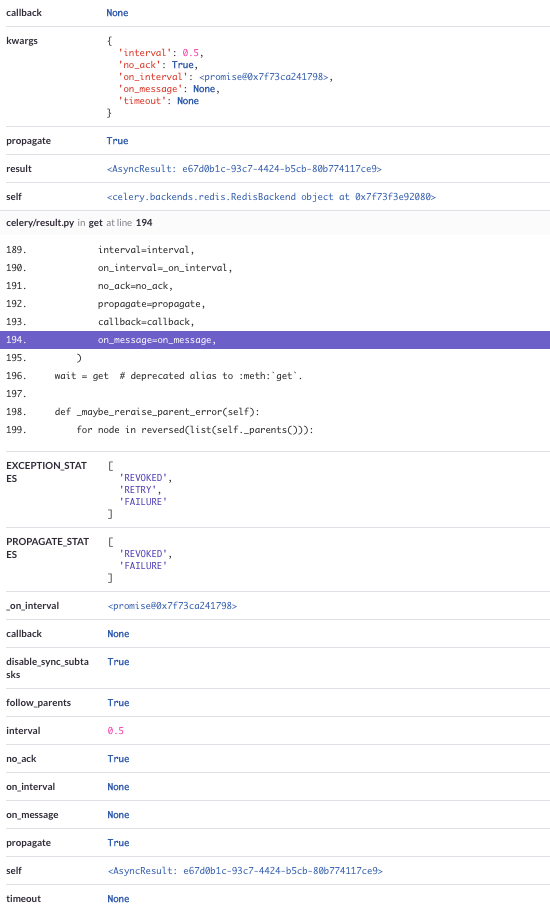
Please let me know if you want some logs or other patches tested.
 wimby
on 12 Mar 2018
wimby
on 12 Mar 2018
@wimby thanks a lot for the feedback. Can you please tell me what options are you using for starting the worker?
georgepsarakis
on 12 Mar 2018
Hey @georgepsarakis
Will answer this one instead of @wimby
that's whole command we use to start celery
celery multi start worker -A ... --pidfile=... --logfile=... --loglevel=... -E --time-limit=300 --autoscale=10,3 --queues=... -Ofair
faced with the same issue when decided to try redis broker, rolled back to rabbit for now..
 dmitry-kostin
on 5 Apr 2018
dmitry-kostin
on 5 Apr 2018
Any update on this? Running into this with a similar setup to @Twista / @wimby where we have cron workers running on a separate machine than the process that schedules our tasks.
celery==4.0.2
redis==2.10.5.
To clarify, this happens on the machine that is sending the tasks, not the worker machine.
 asgoel
on 11 May 2018
asgoel
on 11 May 2018
I'm seeing this as well. Celery 4.2.0, kombu 4.2.1, redis 2.10.6. Using redis for both the broker and the results. Redis traffic goes between servers over an encrypted stunnel connection over ports.
Running into it in a Django 1.11 running on mod_wsgi (2 processes, 15 threads each), and it's not just limited to the above exception. I can't copy-paste full stack traces. The application loads up a web page with a bunch of ajax requests (90ish per page load), each of which runs a background task via celery. The tasks complete successfully, but getting the results back is difficult.
When submitting the tasks, I've gotten ConnectionErrors, AttributeErrors (list has no attribute encode).
When getting the results back, I've gotten InvalidResponse, ResponseError, ValueError, AttributeError, TypeError, IndexError, pretty much all from redis. I've also seen decode errors from kombu when trying to parse the json responses. I suspect traffic is getting mixed up between the requests - in some cases I've seen what looks like partial responses.
I'm switching back to doing bulkier tasks, which should at least minimize this happening. However, I've seen cases where protocol issues will still happen when things have a minimal load. I wouldn't be surprised if this was being caused by underlying networking issues. I am dding additional retry logic as well for submitting requests.
 deterb
on 13 Jun 2018
deterb
on 13 Jun 2018
@deterb if you set task_ignore_result in your celery config, this should prevent this from happening. Unless you care about task results, in which case it obviously won't help.
