Transformers: Memory blowup with TPU Trainer in master
Environment info
transformersversion: 3.0.2 (master)- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.7.0a0+8fb7c50 (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?:Yes, TPU v2-8
Who can help
@sgugger @sshleifer @patrickvonplaten
Information
Recent changes to the Trainer for TPU has resulted in memory blowup during training.
On a machine with 208GB of RAM [sic], this was the memory profile with the master branch on 20th August.

This only has increase in memory during evaluation (which is another memory leak bug https://github.com/huggingface/transformers/issues/5509). If you throw enough RAM to the problem, it stays in control.
After the recent changes the memory profile has become this.

Look how quickly the memory blows up even on this huge machine. I have implemented some optimizations to save memory where I am caching only a single copy of features on redis-server but that is not enough now. The most interesting thing to see is that now the memory also increases during training and not just evaluation.
After these changes, Trainer for TPUs has become unusable for training any practical model and I request you to please look into fixing this.
Model I am using (Bert, XLNet ...): T5
The problem arises when using:
- [ ] the official example scripts: (give details below)
- [x] my own modified scripts: (give details below)
The tasks I am working on is:
- [ ] an official GLUE/SQUaD task: (give the name)
- [x] my own task or dataset: (give details below)
To reproduce
Steps to reproduce the behavior:
Use the TPU example run_language_modelling to reproduce.
Expected behavior
Memory stays constant with the number of training and evaluation iterations.
 misrasaurabh1
misrasaurabh1
All 20 comments
Indeed this seems very problematic. Let's look into it cc @sgugger
 LysandreJik
on 1 Sep 2020
LysandreJik
on 1 Sep 2020
Some hints - The main process takes 3.5x more RAM than the other processes individually.
misrasaurabh1
on 1 Sep 2020
Do you have a commit id that gives the first graph, so we can look into the diff?
 sgugger
on 1 Sep 2020
sgugger
on 1 Sep 2020
I think I'm having a similar issue. I'm using n1-highmem-16 (16 vCPUs, 104 GB memory) with v3-8 TPU for pre-training a RoBERTa model on 24GB text data.
I was able to load the dataset using nlp (https://github.com/huggingface/nlp/issues/532), but it eats up all the available memory during training.
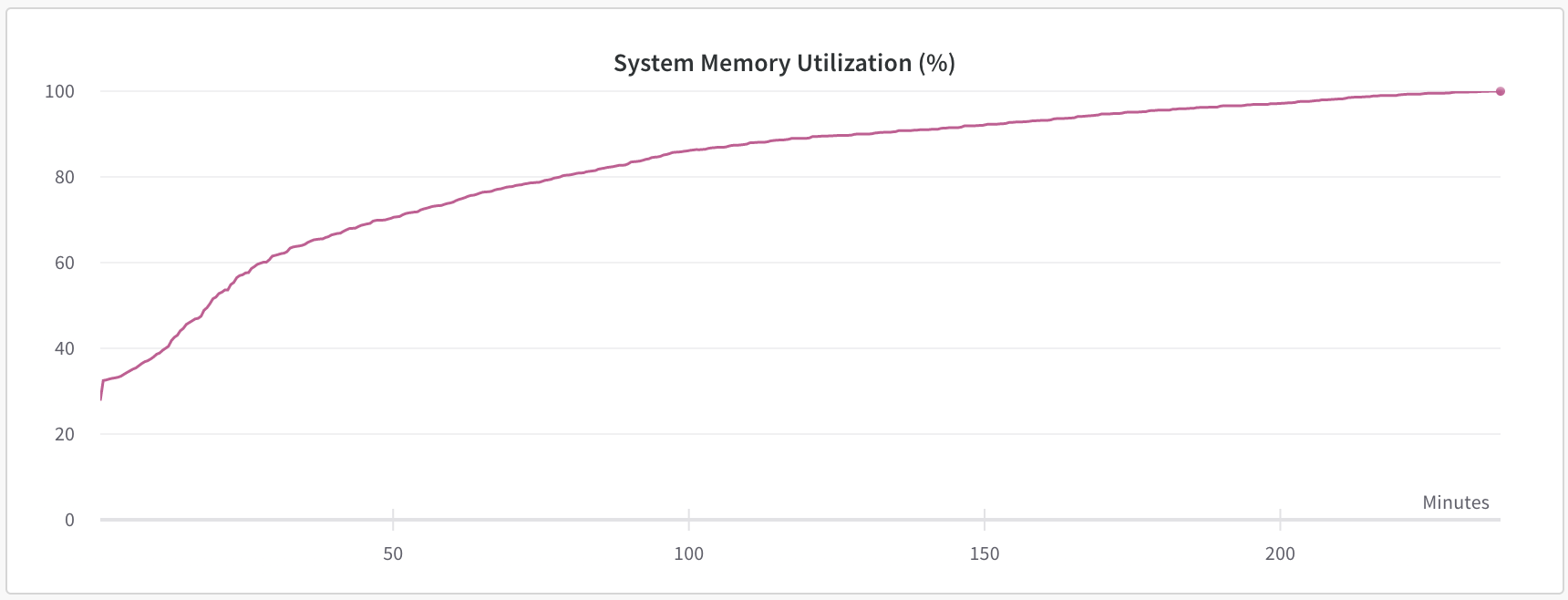
(master branch on Aug 25 installed with pip install git+https://github.com/huggingface/transformers. Not sure how to check a commit id...)
