Victoriametrics: Error in vmstorage regarding big packetsize
Describe the bug
vmstorage has error logs complaining about packet size.
app/vmstorage/transport/server.go:160 cannot process vminsert conn from 10.20.11.94:40018: cannot read packet with size 104176512: unexpected EOF
I assume this also causes data to drop
Expected behavior
Such error should not happen in vmstorage and vminsert should be writing all the data in vmstorage without an error
Version
docker image tag: 1.26.0-cluster
Additional context
- We are running clustered victoriametrics in GKE.
- For vmstorage, the data is stored in a HDD persistent disk.
- There are two pods running for each component
- There are two pods of prometheus (HA) writing data to this VictoriaMetrics
- RAM & CPU are as below:
- vmstorage (3 cpu & 15 Gi memory) *2
- vmselect (1 cpu & 10 Gi memory) * 2
- vminsert (4 cpu & 6 Gi memory) * 2
- sum(rate(vm_rows_inserted_total[5m])) by (instance)
{instance="10.24.7.59:8480"} : 111152.98245614035
{instance="10.24.8.48:8480"} : 111287.36842105263

Please let me know if additional information is required.
 bhavith
bhavith
All 16 comments
@bhavith , thanks for the detailed bug report.
Could you provide additional information?
- Do
vminsertlogs contain any errors or panic messages? Probably they were restarted at the time the error message appeared invmstoragelogs? - Could you provide non-zero promql graphs for the following metrics exported by
vminsertnodes at/metricspage:
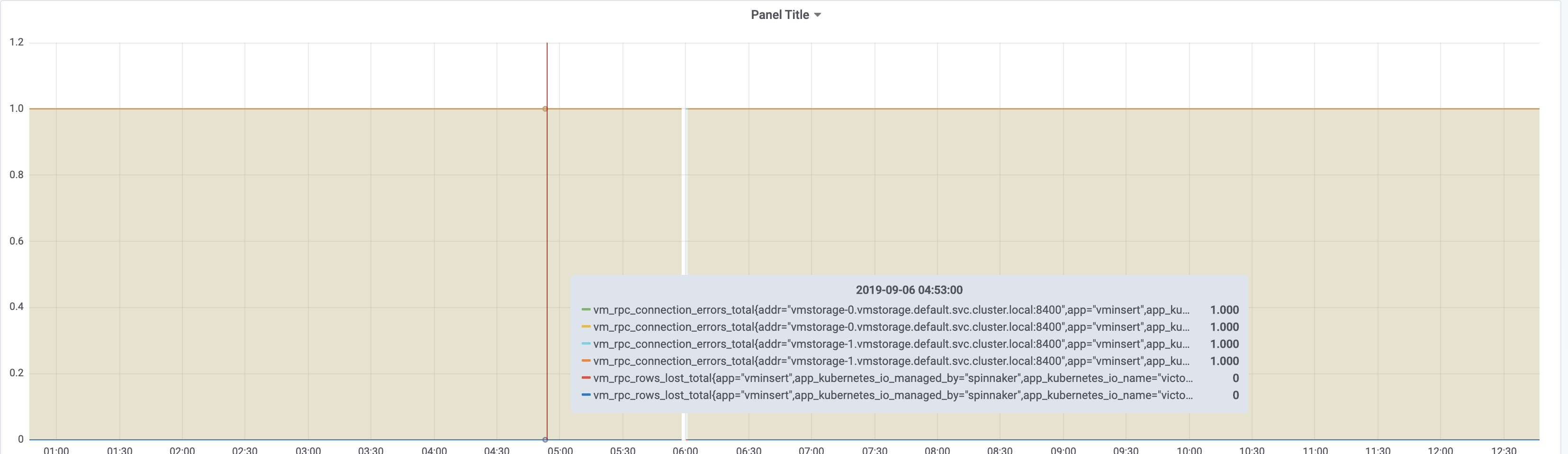
vm_rpc_connection_errors_total
vm_rpc_rows_lost_total
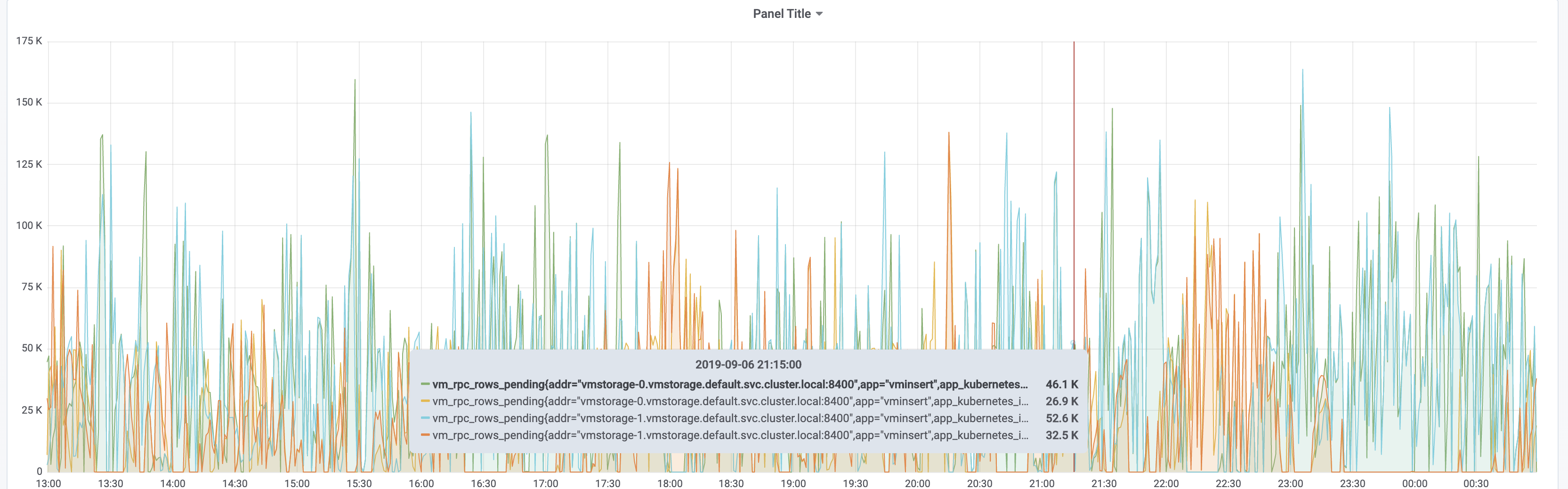