The fix to respect ignore_result when scheduling tasks was made in 4.2.0, so you should be good.
asgoel
on 13 Jun 2018
@asgoel The whole point is to get the results for the bulk of the requests (it's not so much running in the background for them, but running heavy calculations on a server built for it instead of the web server). I will add the ignore result for the others though and see if that helps.
deterb
on 14 Jun 2018
@deterb this sounds like an issue with non thread-safe operations. Is it possible to try not to use multithreading?
georgepsarakis
on 14 Jun 2018
@georgepsarakis I agree that it sounds like a multithreading issue. I'll try configuring mod_wsgi to run with 15 processes, 1 thread per process and see if I still see that behavior. I'm not doing any additional threading or multiprocessing outside of mod_wsgi. I saw similar behavior (though with less frequency) running with Django's runserver. The only interfacing with redis clients in the web application is through Celery, namely the submitting of tasks and retrieval of their results. redis-py claims to be thread safe.
I'll try to do more testing tomorrow, and see if I can recreate outside of Django and without the stunnel proxy.
deterb
on 15 Jun 2018
@georgepsarakis I didn't get a chance to try today, but I believe #4670 (namely the shared PubSub objects not being thread safe) is related, along with #4480. It's likely what I'm seeing is separate from the original ticket and the other issues that were mentioned. While probably related to the issues @asgoel brought up, I think a separate ticket for concurrency issues with the redis result backend would be appropriate (keep #4480 related to the RPC result backend). I can start pulling out relevant parts of stack traces as well.
deterb
on 15 Jun 2018
Hey guys, I was facing this errors a lot.
I was using AWS Elasticache and my app was deployed in AWS Elastic Beanstalk.
We changed the AWS Elasticache to Redis Labs and we increased the timeout of AWS Elastic Load Balancer to 180s and the Apache server to 180s too.
The errors decreased a lot.
Nevertheless they were still ocurring from time to time. Therefore I decided to change the result backend to PostgreSQL and then the errors disappeared completely.
 christiansaiki
on 18 Jul 2018
christiansaiki
on 18 Jul 2018
An intersting thing: we started experiencing this issue right after deploying a new release that
- switched from python 2.7 to python 3.6
( and updated Django 1.11 (incremental. 13 to .14))
So, it's interesting to know this may be something that depends on the python version. Hoping it may help tracking the problem down.
(For the rest, we're using celery 4.2.1 and redis 2.10.6)
Also, the problematic task is launched by Celery beat, and we've had the same problem in a task launched by another task
 ewjoachim
on 9 Aug 2018
ewjoachim
on 9 Aug 2018
Thanks for the feedback everyone. Just to clarify a few things:
ResultConsumeris the Redis Backend component that asynchronously retrieves the resultResultConsumerinitializes aPubSubinstanceResultConsumerinstances can be created either on a worker (Canvas workflows) or when a Task is enqueued and results are not ignored- the same
PubSubinstance cannot be used simultaneously from multiple threads - as far as Workers are concerned, this change should cover the case of starting new forks
I am not aware if the corresponding operations can be performed upon Django startup, perhaps this callback could help; calling ResultConsumer.on_after_fork would then create new instances and the issue will most probably not occur.
georgepsarakis
on 9 Aug 2018
Hmm.
In my case, I've tried reproducing the problem by increasing the frequency on a task in Celery Beat. I currently have something like 1 failure every 15 tasks, but the fail occurs in the worker, not in Beat, and my worker has a concurrency of 1 (I have several independent process, but they are all "single"). htop tells me that there's a main process with a single child thread. Would that be consistent with your hypothesis ?
ewjoachim
on 9 Aug 2018
If I understand correctly your answer (I'm rereading it, just to be sure), the paragraph:
I am not aware if the corresponding operations can be performed upon Django startup, perhaps this callback could help; calling ResultConsumer.on_after_fork would then create new instances and the issue will most probably not occur.
this would be related to a case where we would have errors when publishing the tasks from our web processes (gunicorn/uwsgi/...), right ?
as far as Workers are concerned, this change should cover the case of starting new forks
In our cases, those errors are coming from workers exclusively with Celery 4.2.1. If I'm understanding your statement correctly, then, maybe there's still a problem there...
ewjoachim
on 9 Aug 2018
On Celery 4.2.0, I was able to work around this issue by doing the following:
- Patch celery.backends.redis.ResultConsumer to either store _pubsub and subscribed in a thread.local or to add thread.local to the list of inherited classes.