 go-inoue
on 1 Sep 2020
go-inoue
on 1 Sep 2020
Same question. I was wondering are there any strategies implemented to save memory?
Something like lazyDataloader?
 shizhediao
on 1 Sep 2020
shizhediao
on 1 Sep 2020
@sgugger I retried a run with the commit id 86c07e634f3624cdf3f9e4e81ca53b808c4b22c6 (20 Aug) and it seems to not have this memory blowup that we see on the current master

misrasaurabh1
on 1 Sep 2020
@shizhediao Because the default behavior of Huggingface TPU Trainer is to load features into memory 8 times into all the processes separately, it quickly eats up vast amounts of system memory.
There are two options to save memory-
- Write a lazy loading Dataset whose
__getitem__function quickly loads features from disk when provided with the key. This could save the most memory. Even though I haven't tested this I suspect the disk random lookup and IO in the critical path of the training loop could become a bottleneck. - Cache the features in memory only once and share them among all the processes. I did this by using an in-memory key value server Redis by dumping all the pickled features to redis server and writing the
__getitem__function where it loads the key from the redis server when requested. I saw empirically that this made by training about 20% faster on my workload than loading all the features 8 times into memory (probably due to cache thrashing). I used unix sockets to make the lookups even faster.
misrasaurabh1
on 1 Sep 2020
Thanks for your reply!
Would you like to share your code or are there any open-sourced code I can refer to?
Thanks!
shizhediao
on 2 Sep 2020
Sure, this is in the __init__ function of my Dataset function. As compared to Huggingface TextDataset, this particular way sped up training by 20% for me while using around 1/7 memory and generating features faster (due to less tail-latency in multiprocessing and not writing and reading features from disk)
file_paths_copy = copy.deepcopy(file_paths)
file_paths_copy = sorted(file_paths_copy) #multiprocess env, we want all processes to have the files in the same order
self.redis = redis.Redis(unix_socket_path="/tmp/redis.sock")
self.pipe = self.redis.pipeline()
file_lineno_map = {}
line_counter = 0
for file in file_paths_copy:
num_lines = count_lines(file)
file_lineno_map[file] = line_counter
line_counter += num_lines
# This is so that lines in each file gets assigned a unique line number in a multi-process env
self.num_examples = line_counter
for index, file_path in enumerate(file_paths_copy): # Can be multiple files
if index % xm.xrt_world_size() == xm.get_ordinal():
# If this process is assigned to process the following file, so we can use 8 cpu cores to load data parallely
logger.info("Creating features from dataset file at %s", file_path)
with open(file_path, encoding="utf-8") as f:
for line_num, line in enumerate(f.read().splitlines()): # Text to Text file where each file is an example and source and target is separated by a tab symbol
if (len(line) > 0 and not line.isspace()):
if line.find('\t') == -1:
logger.warning(
f"Encountered a line without tab separator in file {file_path} line {line_num+1}"
)
continue
input, output = line.split('\t')
features = self.text_pair_to_features(input, output)
key = line_num + file_lineno_map[
file_path] if not self.val else "val-" + str(
line_num + file_lineno_map[file_path]) # The name of the redis key
self.pipe.set(key, pickle.dumps(features))
if line_num % self.num_operations_pipelined == 1:
self.pipe.execute() # So that we only dump to redis as a batch, can speed up writing
self.pipe.execute()
if is_torch_tpu_available():
xm.rendezvous(tag="featuresGenerated") # So that the multi-process environment all wait for each other before doing anything else
With the __getitem__ function being
def __getitem__(self, i) -> Dict[str, torch.Tensor]:
if self.val:
key = f"val-{i}"
else:
key = i
example = pickle.loads(self.redis.get(key))
return {"input_ids": example[0], "attention_masks": example[1], "labels": example[2]}
Thanks so much!
shizhediao
on 2 Sep 2020
Cool dataset!
