Stable-baselines: [Question] Stacked-LSTM worse than Single LSTM (PPO2)
Describe the Question
Hello,
I constructed Stacked-LSTM in CustomPolicy module and here’s the point that Stacked-LSTM may perform better than Single LSTM reasonably but we got the exactly opposite result (Stacked-LSTM worse than Single LSTM) in our experiment with many times. The following were the details:
- Params
Params
num_env: 1
nminibatches: 1
lr: 2.5e-4
num_timesteps: 1000000
RL ALGORITHMS : PPO2
- Single LSTM(parameter_list)
'model/pi_fc0/w:0' shape=(8, 64)
'model/pi_fc0/b:0' shape=(64,)
'model/pi_fc1/w:0' shape=(64, 64)
'model/pi_fc1/b:0' shape=(64,)
'model/rnn1/wx:0' shape=(64, 1024)
'model/rnn1/wh:0' shape=(256, 1024)
'model/rnn1/b:0' shape=(1024,)
'model/vf/w:0' shape=(256, 1)
'model/vf/b:0' shape=(1,)
'model/pi/w:0' shape=(256, 4)
'model/pi/b:0' shape=(4,)
'model/q/w:0' shape=(256, 4)
'model/q/b:0' shape=(4,) - Stacked LSTM(parameter_list)
'model/pi_fc0/w:0' shape=(8, 64)
'model/pi_fc0/b:0' shape=(64,)
'model/pi_fc1/w:0' shape=(64, 64)
'model/pi_fc1/b:0' shape=(64,)
'model/rnn1/wx:0' shape=(64, 1024)
‘model/rnn1/wh:0' shape=(256, 1024)
'model/rnn1/b:0' shape=(1024,)
'model/rnn2/wx:0' shape=(256, 1024)
'model/rnn2/wh:0' shape=(256, 1024)
'model/rnn2/b:0' shape=(1024,)
'model/vf/w:0' shape=(256, 1)
'model/vf/b:0' shape=(1,)
'model/pi/w:0' shape=(256, 4)
'model/pi/b:0' shape=(4,)
'model/q/w:0' shape=(256, 4)
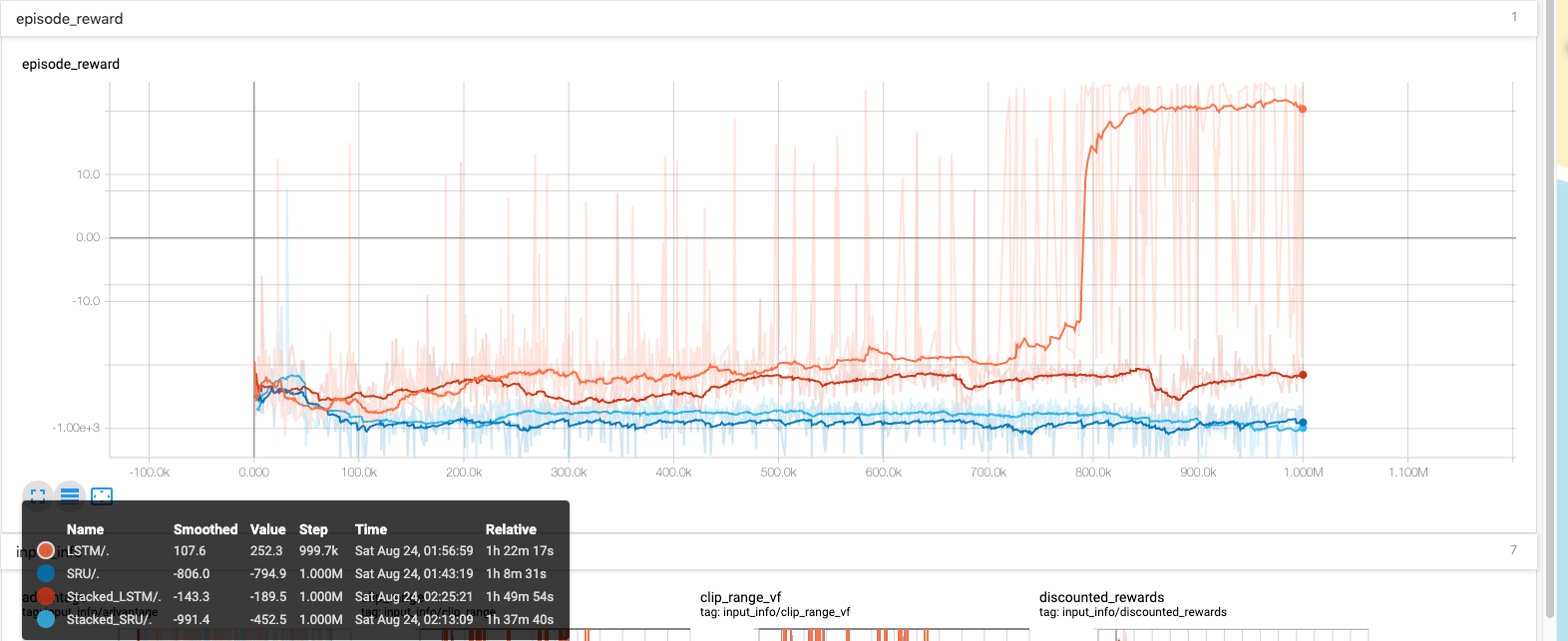
'model/q/b:0' shape=(4,) Stacked-LSTM vs Single LSTM(Benchmark on LunarLander-v2)
Stacked-LSTM
Code example
class CustomRNNPolicy(RecurrentActorCriticPolicy):
recurrent = True
def __init__(self, sess, ob_space, ac_space, n_env, n_steps, n_batch, n_lstm=256, reuse=False, layers=None,
net_arch=None, act_fun=tf.tanh, cnn_extractor=nature_cnn, layer_norm=False, feature_extraction="mlp",**kwargs):
