Victoriametrics: VMAgent dropping target on high load
Describe the bug
When there is a large number of target to scrape from, VMAgent have error on scraping, seem to happen only on large number of node/pods (cf last screenshot) before dropping all scraping target
Expected behavior
Should scrape target, like prometheus
Screenshots
Sometimes VMAgent also remove all scraping target:

Last 1h (number of pods)

Last 12h (number of pods)

Version
The one from your helm chart VMAgent: appVersion: v1.37.2
Used command-line flags
The one from your VMAgent helm chart and 3 customs:
remoteWrite.maxBlockSize: "1000000"remoteWrite.basicAuth.usernameremoteWrite.basicAuth.password
Additional context
K8s is Azure AKS
 AzSiAz
AzSiAz
All 10 comments
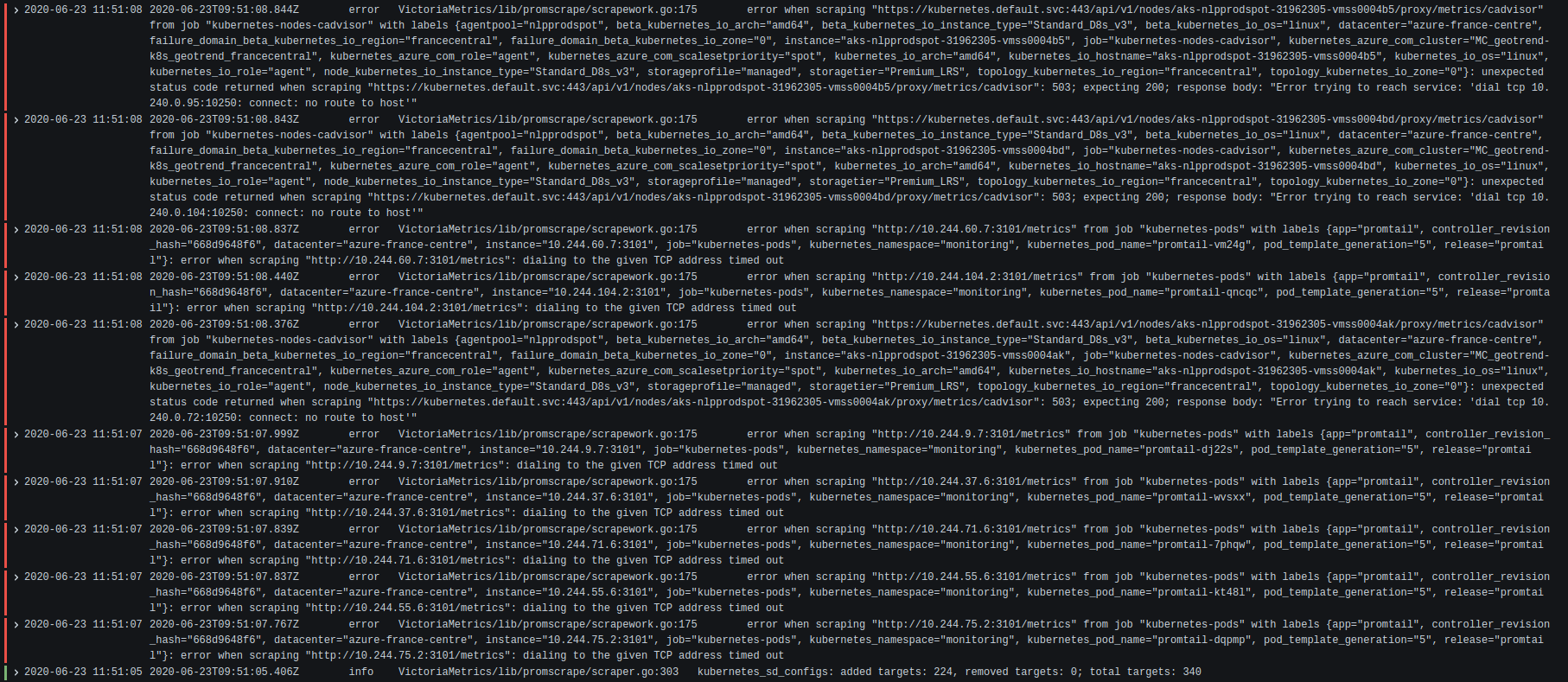
The first screenshot with error logs show that K8S API server had some issues. It couldn't dial certain K8S nodes via /api/v1/nodes/*/proxy/metrics/cadvisor with the error no route to host. This error means that the given K8S nodes were unreachable from K8S API server at this time.
vmagent couldn't dial certain targets at port 3101 during the same time with the error dialing to the given TCP address timed out.
