Test-infra: Prow started extra test pod, causing running test to fail
What happened:
Prow has scheduled an additional test pod, against policy. It deleted the cluster from another run, causing gce-master-scale-performance to fail.
What you expected to happen:
No extra pods.
How to reproduce it (as minimally and precisely as possible):
n/a
Please provide links to example occurrences, if any:
n/a
Anything else we need to know?:
Debugging in https://github.com/kubernetes/kubernetes/issues/84910
/area prow
/kind oncall-hotlist
 oxddr
oxddr
All 22 comments
@oxddr: The label(s) area/ cannot be applied. These labels are supported: api-review, community/discussion, community/maintenance, community/question, cuj/build-train-deploy, cuj/multi-user, platform/aws, platform/azure, platform/gcp, platform/minikube, platform/other
In response to this:
What happened:
Prow has scheduled an additional test pod, against policy. It deleted the cluster from another run, causing gce-master-scale-performance to fail.What you expected to happen:
No extra pods.How to reproduce it (as minimally and precisely as possible):
-Please provide links to example occurrences, if any:
-Anything else we need to know?:
Debugging in https://github.com/kubernetes/kubernetes/issues/84910/area prow
/kind oncall-hotlist
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
 k8s-ci-robot
on 7 Nov 2019
k8s-ci-robot
on 7 Nov 2019
@oxddr: The label(s) area/ cannot be applied. These labels are supported: api-review, community/discussion, community/maintenance, community/question, cuj/build-train-deploy, cuj/multi-user, platform/aws, platform/azure, platform/gcp, platform/minikube, platform/other
In response to this:
What happened:
Prow has scheduled an additional test pod, against policy. It deleted the cluster from another run, causing gce-master-scale-performance to fail.What you expected to happen:
No extra pods.How to reproduce it (as minimally and precisely as possible):
-
Please provide links to example occurrences, if any:
Anything else we need to know?:
Debugging in https://github.com/kubernetes/kubernetes/issues/84910/area prow
/kind oncall-hotlist
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
k8s-ci-robot
on 7 Nov 2019
@oxddr: The label(s) area/ cannot be applied. These labels are supported: api-review, community/discussion, community/maintenance, community/question, cuj/build-train-deploy, cuj/multi-user, platform/aws, platform/azure, platform/gcp, platform/minikube, platform/other
In response to this:
What happened:
Prow has scheduled an additional test pod, against policy. It deleted the cluster from another run, causing gce-master-scale-performance to fail.What you expected to happen:
No extra pods.How to reproduce it (as minimally and precisely as possible):
n/aPlease provide links to example occurrences, if any:
n/aAnything else we need to know?:
Debugging in https://github.com/kubernetes/kubernetes/issues/84910/area prow
/kind oncall-hotlist
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
k8s-ci-robot
on 7 Nov 2019
Looking into logs for this one ...
 stevekuznetsov
on 7 Nov 2019
stevekuznetsov
on 7 Nov 2019
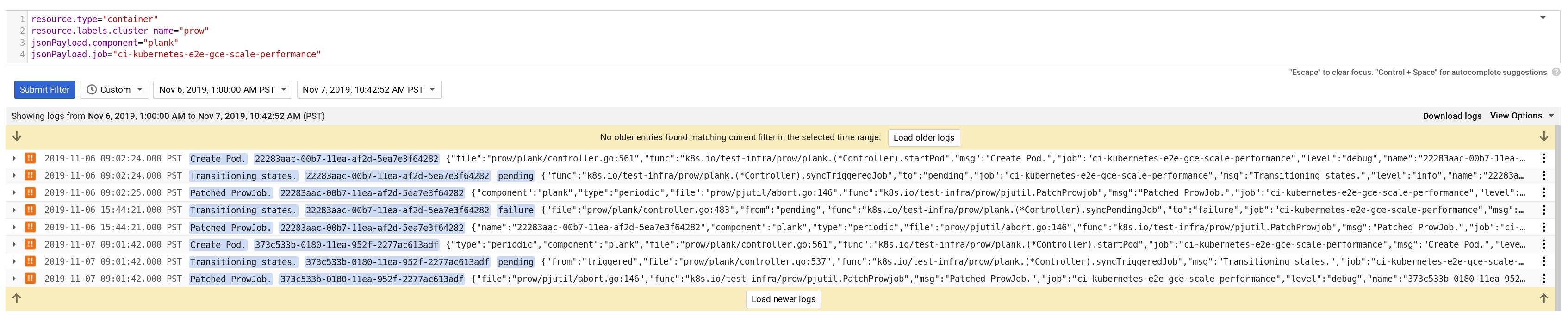
I am not seeing any evidence for Prow starting multiple Pods. Could we please edit the title of this issue to reflect the actual symptoms you saw and dig into the root causes?
stevekuznetsov
on 7 Nov 2019
I'll see if something else reflects these lines ...