- After calling the task and processing the results, call:
result.backend.result_consumer.cancel_for(result.task_id)
result.backend.result_consumer.stop()
I haven't figured out how to remove the call to stop; if I remove it connections start leaking (note I'm running in a mod_wsgi environment connecting to redis over stunnel; end up getting connection issues after a few hundred requests). After a while I stop being able to connect through the tunnel. I haven't figured out to hook into mod_wsgi's thread management either.
The test case I'm using has a web page which makes ~1500 Ajax requests 5 at a time running entirely in Django's run_server command. Without the rate limiting, the race conditions on the result backend pubsub objects occur constantly. They occur regularly with the rate limiting as well.
I suspect using thread local ResultConsumers for redis could help with the Greenlet worker issues as well, though I'm not sure how one would go about reliably closing the pubsubs.
deterb
on 20 Aug 2018
Switching RedisBackend to using polling for the web application works without application specific changes. I swapped the async backend mixin with base.SyncBackendMixin and commented out the lines referencing the result consumer. Until a cleaner solution is fixed, I'll probably switch the web application to use the SyncBackend version of the RedisBackend and let the workers use the normal one (which appears to not have this issue.
deterb
on 20 Aug 2018
Given I'm using Django, my workaround has been to use django-celery-results. It's kind of more in line with other design decisions to use redis less, and we're really not storing a lot anyway. We haven't put that in production yet.
ewjoachim
on 21 Aug 2018
The results are heavy and transitive enough I don't want to put them in the database. As a more conservative option, I may just directly store the results rather than let Celery do so until this is fixed (I'm already using Redis for some caching).
deterb
on 21 Aug 2018
I'm having a similar issue to this. I hope the additional information I'm providing can shed some more light onto the problem.
I have a single celery worker (concurrency=1) and a server that pushes tasks onto the queue and retrieves the results. I'm using rabbitmq as the broker and redis for the result backend.
I'm using celery 4.2.1 & hiredis 0.2.0 (the problem occurs without hiredis as well).
Calling the service at a slower rate works as intended, but once I'm sending ~100 concurrent requests, I begin to see the problems that have been described in this issue. I have a couple different exceptions, which I believe are all related.
File "/___/___/celery_app.py", line 101, in send_task
task_result.wait(timeout=timeout, propagate=True)
File "/usr/lib/python3.6/site-packages/celery/result.py", line 224, in get
on_message=on_message,
File "/usr/lib/python3.6/site-packages/celery/backends/async.py", line 188, in wait_for_pending
for _ in self._wait_for_pending(result, **kwargs):
File "/usr/lib/python3.6/site-packages/celery/backends/async.py", line 255, in _wait_for_pending
on_interval=on_interval):
File "/usr/lib/python3.6/site-packages/celery/backends/async.py", line 56, in drain_events_until
yield self.wait_for(p, wait, timeout=1)
File "/usr/lib/python3.6/site-packages/celery/backends/async.py", line 65, in wait_for
wait(timeout=timeout)
File "/usr/lib/python3.6/site-packages/celery/backends/redis.py", line 119, in drain_events
m = self._pubsub.get_message(timeout=timeout)
File "/usr/lib/python3.6/site-packages/redis/client.py", line 2260, in get_message
response = self.parse_response(block=False, timeout=timeout)
File "/usr/lib/python3.6/site-packages/redis/client.py", line 2183, in parse_response
return self._execute(connection, connection.read_response)
File "/usr/lib/python3.6/site-packages/redis/client.py", line 2176, in _execute
return command(*args)
File "/usr/lib/python3.6/site-packages/redis/connection.py", line 579, in read_response
self.disconnect()
File "/usr/lib/python3.6/site-packages/redis/connection.py", line 530, in disconnect
self._sock.close()
AttributeError: 'NoneType' object has no attribute 'close'
And
Traceback (most recent call last):
File "/usr/lib/python3.6/site-packages/redis/connection.py", line 344, in read_response
