I noticed something peculiar in #33038, notably
So in short, the slowdown is caused by .count() using 64 bit integers. Which is strange, because the length of the vector is known be less than 2^32 - is there any way to optimize Vec or count() to use something smaller than usize?
In my understanding, .count() using usize directly contradicts
So how do you know which type of integer to use? If you’re unsure, Rust’s defaults are generally good choices, and integer types default to i32: this type is generally the fastest, even on 64-bit systems. The primary situation in which you’d use isize or usize is when indexing some sort of collection.
from https://doc.rust-lang.org/book/second-edition/ch03-02-data-types.html
.count() is certainly never realistically being used for indexing, so according to the above paragraph it should default to i32 on 64bit systems (This is referring to automatic typing of integer literals, but as an idea it remains valid). If this was already thoroughly discussed, I apologize. If not, I think it needs a second look. I think that in the majority of use cases, the users of Rust would much prefer .count() be three times faster, as opposed to being able to surpass 4 Billion.
 npip99
npip99
All 14 comments
One thing I am worried about is 16bit systems. I doubt min(usize, i32) is a legitimate type xD
But perhaps that can be resolved by those who know better than me.
npip99
on 1 Nov 2018
We are not going to change the return type of a stable method.
 sfackler
on 1 Nov 2018
sfackler
on 1 Nov 2018
Actually, the fact that it uses usize should have nothing to do with the execution speed, I think this is an implementation misstep. Ignore my comments about converting the return type to i32, since I think the 3x speed issue can be resolved internally (And the larger size and 16bit support is a pure upgrade). As an implementation, it should probably look something like this:
cnt = 0u32 // Honestly, if this is a register why would it ever be faster? Is LLVM spitting out bad 64bit code?
while( cnt & ~((usize::MAX - 1) >> 1) != 0) { // Time for check is amortized out
if( iter.next() is not None ) {
cnt++
} else {break}
... // Number of copy pastes chosen empirically
// Best if it changes # of iterations based on the ISA
if( iter.next() is not None ) {
cnt++
} else {break}
}
// The above code should be skipped during compilation if its to a 16bit or lower ISA
fullcnt = cnt as u64
while( iter.next() is not None ) {
fullcnt++
}
This issue is now basically a dup of #33038 if it's desired to merge and reopen the original ticket
npip99
on 1 Nov 2018
.count() is certainly never realistically being used for indexing
The usize type is able to represent the maximum number of elements that an array might contain. Therefore, it is the type that's used to index into arrays, offset pointers to objects in arrays, etc.
For example (playground):
#[derive(Copy,Clone)] struct ZST;
let x = [ZST; usize::max_value()];
let y = x.iter().count();
If count would return something smaller than usize it wouldn't be able to count the number of elements in an array.
 gnzlbg
on 2 Nov 2018
gnzlbg
on 2 Nov 2018
Yes, I get it now. In my use cases from an abstract perspective in FP, .count()'s primary use is "How many elements fit this predicate?". Of course, yes that's counting an array, so it should definitely be usize. But I was imagining let c = 0; for e in vec { if isgood(e) c++ }. I don't know, seeing c as a usize didn't click. Especially because arr[c] would never be an expression, which breaks my idea of "X is usize if arr[X] makes sense".
Theoretically, if this performance issue was impossible to fix, it'd be sad to see speed loss due to 64bit support (Because I'd otherwise have to remember to avoid .count for performance reasons and use fold instead - that's annoying). However I think I could accept that the speed loss is preferred to keep std clean, and just wait for 64bit chips to close the gap.
This is silly though, because a function could easily call the 32bit version, check for overflow, and then continue counting with usize if it overflowed. I think this should be implemented.
