Test-infra: Use ProwJobs in deck
deck is using its own format for exposing jobs that predates ProwJobs. We should get rid of the old format in favor of using ProwJobs.
TODO:
- [x] Expose ProwJobs in deck at
/prowjobs.jsor something. (https://github.com/kubernetes/test-infra/pull/5631) - [ ] Switch the JS to look at those. (https://github.com/kubernetes/test-infra/pull/7301)
- [ ] Switch the flake detector stuff to look at those.
- [ ] (fwiw) Switch the submit queue to use the new endpoint and a correct timestamp format.
- [ ] Delete
/data.jsand associated machinery.
/area prow
 kargakis
kargakis
All 42 comments
For clarity and why I think this is important, here is the description I created in a Trello card that unfortunately is private.
The prow frontend exposes a JSON blob of all tests in the system that can be used for programmatic access by tools without the need to reside inside our CI cluster. The problem with the exposed format is that it predates ProwJobs (canonical representation of tests in prow) thus any tools built on top of the prow frontend are incompatible with all existing prow utilities and furthermore the exposed format lacks necessary information included in ProwJobs (eg. year in timestamps).
We should fix deck to expose ProwJobs instead of the old format before developers start building on top of the old format (I know one of our devs is already looking into building on top of prow). This is blocking the
refreshplugin, too: https://github.com/kubernetes/test-infra/pull/5075The work required includes changes in deck: both frontend (Javascript) and backend (Go).
https://github.com/kubernetes/test-infra/tree/master/prow/cmd/deck
kargakis
on 3 Nov 2017
This is actually pretty important, because it lets me dry run a copy of tide or plank or something without needing access to the k8s api server.
 spxtr
on 16 Nov 2017
spxtr
on 16 Nov 2017
/assign
kargakis
on 20 Nov 2017
Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle stale
 fejta-bot
on 19 Feb 2018
fejta-bot
on 19 Feb 2018
/remove-lifecycle stale
 stevekuznetsov
on 19 Feb 2018
stevekuznetsov
on 19 Feb 2018
I'm working on the sub task _Switch the JS to look at those._
 katerinapat
on 12 Mar 2018
katerinapat
on 12 Mar 2018
data.js is 11MB (indented json, 820KB compressed). prowjobs.js is 33MB (unindented json, 1.93MB compressed).
You shouldn't have to load that much data to view jobs. If you drop pod_spec and metadata from prowjobs.json, it's only 730KB compressed.
 rmmh
on 14 Mar 2018
rmmh
on 14 Mar 2018
Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle stale
fejta-bot
on 22 Jun 2018
/remove-lifecycle stale
@kargakis what was the status here?
stevekuznetsov
on 6 Jul 2018
https://github.com/kubernetes/test-infra/pull/7301 was the last attempt to move this forward
/unassign
kargakis
on 5 Aug 2018
Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle stale
fejta-bot
on 3 Nov 2018
Stale issues rot after 30d of inactivity.
Mark the issue as fresh with /remove-lifecycle rotten.
Rotten issues close after an additional 30d of inactivity.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle rotten
fejta-bot
on 3 Dec 2018
/remove-lifecycle rotten
/assign
 ibzib
on 19 Dec 2018
ibzib
on 19 Dec 2018
Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle stale
fejta-bot
on 19 Mar 2019
/unassign
ibzib
on 19 Mar 2019
/remove-lifecycle stale
stevekuznetsov
on 19 Mar 2019
Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle stale
fejta-bot
on 17 Jun 2019
Stale issues rot after 30d of inactivity.
Mark the issue as fresh with /remove-lifecycle rotten.
Rotten issues close after an additional 30d of inactivity.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle rotten
fejta-bot
on 17 Jul 2019
/remove-lifecycle rotten
stevekuznetsov
on 18 Jul 2019
/assign @stevekuznetsov
Removing the labels but doing nothing repeatedly is perhaps a sign that this issue isn't going to get done. Is this still relevant? What's your plan?
 spiffxp
on 24 Jul 2019
spiffxp
on 24 Jul 2019
@stevekuznetsov
If this is still relevant and no one else is actively working on it then I can pick it up. It would appear that a large chunk of the implementation is already complete or in PR.
 clarketm
on 13 Aug 2019
clarketm
on 13 Aug 2019
/assign
clarketm
on 13 Aug 2019
Yes, it's still relevant. There's no great reason to use the intermediate representation for the front-end, it can just operate on the actual ProwJobs.
stevekuznetsov
on 14 Aug 2019
(Coalescing the two reduces mental overhead for devs and reviewers)
stevekuznetsov
on 14 Aug 2019
Even with the pod_spec omitted, for large prow instances, the prowjobs format is over twice the size of the custom job format.
e.g. https://prow.k8s.io - 2019-08-28T22:46:13-07:00
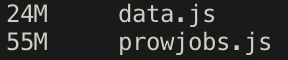
We should follow-up and omit additional fields that are both large and unused in the deck FE.