vm_rpc_rows_pending
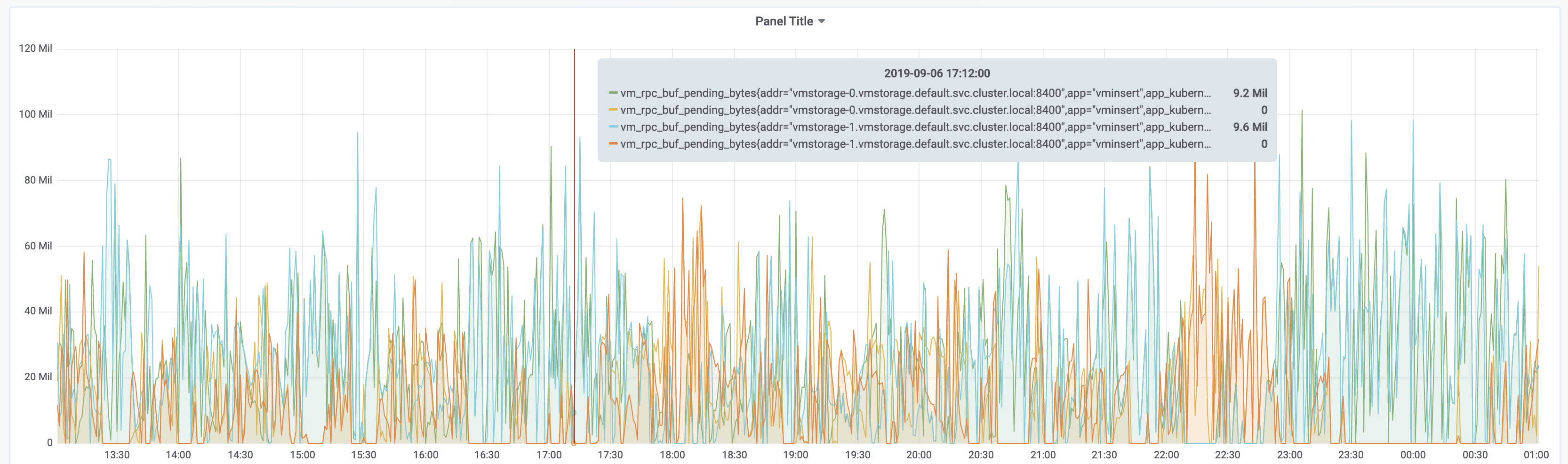
vm_rpc_buf_pending_bytes
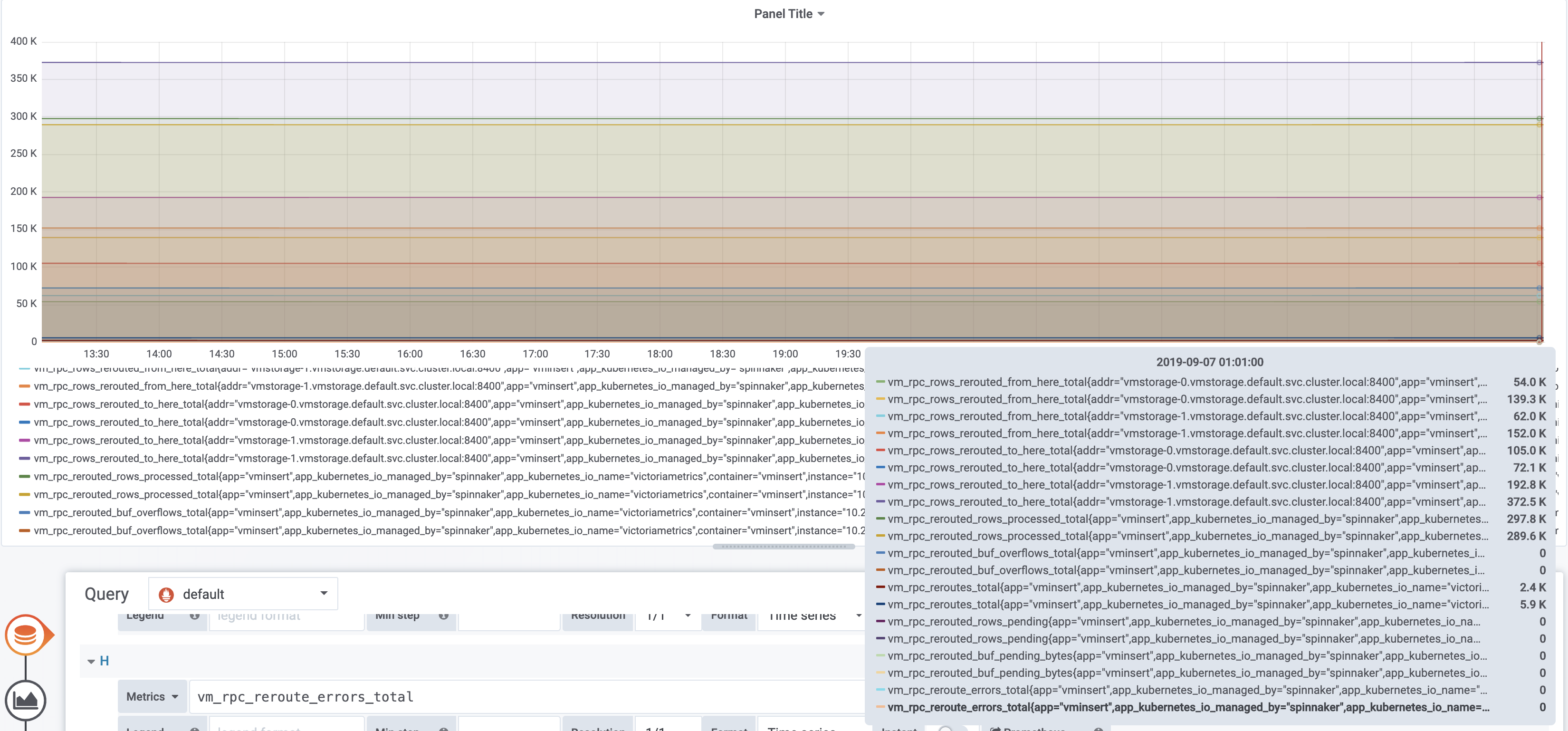
vm_rpc_rows_rerouted_from_here_total
vm_rpc_rows_rerouted_to_here_total
vm_rpc_rerouted_rows_processed_total
vm_rpc_rerouted_buf_overflows_total
vm_rpc_reroutes_total
vm_rpc_rerouted_rows_pending
vm_rpc_rerouted_buf_pending_bytes
vm_rpc_reroute_errors_total
- Could you provide graphs for the following query for metrics collected from
vminsertandvmstoragenodes from/metricspage:
sum(rate(process_cpu_seconds_user_total[2m])) by (instance)
 valyala
on 5 Sep 2019
valyala
on 5 Sep 2019
vminsert started and was completely up by 2019-09-05 14:57:22.062. I could see the error in vmstorage at 2019-09-05 14:58:52.430
I will note it next time this happens.