These errors suggest that there were networking issues in K8S during this time frame.
Sometimes VMAgent also remove all scraping target
This looks like a bug in vmagent. It should leave the previous targets if it cannot obtain new target list due to errors listed on the first screenshot. Could you provide log messages emitted before the total targets: 0 message?
 valyala
on 23 Jun 2020
valyala
on 23 Jun 2020
The first screenshot with error logs show that K8S API server had some issues. It couldn't dial certain K8S nodes via
/api/v1/nodes/*/proxy/metrics/cadvisorwith the errorno route to host. This error means that the given K8S nodes were unreachable from K8S API server at this time.
vmagentcouldn't dial certain targets at port3101during the same time with the errordialing to the given TCP address timed out.These errors suggest that there were networking issues in K8S during this time frame.
That's why it's strange, I don't recall having those error with prometheus, and no gap in graph either
This looks like a bug in vmagent. It should leave the previous targets if it cannot obtain new target list due to errors listed on
the first screenshot. Could you provide log messages emitted before the total targets: 0 message?
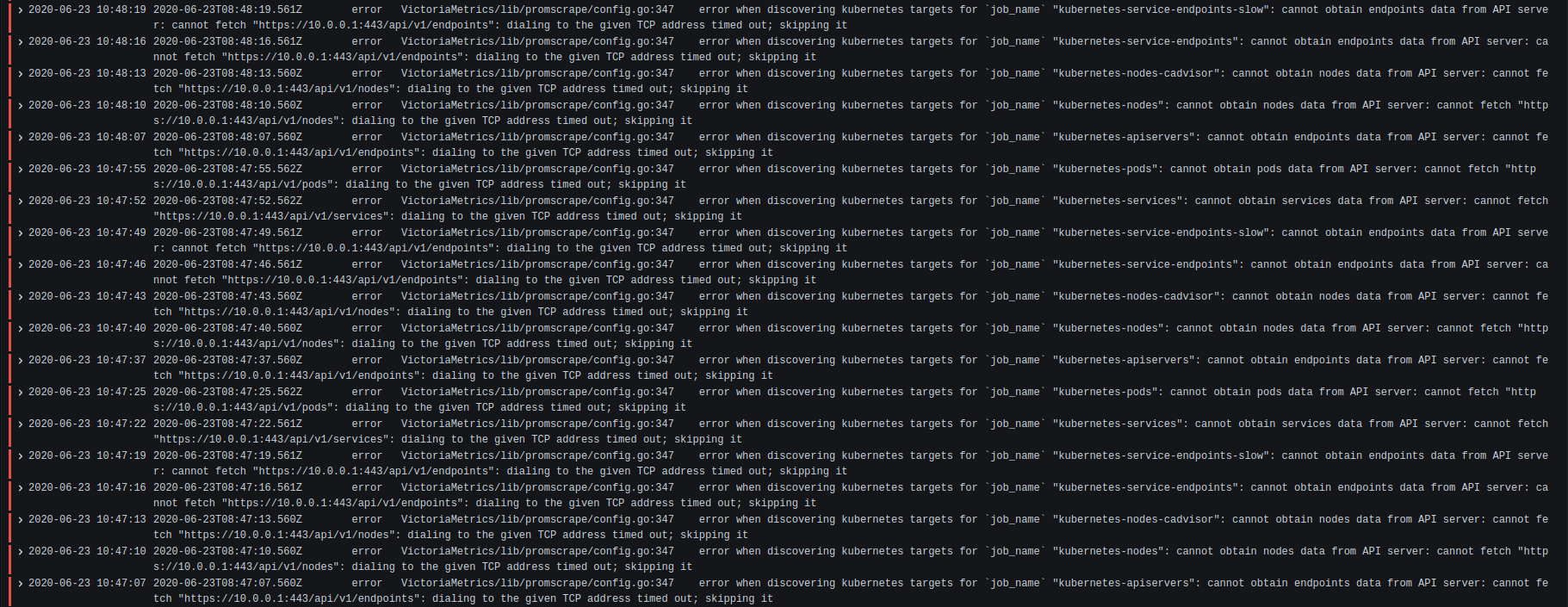
There is more log like the first screenshot, but I also found this, should be linked to target drop:
There was also no problem with discovery on prometheus, or at least no log of it
AzSiAz
on 23 Jun 2020
That's why it's strange, I don't recall having those error with prometheus, and no gap in graph either
Prometheus doesn't log scrape errors. The last error per each target can be seen at /targets page in both Prometheus and in vmagent. It is possible to suppress logging for scrape errors by passing -promscrape.suppressScrapeErrors command-line flag to vmagent. See https://victoriametrics.github.io/vmagent.html#troubleshooting for details.
