Tesseract: Can't encode transcription
Environment
- Tesseract Version: tesseract alpha - 4.0.0
- Platform: Linux Ubuntu 16.04 LTS
Tesseract lstmtraining is used to train Korean language. The following error has occurred.
lstmtraining \
--model_config $HOME/work/kor/tuned/kortuned \
--continue_from $HOME/work/kor/tuned/kor.lstm \
--train_listfile $HOME/work/kor/config/kor.training_files.txt \
--target_error_rate 0.01 \
--max_iterations 1200
It seems that a compression error occurs in the following complex characters.
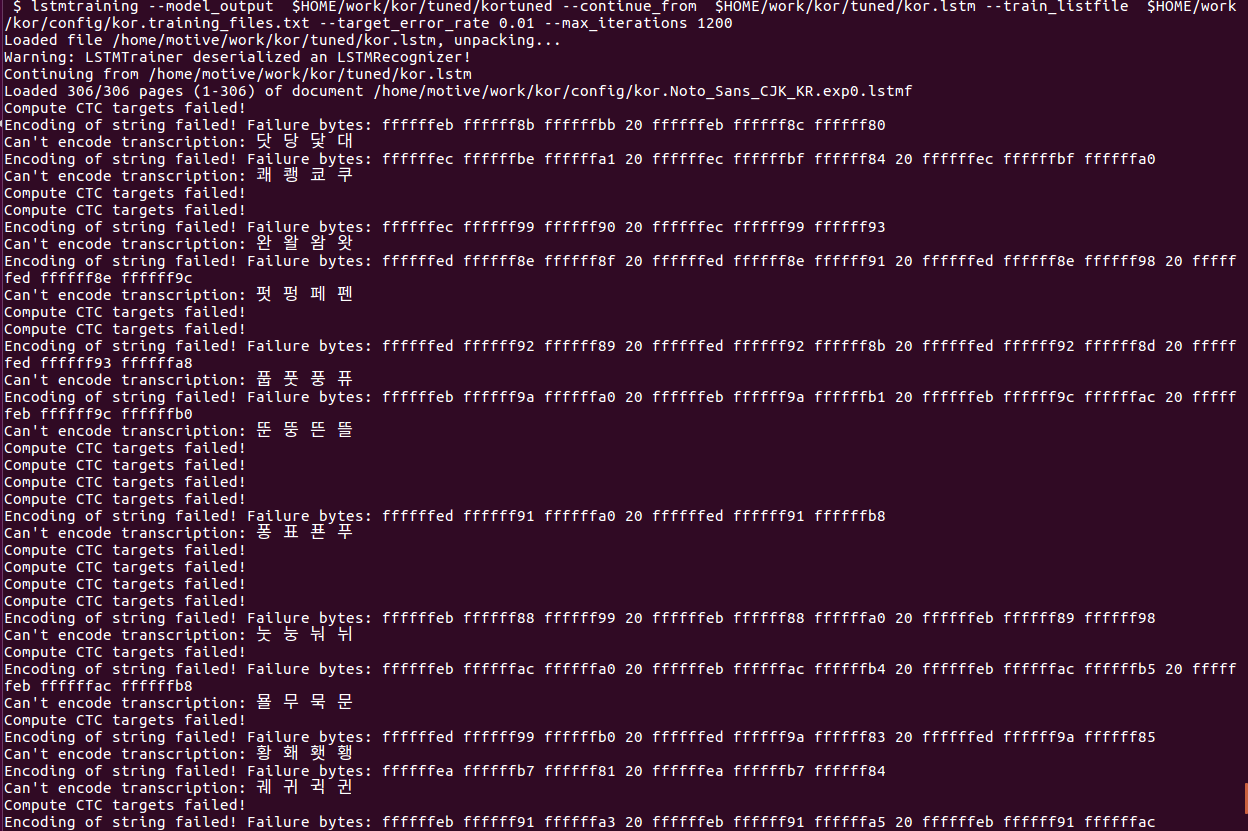
How do I resolve this issue?
Do I need to register for Korean unicharset?
