Scylla: Aggressive compactions after upgrading to 4.1.2
This is Scylla's bug tracker, to be used for reporting bugs only.
If you have a question about Scylla, and not a bug, please ask it in
our mailing-list at [email protected] or in our slack channel.
- [*] I have read the disclaimer above, and I am reporting a suspected malfunction in Scylla.
Installation details
Scylla version (or git commit hash): 4.1.2
Cluster size: 9 nodes
OS (RHEL/CentOS/Ubuntu/AWS AMI): C7.5
Hardware details (for performance issues)
Hardware: sockets=2 x Intel(R) Xeon(R) Gold 6230 CPU @ 2.10GHz cores=40 hyperthreading=yes memory= 6x32GB DDR4 2666MHz
Disks: RAID 10 of 10HDDs 14TB each for data, RAID 1 SSD 1TB for clogs
After updating 4.0.3 => 4.1.2 all the nodes started compacting aggressively and have been doing so for ~5 days. It affects both write and read performance crucially: 1-5% percent of requests time out, high percentile read latencies went ~10 times higher. Usually during weekly compactions we do not experience such a big performance degradation.
Why did it start compacting that much? What can we do to mitigate compactions effect on read/write performance?
Compaction strategy: TWCS, 1 week window
Scheme: https://pastebin.com/VCXM2H18
Logs: https://transfer.sh/I2RfD/scylla_log.tar.gz (filtered out "Writing large ..." messages)
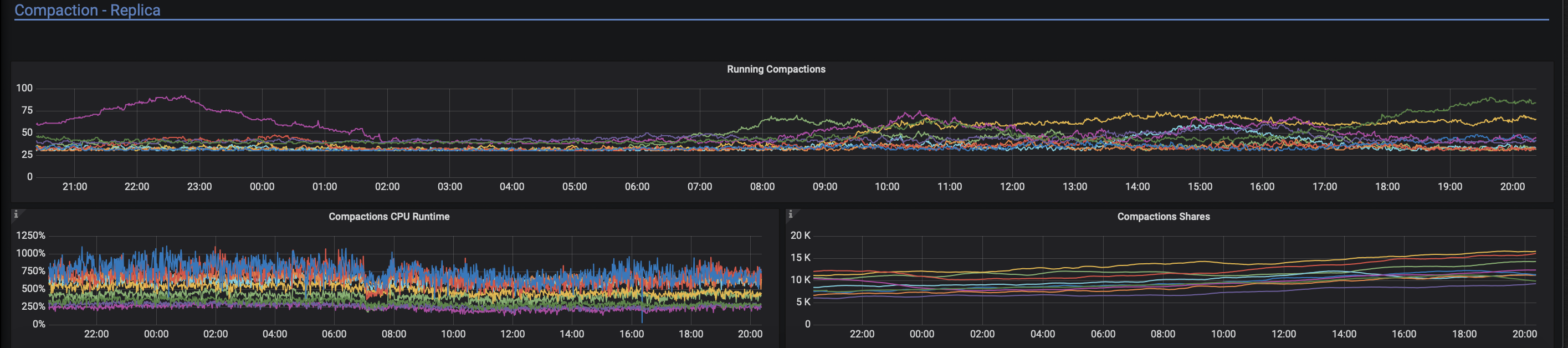
Some screens (yellow node performs much worse probably because we tried tweaking IO bandwidth settings there):
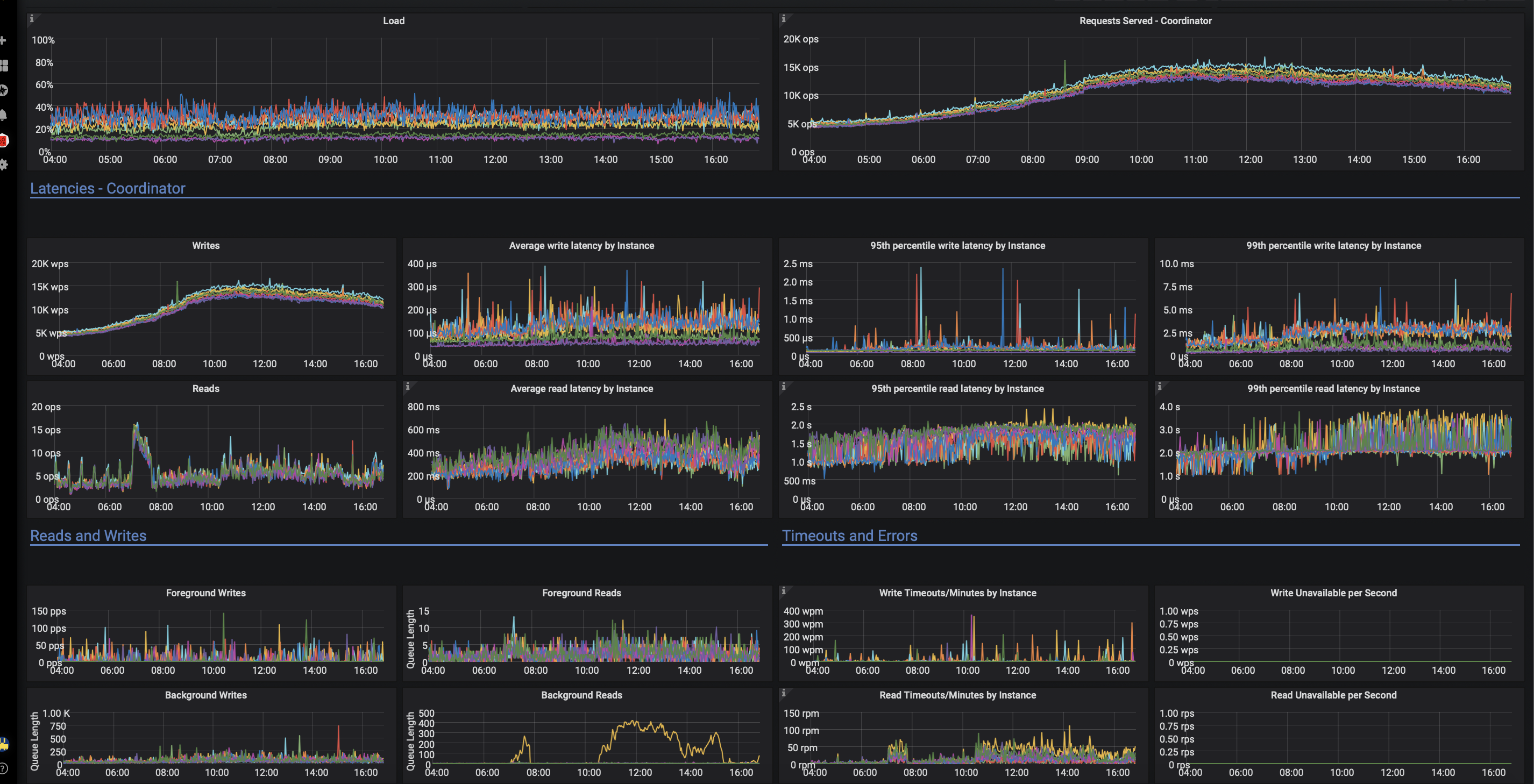
:
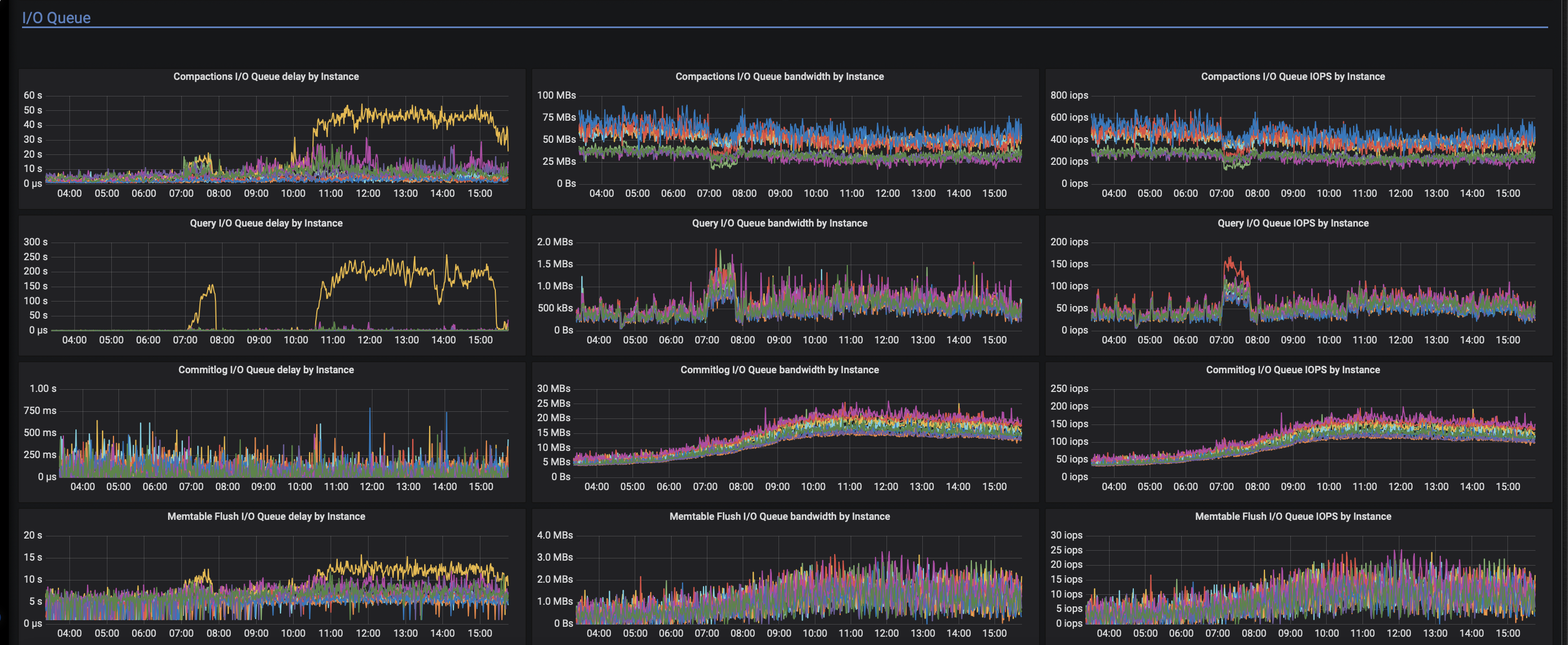
 gibsn
gibsn
All 38 comments
I checked the logs
One thing that is visible is that
- Compaction on 4.0.3 --> generated one sstable
- Compaction on 4.1.2 --> at times generates multiple sstables
[shard 34] compaction - Compacted 2 sstables to [/storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-563270-big-Data.db:level=0, /storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-563308-big-Data.db:level=0, /storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-563346-big-Data.db:level=0, /storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-563384-big-Data.db:level=0, /storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-563422-big-Data.db:level=0, ]. 4391560346 bytes to 4394850863 (~100% of original) in 1967986ms = 2.13MB/s. ~940416 total partitions merged to 988401.