2.
3.
bhavith
on 7 Sep 2019
@bhavith , thanks for the detailed info and graphs.
Non-zero vm_rpc_connection_errors_total indicates on connection errors between vminsert and vmstorage nodes. Such errors usually occur when vmstorage node is temporarily unavailable (for instance, it is restarted). vminsert can gracefully handle such errors by re-routing data to the remaining available vmstorage nodes. Zero values for vm_rpc_rows_lost_total suggest no rows are lost due to connection errors.
Graphs for vm_rpc_rows_pending are OK - vminsert flushes pending rows to vmstorage nodes every second. So vm_rpc_rows_pending can reach per-second number of ingested rows - 50k-100k per vmstorage node in your case. It isn't OK if vm_rpc_rows_pending is much higher (10x) than the ingestion rate.
Non-zero values for vm_rpc_rows_rerouted_from_here_total and vm_rpc_rows_rerouted_to_here_total indicate that the inserted rows were successfully re-routed from temporarily unavailable vmstorage node to the remaining healthy vmstorage node(s). These metrics don't increase over time on graphs, so the error was temporary and now all the vmstorage nodes are in working state.
CPU usage graph for sum(rate(process_cpu_seconds_user_total[2m])) by (instance) suggest that vminsert and vmstorage nodes have enough free CPU, so it isn't a bottleneck.
Did you set -rpc.disableCompression flag on vminsert nodes? This flag reduces CPU usage on vminsert nodes at the cost of higher network bandwidth usage. In your case every inserted row requires ~100 bytes of network bandwidth if uncompressed. So ~100K rows/s ingestion rate requires at least 100K*100 = 10MB/s network bandwidth between each pair of vminsert and vmstorage nodes. The network bandwidth can become a bottleneck if -rpc.disableCompression flag is set. See rate(vm_tcpdialer_written_bytes_total[2m]) for actual network bandwidth usage.
I put a few patches into cluster branch aimed towards reducing the probability of big packet size error and improving reporting for this error. Could you try building VictoriaMetrics from the latest commit in the cluster branch according to these docs and verifying whether the error occurs again (if it occurs, it should contain additional information about the number of bytes read from the packet before reaching EOF).
valyala
on 11 Sep 2019
Hi @valyala Thanks for your analysis. I have not set the flag -rpc.disableCompression. I will try the new patch and let you know the results.