bufflen = self._sock.recv_into(self._buffer)
OSError: [Errno 9] Bad file descriptor
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/lib/python3.6/site-packages/redis/client.py", line 2165, in _execute
return command(*args)
File "/usr/lib/python3.6/site-packages/redis/connection.py", line 577, in read_response
response = self._parser.read_response()
File "/usr/lib/python3.6/site-packages/redis/connection.py", line 357, in read_response
(e.args,))
redis.exceptions.ConnectionError: Error while reading from socket: (9, 'Bad file descriptor')
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/lib/python3.6/site-packages/redis/connection.py", line 577, in read_response
response = self._parser.read_response()
File "/usr/lib/python3.6/site-packages/redis/connection.py", line 362, in read_response
response = self._reader.gets()
redis.exceptions.InvalidResponse: Protocol error, got "t" as reply type byte
And
File "/usr/lib/python3.6/site-packages/celery/result.py", line 224, in get
on_message=on_message,
File "/usr/lib/python3.6/site-packages/celery/backends/async.py", line 188, in wait_for_pending
for _ in self._wait_for_pending(result, **kwargs):
File "/usr/lib/python3.6/site-packages/celery/backends/async.py", line 255, in _wait_for_pending
on_interval=on_interval):
File "/usr/lib/python3.6/site-packages/celery/backends/async.py", line 56, in drain_events_until
yield self.wait_for(p, wait, timeout=1)
File "/usr/lib/python3.6/site-packages/celery/backends/async.py", line 65, in wait_for
wait(timeout=timeout)
File "/usr/lib/python3.6/site-packages/celery/backends/redis.py", line 119, in drain_events
m = self._pubsub.get_message(timeout=timeout)
File "/usr/lib/python3.6/site-packages/redis/client.py", line 2260, in get_message
response = self.parse_response(block=False, timeout=timeout)
File "/usr/lib/python3.6/site-packages/redis/client.py", line 2183, in parse_response
return self._execute(connection, connection.read_response)
File "/usr/lib/python3.6/site-packages/redis/client.py", line 2176, in _execute
return command(*args)
File "/usr/lib/python3.6/site-packages/redis/connection.py", line 577, in read_response
response = self._parser.read_response()
File "/usr/lib/python3.6/site-packages/redis/connection.py", line 359, in read_response
self._reader.feed(self._buffer, 0, bufflen)
AttributeError: 'NoneType' object has no attribute 'feed'
From the celery worker's perspective, all these tasks were successful and no exceptions were sent back. I receive these exceptions from the Python process that is trying to retrieve the task results.
Has there been any update on this issue, or possible work around solutions I should try not listed in this issue?
 sihrc
on 18 Oct 2018
sihrc
on 18 Oct 2018
Are you running with multiple threads? If so, you match up somewhat with the Django setup I mentioned earlier. If not, it may be something else.
My current workaround is to never actually use the result objects coming back and instead push and pull the results directly into/from Redis data structures. Since the web request is blocking on the results, I'll generally pass in a result "list" for the task to put responses into and push into that list in the web request. I'll use redis's blpop to get the results back until I have them all or time out on the last one. I use the ignore results flag when submitting the task to prevent the listening channel from being created, and will still keep the original tasks around for logging the ids and potentially getting the state back later.
I didn't feel comfortable running with the patch I mentioned earlier; I needed something which I knew wouldn't have the potential side effects.
deterb
on 19 Oct 2018
@deterb Thanks for the response.
I do run with multiple threads, so I believe it is very similar to what you are seeing. I could potentially do something similar with an additional thread essentially polling redis for results, but I'd really like to get to the bottom of this as well.
I went ahead and put together a few docker containers to reproduce the bug with a fairly simple setup
https://github.com/sihrc/celery_repro. I'll continue to look into it myself through this repo, but so far I've come up with nothing. It'll take me a bit to get up to speed with the intricacies of celery and redis.