As for gaps, they may be related to the bug with targets' drop in vmagent. This leads to gaps on graphs.
There is more log like the first screenshot, but I also found this, should be linked to target drop
Thanks for these screenshots! They show the real cause of the issue with dropped targets - when vmagent couldn't query K8S API server for updates, it was logging error when discovering kuberenets targets error and then dropping all the scrape targets. This will be fixed soon.
valyala
on 23 Jun 2020
That's why it's strange, I don't recall having those error with prometheus, and no gap in graph either
Prometheus doesn't log scrape errors. The last error per each target can be seen at
/targetspage in both Prometheus and in vmagent. It is possible to suppress logging for scrape errors by passing-promscrape.suppressScrapeErrorscommand-line flag tovmagent. See https://victoriametrics.github.io/vmagent.html#troubleshooting for details.As for gaps, they may be related to the bug with targets' drop in
vmagent. This leads to gaps on graphs.
Oh, that's good to know for prometheus, thanks
I can say for certain since there is a lot of node and pod scrapped but last I checked I don't think there was scrape error in this webpage either
There is more log like the first screenshot, but I also found this, should be linked to target drop
Thanks for these screenshots! They show the real cause of the issue with dropped targets - when
vmagentcouldn't query K8S API server for updates, it was loggingerror when discovering kuberenets targetserror and then dropping all the scrape targets. This will be fixed soon.
Happy to help :)
Thanks for your work, waiting to test this fix then :)
AzSiAz
on 23 Jun 2020
@AzSiAz , the fix is available in the commit 8f0bcec6cc9bf7674962a4e197278bff666d3884 . Could you build vmagent from this commit according to these instructions and verify whether it stops dropping targets on discovery errors when K8S API server is temporarily unavailable?
I can say for certain since there is a lot of node and pod scrapped but last I checked I don't think there was scrape error in this webpage either
Both Prometheus and vmagent record up metric per each scrape target. The values for this metric equals to 1 on successful scrape and equals to 0 on scrape error. So it is easy to determine failing targets with the following query: avg_over_time(up[5m]) < 1 . This query returns non-empty data points for targets, which were temporarily unavailable during the last 5 minutes since each data point.
valyala
on 23 Jun 2020
@AzSiAz , the fix is available in the commit 8f0bcec . Could you build
vmagentfrom this commit according to these instructions and verify whether it stops dropping targets on discovery errors when K8S API server is temporarily unavailable?
Thanks I will try with this commit and come back, hopefully with good news
Both Prometheus and vmagent record
upmetric per each scrape target. The values for this metric equals to 1 on successful scrape and equals to 0 on scrape error. So it is easy to determine failing targets with the following query:avg_over_time(up[5m]) < 1. This query returns non-empty data points for targets, which were temporarily unavailable during the last 5 minutes since each data point.
Well, I did not think of that one, I will use it to check uptime with new version
AzSiAz
on 23 Jun 2020
There is still a lot of scraping error, but it's not dropping target anymore with your latest fix, thanks :)

AzSiAz
on 23 Jun 2020
Well, after regularly forcing scaling for 2 days, I am happy to say this problem did not happend again, so all is now good, issue can be closed on next VMAgent version :smile:
AzSiAz
on 25 Jun 2020
@AzSiAz , thanks for the update!
valyala
on 25 Jun 2020
The bugfix has been included in v1.37.3. Closing the issue as fixed.
valyala
on 26 Jun 2020
Related issues
 faceair
·
3Comments
faceair
·
3Comments
 pmitra43
·
3Comments
pmitra43
·
3Comments
 WilliamDahlen
·
3Comments
WilliamDahlen
·
3Comments
 genericgithubuser
·
4Comments
genericgithubuser
·
4Comments
 abualy
·
3Comments
abualy
·
3Comments