Scylla: MV flow control not working in cassandra-stress run
@vladzcloudius ran a simple cassandra-stress ran against a cluster of 3 Scylla 3.0 nodes:
cassandra-stress-shard-aware write duration=30m no-warmup -node <address> -rate threads=600 fixed=150000/s -mode native cql3
The cluster successfully handled 150,000 requests per second, and after a while, Vlad created a materialized view.
From this point, the cluster is much busier, needing to both build the view on the existing data, and to write view updates for new data which comes in. But we expect flow control to slow down the client.
But the "view update backlog per shard" graph on one of the nodes looks like this:
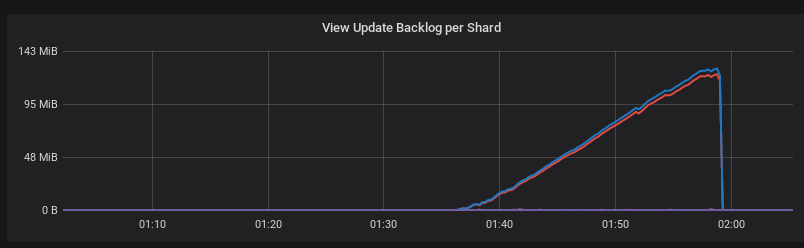
There are two bad things here. First, we see a view backlog on just two shards. Why? Second, the view backlog is growing linearly. It should have slowed down its growth because of flow control, but doesn't. In this graph it appears as if the client is not slowing down at all (in total requests box, we see the client slow down to 95,000 requests per second immediately after the creation of the view, but it does not continue to slow down).
Is it possible that we have a bug in our view backlog reporting - where a base replica where only two shards have large backlogs, and 6 others have almost zero backlogs - report back an almost zero backlog instead of the maximum of all shards?
 nyh
nyh
All 10 comments
Cassandra-stress is what you call an interactive client, so depending on its concurrency (and potentially other factors), it will just keep sending requests to meet the requested rate.
What's the key distribution?
 duarten
on 24 Jan 2019
duarten
on 24 Jan 2019
As far as I know, at least in its default modes, Cassandra-stress is a limited-concurrency application. You set a specific number of threads and each thread will send at most one request.
So flow control should have worked.
 glommer
on 24 Jan 2019
glommer
on 24 Jan 2019
It isn't if you specify the rate, otherwise it would suffer from coordinated omission. This is assuming we use the c-s version that has those fixes.
duarten
on 24 Jan 2019
@duarten really, so the "threads" option is just ignored, and it just uses the "fixed" option and bombards the server with unlimited concurrency?
@vladzcloudius can you try the same test without the "fixed" option, just let it run with a known concurrency, not trying to achieve any specific rate?
nyh
on 24 Jan 2019
I think so, if we're running with the fix described in http://psy-lob-saw.blogspot.com/2016/07/fixing-co-in-cstress.html (which I hope we are).
duarten
on 24 Jan 2019
I chatted with @vladzcloudius and it looks like a real bug, where we aren't applying any delay to user writes (the throttled base writes were 0). He showed me a run without the --rate option.
The difference between this test and the ones we performed before is that the shards have 8GB of memory, which allows for a much bigger backlog. Maybe that's messing with the calculations?
duarten
on 24 Jan 2019
We should look into this with very high priority, @eliransin and @nyh. I'm knee-deep in the consensus stuff :/
duarten
on 24 Jan 2019
@duarten @vladzcloudius I'm now trying to reproduce this issue. Just so we're on the same page, @vladzcloudius were you running this on Scylla 3.0 or master?
nyh
on 27 Jan 2019
@nyh scylla-3.0.1
 vladzcloudius
on 28 Jan 2019
vladzcloudius
on 28 Jan 2019
@vladzcloudius also clarified in an email to the mailing list that in this test:
- He was using three i3.2xlarge nodes for the cluster.
- He was using RF=1 (not cassandra-stress's default RF=3!).
- He was not limiting the stress rate in this case.
- He created 7 MVs were created after some (10 minutes) of base table data was populated.
- Cassandra-stress was running with our shard-aware driver
nyh
on 5 Feb 2019
Related issues
 eyalgutkind
·
3Comments
eyalgutkind
·
3Comments
 pdziepak
·
6Comments
pdziepak
·
6Comments
 tzach
·
7Comments
tzach
·
7Comments
 hellowaywewe
·
3Comments
hellowaywewe
·
3Comments
 dimaqq
·
6Comments
dimaqq
·
6Comments
Most helpful comment
We should look into this with very high priority, @eliransin and @nyh. I'm knee-deep in the consensus stuff :/