Traceback (most recent call last):
File "/usr/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/usr/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/app/celery_race_condition/app.py", line 21, in <module>
results = [result.result() for result in futures]
File "/app/celery_race_condition/app.py", line 21, in <listcomp>
results = [result.result() for result in futures]
File "/usr/lib/python3.6/concurrent/futures/_base.py", line 432, in result
return self.__get_result()
File "/usr/lib/python3.6/concurrent/futures/_base.py", line 384, in __get_result
raise self._exception
File "/usr/lib/python3.6/concurrent/futures/thread.py", line 56, in run
result = self.fn(*self.args, **self.kwargs)
File "/app/celery_race_condition/app.py", line 11, in call_and_retrieve
async_result.wait(timeout=100, propagate=True)
File "/usr/lib/python3.6/site-packages/celery/result.py", line 224, in get
on_message=on_message,
File "/usr/lib/python3.6/site-packages/celery/backends/async.py", line 188, in wait_for_pending
for _ in self._wait_for_pending(result, **kwargs):
File "/usr/lib/python3.6/site-packages/celery/backends/async.py", line 255, in _wait_for_pending
on_interval=on_interval):
File "/usr/lib/python3.6/site-packages/celery/backends/async.py", line 56, in drain_events_until
yield self.wait_for(p, wait, timeout=1)
File "/usr/lib/python3.6/site-packages/celery/backends/async.py", line 65, in wait_for
wait(timeout=timeout)
File "/usr/lib/python3.6/site-packages/celery/backends/redis.py", line 119, in drain_events
m = self._pubsub.get_message(timeout=timeout)
File "/usr/lib/python3.6/site-packages/redis/client.py", line 2513, in get_message
response = self.parse_response(block=False, timeout=timeout)
File "/usr/lib/python3.6/site-packages/redis/client.py", line 2428, in parse_response
if not block and not connection.can_read(timeout=timeout):
File "/usr/lib/python3.6/site-packages/redis/connection.py", line 618, in can_read
return self._parser.can_read() or \
File "/usr/lib/python3.6/site-packages/redis/connection.py", line 372, in can_read
self._next_response = self._reader.gets()
redis.exceptions.InvalidResponse: Protocol error, got "\r" as reply type byte
I've been debugging since and I've found that as soon as a thread that has been used before is used again to retrieve a result, we start to get errors. I tested this by created a thread pool of 100 and running 101 tasks at the same time.
For me it has boiled down to thread safety of the ResultConsumer and possibly redis' PubSub client. My current workaround is using a separate ResultConsumer per thread's local context.
import threading
from celery.backends.redis import RedisBackend
local_context = threading.local()
class Backend(RedisBackend):
@property
def result_consumer(self):
consumer = getattr(local_context, "consumer", None)
if consumer:
return consumer
local_context.consumer = self.ResultConsumer(
self, self.app, self.accept,
self._pending_results, self._pending_messages,
)
return local_context.consumer
@result_consumer.setter
def result_consumer(self, value):
local_context.consumer = value
Celery(
...,
result_backend=__name__ + ".Backend",
...
)
Unfortunately, I couldn't dig in enough to figure out why this is a problem to begin with, but hopefully, this workaround is useful for someone else.
sihrc
on 19 Oct 2018
Celery is fairly aggressive about registering channels in the PubSub interface, which redis-py's documentation states is not thread safe. I think we're seeing different threads pick up different parts of the responses.