/mnt/maillogs/beccasc8/scylla.log-2020.07.23-18:2020-07-23T17:43:50.380942+03:00 beccasc8 scylla:
[shard 18] compaction - Compacted 2 sstables to [/storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-562038-big-Data.db:level=0, /storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-562076-big-Data.db:level=0, /storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-562114-big-Data.db:level=0, /storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-562152-big-Data.db:level=0, /storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-562190-big-Data.db:level=0, /storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-562228-big-Data.db:level=0, /storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-562304-big-Data.db:level=0, ]. 4475033048 bytes to 4477155872 (~100% of original) in 2591534ms = 1.65MB/s. ~944128 total partitions merged to 987114.
/mnt/maillogs/beccasc8/scylla.log-2020.07.23-18:2020-07-23T17:45:16.029186+03:00 beccasc8 scylla:
[shard 22] compaction - Compacted 2 sstables to [/storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-568692-big-Data.db:level=0, /storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-568730-big-Data.db:level=0, /storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-568768-big-Data.db:level=0, /storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-568806-big-Data.db:level=0, /storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-568844-big-Data.db:level=0, /storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-568920-big-Data.db:level=0, /storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-568958-big-Data.db:level=0, ]. 4388920947 bytes to 4389582116 (~100% of original) in 2526142ms = 1.66MB/s. ~941824 total partitions merged to 970432.
and those are compacted again with others
/mnt/maillogs/beccasc8/scylla.log-2020.07.23-21:2020-07-23T20:01:27.109829+03:00 beccasc8 scylla: [shard 22] compaction - Compacting [/storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-568730-big-Data.db:level=0, /storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-558356-big-Data.db:level=0, ]
/mnt/maillogs/beccasc8/scylla.log-2020.07.26-09:2020-07-26T08:19:23.075160+03:00 beccasc8 scylla: [shard 22] compaction - Compacting [/storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-573784-big-Data.db:level=0, /storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-572568-big-Data.db:level=0, /storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-568920-big-Data.db:level=0, /storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-569376-big-Data.db:level=0, /storage/scylla/becca/events-5da3ae90ef4911e9a503000000000004/mc-570478-big-Data.db:level=0, ]
.
.
So that seems to indicate that in compaction of TWCS we are splitting into windows (like we should) but for some reason - we are not compacting only the last up window (or at least possibly not doing that).
Please note the window is very large 7 days.
@raphaelsc - is that clear to you in some manner will TWCS split files into uints smaller than the window / compact old windows than the first (active) one.
 slivne
on 28 Jul 2020
slivne
on 28 Jul 2020
thanks for the analysis @slivne.
That's happening because TWCS wants to limit each window other than the last one to just 1 SSTable. For example, TWCS does STCS on the last window until it closes, and thereafter TWCS makes sure that it has a single SSTable.
After data segregation, compaction may now generate a SSTable that will be pushed to older windows, causing them to have more than 1 SSTable. As a result, compaction will be triggered for them.
This is probably causing lots of write amplification. Because the single relatively-big SSTable that was previously alone now will have to be compacted again whenever a new SSTable comes in as a result of data segregation. Adding a WA of 1 for this particular window whenever this happens.
That's probably too expensive, but we shouldn't let the older windows accumulate in # of SSTables too.
I can think of two options to make this whole thing less aggressive when data segregation pushes a new SSTable to an older window that only had a single SSTable:
1) Apply min threshold to older windows, so compact everything together if # of SSTables is > min threshold. Now in worst case # of sstables can be (# of windows * (min threshold - 1))
2) If data segregation pushed data to an old window, we'll do STCS in that old window to avoid the write amplification, and only when the window of the last (current) window closes, we'd look for all windows (last and older ones) that have more than 1 SSTable and limit them to one. I like this approach.
@avikivity @slivne
 raphaelsc
on 28 Jul 2020
raphaelsc
on 28 Jul 2020
@raphaelsc thanks for explanation
In our case weekly single SSTables are ~20GB big. Looks like one read repair could cause the whole 20GB being rewritten for just one partition, and then again and again. We took TWCS because it provided significantly lower WA. We never intentionally write to the past and reads from the past are quite rare so TWCS was a really good choice for us, once compacted those big SSTables should have never been rewritten. Now we do not have that advantage anymore, our production reads suffer and we can not rollback to 4.1 :(
I think that maybe it is ok to do minor compactions on small SSTables with old data but you should not compact automatically small SSTables with large ones. IMHO one can always call nodetool compact if they think they really need to have single SSTables per window and know what that's gonna cost
gibsn
on 28 Jul 2020
@gibsn The # of SSTables in each window is important because of read amplification, which affects latency. Your latency is being hurt due to the significant increase in WA (write amplification), which cause the disk to be dominated by writes. My idea is that we do STCS on older windows, that received new data as a result of this data segregation feature, given that STCS is really low in terms of WA. Additionally, I suggested that we do a kind of "major compaction" when the current window closes on all windows that have more than 1 SSTable, to prevent the # of SSTables in the system from growing unboundly as that can hurt read latency and cause the node to run out of memory. But perhaps this last step we should make it optional via a property, to satisfy all users.
raphaelsc
on 28 Jul 2020
But perhaps this last step we should make it optional via a property, to satisfy all users.
