Thanos: compaction uses a lot of disk space
Thanos v0.3.2, Prometheus v2.8.0
Hi,
we have a problem with the used disk space by compactor component I've read somewhere that the compaction need(or will use) max ~300gb of disk space but in my case it uses more than 600GB. I use Thanos with prometheus about 20 days.
root@ny-prometheus2:~# du -hs /storage/compact/compact/0@\{monitor\=\"PA-Monitoring\"\}/01D7KG4D8WJ5YZ332GWW996S58/
321G /storage/compact/compact/0@{monitor="PA-Monitoring"}/01D7KG4D8WJ5YZ332GWW996S58/
root@ny-prometheus2:~# du -hs /storage/compact/compact/0@\{monitor\=\"PA-Monitoring\"\}/*
4.0K /storage/compact/compact/0@{monitor="PA-Monitoring"}/01D6FF7ZMY99RVRA5SDGVNEPWE
48G /storage/compact/compact/0@{monitor="PA-Monitoring"}/01D6MFAC97T9N69DQQHHMMX5H2
48G /storage/compact/compact/0@{monitor="PA-Monitoring"}/01D6SKSS3K74XHEP3YG0Y6QHAW
48G /storage/compact/compact/0@{monitor="PA-Monitoring"}/01D6YPKNTT2F4JPG167FE649K3
49G /storage/compact/compact/0@{monitor="PA-Monitoring"}/01D75EDMY21SEY2H6QAG75XNH
42G /storage/compact/compact/0@{monitor="PA-Monitoring"}/01D7963HEGYGVSV8J209G3KXFR
44G /storage/compact/compact/0@{monitor="PA-Monitoring"}/01D7EKSVAKCRJ1KAA2R9H1E6HB
4.0K /storage/compact/compact/0@{monitor="PA-Monitoring"}/01D7K4397DBQSADAD4RNK4KT1A
48G /storage/compact/compact/0@{monitor="PA-Monitoring"}/01D7K8GQNQM4T9TZZMH7Q6D45N
321G /storage/compact/compact/0@{monitor="PA-Monitoring"}/01D7KG4D8WJ5YZ332GWW996S58
root@ny-prometheus2:~# du -hs /storage/compact/compact/
643G /storage/compact/compact/
So I worried that it will eat all my disk space after some time.
 harutyundermenjyan
harutyundermenjyan
All 9 comments
Disk space usage graph chart by compactor with percentages
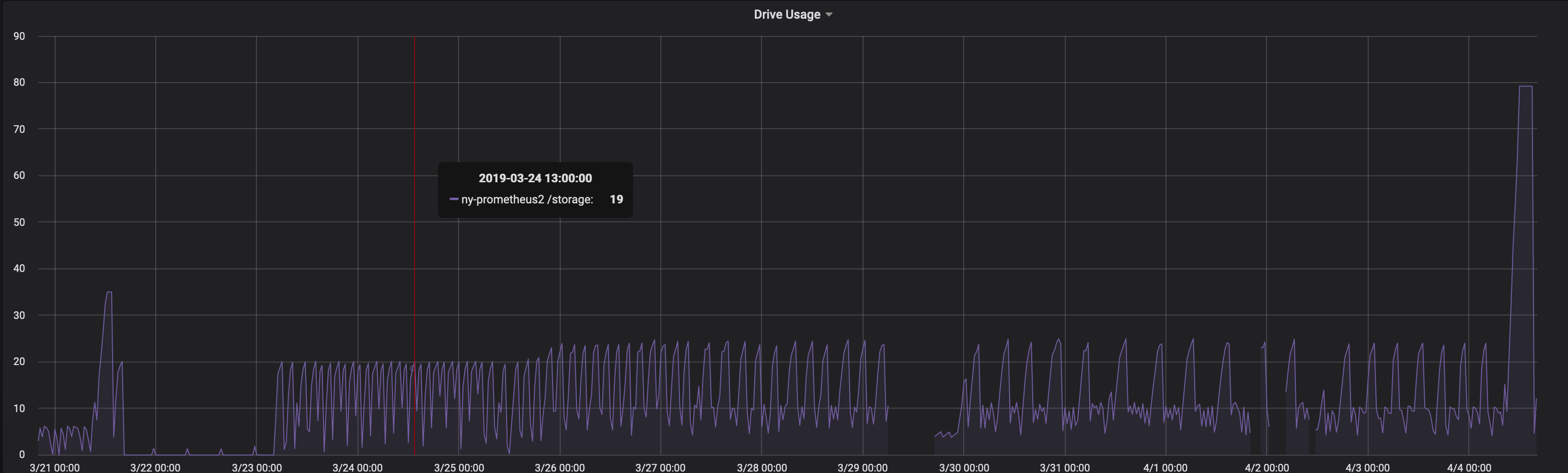
harutyundermenjyan
on 4 Apr 2019
this's expected. you have 7 compacted blocks of level 3 and compactor produces thew new one of 4th level from them
this is basically:
final block ~= 3lvl_block_size*7
depends on data cardinality, but 4 level compacted blocks has ~ 1.7 byte per sample.