super(CustomRNNPolicy, self).__init__(sess, ob_space, ac_space, n_env, n_steps, n_batch,
state_shape=(2 * n_lstm, ), reuse=reuse,
scale=(feature_extraction == "cnn"))
self._kwargs_check(feature_extraction, kwargs)
if net_arch is None: # Legacy mode
if layers is None:
layers = [64, 64]
else:
warnings.warn("The layers parameter is deprecated. Use the net_arch parameter instead.")
with tf.variable_scope("model", reuse=reuse):
if feature_extraction == "cnn":
extracted_features = cnn_extractor(self.processed_obs, **kwargs)
else:
extracted_features = tf.layers.flatten(self.processed_obs)
for i, layer_size in enumerate(layers):
extracted_features = act_fun(linear(extracted_features, 'pi_fc' + str(i), n_hidden=layer_size,
init_scale=np.sqrt(2)))
input_sequence = batch_to_seq(extracted_features, self.n_env, n_steps)
masks = batch_to_seq(self.dones_ph, self.n_env, n_steps)
if name == 'SRU':
rnn_output, self.snew = sru_opt(input_sequence, masks ,self.states_ph , 'rnn1', n_hidden=n_lstm,layer_norm=layer_norm)
elif name == 'Stacked_SRU':
rnn_out, _ = sru_opt(input_sequence, masks, self.states_ph, 'rnn1', n_hidden=n_lstm,layer_norm=layer_norm)
rnn_output, self.snew = sru_opt(rnn_out, masks, self.states_ph, 'rnn2', n_hidden=n_lstm, layer_norm=layer_norm)
elif name == 'LSTM':
rnn_output, self.snew = lstm(input_sequence, masks ,self.states_ph, 'rnn1', n_hidden=n_lstm,layer_norm=layer_norm)
elif name == 'Stacked_LSTM':
rnn_out, _ = lstm(input_sequence, masks ,self.states_ph, 'rnn1', n_hidden=n_lstm,layer_norm=layer_norm)
rnn_output, self.snew = lstm(rnn_out, masks ,self.states_ph, 'rnn2', n_hidden=n_lstm,layer_norm=layer_norm)
else:
pass
rnn_output = seq_to_batch(rnn_output)
value_fn = linear(rnn_output, 'vf', 1)
self._proba_distribution, self._policy, self.q_value = \
self.pdtype.proba_distribution_from_latent(rnn_output, rnn_output)
self._value_fn = value_fn
else: # Use the new net_arch parameter
......