If you could provide some config param that would be ok for us. What can we do now to regain read latencies we had before upgrading?
I suggested that we do a kind of "major compaction" when the current window closes on all windows that have more than 1 SSTable
Imagine that during the week there happened read repairs for every past week. In this case every week we are gonna rewrite all the data in cluster.
the # of SSTables in each window is important because of read amplification, which affects latency
I suggested doing minor compactions, in this case for every week will have at max 2 SSTables, which increases the latency 2x in the worst case for those requests that hit the affected SSTables. On the contrary if there is constant heavy disk load due to compactions that are trying to sustain 1 SSTable per window that actually might hurt latencies worse than 2x and for all requests (which happens right now for us)
gibsn
on 28 Jul 2020
output of expired_sstables.py:
expired.sc8.log
gibsn
on 28 Jul 2020
But perhaps this last step we should make it optional via a property, to satisfy all users.
If you could provide some config param that would be ok for us. What can we do now to regain read latencies we had before upgrading?
I can work on this fix where we'll do STCS (with a min threshold of 2 to keep the max # of SSTables in a window relatively small) instead of major compaction in older windows that received new data. Write amplification will be significantly improved and will probably solve your issue. We can then backport the fix to your branch. How does it sound to you?
I suggested that we do a kind of "major compaction" when the current window closes on all windows that have more than 1 SSTable
Imagine that during the week there happened read repairs for every past week. In this case every week we are gonna rewrite all the data in cluster.
Yes, that may be too aggressive for some users. For others where # of SSTables will have a larger impact on read perf / resources, they may be willing to accept the trade off. So I will consider making it an optional.
the # of SSTables in each window is important because of read amplification, which affects latency
I suggested doing minor compactions, in this case every week will have at max 2 SSTables, which increases the latency 2x in the worst case for those requests that hit the affected SSTables. On the contrary if there is constant heavy disk load due to compactions that are trying to sustain 1 SSTable per window that actually might hurt latencies worse than 2x and for all requests (which happens right now for us)
That may still significantly hurt the write amplification. As you will have to keep recompacting the large SSTable with the 2 new small SSTables that came in. I'd rather do STCS on older windows with a min threshold of 2. So you will have at most O(log N data size) SSTables per window.
raphaelsc
on 28 Jul 2020
I can work on this fix where we'll do STCS (with a min threshold of 2 to keep the max # of SSTables in a window relatively small) instead of major compaction in older windows that received new data.
So you are gonna have two positions for some new knob:
- do STCS on older windows with a min threshold of 2
- do STCS on older windows with a min threshold of 2 and do major compaction for every previous window when the current window closes (default)
Did I understand you right? If so I guess it's ok for us.
We can then backport the fix to your branch. How does it sound to you?
I understand that it is gonna take a couple of weeks :( Can we do something now? Like maybe tuning io_properties to limit the compaction BW or maybe tweaking min_threshold or split_during_flush?
gibsn
on 28 Jul 2020
I can work on this fix where we'll do STCS (with a min threshold of 2 to keep the max # of SSTables in a window relatively small) instead of major compaction in older windows that received new data.
So you are gonna have two positions for some new knob:
- do STCS on older windows with a min threshold of 2
- do STCS on older windows with a min threshold of 2 and do major compaction for every previous window when the current window closes (default)
Something along these lines, yeah.
Did I understand you right? If so I guess it's ok for us.
We can then backport the fix to your branch. How does it sound to you?
I understand that it is gonna take a couple of weeks :( Can we do something now? Like maybe tuning io_properties to limit the compaction BW or maybe tweaking
min_thresholdorsplit_during_flush?
I will think about something.
raphaelsc
on 28 Jul 2020
@raphaelsc thanks much!
gibsn
on 28 Jul 2020
@raphaelsc thanks much!
It's possible to control compaction bandwidth with the config compaction_static_shares, but setting compaction shares like that can affect read performance as compaction will potentially fall behind.
An alternative is to temporarily increase the window size to 1 month for example. That means TWCS is going to do size-tiered compaction on the last month of data, and there will be no data segregation if the repaired data is not older than 1 month (meaning data will not get recompacted on past windows if this condition is true). This will require that all past time windows will be rewritten once though as time windows will have to be reshaped as according to the new setting.
If this doesn't work to you, I can try to propose a simple patch that optionally disable the data segregation feature. This can be easily coded and test, therefore it will quickly be made available for you.
raphaelsc
on 28 Jul 2020
Cc @avikivity please be in the loop
 bhalevy
on 29 Jul 2020
bhalevy
on 29 Jul 2020
@raphaelsc let's apply normal STCS within windows. This way the small updates from read repair won't cause too much damage.
 avikivity
on 29 Jul 2020
avikivity
on 29 Jul 2020
On Wed, Jul 29, 2020 at 11:06 AM Avi Kivity notifications@github.com
wrote:
@raphaelsc https://github.com/raphaelsc let's apply normal STCS within
windows. This way the small updates from read repair won't cause too much
damage.