npip99
on 2 Nov 2018
fold32.rs
fn main() {
println!("{}", (0..1u32<<30)
.filter(|&i| i.count_ones() == 15)
.fold(0, |count, _| count + 1)
);
}
fold64.rs
fn main() {
println!("{}", (0..1u32<<30)
.filter(|&i| i.count_ones() == 15)
.fold(0u64, |count, _| count + 1)
);
}
count.rs
fn main() {
println!("{}", (0..1u32<<30)
.filter(|&i| i.count_ones() == 15)
.count()
);
}
Benchmark on 64bit system
Timing fold32
155117520
real 0m0.675s
user 0m0.609s
sys 0m0.005s
Timing fold64
155117520
real 0m2.861s
user 0m2.736s
sys 0m0.015s
Timing count
155117520
real 0m2.879s
user 0m2.745s
sys 0m0.014s
Same system but with target-cpu=native
Timing fold32
155117520
real 0m0.317s
user 0m0.285s
sys 0m0.004s
Timing fold64
155117520
real 0m0.714s
user 0m0.700s
sys 0m0.005s
Timing count
155117520
real 0m0.743s
user 0m0.687s
sys 0m0.006s
Even with target-cpu=native, count is twice as slow as fold32.
I'm kind of confused though, target-cpu=native seems like it should be a few percent, not as dramatic of a difference as it was. What is happening in target-cpu=native that is not happening in -O? I imagine the only things in target-cpu=native would be things that might be slower or might SIGILL on other processors. Anything else should just be in -O by my understanding (Which might just be the case; I'm just surprised by the huge difference).
Note that I'm not suggesting that fold64 be optimized in any way (Which is mostly impossible). I'm only suggesting that count be optimized since it can be 4 times faster by only changing internals (And twice as fast with target-cpu=native on my CPU).
(Note that these files come from the issue that I referenced earlier)
npip99
on 2 Nov 2018
count is literally just the fold, so any differences are definitely down to LLVM implications of type sizes:
#[inline]
#[rustc_inherit_overflow_checks]
#[stable(feature = "rust1", since = "1.0.0")]
fn count(self) -> usize where Self: Sized {
// Might overflow.
self.fold(0, |cnt, _| cnt + 1)
}
I suppose it would be legal to look at .size_hint().1 and use a smaller type if that allows, though it seems silly to have to do that.
 scottmcm
on 5 Nov 2018
scottmcm
on 5 Nov 2018
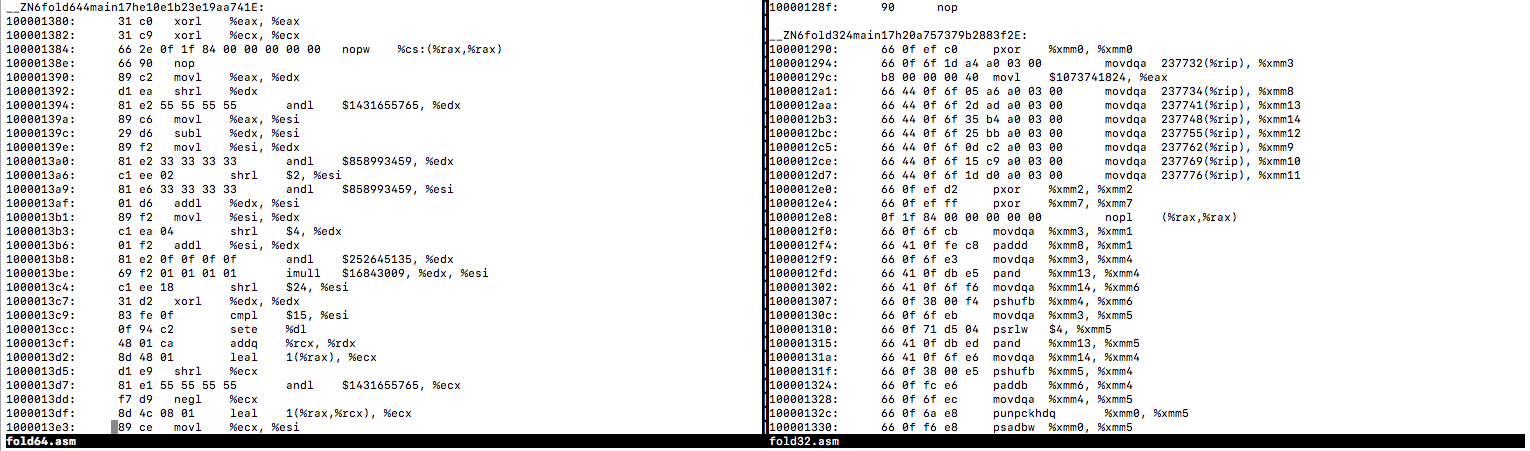
Something is going haywire on the backend. The RHS is awesome and it's exclusively using xmm registers. Ironically, by swapping to 64bit (the larger value), now all of the assembly is using 32bit commands. It's not even using rax anywhere, which is highly alarming and just.. weird. I fear 64bit integer arithmetic performance is being hammered everywhere by this.