The solution you posted has the same theme as what I did, though it looks cleaner.
deterb
on 20 Oct 2018
@sihrc @deterb I think you are on the right track, this can be attributed to the PubSub client not being thread-safe. @sihrc using thread locals for this purpose seems correct to me, have you perhaps considered/tried transferring the logic to the ResultConsumer and the PubSub client instance? Either way if you could just provide a PR with this solution it would be great!
georgepsarakis
on 24 Oct 2018
@georgepsarakis I've attempted to move the logic into the ResultConsumer and thrown it up on a PR. Total disclaimer: I'm uncertain if I have the time to actively push this PR through in a timely manner, but I'll do my best.
sihrc
on 24 Oct 2018
@sihrc thank you! That is perfectly understandable, just let us know if you cannot dedicate more time at any point forward.
georgepsarakis
on 28 Oct 2018
It looks like the PR for the solution is inactive. Is there any intention of fixing this issue?
 jakeatallyo
on 23 Mar 2019
jakeatallyo
on 23 Mar 2019
Probably after the release.
 thedrow
on 24 Mar 2019
thedrow
on 24 Mar 2019
@thedrow Thanks for the quick response. Are you saying once 4.3 is released (hopefully not 5.0), contributors will turn their attention to this bug?
jakeatallyo
on 25 Mar 2019
Yes.
thedrow
on 26 Mar 2019
We also have seen this on the 4.2 version recently in the past month.
 jheld
on 3 Apr 2019
jheld
on 3 Apr 2019
@thedrow do you have a rough estimate on the timeline for the 4.3 release?
 ghost
on 10 Jul 2019
ghost
on 10 Jul 2019
4.3 is released back in March. also, 4.4rc2 is on pypi and 4.4 will be released on this week.
auvipy
on 11 Jul 2019
@auvipy oh great, thank you. Is this issue currently being addressed then?
ghost
on 11 Jul 2019
not sure but it is planned for 4.5.
auvipy
on 11 Jul 2019
FWIW, even with the code snippet above, we still see periodic Protocol Errors, though less frequently:
Traceback (most recent call last):
File "/opt/python/current/app/app/XXXX", line #, in _check_celery
result = async_result.get(timeout=self.service_timeout)
File "/opt/python/run/venv/local/lib/python3.6/site-packages/celery/result.py", line 226, in get
on_message=on_message,
File "/opt/python/run/venv/local/lib/python3.6/site-packages/celery/backends/asynchronous.py", line 188, in wait_for_pending
for _ in self._wait_for_pending(result, **kwargs):
File "/opt/python/run/venv/local/lib/python3.6/site-packages/celery/backends/asynchronous.py", line 255, in _wait_for_pending
on_interval=on_interval):
File "/opt/python/run/venv/local/lib/python3.6/site-packages/celery/backends/asynchronous.py", line 56, in drain_events_until
yield self.wait_for(p, wait, timeout=1)
File "/opt/python/run/venv/local/lib/python3.6/site-packages/celery/backends/asynchronous.py", line 65, in wait_for
wait(timeout=timeout)
File "/opt/python/run/venv/local/lib/python3.6/site-packages/celery/backends/redis.py", line 127, in drain_events
message = self._pubsub.get_message(timeout=timeout)
File "/opt/python/run/venv/local/lib/python3.6/site-packages/redis/client.py", line 3297, in get_message
response = self.parse_response(block=False, timeout=timeout)
File "/opt/python/run/venv/local/lib/python3.6/site-packages/redis/client.py", line 3185, in parse_response
response = self._execute(conn, conn.read_response)
File "/opt/python/run/venv/local/lib/python3.6/site-packages/redis/client.py", line 3159, in _execute
return command(*args, **kwargs)
File "/opt/python/run/venv/local/lib/python3.6/site-packages/redis/connection.py", line 700, in read_response
response = self._parser.read_response()
File "/opt/python/run/venv/local/lib/python3.6/site-packages/redis/connection.py", line 318, in read_response
(str(byte), str(response)))
redis.exceptions.InvalidResponse: Protocol Error: , b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00*3'
The all-zeros response is the most common one, though I just saw a ProtocolError: 1, b'575932362]' go by.
I don't discount the possibility that this could also just be a glitch in Redis and nothing to do with Celery though. It's kind of hard to tell.