I think that the active window needs to follow the TWCS rules (if they are
STCS great - if they are more aggressive they should stay that way).
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/scylladb/scylla/issues/6928#issuecomment-665506142,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AA2OCCALAN22A3VSM3KFPVDR57KATANCNFSM4PJAW45Q
.
slivne
on 29 Jul 2020
@raphaelsc thanks
It's possible to control compaction bandwidth with the config compaction_static_shares, but setting compaction shares like that can affect read performance as compaction will potentially fall behind.
We tried tuning compaction_static_shares when we encountered #5921. Even with relatively small values we still had high read latencies :( also current compaction_static_shares values (can be seen on the screenshot attached) are somewhat like those during weekly compactions and we do not get so many timeouts during weekly compactions.
An alternative is to temporarily increase the window size to 1 month for example.
We have data since 12.2019 and read repairs can reach ~02.2020
If this doesn't work to you, I can try to propose a simple patch that optionally disable the data segregation feature. This can be easily coded and test, therefore it will quickly be made available for you.
This seems like the best (and only as I see it) option, if you could that it would be great. Can we deploy some custom RPM until the fix is released officially?
gibsn
on 29 Jul 2020
On Wed, Jul 29, 2020 at 11:06 AM Avi Kivity @.*> wrote: @raphaelsc https://github.com/raphaelsc let's apply normal STCS within windows. This way the small updates from read repair won't cause too much damage.
I think that the active window needs to follow the TWCS rules (if they are STCS great - if they are more aggressive they should stay that way).
…
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub <#6928 (comment)>, or unsubscribe https://github.com/notifications/unsubscribe-auth/AA2OCCALAN22A3VSM3KFPVDR57KATANCNFSM4PJAW45Q .
The problem is that TWCS users care a lot about write amplification. They expect that once a window is closed it will not be written to anymore. With data segregation, we may be constantly generating data to past windows, causing those past windows to be recompacted over and over again (like Avi pointed out, even small updates from read repair can trigger this). So now disk is dominated by writes, hurting severely the latency of queries.
I think that the behavior should be the follow:
When the last window is closed, the TWCS rule is applied where that window will be compacted into 1 single SSTable (this is already the current behavior).
But if we generate another SSTable later on (with data segregation) to that closed last window, which was compacted into a single SSTable, let's do STCS instead (this will be the new behavior).
raphaelsc
on 29 Jul 2020
@gibsn
Solution can be found in my private branch https://github.com/raphaelsc/scylla/tree/fix_twcs_agressiveness_after_data_segregation
The patchset was already sent to scylladb mailing list as:
"[PATCH 0/7] Fix TWCS compaction aggressiveness due to data segregation"
https://groups.google.com/g/scylladb-dev/c/_y-DWRpZreM/m/Vbc1nxJXAQAJ
raphaelsc
on 29 Jul 2020
@raphaelsc please provide a private rpm to @gibsn (and @gibsn please report if it helps)
avikivity
on 30 Jul 2020
@raphaelsc please provide a private rpm to @gibsn (and @gibsn please report if it helps)
working on it...
raphaelsc
on 30 Jul 2020
@gibsn Please find your private RPM here:
gsutil cp gs://scratch.scylladb.com/raphaelsc/scylla-rpm-20200730.7561d2784.tar.bz2 /path/to/rpm
It was built from my private branch which is based on scylla-4.1.2 and contains the fix for this issue: https://github.com/raphaelsc/scylla/commits/fix_twcs_aggressiveness_for_4_1_2
raphaelsc
on 30 Jul 2020
I installed the provided RPM in dev cluster and Scylla prints the old version in log:
2020-07-31T15:44:10.227050+03:00 beccascdev1 scylla[22014]: Scylla version 4.1.2-0.20200715.3e6c6d5f582 with build-id 05ae958a5663193f3ba65ba0786421926a9a7c18 starting ...
