Transformers: From which layer is fine tuning starting in BERT?
Hi, I looked at the code but couldn't manage to understand the layer from which BERT is being fine tuned. I am using simple_lm_finetuning.py function.
 kbulutozler
kbulutozler
All 14 comments
When BERT is fine-tuned, all layers are trained - this is quite different from fine-tuning in a lot of other ML models, but it matches what was described in the paper and works quite well (as long as you only fine-tune for a few epochs - it's very easy to overfit if you fine-tune the whole model for a long time on a small amount of data!)
 Rocketknight1
on 6 May 2019
Rocketknight1
on 6 May 2019
Thank you. May I ask what the difference of this approach is from pre-training?
kbulutozler
on 7 May 2019
The original model weights are used for initialization, whereas for a model trained from scratch, the weights are initialized randomly.
Rocketknight1
on 10 May 2019
Thank you, I got it now.
kbulutozler
on 13 May 2019
Came upon this when searching for an answer to a related question.
When adding a dense layer on top for a classification task, do the model weights for BERT get updated or only the dense layer(are the BERT layers frozen or unfrozen during training)? I ask b/c when training a classifier on the stack overflow tags dataset which contains 40.000 posts with tags in 20 classes I got some unusual results. I trained base-uncased and base-cased and what is weird is that after the first epoch, the test set prediction remain the same. By that I mean exactly the same. In other words, with a 80/20 split (32.000 posts in train set / 8.000 posts in test set) it doesn't matter if you are doing 1, 2 or 3 epochs, the test set prediction don't change. It stays at 83.875% for uncased and 83.224% for cased. The weird thing is that the training loss goes down.
I have put the actual predictions in a pandas dataframe and the predictions in epoch 1, 2 and 3 are exactly the same.
 steindor
on 13 May 2019
steindor
on 13 May 2019
When a classifier is trained, all the model weights get updated, not just the weights in the classifier layer, so I would expect some overfitting if you train on a small labelled dataset for a lot of epochs.
The behaviour you've described is unusual - have you tried varying the learning rate, or making a much smaller training set, training on it for 1 epoch only and seeing what the results look like? It might indicate a problem with the data.
Rocketknight1
on 13 May 2019
That's what I thought. I tested training the uncased version with 20% of the dataset (training set 6400 and testing set 1600) which gave me an eval accuracy of 0.76875 after epoch 1 and 2. The eval loss is even the excact same value ( 0.7407131800800562 )
I ran eval before starting the training which gave an accuracy of 0.05 which makes sense with 20 classes and random weights. Then after epoch 1 it jumps up to aforementioned values and stays the same in epoch 2 and 3.
Any pointers on how to debug this? Might it help checking the gradients?
steindor
on 15 May 2019
Yeah, that's where I'd look. If forced to guess, I'd say the network isn't really getting any input, and is therefore just learning the bias in the last layer. So you could try inspecting the data batches in the training loop right before they enter the network, to make sure there's actually data there and that the data matches the labels, and also checking that most network parameters are getting some gradient after each batch. If your code is in a repo somewhere, feel free to link it and I'll take a look.
Rocketknight1
on 16 May 2019
I went through the training data and it appears that its formatted the right way. I also checked the gradients and they are adjusted after each back() call. I think this might be related to the warm_up part of the adjustable learning rate.
It happens after epoch 3:
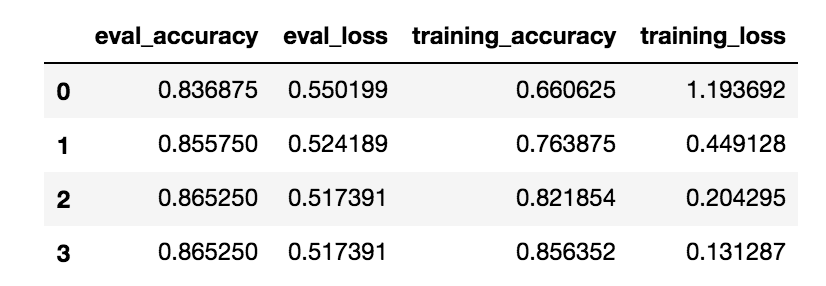
Then I also get a warning:
05/17/2019 20:15:02 - WARNING - pytorch_pretrained_bert.optimization - Training beyond specified 't_total'. Learning rate multiplier set to 0.0. Please set 't_total' of WarmupLinearSchedule correctly.