I 2019-11-06T18:54:55Z POST /api/v1/namespaces/test-pods/pods: (15.58548ms) 201 [app.binary/v0.0.0 (linux/amd64) kubernetes/$Format 104.154.169.0:52340]
I 2019-11-06T18:54:55Z POST /api/v1/namespaces/test-pods/pods/de5df282-00c6-11ea-8799-a606d7f02d02/binding: (2.88648ms) 201 [kube-scheduler/v1.13.11 (linux/amd64) kubernetes/5976cae/scheduler [::1]:36700]
We did start pod "de5df282-00c6-11ea-8799-a606d7f02d02" but that is for job "ci-kubernetes-e2e-gce-scale-correctness":

This does not seem like a Prow bug. In what way did the jobs interact to make the first one fail? Were they contentious on resources? Is this an issue with boskos?
stevekuznetsov
on 7 Nov 2019
ci-kubernetes-e2e-gce-scale-correctness should in fact start daily per the config.
 BenTheElder
on 7 Nov 2019
BenTheElder
on 7 Nov 2019
Thanks @stevekuznetsov for looking into that.
ci-kubernetes-e2e-gce-scale-correctnessandci-kubernetes-e2e-gce-scale-performancetest run in scalability build cluster- Those test are started at 12:01 and 17:01 UTC as per config
- Pods creations from scalability build cluster:
I 2019-11-06T17:02:24Z POST /api/v1/namespaces/test-pods/pods: (19.082914ms) 201 [app.binary/v0.0.0 (linux/amd64) kubernetes/$Format 104.154.169.0:52340]
I 2019-11-06T17:02:24Z POST /api/v1/namespaces/test-pods/pods/22283aac-00b7-11ea-af2d-5ea7e3f64282/binding: (3.446873ms) 201 [kube-scheduler/v1.13.11 (linux/amd64) kubernetes/5976cae/scheduler [::1]:36700]
I 2019-11-06T18:54:55Z POST /api/v1/namespaces/test-pods/pods: (15.58548ms) 201 [app.binary/v0.0.0 (linux/amd64) kubernetes/$Format 104.154.169.0:52340]
I 2019-11-06T18:54:55Z POST /api/v1/namespaces/test-pods/pods/de5df282-00c6-11ea-8799-a606d7f02d02/binding: (2.88648ms) 201 [kube-scheduler/v1.13.11 (linux/amd64) kubernetes/5976cae/scheduler [::1]:36700]
I 2019-11-07T12:01:41Z POST /api/v1/namespaces/test-pods/pods: (38.973551ms) 201 [app.binary/v0.0.0 (linux/amd64) kubernetes/$Format 35.226.65.173:59104]
I 2019-11-07T12:01:41Z POST /api/v1/namespaces/test-pods/pods/4e754e23-0156-11ea-952f-2277ac613adf/binding: (4.538674ms) 201 [kube-scheduler/v1.13.11 (linux/amd64) kubernetes/6c1e92d/scheduler [::1]:49938]
First and last creations match the config, but the one in the middle doesn't. It shouldn't be started, especially if it's for ci-kubernetes-e2e-gce-scale-correctness.
oxddr
on 7 Nov 2019
Do you have more details than those pod creation time stamps? There's not a ton to go on here.
BenTheElder
on 7 Nov 2019
What kind of details you think of?
oxddr
on 8 Nov 2019
do you have the pod names / IDs? or more details about what kind of cluster it deleted or what jobs would do that?
BenTheElder
on 8 Nov 2019
- On our end we observed that master VM for
ci-kubernetes-e2e-gce-scale-performancetest has been deleted (test run by pod22283aac-00b7-11ea-af2d-5ea7e3f64282) - Caller IP of the GCE API call points to the scalability build cluster.
- We use this cluster only for two tests
ci-kubernetes-e2e-gce-scale-correctnessandci-kubernetes-e2e-gce-scale-performance. - They share the same cluster name. We rely on kubetest to cleanup old resources before starting a new test.
- Tests are scheduled so they don't interfere.
de5df282-00c6-11ea-8799-a606d7f02d021runningci-kubernetes-e2e-gce-scale-correctnesshas been scheduled outside the time specific in the config.