 WhiteGom88
WhiteGom88
All 20 comments
I think this happens when the complex characters in your training text are not part of the original Korean Unicharset that the 4.00.00alpha kor.traineddata was trained with.
Do 'replace top layer' training instead of finetune. @abhishekchopde has had good results with it - see https://github.com/tesseract-ocr/tesseract/issues/1009
It will take longer than finetuning.
 Shreeshrii
on 29 Jun 2017
Shreeshrii
on 29 Jun 2017
also see
https://github.com/tesseract-ocr/tesseract/wiki/TrainingTesseract-4.00#error-messages-from-training
Shreeshrii
on 29 Jun 2017
Please also see same issue highlighted for Sinhala language.
https://groups.google.com/forum/?utm_medium=email&utm_source=footer#!msg/tesseract-ocr/jm0c0x38hXU/VOxoXLcBAQAJ
Shreeshrii
on 19 Jan 2018
@jbreiden I tested this just now with the latest code from github master branch. I tried finetune, plusminus as well as from scratch training for Sinhala. Please note that language name is coming as a blank.
Errors are similar to:
Can't encode transcription: 'සම්බන්ධයෙන් ෆෙඩරල් අනුකූලව -' in language ''
Recognition from both Sinhala and sin traineddata files in tessdata_best is working fine.
I do not know if this is related in anyway to the new validation/normalization rules for complex scripts.
Shreeshrii
on 19 Jan 2018
It seems that a compression error occurs in the following complex characters.
I am not able to reproduce the problem for Korean using the training_text in langdata. Since the original issue does not provide the error text (only an image) I cannot test with it.
However, error exists for Sinhala.
Shreeshrii
on 19 Jan 2018
Not reproducable for Korean with latest version
tesseract 4.0.0-beta.1
leptonica-1.76.0
libjpeg 8d (libjpeg-turbo 1.3.0) : libpng 1.2.50 : libtiff 4.0.3 : zlib 1.2.8
Found AVX
Found SSE
File /tmp/tmp.I5qtDeV6yp/kor/kor.Adobe_Myungjo_Std_Medium.exp0.lstmf page 83 :
Mean rms=0.835%, delta=1.958%, train=4.775%(17.12%), skip ratio=21.053%
Iteration 95: ALIGNED TRUTH : 된 올 , 짤방 찝찝 팝업 80 아팠던 그땐 1.0 고아읍 설정 1 키워드 위치
Iteration 95: BEST OCR TEXT : 된 을 , 짤방 찝찝 팝업 80 아팠던 그땐 1.0 고아읍 설정1 키워드 위치
File /tmp/tmp.I5qtDeV6yp/kor/kor.Arial_Unicode_MS.exp0.lstmf page 36 :
Mean rms=0.833%, delta=1.95%, train=4.76%(17.15%), skip ratio=20.833%
Iteration 96: ALIGNED TRUTH : 키워드 꽝 베어벡 의해 드립니다 그의 밧 절 기사 입찰 0.0
Iteration 96: BEST OCR TEXT : 키워드 꽝 베어벡 의해 드립니다 그의 밧 절 기사 입찰 0.0
File ./trained_plus_chars_kor/kor.Bitstream_CyberCJK.exp0.lstmf page 19 :
Mean rms=0.833%, delta=1.946%, train=4.711%(16.974%), skip ratio=20.619%
Image too small to scale!! (2x48 vs min width of 3)
Line cannot be recognized!!