Though:
[root@beccascdev1 kirill.alekseev]# yum list installed scylla
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
Installed Packages
scylla.x86_64 4.1.2-0.20200730.7561d2784 @mailrutesting
Yum installed only the main package, I installed all the others and now it's ok
gibsn
on 31 Jul 2020
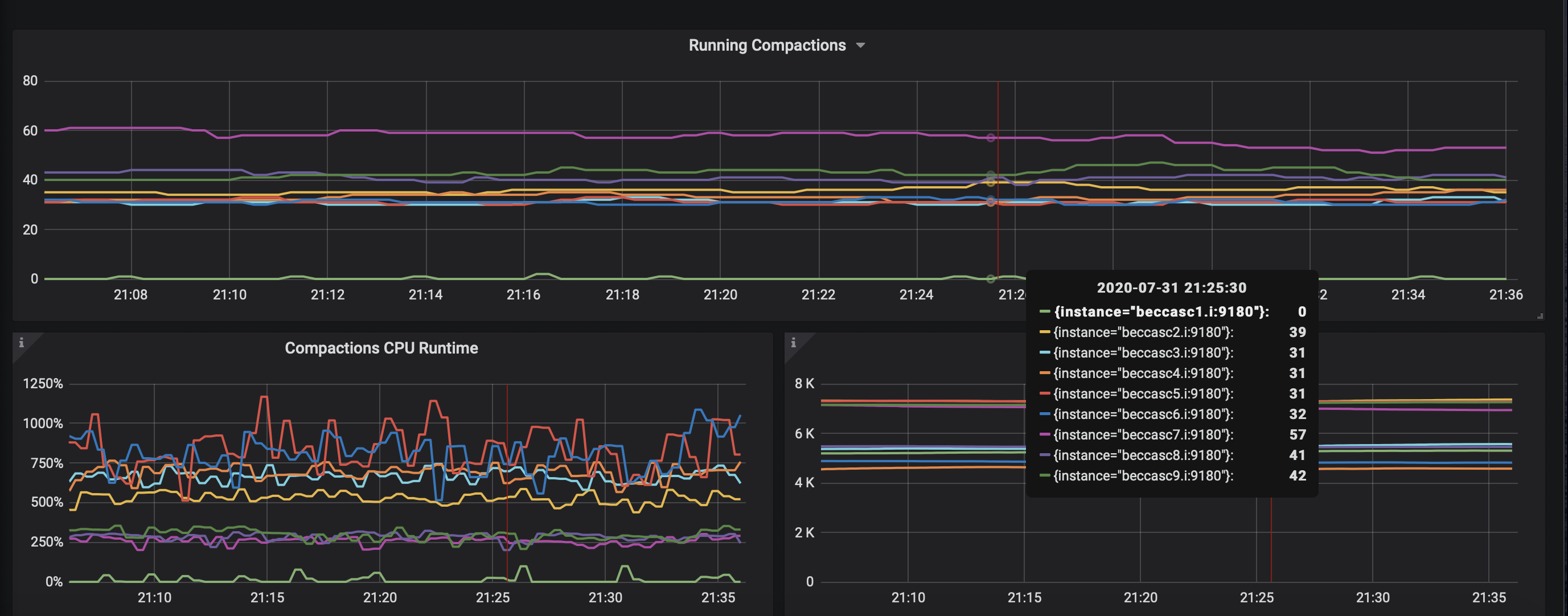
We have deployed the fix to one node and it seems to behave better. Number of SSTables has dropped 2x and Scylla is not compacting much:
Will update the whole cluster on Monday
gibsn
on 31 Jul 2020
We have deployed the fix to one node and it seems to behave better. Number of SSTables has dropped 2x and Scylla is not compacting much:
Will update the whole cluster on Monday
Thanks for the report, @gibsn. Really glad to know that the fix worked well to you.
raphaelsc
on 2 Aug 2020
We have deployed the fix to all nodes in the cluster and it seems to help a lot. Scylla seems to compact a bit more than it used to, but it doesn't affect the read performance. We have a pending weekly compaction on Wednesday night, we'll report how it behaves
gibsn
on 3 Aug 2020
We have deployed the fix to all nodes in the cluster and it seems to help a lot. Scylla seems to compact a bit more than it used to, but it doesn't affect the read performance. We have a pending weekly compaction on Wednesday night, we'll report how it behaves