It's not even any issue with usize. Just using u64 breaks xmm optimization here.
Even worse, when u128 is used it still refuses to use xmm!
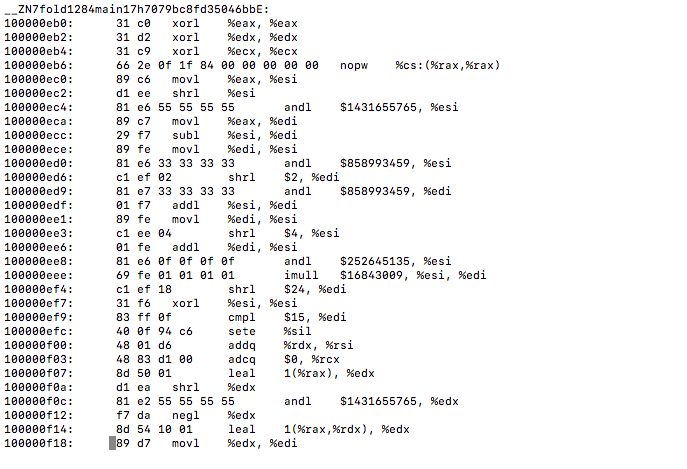
It's doing a bunch of shifting to get the operations done, despite the fact that u32 freely used xmm registers.
npip99
on 5 Nov 2018
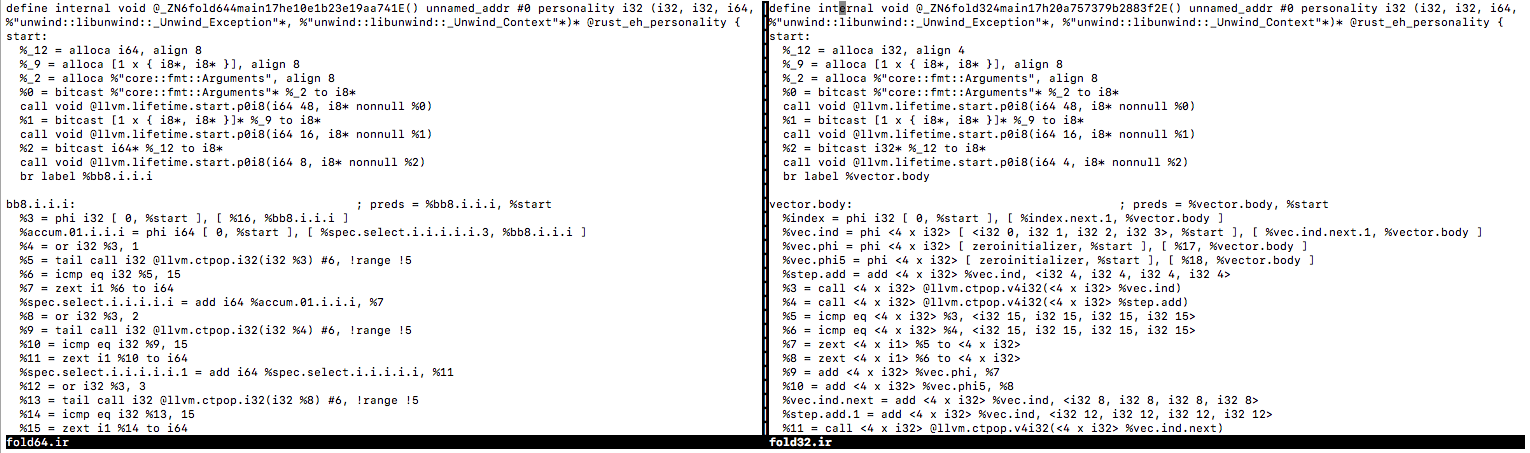
The 64bit version is emitting 32bit IR, even though 32bit is perfectly vectorized. So it's not the backend actually, it's in the frontend. This looks like a bug.