Image not trainable
Iteration 97: ALIGNED TRUTH : 논의 해당 위해서는 리포트 하악 형 등 조직 웬만한 때 : 대학교
Iteration 97: BEST OCR TEXT : 논의 해당 위해서는 리포트 하악 형 등 조직 웬만한 때 : 대학교
File ./trained_plus_chars_kor/kor.UnBatang.exp0.lstmf page 19 (Perfect):
Mean rms=0.825%, delta=1.926%, train=4.663%(16.8%), skip ratio=21.429%
Iteration 98: ALIGNED TRUTH : 섀도우 2006 색깔 자유 08.08 모델 댄 수 괌섬 깃발 ' 엌 로 기타 평점
Iteration 98: BEST OCR TEXT : 새도우 2006 색깔 자유 08.08 모델 댄 수 괌섬 깃발'얼 로 기타 평점
File /tmp/tmp.I5qtDeV6yp/kor/kor.UnDotum.exp0.lstmf page 19 :
Mean rms=0.83%, delta=1.941%, train=4.685%(16.9%), skip ratio=21.212%
Iteration 99: ALIGNED TRUTH : 제출 솥뚜껑 팔 27 들이 년대 추천 처럼 몹 이 기간 나무 황후 ' 횟수
Iteration 99: BEST OCR TEXT : 제출 솔뚜껑 팔 27 들이 년대 추천 처럼 몹 이 기간 나무 황후' 횟수
File /tmp/tmp.I5qtDeV6yp/kor/kor.Adobe_Myungjo_Std_Medium.exp0.lstmf page 67 :
Mean rms=0.831%, delta=1.933%, train=4.672%(16.931%), skip ratio=21%
2 Percent improvement time=83, best error was 100 @ 0
At iteration 83/100/121, Mean rms=0.831%, delta=1.933%, char train=4.672%, word train=16.931%, skip ratio=21%,
New best char error = 4.672
Transitioned to stage 1
wrote best model:./trained_plus_chars_kor/pluschars4.672_83.checkpoint
wrote checkpoint.
@WhiteGom88 Were you able to resolve the issue?
Shreeshrii
on 30 Apr 2018
@WhiteGom88 @Shreeshrii
I also faced the same problem training for the uyghur language,later l find that some un-printable character (ascii code is 20 or 31) in the training text, I remove the character by follow python code , problem is missing.
import unicodedata, re
all_chars = (unichr(i) for i in xrange(0x110000))
control_chars = ''.join(c for c in all_chars if unicodedata.category(c) == 'Cc')
control_chars = ''.join(map(unichr, range(0,32) + range(127,160)))
control_char_re = re.compile('[%s]' % re.escape(control_chars))
def remove_control_chars(s):
return control_char_re.sub('', s)
 azmat21
on 29 May 2018
azmat21
on 29 May 2018
@azmat21 Thank you for the details.
@stweil Can this be added to text2image processing, to mark the control characters as unrenderable? Thanks.
Shreeshrii
on 29 May 2018
@Shreeshrii text lines which contains the Uyghur char ، (unicode is \u060c) is show the 'Can't encode transcript' error, but this char is also in unicharset file ,How do I resolve this issue?
azmat21
on 30 May 2018
@azmat21 Are you specifying it as RTL while training?
specify it while building the starter traineddata to give to lstm training.
combine_lang_model \
--input_unicharset $train_output_dir/$Lang.continue.unicharset \
--script_dir $langdata_dir \
--words $langdata_dir/$Lang/$Lang.wordlist \
--numbers $langdata_dir/$Lang/$Lang.numbers \
--puncs $langdata_dir/$Lang/$Lang.punc \
--output_dir $train_output_dir \
--lang_is_rtl \
--pass_through_recoder \
--lang $Lang \
--version_str ` cat $train_output_dir/$Lang.new.version`
This error happens with combining acute accent (U+0301).
Well-prepared texts (Slavic, specifically) contain them to disambiguate the meaning.
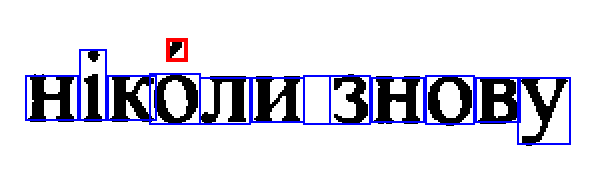
text2image does the job correctly:
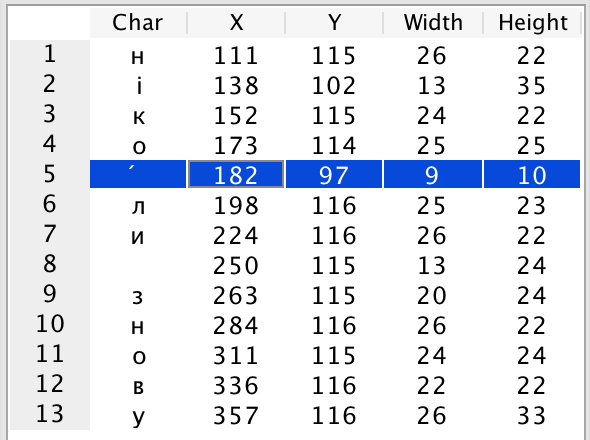
But during training, you get _Can't encode transcription_ followed by _Encoding of string failed!_ As the result, Tesseract is unable to recognize words containing accent.