bhavith
on 12 Sep 2019
Hi @valyala , updated the installation with new images. Will let you know the results soon. Btw while vmstorage was getting updated, vminsert went red with the error -- > "error in "/insert/1/prometheus": cannot send 35557 bytes to storageNode "vmstorage-1.vmstorage.default.svc.cluster.local:8400": 57 rows dropped because of reroutedBuf overflows 362387865 bytes "
bhavith
on 13 Sep 2019
I got the error once till now : --> error app/vmstorage/transport/server.go:160 cannot process vminsert conn from 10.24.0.80:52044: cannot read packet with size 34759884: unexpected EOF; read only 27787256 bytes
bhavith
on 13 Sep 2019
Error logs from vmstorage:
2019-09-13T10:28:03.191165670Z 2019-09-13T10:28:03.190+0000 error app/vmstorage/transport/server.go:160 cannot process vminsert conn from 10.24.8.4:39680: cannot read packet with size 51684065: unexpected EOF; read only 32243704 bytes
E
2019-09-13T10:28:03.191221122Z 2019-09-13T10:28:03.190+0000 info app/vmstorage/transport/server.go:149 closing vminsert conn from 10.24.8.4:39680
E
2019-09-13T10:28:04.075078172Z 2019-09-13T10:28:04.074+0000 info app/vmstorage/transport/server.go:122 accepted vminsert conn from 10.24.8.4:39994
E
2019-09-13T10:28:04.075910972Z 2019-09-13T10:28:04.075+0000 info app/vmstorage/transport/server.go:154 processing vminsert conn from 10.24.8.4:39994
E
2019-09-13T10:28:35.136735901Z 2019-09-13T10:28:35.136+0000 error app/vmstorage/transport/server.go:160 cannot process vminsert conn from 10.24.8.4:39270: cannot read packet with size 69465325: unexpected EOF; read only 41811960 bytes
E
2019-09-13T10:28:35.136776104Z 2019-09-13T10:28:35.136+0000 info app/vmstorage/transport/server.go:149 closing vminsert conn from 10.24.8.4:39270
E
2019-09-13T10:29:01.258472554Z 2019-09-13T10:29:01.258+0000 error app/vmstorage/transport/server.go:160 cannot process vminsert conn from 10.24.2.2:54152: cannot read packet with size 32116321: unexpected EOF; read only 16515064 bytes
E
2019-09-13T10:29:01.258520381Z 2019-09-13T10:29:01.258+0000 info app/vmstorage/transport/server.go:149 closing vminsert conn from 10.24.2.2:54152
E
2019-09-13T10:30:00.919754231Z 2019-09-13T10:30:00.919+0000 info app/vmstorage/transport/server.go:185 accepted vmselect conn from 10.24.1.10:52732
E
2019-09-13T10:30:00.920380162Z 2019-09-13T10:30:00.920+0000 info app/vmstorage/transport/server.go:224 processing vmselect conn from 10.24.1.10:52732
E
2019-09-13T10:30:01.476199390Z 2019-09-13T10:30:01.475+0000 info app/vmstorage/transport/server.go:185 accepted vmselect conn from 10.24.12.3:44724
E
2019-09-13T10:30:01.476777403Z 2019-09-13T10:30:01.476+0000 info app/vmstorage/transport/server.go:224 processing vmselect conn from 10.24.12.3:44724
E
2019-09-13T10:31:09.341060742Z 2019-09-13T10:31:09.340+0000 info app/vmstorage/transport/server.go:122 accepted vminsert conn from 10.24.8.4:41056
E
2019-09-13T10:31:09.342033987Z 2019-09-13T10:31:09.341+0000 info app/vmstorage/transport/server.go:154 processing vminsert conn from 10.24.8.4:41056
E
2019-09-13T10:31:19.078152729Z 2019-09-13T10:31:19.077+0000 info app/vmstorage/transport/server.go:122 accepted vminsert conn from 10.24.2.2:54842
E
2019-09-13T10:31:19.078837686Z 2019-09-13T10:31:19.078+0000 info app/vmstorage/transport/server.go:154 processing vminsert conn from 10.24.2.2:54842
E
2019-09-13T10:31:49.832104362Z 2019-09-13T10:31:49.831+0000 error app/vmstorage/transport/server.go:160 cannot process vminsert conn from 10.24.8.4:39994: cannot read packet with size 50629413: unexpected EOF; read only 16252920 bytes
E
2019-09-13T10:31:49.832148647Z 2019-09-13T10:31:49.831+0000 info app/vmstorage/transport/server.go:149 closing vminsert conn from 10.24.8.4:39994
E
2019-09-13T10:31:58.867679600Z 2019-09-13T10:31:58.867+0000 error app/vmstorage/transport/server.go:160 cannot process vminsert conn from 10.24.2.2:54372: cannot read packet with size 104847136: unexpected EOF; read only 65535992 bytes
E
2019-09-13T10:31:58.867750272Z 2019-09-13T10:31:58.867+0000 info app/vmstorage/transport/server.go:149 closing vminsert conn from 10.24.2.2:54372
E
Could you try the commit 550a12415a77d7d4a1294450fdfaa37e75808ae1 ? It improves error reporting on vminsert side.