I'd like to understand why it happened. Prow shouldn't run test outside the spec provided in the config
I hope that helps.
FTR: scalability tests are pretty expensive to run both in terms of dollars and their duration (we can only run them once a day). We'd like to minimize infra impact on them to a minimum, that's the reason I'd like to understand what has happened here.
Thanks!
oxddr
on 8 Nov 2019
I'm aware of how expensive these are.
container_cluster_name_prow__logs__2019-11-06T10-54.txt
I actually see @stevekuznetsov triggering a rerun??
{
"insertId": "1wjdmgofmmfz1q",
"jsonPayload": {
"handler": "/rerun",
"file": "prow/cmd/deck/main.go:1457",
"func": "main.handleRerun.func1",
"job": "ci-kubernetes-e2e-gce-scale-correctness",
"msg": "Attempted rerun",
"allowed": true,
"prowjob": "38ec6d1c-008d-11ea-af2d-5ea7e3f64282",
"level": "info",
"user": "stevekuznetsov",
"component": "deck"
},
"resource": {
"type": "container",
"labels": {
"pod_id": "deck-66f9dd7655-p8tq5",
"zone": "us-central1-f",
"project_id": "k8s-prow",
"cluster_name": "prow",
"container_name": "deck",
"namespace_id": "default",
"instance_id": "5742234516608501261"
}
},
"timestamp": "2019-11-06T18:54:32Z",
"severity": "ERROR",
"labels": {
"container.googleapis.com/namespace_name": "default",
"compute.googleapis.com/resource_name": "gke-prow-n1-standard-8-24b71378-l0s8",
"container.googleapis.com/pod_name": "deck-66f9dd7655-p8tq5",
"container.googleapis.com/stream": "stderr"
},
"logName": "projects/k8s-prow/logs/deck",
"receiveTimestamp": "2019-11-06T18:54:36.207271797Z"
},
https://console.cloud.google.com/logs/viewer?project=k8s-prow&minLogLevel=0&expandAll=false×tamp=2019-11-08T15:52:03.965000000Z&customFacets=&limitCustomFacetWidth=true&dateRangeStart=2019-11-06T08:00:00.000Z&dateRangeEnd=2019-11-06T19:01:00.000Z&interval=CUSTOM&resource=container%2Fcluster_name%2Fprow&scrollTimestamp=2019-11-06T18:54:55.000000000Z&filters=jsonPayload.job:ci-kubernetes-e2e-gce-scale-correctness
BenTheElder
on 8 Nov 2019
I was asked to trigger a re-run when the tests were failed by the release CI signal lead -- on the Deck overview the runs for the job I re-triggered were all red at the time.
stevekuznetsov
on 8 Nov 2019
I still don't understand, though -- these are separate jobs with separate configurations. There's no bug in Prow here. If you want jobs to not be able to collide because they share the same resources, I'd suggest using a boskos resource to limit concurrency across jobs.
stevekuznetsov
on 8 Nov 2019
/cc @mm4tt
Thanks @stevekuznetsov, that's make sense to me now. I didn't catch correctness test has been triggered manually. Can I ask you, to consult next time with sig-scalability before triggering 5k tests manually? Our setup is quite fragile. While using boskos might help with the management, we are simply not there yet.
oxddr
on 8 Nov 2019
Totally -- I'll admit I knew the tests were large but I didn't see any test running, so I figured it was fine. I didn't know there were inter-test dependencies. @krzyzacy could help you set up a simple dynamic resource to limit throughput.
stevekuznetsov
on 8 Nov 2019
I suspect even with resource limits we just don't want to rerun these because we already have the time slots scheduled.
Perhaps deck can be aware of certain jobs not being suitable to re-run.
BenTheElder
on 8 Nov 2019
https://github.com/kubernetes/test-infra/issues/15192 to follow up @oxddr
BenTheElder
on 8 Nov 2019
I think we can close this one out, but it would be good to put a list of exactly which tests shouldn't be triggered somewhere, perhaps in a comment on https://github.com/kubernetes/test-infra/issues/15192 at least
BenTheElder
on 8 Nov 2019
Related issues
 chaosaffe
·
3Comments
chaosaffe
·
3Comments
 cjwagner
·
3Comments
BenTheElder
·
3Comments
stevekuznetsov
·
3Comments
cjwagner
·
3Comments
BenTheElder
·
3Comments
stevekuznetsov
·
3Comments
 spzala
·
4Comments
spzala
·
4Comments