This is using Celery 4.3.0, Kombu 4.6.6, and Redis 3.3.11
 nicklyra
on 10 Dec 2019
nicklyra
on 10 Dec 2019
I have started getting this error frequently after implementing an async call. A flask app calls to celery. It works some times and then others I get the x00 result:
web_1 | Traceback (most recent call last):
web_1 | File "/root/.local/share/virtualenvs/app-lp47FrbD/lib/python3.7/site-packages/flask/app.py", line 2463, in __call__
web_1 | return self.wsgi_app(environ, start_response)
web_1 | File "/root/.local/share/virtualenvs/app-lp47FrbD/lib/python3.7/site-packages/flask/app.py", line 2449, in wsgi_app
web_1 | response = self.handle_exception(e)
web_1 | File "/root/.local/share/virtualenvs/app-lp47FrbD/lib/python3.7/site-packages/flask/app.py", line 1866, in handle_exception
web_1 | reraise(exc_type, exc_value, tb)
web_1 | File "/root/.local/share/virtualenvs/app-lp47FrbD/lib/python3.7/site-packages/flask/_compat.py", line 39, in reraise
web_1 | raise value
web_1 | File "/root/.local/share/virtualenvs/app-lp47FrbD/lib/python3.7/site-packages/flask/app.py", line 2446, in wsgi_app
web_1 | response = self.full_dispatch_request()
web_1 | File "/root/.local/share/virtualenvs/app-lp47FrbD/lib/python3.7/site-packages/flask/app.py", line 1951, in full_dispatch_request
web_1 | rv = self.handle_user_exception(e)
web_1 | File "/root/.local/share/virtualenvs/app-lp47FrbD/lib/python3.7/site-packages/flask/app.py", line 1820, in handle_user_exception
web_1 | reraise(exc_type, exc_value, tb)
web_1 | File "/root/.local/share/virtualenvs/app-lp47FrbD/lib/python3.7/site-packages/flask/_compat.py", line 39, in reraise
web_1 | raise value
web_1 | File "/root/.local/share/virtualenvs/app-lp47FrbD/lib/python3.7/site-packages/flask/app.py", line 1949, in full_dispatch_request
web_1 | rv = self.dispatch_request()
web_1 | File "/root/.local/share/virtualenvs/app-lp47FrbD/lib/python3.7/site-packages/flask/app.py", line 1935, in dispatch_request
web_1 | return self.view_functions[rule.endpoint](**req.view_args)
web_1 | File "/usr/src/app/web.py", line 81, in balances
web_1 | result = group(balance.s(name) for name in factories.LAZY_STRATEGY_MAP.keys())().get()
web_1 | File "/root/.local/share/virtualenvs/app-lp47FrbD/lib/python3.7/site-packages/celery/result.py", line 703, in get
web_1 | on_interval=on_interval,
web_1 | File "/root/.local/share/virtualenvs/app-lp47FrbD/lib/python3.7/site-packages/celery/result.py", line 822, in join_native
web_1 | on_message, on_interval):
web_1 | File "/root/.local/share/virtualenvs/app-lp47FrbD/lib/python3.7/site-packages/celery/backends/asynchronous.py", line 151, in iter_native
web_1 | for _ in self._wait_for_pending(result, no_ack=no_ack, **kwargs):
web_1 | File "/root/.local/share/virtualenvs/app-lp47FrbD/lib/python3.7/site-packages/celery/backends/asynchronous.py", line 268, in _wait_for_pending
web_1 | on_interval=on_interval):
web_1 | File "/root/.local/share/virtualenvs/app-lp47FrbD/lib/python3.7/site-packages/celery/backends/asynchronous.py", line 55, in drain_events_until
web_1 | yield self.wait_for(p, wait, timeout=interval)
web_1 | File "/root/.local/share/virtualenvs/app-lp47FrbD/lib/python3.7/site-packages/celery/backends/asynchronous.py", line 64, in wait_for
web_1 | wait(timeout=timeout)
web_1 | File "/root/.local/share/virtualenvs/app-lp47FrbD/lib/python3.7/site-packages/celery/backends/redis.py", line 161, in drain_events
web_1 | message = self._pubsub.get_message(timeout=timeout)
web_1 | File "/root/.local/share/virtualenvs/app-lp47FrbD/lib/python3.7/site-packages/redis/client.py", line 3565, in get_message
web_1 | response = self.parse_response(block=False, timeout=timeout)
web_1 | File "/root/.local/share/virtualenvs/app-lp47FrbD/lib/python3.7/site-packages/redis/client.py", line 3453, in parse_response