self._setup_init()
def step(self, obs, state=None, mask=None, deterministic=False):
if deterministic:
return self.sess.run([self.deterministic_action, self.value_flat, self.snew, self.neglogp],
{self.obs_ph: obs, self.states_ph: state, self.dones_ph: mask})
else:
return self.sess.run([self.action, self.value_flat, self.snew, self.neglogp],
{self.obs_ph: obs, self.states_ph: state, self.dones_ph: mask})
def proba_step(self, obs, state=None, mask=None):
return self.sess.run(self.policy_proba, {self.obs_ph: obs, self.states_ph: state, self.dones_ph: mask})
def value(self, obs, state=None, mask=None):
return self.sess.run(self.value_flat, {self.obs_ph: obs, self.states_ph: state, self.dones_ph: mask})
name = 'Stacked_LSTM'
env = DummyVecEnv([lambda: gym.make('LunarLander-v2')])
model = PPO2(CustomRNNPolicy, env, verbose=1, tensorboard_log='./tensorboard/', nminibatches=1)
model.learn(1e6)
System Info
Describe the characteristic of your environment:
- Describe how the library was installed (pip, docker, source, ...)
- Python version : 3.5.6
- Tensorflow version : 1.12.0
- stable-baselines : 2.7.0
Looking forward to your kindly reply , thank you.
@araffin
@hill-a
Sincerely ,
RonaldJEN
 RonaldJEN
RonaldJEN
All 9 comments
Are there previous results on Stacked-LSTM working better than regular LSTM in this specific environment (LunarLander)? With reinforcement learning, larger model does not necessarily mean better performance and sometimes can be even worse performance (e.g. ResNet with batchnorm does not work well with RL), so unless there are previous results on this I would not be surprised if more complicated model does not work well.
 Miffyli
on 26 Aug 2019
Miffyli
on 26 Aug 2019
Are there previous results on Stacked-LSTM working better than regular LSTM in this specific environment (LunarLander)? With reinforcement learning, larger model does not necessarily mean better performance and sometimes can be even worse performance (e.g. ResNet with batchnorm does not work well with RL), so unless there are previous results on this I would not be surprised if more complicated model does not work well.
Yeah, I think the point you mentioned was about the mindset between simple and complicated method applying in RL. Thank for your feedback.
On the other side, as the part of the Stacked LSTM, is there any problems with my coding? I'm concerned about the valid of the result even though I ran successfully with my code.
RonaldJEN
on 26 Aug 2019
Sorry for not looking at the code before, but now I see one part that could be a big mistake:
elif name == 'Stacked_LSTM':
rnn_out, _ = lstm(input_sequence, masks ,self.states_ph, 'rnn1', n_hidden=n_lstm,layer_norm=layer_norm)
rnn_output, self.snew = lstm(rnn_out, masks ,self.states_ph, 'rnn2', n_hidden=n_lstm,layer_norm=layer_norm)
You are feeding self.states_ph to both lstm layers (i.e. the same hidden state to both LSTMs). If this is standard "multiple LSTM layers" approach, then you want to have two separate hidden states, one for each LSTM layer.