Seq2SeqDataset is also lazy, but no redis. I wonder the speed difference: https://github.com/huggingface/transformers/blob/master/examples/seq2seq/utils.py#L159
@patil-suraj is this going to be an issue for Seq2SeqTrainer? We can't read all examples into memory for MT.
 sshleifer
on 3 Sep 2020
sshleifer
on 3 Sep 2020
@sshleifer Not sure. I have yet to experiment with Seq2SeqTrainer on TPU so can't say much. But I have managed to successfully train t5-base and on TPU using Trainer with lazy dataset.
 patil-suraj
on 3 Sep 2020
patil-suraj
on 3 Sep 2020
@sshleifer @patil-suraj I studied the linecache way of doing things and the reasons for not going with linecache for me were
- Our data files are on mounted network disks so first byte access time would be too large.
- Data sharded in multiple files leading to linecache being less effective as compared to just one file.
- I also suspect how much would linecache help because we are not reading lines sequentially where caching would have helped but rather reading random lines where reading a whole block of text from disk would still mean that on average we only use only one line from the block.
- I am also generally wary of involving disks in the critical path of the training loop as disks are very slow. Given that TPU requires higher input feed rate and evidence that Huggingface Trainer only uses a single CPU worker rather than many which could have helped with CPU generating features from disk in parallel while the TPU was working. See https://github.com/huggingface/transformers/issues/6316 . I believe if multiple workers were allowed in DataLoader then loading features from disk would be a valid solution.
misrasaurabh1
on 4 Sep 2020
@misrasaurabh1 We just merged a simple fix that was obviously leaking memory for training (non-detached tensors) and that came from a recent change, so it might very well be the source of your leaks. Could you confirm whether or not current master has the leak or not? If so, using the same fix in the evaluation loop should also fix the eval memory leak we currently have.
sgugger
on 8 Sep 2020
Yes, with the latest master the memory leak during training is not there anymore! Memory usage seems to be constant during training.

Although if the same .detach() method would fix the evaluation memory leak, that would be huge! I could go down from a 32-CPU 208GB machine I am using right now to something like 16-CPU 64GB machine resulting in big monetary savings over time.
misrasaurabh1
on 8 Sep 2020
Will look at the evaluation leak a bit more. From a first read, it looks like everything is properly detached, so it seems like this leak has another cause.
Thanks a lot for checking!
sgugger
on 8 Sep 2020
@shizhediao Because the default behavior of Huggingface TPU Trainer is to load features into memory 8 times into all the processes separately, it quickly eats up vast amounts of system memory.
There are two options to save memory-
- Write a lazy loading Dataset whose
__getitem__function quickly loads features from disk when provided with the key. This could save the most memory. Even though I haven't tested this I suspect the disk random lookup and IO in the critical path of the training loop could become a bottleneck.- Cache the features in memory only once and share them among all the processes. I did this by using an in-memory key value server Redis by dumping all the pickled features to redis server and writing the
__getitem__function where it loads the key from the redis server when requested. I saw empirically that this made by training about 20% faster on my workload than loading all the features 8 times into memory (probably due to cache thrashing). I used unix sockets to make the lookups even faster.
Recently I had the same issue and such behavior is on GPU as well. One good solution is to use memory-mapped dataset, which is in spirit similar to Option 1 here. I used the awesome huggingface/datasets library which provides memory-mapped dataset class automatically through Apache Arrow and it is fairly easy to use. I reduced my RAM usage from 90G to 6G and it won't grow with the dataset size.
 jxhe
on 13 Sep 2020
jxhe
on 13 Sep 2020
Is there any update on this? Is the memory leak during evaluation fixed?
 phtephanx
on 12 Oct 2020
phtephanx
on 12 Oct 2020
@sgugger Is the memory leak during evaluation fixed by https://github.com/huggingface/transformers/pull/7767 ?
phtephanx
on 14 Oct 2020
I don't know, as I have not had time to investigate the leak during evaluation on TPUs yet.
sgugger
on 14 Oct 2020
Related issues
 HanGuo97
·
3Comments
HanGuo97
·
3Comments
 fyubang
·
3Comments
fyubang
·
3Comments
 yspaik
·
3Comments
yspaik
·
3Comments
 zhezhaoa
·
3Comments
zhezhaoa
·
3Comments
 lemonhu
·
3Comments
lemonhu
·
3Comments
Most helpful comment
@misrasaurabh1 We just merged a simple fix that was obviously leaking memory for training (non-detached tensors) and that came from a recent change, so it might very well be the source of your leaks. Could you confirm whether or not current master has the leak or not? If so, using the same fix in the evaluation loop should also fix the eval memory leak we currently have.