/area autoscale
/kind dev
/assign @josephburnett
The default Elafros autoscaling strategy is based on concurrent requests and the set point is hardcoded at 1.0. We need to connect scaling to actual resource usage (CPU and memory). One way we can do that is to use Vertical Pod Autoscaling to adjust the resource requests of a revision to just what's needed to serve 1 request concurrently.
 josephburnett
josephburnett
All 6 comments
I did some initial testing with vertical pod autoscaling (vpa) on an Elafros revision.
Test Conditions
The test was run on a 3x 32-core node GKE cluster. The revision was a cpu-bound workload which calculates the largest prime less than 10 million (about 1/2 cpu second per request). The initial cpu request size was 2000m (2 cpus/pod).
I started with 100 qps and waited for the vpa to narrow in on its recommendation. Then I increased the qps to 200 for 5 minutes. And then dropped qps back to 100. The entire test duration was 20 minutes.
Results
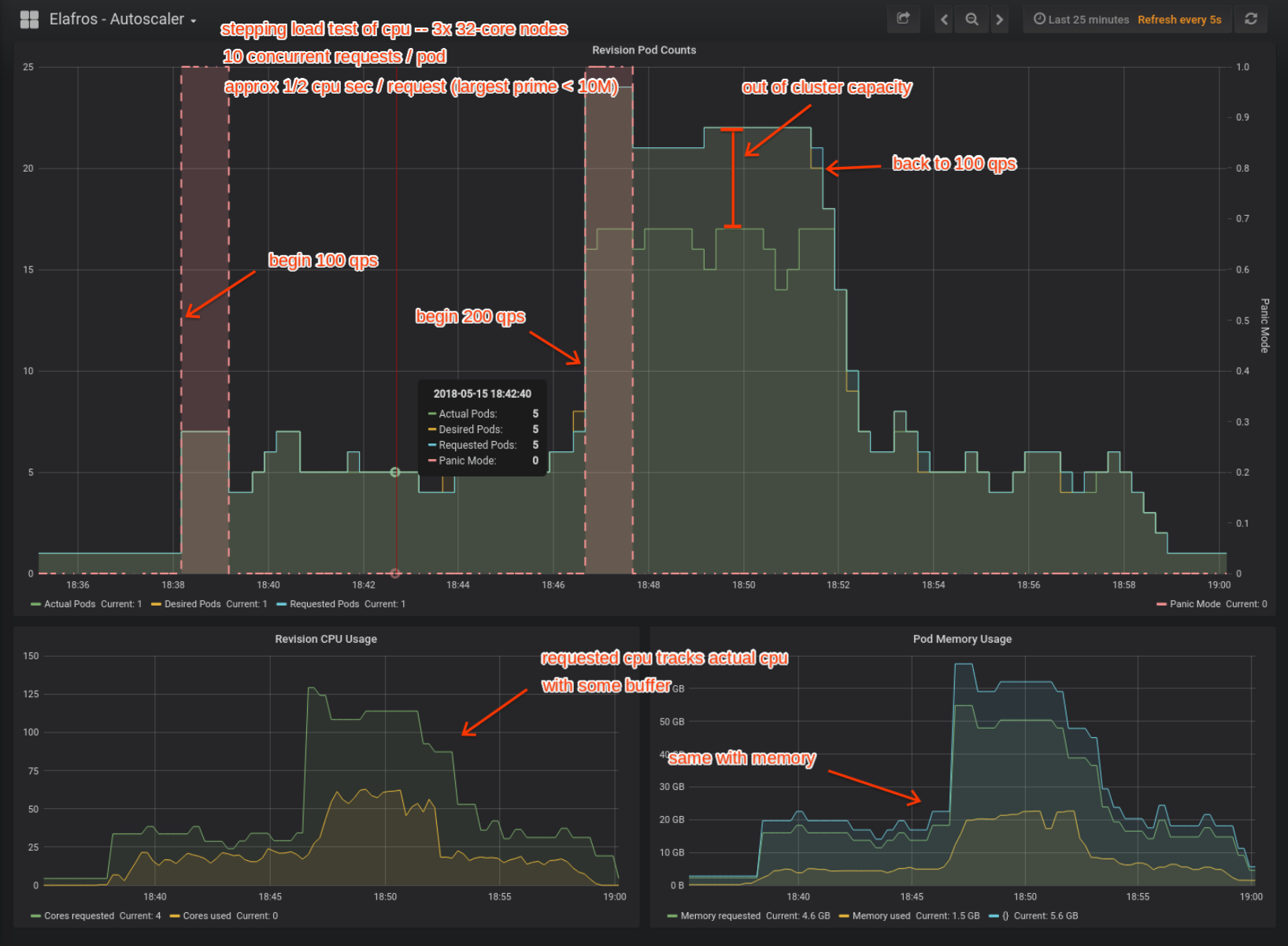
When qps was increased to 200, the desired pod count roughly doubled, which is normal behavior by the Elafros autoscaler. However the cluster did not have enough capacity to schedule all requested pods (17/22). As a result, each scheduled pod was doing slightly more work during the 200 qps period.