(e.g. metadata.annotations, metadata.labels, spec.decoration_config)
clarketm
on 29 Aug 2019
Why? What's the worry about size?
stevekuznetsov
on 29 Aug 2019
55 MB of javascript to _load a webpage_ is truly absurd.
 Katharine
on 29 Aug 2019
Katharine
on 29 Aug 2019
@stevekuznetsov - I have not run any benchmarks, but my primary concern is load time and the fact that most of the prowjob data is unused. Pagination is another option to reduce payload size but would require additional changes to FE.
clarketm
on 29 Aug 2019
We have metrics on load time for the page, let's use them. https://monitoring.prow.k8s.io/d/c27162ae7ad9ce08d2dcfa2d5ce7fee8/deck-dashboard?orgId=1
If we transparently hide fields I guess that's fine, or render server-side ... I think I'd prefer to see server-side endpoints for digested data over weird quasi-filled objects with nullable fields
stevekuznetsov
on 29 Aug 2019
The upshot is that the page will take about twice as long to load as it does today (having measured this on a very fast machine with a very fast internet connection, it adds an extra 1.5 seconds - if your machine parses JS slower or does not have gigabit internet, it will likely be worse), which I don't think is something I particularly want to ship.
Katharine
on 29 Aug 2019
We also never display all ~40k prowjobs to the user, so why not ask the backend for the last 100?
stevekuznetsov
on 29 Aug 2019
@stevekuznetsov - the most recent 500 get displayed in the table (when filters are not applied), but all jobs are added to the job histogram and can show if a filter is applied and table is redrawn (one that may have not been one of the most recent 500).
We could hit the deck backend and generate the results server-side on filter, but this is a design change on FE to make the api calls (which I am in favor of BTW but would require time). This could also unlock ability to paginate for calls that return over the threshold (e.g. 500).
clarketm
on 29 Aug 2019
@stevekuznetsov @Katharine
By also omitting metadata.annotations, metadata.labels, spec.decoration_config I can reduced the size significantly.
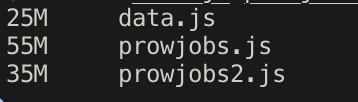
Note:
prowjobs2.jsomits the additional fields above.
clarketm
on 29 Aug 2019
I don't really know if it's _that_ useful to show the histogram and bar chart breakdown for _all_ jobs. Those are useful diagnostic tools once you filter but otherwise are just novel.
stevekuznetsov
on 29 Aug 2019
@stevekuznetsov - I agree with you regarding histogram ... but my second point was that if we only return 500 jobs on load, then the remaining n amount of jobs will not be known to the front-end; since filtering in the UI does not make an API call, but rather uses the allBuilds javascript requested onload, information will be lost on FE.
Currently, although 500 most recent jobs are shown onload. The other n jobs still exist to be uncovered via various filtering mechanisms on FE.
clarketm
on 29 Aug 2019
Right. I guess we could also just make more pointed requests to the backend -- pass along the filter options and do the filtering server-side. If we want to have 55M of data to work with we can't also hold it all in the front-end and work on it there. Will be faster in Go anyway ;)
stevekuznetsov
on 29 Aug 2019
I agree with you @stevekuznetsov that the filtering, sorting, punning can be better (and more robustly) handled server-side. The implementation on FE should be trivial; most of the effort will be server-side to build the API to accept additional parameters and properly munge this information. I can start a design for this and solicit feedback.
@Katharine
For now, if we want to move forward with prowjobs.js (#14126) we can omit the fields I list above (https://github.com/kubernetes/test-infra/issues/5216#issuecomment-526289836) (and more) to get a comparable payload size to the original.
clarketm
on 29 Aug 2019
@stevekuznetsov
Once #14254 and #14258 go through, you can close this issue. Also, please use your admin powers to edit the original issue and check the boxes.
clarketm
on 10 Sep 2019
Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle stale
fejta-bot
on 9 Dec 2019
Stale issues rot after 30d of inactivity.
Mark the issue as fresh with /remove-lifecycle rotten.
Rotten issues close after an additional 30d of inactivity.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle rotten
fejta-bot
on 8 Jan 2020
Rotten issues close after 30d of inactivity.
Reopen the issue with /reopen.
Mark the issue as fresh with /remove-lifecycle rotten.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/close
fejta-bot
on 7 Feb 2020
@fejta-bot: Closing this issue.
In response to this:
Rotten issues close after 30d of inactivity.
Reopen the issue with/reopen.
Mark the issue as fresh with/remove-lifecycle rotten.Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/close
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
 k8s-ci-robot
on 7 Feb 2020
k8s-ci-robot
on 7 Feb 2020
Related issues
 BenTheElder
·
3Comments
stevekuznetsov
·
3Comments
BenTheElder
·
3Comments
stevekuznetsov
·
3Comments
 zacharysarah
·
3Comments
stevekuznetsov
·
4Comments
spiffxp
·
3Comments
zacharysarah
·
3Comments
stevekuznetsov
·
4Comments
spiffxp
·
3Comments
Most helpful comment
I'm working on the sub task _Switch the JS to look at those._