Does anyone know a solution to make Tesseract work with accents? at least to recognize a “clean” letter underneath and ignore the mark itself.
(Built from github revision 72d8df581b315168c8f73a42ae74f733f9d018b9, Dec 16)
 msklvsk
on 18 Dec 2018
msklvsk
on 18 Dec 2018
Sorry to post problem here, but I have post the problem in tesseract-ocr forum, but it disappear, and the forum is inconvenient to read.
I encount this problem when I eval and finetune with traineddata from tessdata_best. It confused me for a few days.
I use tesstrain.sh to generate train and eval files as tutorial. When I execute lstmeval, it report the bug, can't encode transcription, encoding of string failed!
training/lstmeval --model ../tessdata/chi_sim.traineddata --eval_listfile ~/tessnew/chi_simeval/chi_sim.training_files.txt
note that the chi_sim.traineddata is wget from tessdata_best repository.

When I use combine_tessdata to extract recognition model from traineddata from tessdata_best repository, and then finetune it with train files generated with tesstrain.sh, it also report this bug.
After reading the above discussion, I know it might be the problem with unicharset. However, I don't know how to solve it. Can anyone helps me, it would be better if in details. Thanks.
 JisongXie
on 16 Aug 2019
JisongXie
on 16 Aug 2019
I get this error message for two text lines while training Fraktur from scratch, see https://github.com/OCR-D/ocrd-train/wiki/GT4HistOCR#encoding-failure. Commit 43b2e9513bfb57722ad00955f5adbb72d0c09430 fixes the byte formatting in the error message, but the encoding problem still needs a fix.
 stweil
on 17 Aug 2019
stweil
on 17 Aug 2019
Reproduce the problem using data from issue-1012.zip:
lstmtraining --traineddata test.traineddata --net_spec '[1,36,0,1 Ct3,3,16 Mp3,3 Lfys48 Lfx96 Lrx96 Lfx256 O1c5]' --learning_rate 20e-4 --train_listfile test.train --eval_listfile test.eval --max_iterations 1
The transcription ά cannot be encoded.
stweil
on 17 Aug 2019
I tried testing with the Fraktur string referenecd by you. I can also reproduce the error.
I added couple of spaces to the groundtruth text.
Encoding of string failed! Failure bytes: cc 81 20 cf b0 cf 87 ce b5 2c 20 e1 bc b8 ce b1 cf b0 cf 87 ce b5 21 20 57 69 65 20 62 6c 69 74 7a 65 6e 20 69 68 72 65 20 67 72 6f c3 9f 65 6e 20 41 75 67 65 6e 21 20 4e 6f 63 68
Can't encode transcription: 'Ἰ ά ϰχε, Ἰαϰχε! Wie blitzen ihre großen Augen! Noch' in language ''
The error in this case is for ́ 0x301 (cc 81 ). It might be related to normalization of the strings.
Is it possible that 0x301 is getting matched for 0x301D and 0x301E because of some truncation?
Shreeshrii
on 18 Aug 2019
@JisongXie I replied to your message in the forum - https://groups.google.com/forum/#!topic/tesseract-ocr/_NYCB3wZBww
I can successfully training from scratch and eval the output checkpoint. However, when I eval with the official provided traineddata, it fails. I am training with chinese simplified language.
