Visidata: [Loader] Frictionless Data Packages
Dear @saulpw ,
this one is a big proposal, I think it's also a great idea (I will seem presumptuous); unfortunately I am not able to help you in a concrete way.
"Data Packages" is the specification core of Open Knowledge Foundation "Frictionless Data" project. This spec solve big problems strictly related to structured text files (especially CSV and TSV), as lack of metadata, lack of info about separators and text qualifiers, lack of info about field types, ecc..
Some interesting URL are:
- the spec for data-package https://frictionlessdata.io/specs/data-package/#specification
- and the one for table schema https://frictionlessdata.io/specs/table-schema/
There is a Python module to manage (reading and writing) Data Packages https://github.com/frictionlessdata/datapackage-py
If VisiData were a Data Packages reader and writer the number of users and stakeholder would increase significantly, because this is a big open data theme and many users of this world would be interested.
This specs are useful in example for one of the most used opensource open data portal platform (CKAN), and are used as official input and output format in data.world and in kaggle.
Thank you
 aborruso
aborruso
All 29 comments
Sure, I like the idea! This should not be hard for someone familiar with the format to create a loader. If you know of anyone who would like to collaborate, I'm sure we can get something working in an afternoon (or two at most).
 saulpw
on 31 Dec 2018
saulpw
on 31 Dec 2018
This issue has been added to the someday roadmap!
Things we need help with to re-open this issue:
1) Providing us with a representative Data Package specification for tabular data.
2) Sharing a Python script which queries and engages with that data.
If anyone wants to step up and help out, please feel free to re-open the issue!
 anjakefala
on 2 Aug 2019
anjakefala
on 2 Aug 2019
Hi @anjakefala
Things we need help with to re-open this issue:
- Providing us with a representative Data Package specification for tabular data.
I think that the official documentation could be a starting point https://frictionlessdata.io/docs/tabular-data-package/
Is it what you want?
- Sharing a Python script which queries and engages with that data.
Once again a good starting point is in the same website https://frictionlessdata.io/docs/using-data-packages-in-python/
aborruso
on 7 Aug 2019
That is definitely helpful (thank you :), but not quite what we are looking for!
We would like a direct link to a file, and an attached/inlned .py that specifically parses/dumps that file.
If you (or anyone) put that together for us, we would reopen the issue. :blush:
anjakefala
on 7 Aug 2019
Hi,
the code of the example read and parse the file
import datapackage
url = 'https://raw.githubusercontent.com/frictionlessdata/example-data-packages/master/periodic-table/datapackage.json'
dp = datapackage.Package(url)
# to have the resources names (here is only one)
dp.resource_names
# to print the value of a field of the resource 0
print([e['name'] for e in dp.resources[0].data if int(e['atomic number']) < 10])
# to read fields schema of resource 0
dp.descriptor['resources'][0]['schema']
Good first step!
How is the data and metadata usually kept together? A .zip? A url? How does Frictionless look in the wild?
How do people usually use frictionless? How does it help them? Do you have a vision for how the loader can make use of Datapackage?
anjakefala
on 7 Aug 2019
@anjakefala I have written a reply inside a notebook, because I think it could be more readable https://nextjournal.com/aborruso/data-package-loader-for-visidata
Thank you
aborruso
on 12 Aug 2019
I am really touched by the work you put into this, so I am going to reopen this issue. Let us collaborate on this in #visidata. =)
anjakefala
on 12 Aug 2019
@anjakefala I'm happy.
What could be the next step?
aborruso
on 13 Aug 2019
@aborruso, I have some stuff that I want to finish first for packaging up 2.-1, and then this will be my next task. =)
I think I will start in about a week!
anjakefala
on 13 Aug 2019
Hi @anjakefala I have seen changelog, wow!!
Then If I update my dev version, can I test this great new feature?
Thank yoi
aborruso
on 11 Nov 2019
Hi @aborruso!
The reason I did not write a comment that Saul got a basic loader up because I was distracted by looking into some of its kinks. But, you know what, yes, go ahead and please let me know how it works out.
I think you will run into a bug with datapackage.json's that reference data through urls, but all locally referenced ones should be fine.
Can you confirm?
anjakefala
on 11 Nov 2019
Hi @anjakefala I have tried to open this attached example.
The question is: how to open then the two csv resources?
Thank you
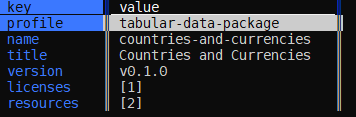
aborruso
on 11 Nov 2019
Which VisiData commit are you working with @aborruso?