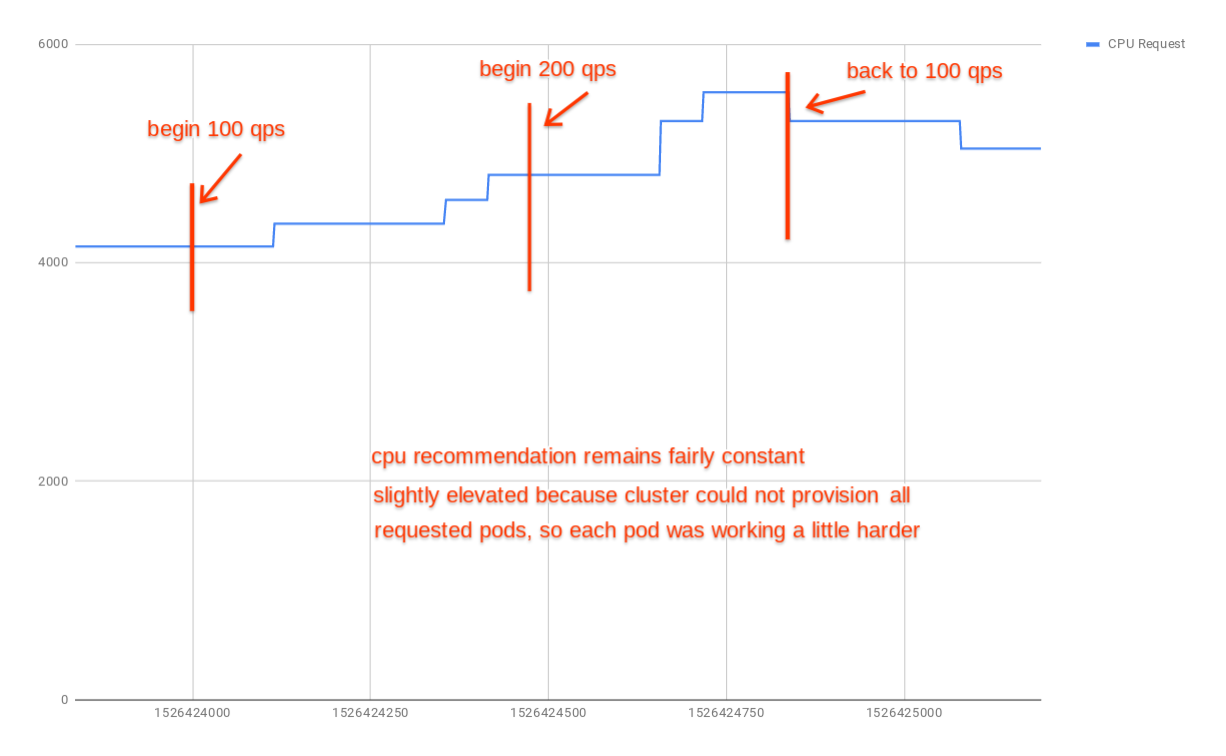
The vpa settled on an initial recommendation of 4151m (~4 cpus/pod). When qps increased to 200, the recommendation increased to 5563m (~5.5 cpus/pod). After the load returned to 100 qps, the recommendation dropped to 5046m (~5 cpus/pod). Some time later, when the revision was idle, the recommendation returned to 4151m.
