Stockfish: Approval of useless/repetitive tests
I see this patch running on fishtest :
Tuned safechecks; 636, 785, 786, 1080
And this one :
Tuned safechecks; 636, 785, 787, 1080
This is perfectly ridiculous. Both are basically identical, and it's a waste of resources. The change to the original value is also tiny.
And there has already been a bunch of useless tune attempts of these parameters.
Such tests should not be approved blindly.
 Alayan-stk-2
Alayan-stk-2
All 5 comments
@lantonov I do agree with this statement, e.g. Tuned KAWhas been submitted >20 times with slight variations. A 0 Elo patch will pass both STC and LTC with quite a probability if 20 attempts are made. So, I suggest limiting the number of tries considerably.
Approvers indeed have a role there as well, (but I know from experience it easier to approve), nevertheless the main responsibility lies with the author.
 vondele
on 14 Apr 2020
vondele
on 14 Apr 2020
I agree that that this looks like trolling fishtest but I assure you that it is not just random guessing. I tune these values at home and check each combination before submitting with 1000 home games to have at least +15 Elo (with necessarily large error bars). I simply do not have enough resources to test more precisely at home.
Concretely for safechecks (and also KAW before that), tuning was with 500 game pairs for the test and the prior from the previous tests. In the below combination plot you see that there are many peaks close by not only on the integer values but also between them. From these I check the largest peak with 1000 games and only if it is > 15 Elo I submit it to fishtest. I attach here both the plot and the results from the tuning.
Anyway, if this work is not appreciated here, I will stop with these tests and direct my efforts to preparing and publishing the paper with my tuning methods.
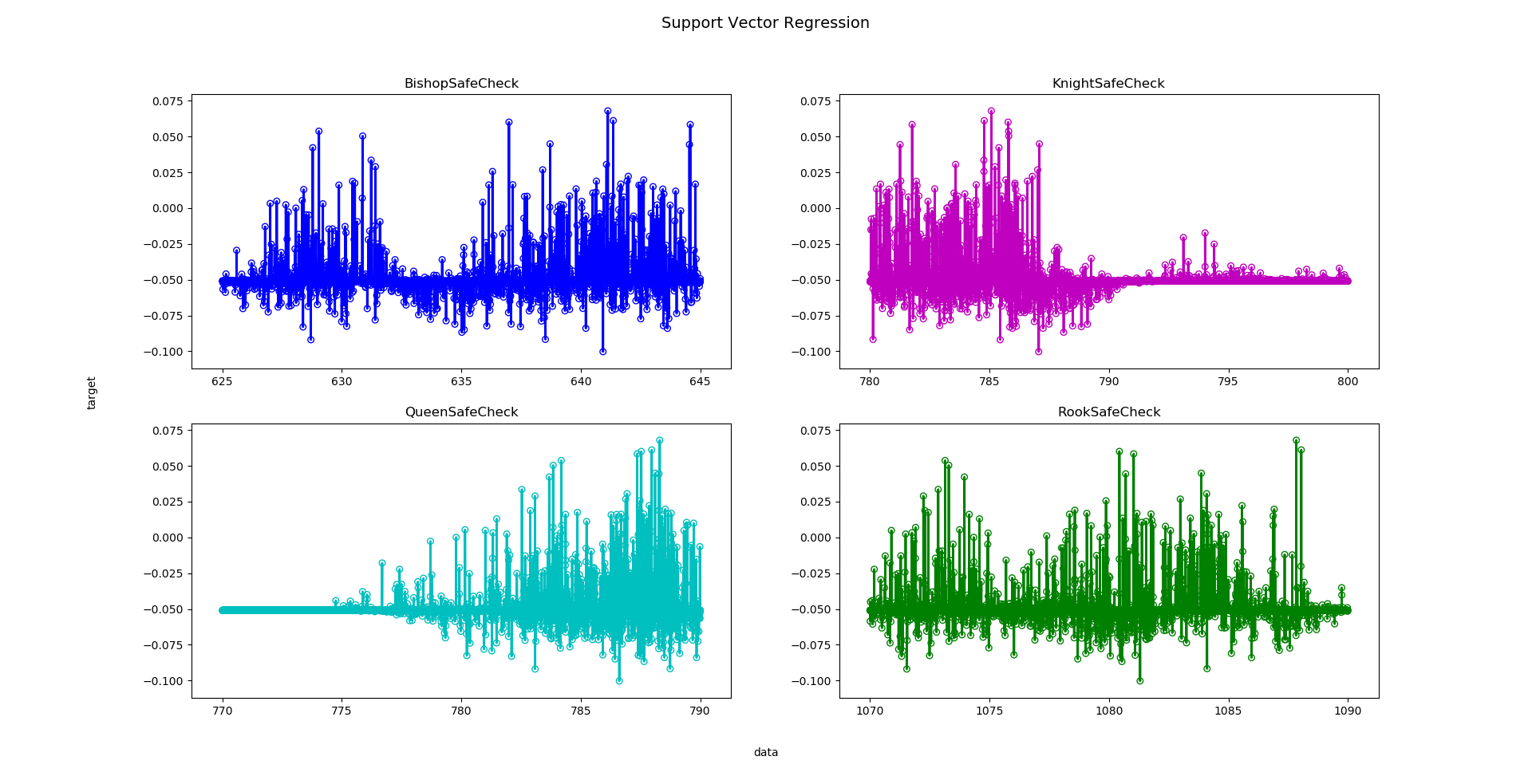
safechecks1.txt
 lantonov
on 14 Apr 2020
lantonov
on 14 Apr 2020
appreciation is unrelated to the concerns expressed here. I'm indeed very well aware that optimization of noisy objective functions is really hard (and interesting!), and that the resources needed to optimize parameters of SF are almost impossible to have at home. Nevertheless, the objective of fishtest should be to bring SF forward in the most efficient way possible. As such it is reasonable to question certain usage patterns on fishtest. Clearly, there is no problem from my point of view to test parameters on fishtest, but I'm asking to limit the number of attempts and to take care that different attempts vary parameters in a meaningful way.
I would be interested in having a wider range of optimizers available in fishtest, but I also appreciate that this is not so easy to do.
vondele
on 14 Apr 2020
I don't think that these tests are meaningless which is supported by the attached. However, you have the final word here and I have to comply.
lantonov
on 14 Apr 2020
The difference between these tests:
Tuned safechecks; 636, 785, 786, 1080
Tuned safechecks; 636, 785, 787, 1080
is indeed meaningless.
Even nicely developed statistical theories and good priors can not avoid dealing with the fact that most Elo gains by tuning a few parameters will be in the 0-2 Elo range, which needs >>1000 of games to measure.
So again, feel free to develop the methods, and test the outcome on fishtest, but with moderation.
I think we can close the issue.
vondele
on 14 Apr 2020
Related issues
 bftjoe
·
5Comments
bftjoe
·
5Comments
 Technologov
·
3Comments
Technologov
·
3Comments
 maelic13
·
3Comments
maelic13
·
3Comments
 niklasf
·
5Comments
niklasf
·
5Comments
 GBeauregard
·
7Comments
GBeauregard
·
7Comments
Most helpful comment
The difference between these tests:
is indeed meaningless.
Even nicely developed statistical theories and good priors can not avoid dealing with the fact that most Elo gains by tuning a few parameters will be in the 0-2 Elo range, which needs >>1000 of games to measure.
So again, feel free to develop the methods, and test the outcome on fishtest, but with moderation.
I think we can close the issue.