anjakefala
on 11 Nov 2019
@anjakefala before replying to you I have run pip3 install --upgrade git+https://github.com/saulpw/visidata.git@develop
And now if I run vd datapackage.json I have a black window :(
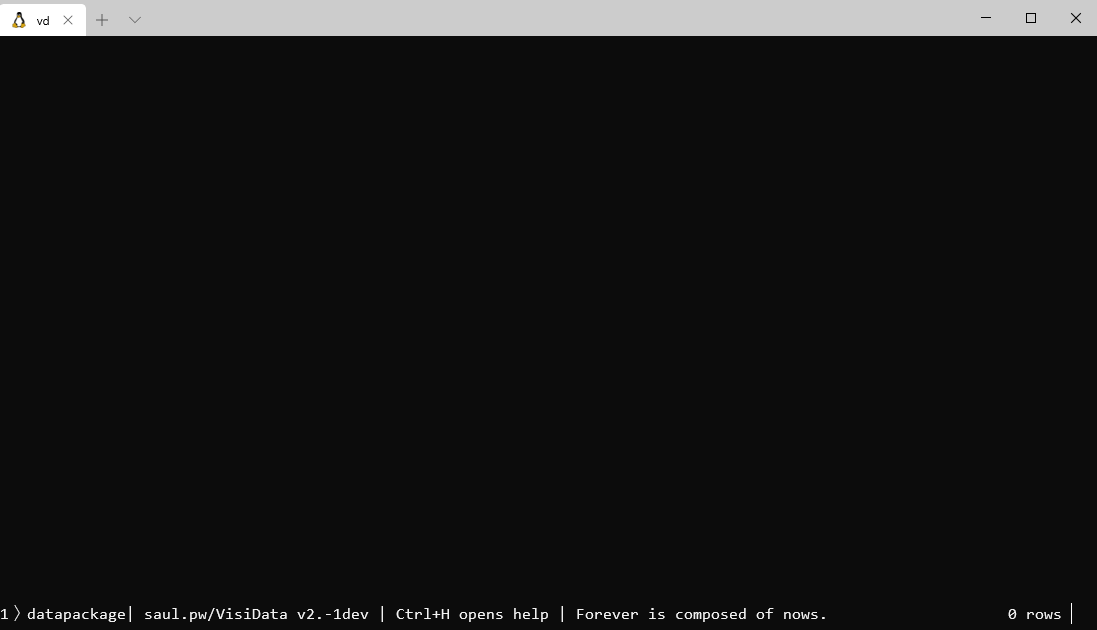
aborruso
on 11 Nov 2019
@aborruso yup. =( Working on it!
anjakefala
on 11 Nov 2019
Hi @aborruso,
Something a bit deeper is going on, and this loader is going to take some more time to fix. I will give you a poke here when it is ready for you to play with!
anjakefala
on 11 Nov 2019
thank you very much @anjakefala
aborruso
on 11 Nov 2019
Give it a whirl, please!!
You open the resources with Enter =)
anjakefala
on 13 Nov 2019
Hi @anjakefala please write me the steps.
I'm here, how to open a resource?

Thank you
aborruso
on 13 Nov 2019
vd -f frictionless x where x can be a url to a datapackage.json or a file system path to a datapackage.json. =D
Then you will get a table of resource. Press Enter to load one.
anjakefala
on 13 Nov 2019
For example: vd -f frictionless https://raw.githubusercontent.com/frictionlessdata/example-data-packages/master/geo-countries/datapackage.json
anjakefala
on 13 Nov 2019
@anjakefala I have
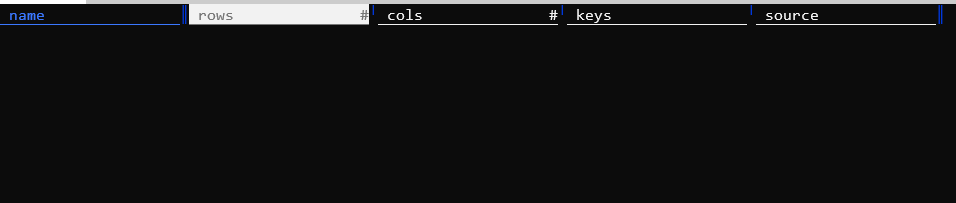
aborruso
on 13 Nov 2019
What is your most recent commit?
anjakefala
on 13 Nov 2019
Hi @anjakefala this morning this morning I have uninstalled and then installed again via pip3 install git+https://github.com/saulpw/visidata.git@develop
Is there a better procedure?
aborruso
on 13 Nov 2019
No, that is right. =( Can you drop by #visidata when you have a free moment?
anjakefala
on 13 Nov 2019
Also have you done pip3 install datapackage?
anjakefala
on 13 Nov 2019
@anjakefala I'm really stupid: in my pyenv environment I did have not installed datapackage.
It works, but not always. I'll try to write a report tomorrow.
@anjakefala @saulpw this is really a great new feature, Thank you
aborruso
on 13 Nov 2019
Awesome!
Please feel free to file new bugs against the frictionless loader. :blush: I am excited to see it fleshed out. I consider the basic feature request to be complete.
anjakefala
on 19 Nov 2019
Related issues
 suntzuisafterU
·
11Comments
suntzuisafterU
·
11Comments
 geekscrapy
·
12Comments
geekscrapy
·
12Comments
 khughitt
·
14Comments
khughitt
·
14Comments
 p3k
·
21Comments
aborruso
·
12Comments
p3k
·
21Comments
aborruso
·
12Comments