Looking at the assembly, the problem has nothing to do with .count and u32 vs u64 (Which makes sense, as simple incrementing shouldn't be faster on 32bit numbers). The problem is with optimizing the filter out. For some reason, in the 32bit version, the filter is being optimized out and replaced with xmm that bitcounts 4 numbers at a time, and matches all four against <15, 15, 15, 15> (The desired bitcount). The 64bit version is calling an unoptimized Filter function.
npip99
on 5 Nov 2018
The 64bit version is emitting 32bit IR, even though 32bit is perfectly vectorized. So it's not the backend actually, it's in the frontend. This looks like a bug.
Look at the %accum.03.i.i.i = phi i64 part, which is counting in 64-bit. The IR looks fine.
Note also that there's another possible dimension here: the width of the items being iterated. It appears that if you iterate over (0..1u64<<30) and fold into a u32, it _also_ doesn't vectorize: https://play.rust-lang.org/?version=nightly&mode=release&gist=8d89c2059756f6eaf20a2f944293b51f
That makes me wonder if there's something going on here that's actually about what LLVM can prove about the length of the Range, and if that gives it the necessary proof to do some transformation.
scottmcm
on 6 Nov 2018
The IR is bad. You can see it calling ctpop (Google showing that ctpop is llvm-speech for "count bits") just once on an element, and then comparing to 15 just once. Then it does that 4 times, iterating a total of four times (I suppose it decided 4 was a good unroll). All of those ctpops and cmp eq 15's could be done four at a time using xmm. That would lead to 16 iterations by the end, not 4. That's what the 32bit IR does. The counting is good as you said; what is bad is that for some reason vectorization of the closure broke. The counting in fact has nothing to do with the runtime, it just had a side effect of unvectorizing the closure's IR for some reason.
npip99
on 6 Nov 2018
This all looks in line with expectations to me. X86 doesn't have native vector popcounts, they're going to be emulated based on shuffles. The cost model decides it's not worthwhile to vectorize a 64-bit popcount if you only have 128-bit vectors. If you specify a target CPU that has wider vectors, the 64-bit popcounts will be vectorized as well.
Narrowing the types would be within the real of possibility for the specific example given here (where the range is statically known), but this doesn't seem like something worth pursuing to me. Apart from just being hard to do, it's even harder to model when it will be profitable. Going to a narrower integer width will often be a pessimization due to microarchitectural concerns.
 nikic
on 10 Dec 2018
nikic
on 10 Dec 2018
@nikic That's not where the issue is. I would understand it having some trouble vectorizing 64bit arithmetic on xmm (Though the benchmarks are notably more than twice as slow, but doing 2-at-a-time vs 4-at-a-time should be exactly twice as slow). However, let's look at the file again:
fold64.rs
fn main() {
println!("{}", (0..1u32<<30)
.filter(|&i| i.count_ones() == 15)
.fold(0u64, |count, _| count + 1)
);
}
Note that what we're counting here is (0..1u32<<30).filter(|&i| i.count_ones() == 15), so all of the count_ones are being done on 32bit values. You can see in the IR that it's still doing 32bit popcounts in fold64.rs (Which is expected, from 0..1u32<<30). Almost all of the code is doing the exact same thing, other than the simple i++ to keep track of the counter (Which went from 32bit to 64bit). It should still be entirely vectorized, regardless of the bitwidth of the counter. I think it's unvectorizing it because its trying too hard to vectorize the counter, which isnt important. it should simply zext into 4 x i32, and then sum those values into a 64bit accumulator. I think even in fold32.ir, it's being slower (Or at least not faster) by setting %9 and %10 the way it does, as opposed to summing the vector into a scalar.
npip99
on 10 Dec 2018
@npip99 You're right, sorry, I didn't read the example carefully enough. This does look like a missing optimization opportunity.
nikic
on 10 Dec 2018
Related issues
 eddyb
·
3Comments
eddyb
·
3Comments
 dnsl48
·
3Comments
dnsl48
·
3Comments
 modsec
·
3Comments
modsec
·
3Comments
 pedrohjordao
·
3Comments
pedrohjordao
·
3Comments
 zhendongsu
·
3Comments
zhendongsu
·
3Comments
Most helpful comment
We are not going to change the return type of a stable method.