Thanks. Keep us posted!
raphaelsc
on 7 Aug 2020
Hi!
Weekly compactions were ok, but today timeouts are back sporadically on some nodes, it did not happen on 3.2.4
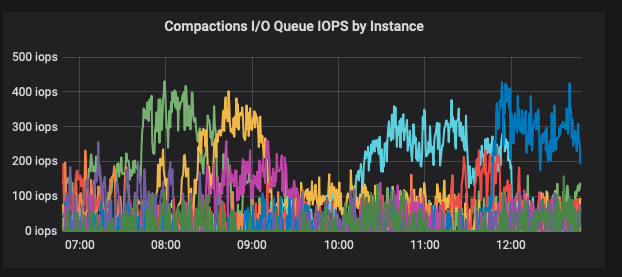
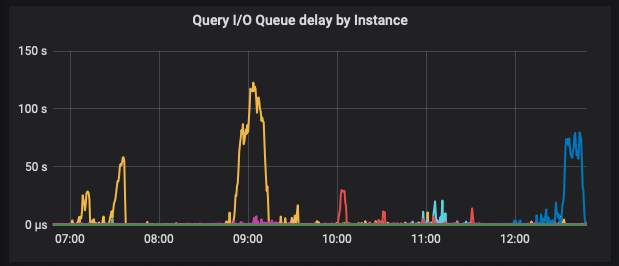
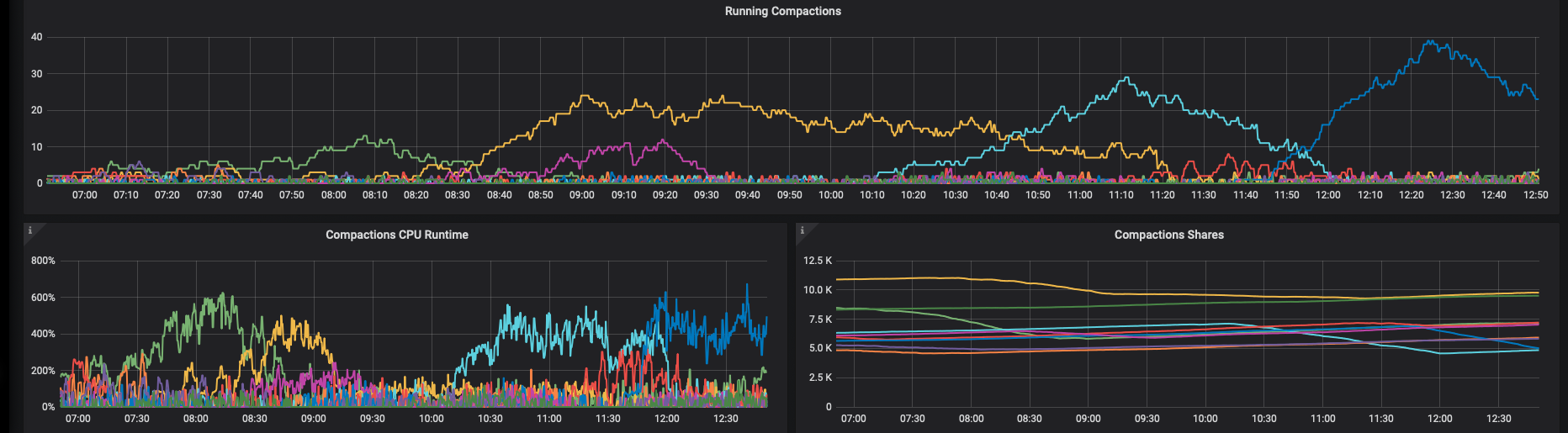
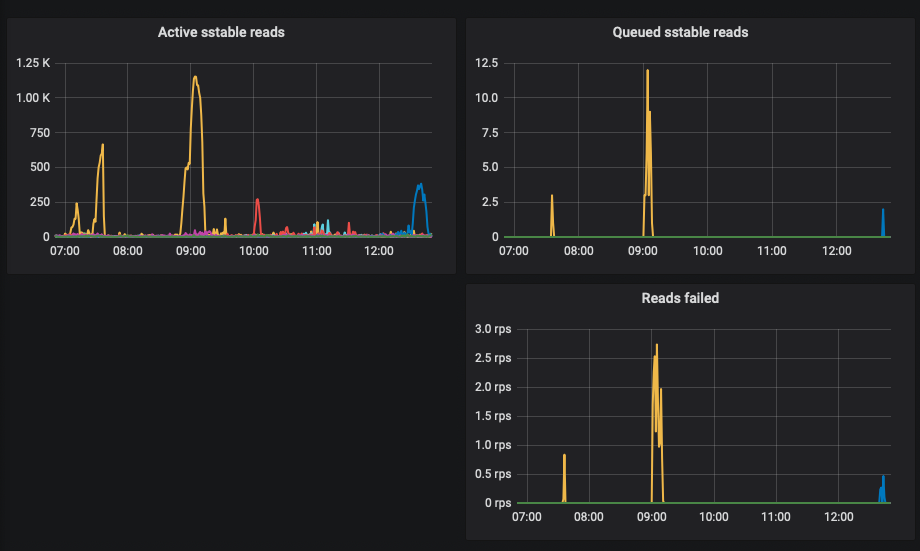
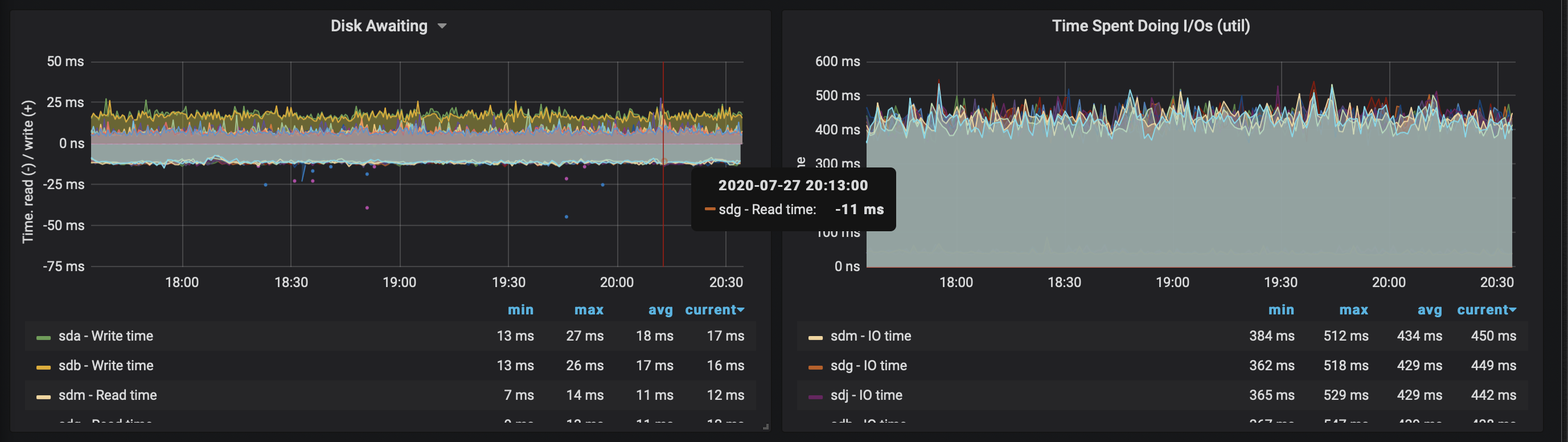
Disks do not seem overloaded:
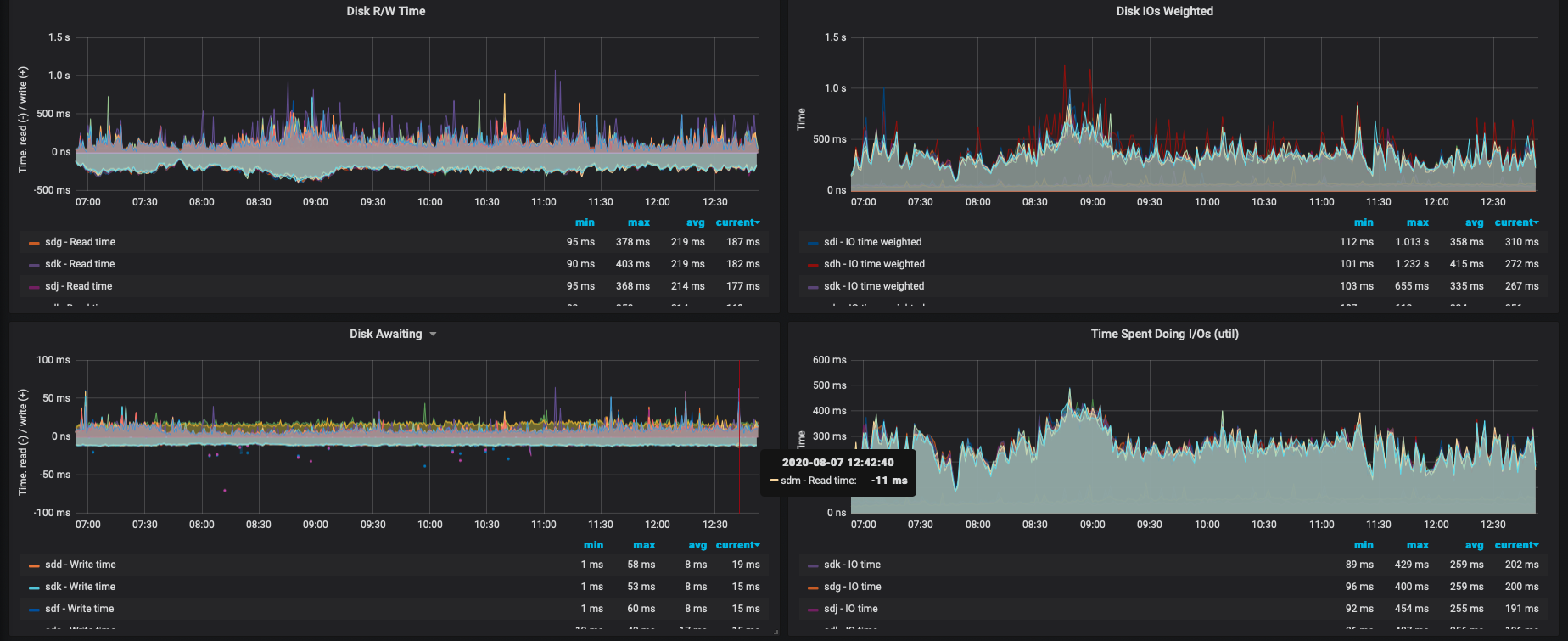
gibsn
on 7 Aug 2020
Hi!
Weekly compactions were ok, but today timeouts are back sporadically on some nodes, it did not happen on 3.2.4
Disks do not seem overloaded:
Could you please show the dashboard of the node which had time outs? (like the one depicted by yellow color). I'd like to have a per-shard view instead, for that specific node.
raphaelsc
on 7 Aug 2020
We had a discussion with @raphaelsc in direct messages and decided that we should try disabling speculative retries. I noticed that on Friday read load increased ~2 times, so I am pretty sure read timeouts were not correlated with the new data segregation feature.
However I can see that disks are underutilised yet Scylla times out
gibsn
on 10 Aug 2020