Generally, this is the fun part of RL/ML research: Implementing something that runs without errors, but you still can not be sure if it the computations are correct. For this reason I recommend trying your implementation in experiments that have been done by others. This way you can compare your results to others. Once you get these similar returns, move onto new experiments.
Miffyli
on 26 Aug 2019
hi @Miffyli , thank for your detail explanation. Based on your opinion (it also matched what I think as you), here's a further question: which solution in the second LSTM layer is correct?
1.combine with rnn_output and cell hidden_state from the previous layer
rnn_out, cell_hidden_state = lstm(input_sequence, masks ,self.states_ph, 'rnn1', n_hidden=n_lstm,layer_norm=layer_norm)
rnn_output, self.snew = lstm(rnn_out, masks , cell_hidden_state, 'rnn2', n_hidden=n_lstm,layer_norm=layer_norm)
- initial self.states_ph
rnn_out, _ = lstm(input_sequence, masks ,self.states_ph, 'rnn1', n_hidden=n_lstm,layer_norm=layer_norm)
rnn_output, self.snew = lstm(rnn_out, masks ,self.states_ph, 'rnn2', n_hidden=n_lstm,layer_norm=layer_norm)
I tend to choose the latter one because the flow chart , so hope someone here could solve my problems.
RonaldJEN
on 26 Aug 2019
I am sorry to say neither are correct: In 1) you are mixing hidden states together, and in 2) you are not updating the hidden state (which is essential part of recurrent networks, as this carries the information between activations). Try backtracking what the self.states_ph contains (e.g. check the step function and what is fed in there etc.)
The solution requires tracking two completely separate states. However the underlying code only supports one variable (the state in step function). You'd have to figure out including both LSTM states in this variable, and then separating them into separate states for two LSTM layers.
Do note that even higher end papers with large RL models (e.g. Deepmind IMPALA) do not use more than one LSTM layer. Deepmind CTF paper has multiple layers of LSTM but with more complicated model (different LSTM layers run at different rates).
Miffyli
on 26 Aug 2019
Thank for your answer . I will try to research it in this weeks.
RonaldJEN
on 26 Aug 2019
@RonaldJEN any luck on how to properly stack lstm ?
 junhuang-ifast
on 17 Oct 2019
junhuang-ifast
on 17 Oct 2019
Does it works? @RonaldJEN
 asdfqwer2015
on 3 Feb 2020
asdfqwer2015
on 3 Feb 2020
Hi,
In case of single LSTM, your Episodic reward increases all of a sudden at a particular step. Have you consistently got this plot for different seed values? This seems to be a one off case of getting good initializers.
Also, training Multi-stacked LSTM _could_ possibly take more steps to learn due to more number of trainable parameters than single layer LSTM. So, you will have to train for more steps for multi layer lstm to be conclusive about your results.(which introduces extra toll as higher chances of vanishing/exploding gradient.)
 Siddhant7
on 18 Apr 2020
Siddhant7
on 18 Apr 2020
Related issues
 H2SO4T
·
3Comments
H2SO4T
·
3Comments
 saeid93
·
3Comments
saeid93
·
3Comments
 ktattan
·
3Comments
ktattan
·
3Comments
ktattan
·
3Comments
ktattan
·
3Comments
 pirobot
·
3Comments
pirobot
·
3Comments
Most helpful comment
I am sorry to say neither are correct: In 1) you are mixing hidden states together, and in 2) you are not updating the hidden state (which is essential part of recurrent networks, as this carries the information between activations). Try backtracking what the
self.states_phcontains (e.g. check thestepfunction and what is fed in there etc.)The solution requires tracking two completely separate states. However the underlying code only supports one variable (the
stateinstepfunction). You'd have to figure out including both LSTM states in this variable, and then separating them into separate states for two LSTM layers.Do note that even higher end papers with large RL models (e.g. Deepmind IMPALA) do not use more than one LSTM layer. Deepmind CTF paper has multiple layers of LSTM but with more complicated model (different LSTM layers run at different rates).