I am using a default value of 0.1. I plotted the learning rate over 4 epochs and in epoch 4 the learning rate becomes negative:
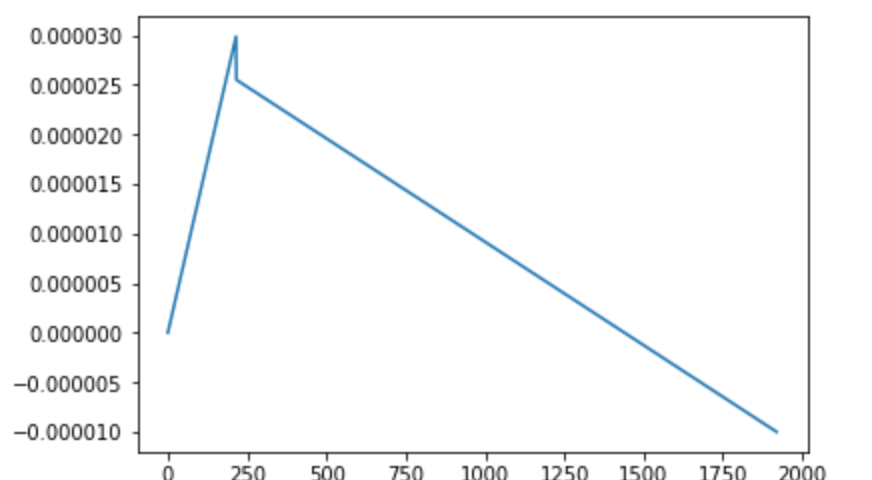
3 epochs is more then enough for this dataset as it starts to overfit quickly. I just want to understand why this happens, it doesn't make sense to me. The loss and accuracy in the evaluation phase is exactly the same(and the training loss drops in epoch no 4 when the LR is negative). I put the code on Kaggle if you want to take a look ( no pressure :-) )
https://www.kaggle.com/stoddur/bert-so-classification-test/edit
Im going to play a bit with the warm_up function and see which learning rates are set with different values. Will let you know if I find out anything else.
steindor
on 17 May 2019
In the BERT paper, and in this repo, the learning rate is 'warmed up' from 0 to the maximum over the first 10% of training, and then linearly decays back to 0 for the remaining 90% of training. In order for that to work, the learning rate scheduler needs to know how many steps there will be in training in total (i.e. steps_per_epoch * num_epochs). It seems like that value is being passed incorrectly, causing the LR to decay to zero too quickly and therefore freezing all the weights.
Also, I can't see the code at your link - is it possibly private?
Rocketknight1
on 18 May 2019
Yeah, I noticed that now reading through the paper :)
Made the kernel public, the code is a bit rough, hope it makes sense to you.
steindor
on 18 May 2019
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
![stale[bot] picture](https://avatars3.githubusercontent.com/in/1724?v=4&s=40) stale[bot]
on 17 Jul 2019
stale[bot]
on 17 Jul 2019
I get error below while running the program.. Did I do any mistake?
warmup_linear = WarmupLinearSchedule( warmup=args.warmup_proportion,
t_total=num_train_optimization_steps)
lr_this_step = args.learning_rate * warmup_linear.get_lr(num_train_optimization_steps,
args.warmup_proportion)
WARNING - pytorch_pretrained_bert.optimization - Training beyond specified 't_total'. Learning rate multiplier set to 0.0. Please set 't_total' of WarmupLinearSchedule correctly.
 niranjan8129
on 7 Sep 2019
niranjan8129
on 7 Sep 2019
@kbulutozler
@steindor .. did you solve WarmupLinearSchedule issue ? I am getting same error .. I tried your kaggle code but getting error that " the link does not exists"
I get error below while running the program.. Did I do any mistake?
warmup_linear = WarmupLinearSchedule( warmup=args.warmup_proportion,
t_total=num_train_optimization_steps)
lr_this_step = args.learning_rate * warmup_linear.get_lr(num_train_optimization_steps,
args.warmup_proportion)
WARNING - pytorch_pretrained_bert.optimization - Training beyond specified 't_total'. Learning rate multiplier set to 0.0. Please set 't_total' of WarmupLinearSchedule correctly.
niranjan8129
on 13 Sep 2019
Related issues
 iedmrc
·
3Comments
iedmrc
·
3Comments
 yspaik
·
3Comments
yspaik
·
3Comments
 fabiocapsouza
·
3Comments
fabiocapsouza
·
3Comments
 siddsach
·
3Comments
siddsach
·
3Comments
 alphanlp
·
3Comments
alphanlp
·
3Comments
Most helpful comment
When BERT is fine-tuned, all layers are trained - this is quite different from fine-tuning in a lot of other ML models, but it matches what was described in the paper and works quite well (as long as you only fine-tune for a few epochs - it's very easy to overfit if you fine-tune the whole model for a long time on a small amount of data!)