Conclusions
Vertical pod autoscaling seems stable with horizontal pod autoscaling (the Elafros autoscaler). It is able to increase and decrease cpu recommendations to match the workload. Note: the Elafros autoscaler and the vpa use different signals for autoscaling (request concurrency and cpu usage respectively) which likely accounts for their playing nicely together.
However increasing recommendations and pod sizes causes fragmentation of schedulable cpu space (especially in smaller node sizes such as 8-cores). With fragmentation, fewer pods can be scheduled and the load on each scheduled pod increases. This may lead to increased recommendations again, in a loop.
(raw data)
josephburnett
on 16 May 2018
@josephburnett great test setup!
I think it would also be very interesting to see the total execution time for each calculation and plot it -- are you tracking that data?
 mbehrendt
on 16 May 2018
mbehrendt
on 16 May 2018
@mbehrendt, I can easily get that data by turning on Istio sidecar injection. Then per-revision qps, latency and error rates will show up in Grafana (where I got the autoscaler graphs).
josephburnett
on 16 May 2018
There are a few other test scenarios I want to test out as well:
- Testing with a memory bound process.
- Testing with changing request loads. E.g. instead of increasing QPS, increase the "weight" of each request to see if I get comparable behavior.
- Testing the OOM detection capabilities of VPA. E.g. launch a 4GB JVM with only 2GB available and verify it is able to stabilize above 4GB.
One thing I noticed is that the VPA will never recommmend less than 350m cpu per container (1 cpu/pod). Currently we start with 500m cpu/pod, so VPA is always going up. I had to increase the starting cpu request to 2000m to verify decreasing recommendations. I want to do some more testing around this.
josephburnett
on 16 May 2018
/milestone Ice Box
 k4leung4
on 20 Feb 2019
k4leung4
on 20 Feb 2019
I've opened a separate issue to track the beta implementation of this feature with some improvements: https://github.com/knative/serving/issues/2929
josephburnett
on 8 Mar 2019
Related issues
 alexnederlof
·
5Comments
alexnederlof
·
5Comments
 scothis
·
3Comments
scothis
·
3Comments
 evankanderson
·
3Comments
evankanderson
·
3Comments
 ZhiminXiang
·
3Comments
ZhiminXiang
·
3Comments
 xpepermint
·
6Comments
xpepermint
·
6Comments
Most helpful comment
I did some initial testing with vertical pod autoscaling (vpa) on an Elafros revision.
Test Conditions
The test was run on a 3x 32-core node GKE cluster. The revision was a cpu-bound workload which calculates the largest prime less than 10 million (about 1/2 cpu second per request). The initial cpu request size was 2000m (2 cpus/pod).
I started with 100 qps and waited for the vpa to narrow in on its recommendation. Then I increased the qps to 200 for 5 minutes. And then dropped qps back to 100. The entire test duration was 20 minutes.
Results
When qps was increased to 200, the desired pod count roughly doubled, which is normal behavior by the Elafros autoscaler. However the cluster did not have enough capacity to schedule all requested pods (17/22). As a result, each scheduled pod was doing slightly more work during the 200 qps period.
The vpa settled on an initial recommendation of 4151m (~4 cpus/pod). When qps increased to 200, the recommendation increased to 5563m (~5.5 cpus/pod). After the load returned to 100 qps, the recommendation dropped to 5046m (~5 cpus/pod). Some time later, when the revision was idle, the recommendation returned to 4151m.
Conclusions
Vertical pod autoscaling seems stable with horizontal pod autoscaling (the Elafros autoscaler). It is able to increase and decrease cpu recommendations to match the workload. Note: the Elafros autoscaler and the vpa use different signals for autoscaling (request concurrency and cpu usage respectively) which likely accounts for their playing nicely together.
However increasing recommendations and pod sizes causes fragmentation of schedulable cpu space (especially in smaller node sizes such as 8-cores). With fragmentation, fewer pods can be scheduled and the load on each scheduled pod increases. This may lead to increased recommendations again, in a loop.
(raw data)