Hi! Do you think this fix will be released soon? We are also waiting for another fix, which has been backported recently and we cannot update until this fix is released
gibsn
on 11 Aug 2020
Hi! Do you think this fix will be released soon? We are also waiting for another fix, which has been backported recently and we cannot update until this fix is released
I plan to send next iteration of the fix today, and after it cooks for a few days in master, it will probably be backported to your version.
raphaelsc
on 11 Aug 2020
@roydahan please let me know as soon as we have some runs with TWCS, so I can backport.
avikivity
on 20 Aug 2020
@roydahan please update.
avikivity
on 27 Aug 2020
no updates yet.
We don't have a good TWCS scenario in SCT, I'm working on one these days.
 roydahan
on 30 Aug 2020
roydahan
on 30 Aug 2020
@avikivity @bhalevy extremely important to have this backported to 4.2 before it's released
raphaelsc
on 1 Sep 2020
All right, I'll backport and trust @gibsn's testing.
avikivity
on 2 Sep 2020
Backported to 4.2. Will consider for 4.1 after some more soak time.
avikivity
on 2 Sep 2020
Backported to 4.1.
avikivity
on 5 Nov 2020
Related issues
 eyalgutkind
·
3Comments
eyalgutkind
·
3Comments
 veramine
·
5Comments
veramine
·
5Comments
 dimaqq
·
6Comments
dimaqq
·
6Comments
 gnumoreno
·
5Comments
gnumoreno
·
5Comments
 tarzanek
·
6Comments
tarzanek
·
6Comments