The command is:
training/lstmeval --model ../tessdata/chi_sim.traineddata --eval_listfile ~/tessnew/chi_simeval/chi_sim.training_files.txt
the model is downloaded from tessdata_best, the eval_listfile is generated from tesstrain.sh as above.
The error is as follow:
Encoding of string failed! Failure bytes: ffffffe6 ffffffbc ffffffa9 ffffffe6 ffffffb6 ffffffa1 20 ffffffe6 ffffffa1 ffffff80 ffffffe9 ffffffaa ffffff9c 54 58 ffffffe5 ffffff90 ffffffaf ffffffe5 ffffff8a ffffffa8 2e ffffffe7 ffffffa7 ffffff8d ffffffe6 ffffffa4 ffffff8d ffffffe5 ffffff9d ffffff91 ffffffe9 ffffff81 ffffff93 30 33 20 ffffffe5 ffffff81 ffffff9a 20 ffffffe9 ffffff92 ffffff88 ffffffe7 ffffff81 ffffffb8 20 ffffffe9 ffffff81 ffffffad ffffffe6 ffffffae ffffff83 20 38 31 3b ffffffe8 ffffff80 ffffff81 ffffffe7 ffffff88 ffffffb7 ffffffe5 ffffff86 ffffff85 ffffffe5 ffffffae ffffffb9
Can't encode transcription: '啊时3全新跑送防伪漩涡 桀骜TX启动.种植坑道03 做 针灸 遭殃 81;老爷内容' in language ''
Encoding of string failed! Failure bytes: ffffffe8 ffffffb8 ffffff9d ffffffe5 ffffff8a ffffffa8 ffffffe6 ffffff80 ffffff81 20 ffffffe5 ffffff9e ffffff84 ffffffe6 ffffff96 ffffffad 31 ffffffe5 ffffff85 ffffffa8 ffffffe9 ffffff9d ffffffa2 34 20 ffffffe8 ffffff84 ffffff82 ffffffe8 ffffff82 ffffffaa 20 5b ffffffe9 ffffff80 ffffff89 ffffffe9 ffffffa1 ffffffb9 20 42 6f 6f 6b 6d 61 72 6b 20 3a ffffffe6 ffffffad ffffffa4 ffffffe5 ffffff9f ffffffba ffffffe7 ffffff9d ffffffa3 ffffffe5 ffffffbe ffffffb7 ffffffe6 ffffffba ffffff90 ffffffe7 ffffffa0 ffffff81 55 6e 69 76 65 72 73 69 74 79 20 ffffffe6 ffffffb3 ffffffb0 ffffffe9 ffffff93 ffffffa2 43 2b 2b
Since training from scratch works ok and error is only during eval of best traineddata, it means that official traineddata was not trained with some of the characters that are there in your training text.
One way to verify this is to use the combine_tessdata command with -u to unpack the files in it and look at the lstm-unicharset.
Shreeshrii
on 18 Aug 2019
The error in this case is for ́ 0x301 (cc 81 ). It might be related to normalization of the strings.
I could narrow down the problem to ά: a ground truth text which just contains that character also shows the problem.
stweil
on 18 Aug 2019
@Shreeshrii thanks very much! Yes, I have used combine_tessdata to extract lstm-unicharset file, and use tesstrain.sh to generate unicharset file from training text. The previous unicharset file has less char than my generated unicharset file.
However, it seems difficult to know which char is conflicted. The training text I get is from the official lang repository, I don't know why it can't work with official traineddata.
Maybe I should manually delete some chars in training text file?
Now I train just a few layers, it can work fluently.
JisongXie
on 19 Aug 2019
@stweil Should removal of unprintable control characters in training_text also be done as part of normalize.py? Please see https://github.com/tesseract-ocr/tesseract/issues/1012#issuecomment-392655885
Shreeshrii
on 12 Oct 2019
Related issues
 clarkk
·
6Comments
Shreeshrii
·
4Comments
clarkk
·
6Comments
Shreeshrii
·
4Comments
 duzenko
·
3Comments
duzenko
·
3Comments
 reubano
·
6Comments
reubano
·
6Comments
 eliyaz-kl
·
4Comments
eliyaz-kl
·
4Comments