the same disk consumption for downsampling, thus you should do capacity planning for your metrics pipeline.
as a workaround, you can specify max compaction level manually: https://github.com/improbable-eng/thanos/blob/master/cmd/thanos/compact.go#L103
p.s. 4lvl is 2 weeks blocks, so as you can see, this compaction happened in 2 weeks interval.
 xjewer
on 16 Apr 2019
xjewer
on 16 Apr 2019
Well, this: 3lvl_block_size*7 is essentially the worst case scenario.
Also ~ 1.7 byte per sample. this really depends. For some data they claim up to 3 bytes/sample so it all depends.
Anyway, as @xjewer said it is all expected. We have to prepare block before uploading so compactor needs space for:
3 older blocks (e.g 3lvl)
1 newer block (e.g 4lvl).
Closing as expected behaviour.
Feedback welcome how we could improve this (: I don't think there is super need to lowering disk usage, there are more important resources then this that we might want to optimize for (e.g mem) first.
 bwplotka
on 16 Apr 2019
bwplotka
on 16 Apr 2019
Thanks for detailed explanation and suggestions.
Good product with good approaches to implementations.
harutyundermenjyan
on 16 Apr 2019
Is it possible to change the default maxCompactionLevel by giving it as flag for compactor?
I didn't find such flag in DOCs here --> https://github.com/improbable-eng/thanos/blob/master/docs/components/compact.md
But based on the link above the flag should be max-compaction-level. Am I right?
harutyundermenjyan
on 16 Apr 2019
Yes. It is hidden though:
https://github.com/improbable-eng/thanos/blob/e6d5b49bf2d2281f8f2f2d0e853158174a2e541f/cmd/thanos/compact.go#L103-L104
On Tue, 16 Apr 2019 at 19:23, Harutyun Dermenjyan notifications@github.com
wrote:
Is it possible to change the default maxCompactionLevel by giving it as
command line option for compaction?
I didn't find such option.—
You are receiving this because you modified the open/close state.
Reply to this email directly, view it on GitHub
https://github.com/improbable-eng/thanos/issues/1007#issuecomment-483789006,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AGoNu6FwjXBt7CCNfvfF6JAn_pRDkr7yks5vhhUjgaJpZM4ccRuR
.
bwplotka
on 16 Apr 2019
One more question: what else will it affect if we change max-compaction-level to a lower value than the default one except decrease of disk space usage which is expected?
harutyundermenjyan
on 18 Apr 2019
Facing the same issue, please let us know what adverse effect we can expect if we lower the max-compaction-level. ie (I have lvl6 blocks in the store but set the limit to lvl5, will it break?)
Thanks.
 rhamon
on 3 Jun 2019
rhamon
on 3 Jun 2019
FWIW: I was getting constant pod evictions due to disk pressure, set --debug.max-compaction-level=3 and it's running straight for 20min for the very first time.
 caarlos0
on 30 Jul 2019
caarlos0
on 30 Jul 2019
Related issues
 d-ulyanov
·
27Comments
d-ulyanov
·
27Comments
 smalldirector
·
33Comments
bwplotka
·
36Comments
smalldirector
·
33Comments
bwplotka
·
36Comments
 daviddyball
·
52Comments
bwplotka
·
31Comments
daviddyball
·
52Comments
bwplotka
·
31Comments
Most helpful comment
Well, this:
3lvl_block_size*7is essentially the worst case scenario.Also
~ 1.7 byte per sample.this really depends. For some data they claim up to 3 bytes/sample so it all depends.Anyway, as @xjewer said it is all expected. We have to prepare block before uploading so compactor needs space for:
3 older blocks (e.g 3lvl)
1 newer block (e.g 4lvl).
Closing as expected behaviour.
Feedback welcome how we could improve this (: I don't think there is super need to lowering disk usage, there are more important resources then this that we might want to optimize for (e.g mem) first.