web_1 | response = self._execute(conn, conn.read_response)
web_1 | File "/root/.local/share/virtualenvs/app-lp47FrbD/lib/python3.7/site-packages/redis/client.py", line 3427, in _execute
web_1 | return command(*args, **kwargs)
web_1 | File "/root/.local/share/virtualenvs/app-lp47FrbD/lib/python3.7/site-packages/redis/connection.py", line 734, in read_response
web_1 | response = self._parser.read_response()
web_1 | File "/root/.local/share/virtualenvs/app-lp47FrbD/lib/python3.7/site-packages/redis/connection.py", line 324, in read_response
web_1 | (str(byte), str(response)))
web_1 | redis.exceptions.InvalidResponse: Protocol Error: , b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00*3'
More weird errors:
web_1 | redis.exceptions.InvalidResponse: Protocol Error: s, b'ubscribe'
And:
web_1 | File "/root/.local/share/virtualenvs/app-lp47FrbD/lib/python3.7/site-packages/redis/connection.py", line 350, in read_response
web_1 | response = self._buffer.read(length)
web_1 | AttributeError: 'NoneType' object has no attribute 'read'
Python 3.7, Celery 4.4.1, Redis 3.4.1.
 jmoz
on 13 Mar 2020
jmoz
on 13 Mar 2020
could any of you try this patch https://github.com/celery/celery/pull/5145?
auvipy
on 18 Mar 2020
could any of you try this patch #5145?
I wouldn't mind trying it, but I note there's a great deal of contention on the approach in that patch, builds with that patch are failing, and it's been sitting there for 17 months. It kind of looks like the idea has been abandoned.
nicklyra
on 18 Mar 2020
give it a try first and don't' mind review the PR and prepare a failing test for it.
auvipy
on 18 Mar 2020
FWIW, confirmed today this is still an issue with Celery 4.4.2, Kombu 4.6.8, Redis 3.4.1.
nicklyra
on 19 Mar 2020
Considering how old of an issue this is, is there any hint of what causes it? I don't think my project has seen it [much] recently, but nonetheless, at least a couple projects continue to see this bug occur.
jheld
on 4 Apr 2020
@jheld Comments from https://github.com/celery/celery/issues/4363#issuecomment-411708951 fit with what I saw last time I poked at it - namely the result consumer initializes a PubSub which ends up getting shared across threads and that PubSubs are not thread safe. My workaround was ignoring the results and saving/watching the results independently from my Django app.
Thanks for the feedback everyone. Just to clarify a few things:
ResultConsumeris the Redis Backend component that asynchronously retrieves the resultResultConsumerinitializes aPubSubinstanceResultConsumerinstances can be created either on a worker (Canvas workflows) or when a Task is enqueued and results are not ignored- the same
PubSubinstance cannot be used simultaneously from multiple threads- as far as Workers are concerned, this change should cover the case of starting new forks
I am not aware if the corresponding operations can be performed upon Django startup, perhaps this callback could help; calling
ResultConsumer.on_after_forkwould then create new instances and the issue will most probably not occur.
deterb
on 5 Apr 2020
Earlier in the issue, somebody mentioned this started happening after they upgraded Django:
and updated Django 1.11 (incremental. 13 to .14))
We just upgraded from 1.11 to 2.2, and we're started seeing it. I can't imagine why, but thought I'd echo the above.
 mlissner
on 2 Mar 2021
mlissner
on 2 Mar 2021
I just checked this https://github.com/andymccurdy/redis-py/issues/612#issuecomment-515019364 but not fully sure though
auvipy
on 3 Mar 2021
Related issues
 sklarsa
·
3Comments
sklarsa
·
3Comments
 Xuexiang825
·
3Comments
Xuexiang825
·
3Comments
 aoerliang
·
3Comments
aoerliang
·
3Comments
 jmaroeder
·
3Comments
jmaroeder
·
3Comments
 keisetsu
·
3Comments
keisetsu
·
3Comments