valyala
on 13 Sep 2019
deployed the new version. I saw a single instance where the error was logged in vmstorage, but couldnt find anything related in vminserts. Will keep monitoring and let you know. Thanks!!!
bhavith
on 17 Sep 2019
This error is reported during startup -->
2019-09-23T11:28:34.650+0000 error VictoriaMetrics@/app/vmstorage/transport/server.go:160 cannot process vminsert conn from 10.24.14.18:54390: cannot read packet with size 103479784: unexpected EOF; read only 39321592 bytes
At the exact time there was no error log in vmsinert. But a few seconds before, there were these logs --> 2019-09-23T11:28:07.007+0000 error VictoriaMetrics@/app/vminsert/netstorage/netstorage.go:100 cannot send data to vmstorage vmstorage-1.vmstorage.default.svc.cluster.local:8400: cannot write data: cannot flush internal buffer to the underlying writer: write tcp4 10.24.14.18:54390->10.24.8.2:8400: i/o timeout; re-routing data to healthy vmstorage nodes
Seems these are related and probably has something to do with the restart.
Also it seems, even when the logs say vminsert will try to connect to the next storage node, the logs shows that it is still sending traffic to the same vmstorage node.
bhavith
on 23 Sep 2019
These messages suggest one of the following issues:
1) Limited network bandwidth between vminsert and vmstorage nodes, so vminsert cannot send 100MB of data to vmstorage in 100 seconds.
2) Slow vmstorage that can't keep up with the incoming data from vminsert nodes. In this case vmstorage node should have a bottleneck - either CPU or disk IO.
Each vminsert establishes a single connection to each vmstorage node. Each such connection is limited by a single CPU core on both vminsert and vmstorage side. Try increasing the number of vminsert nodes in order to spread incoming data among bigger number of connections between vminsert and vmstorage nodes, so more CPU cores can be loaded.
Also try disabling data compression with -rpc.disableCompression command-line flag passed to vminsert. This should reduce CPU usage at the cost of higher network bandwidth usage.
valyala
on 25 Sep 2019
Also it seems, even when the logs say vminsert will try to connect to the next storage node, the logs shows that it is still sending traffic to the same vmstorage node.
vminsert keeps trying to send data to unhealthy vmstorage node in order to determine when the node becomes healthy again.
valyala
on 25 Sep 2019
done. lets see how it goes.
bhavith
on 25 Sep 2019
I dont see any more of such errors. Looks like it is good now.
bhavith
on 1 Oct 2019
Thanks for the update! Then leaving the issue open until possible solutions for this issue are published in README.md for cluster version.
The solutions:
- increasing the number of vminsert or vmstorage nodes, so more CPU cores can be loaded with serving increased number of connections between vminsert and vmselect nodes.
- Disabling compression for such connections with
-rpc.disableCompressionon vminsert.
These workarounds are needed, since currently vminsert establishes a single connection per each configured vmstorage node and this connection is served by a single CPU core, which can be saturated with high amounts of data.
In the future we can add support for automatic adjustement for the number of connections between vminsert and vmstorage nodes depending on the ingestion rate.
valyala
on 1 Oct 2019
Added reference to this issue from REAMDE.md at f1a79656766a091dff537d3acf03044a29d54b3f . Closing the issue.
valyala
on 9 Oct 2019
Related issues
 oOHenry
·
4Comments
oOHenry
·
4Comments
 localpref
·
3Comments
localpref
·
3Comments
 genericgithubuser
·
4Comments
genericgithubuser
·
4Comments
 EricAntoni
·
3Comments
EricAntoni
·
3Comments
 pmitra43
·
3Comments
pmitra43
·
3Comments