I had a power failure at work today, which caused an unclean shutdown of a machine I had that was actively running rq jobs. When power came back and I started redis back up again, rq info listed the workers that existed before the power failure (modulo unsaved info, which I am fine with).
I am calling these workers "zombie workers". They exists only in redis. They do not have a corresponding running process, but redis-queue thinks they exist for the moment. Now, any workers that were not busy at the time of the last save will show up as "idle", and it seems like they eventually get automatically cleared out after 7 minutes (the 420 second worker_ttl, I am guessing). However, the workers that were "busy" at the time of the last save do not get automatically cleared out. This causes issues because the jobs they were holding don't get failed over to the failed queue. They just sit there.
So, I have two problems. 1) I don't have a very clean way to automatically identify these zombie processes. The best I have been able to do is to parse their name for the PID, then run ps -p PID and see if it comes back with a command name of "rq". If it doesn't, then I assume it is a zombie.
2) I haven't figured out a proper way to clear these zombie processes so that the job they are holding gets failed over correctly. Simply doing j.request_force_stop() or messing with the hearbeat doesn't seem to do the trick. It'll clear it out, but the job doesn't get failed over.
Thoughts?
My employer is willing for me to devote a little bit of time to implement some code to help address this problem, if you are receptive to it.
 WeatherGod
WeatherGod
All 20 comments
To get the list of zombie workers we do the following:
- In our setup each worker is executed inside a docker container.
- The name of the worker is by default the hostname.1. (hostname + ".1"). In the case of a docker container, the hostname is the container id.
- We get the list of containers id (Set A)
- We get the list of redis workers (Set B)
- zombie workers = Set B - Set A
To remove them nicely:
First we get the zombie worker object and make the job fail by doing
worker.failed_queue.quarantine(job, exc_info=("Dead worker", "Moving job to failed queue"))
and then register the death of the worker:
worker.register_death()
In code:
get_zombies.py
import sys
import subprocess
import re
from env import envget
from rq import Worker
from redis import Redis
import datetime
def call_with_output(array):
p = subprocess.Popen(array, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
output, err = p.communicate()
return output
def get_zombie_workers():
containers = call_with_output(['docker','ps','-q'])
containers = containers.split()
redis_workers = call_with_output(['docker-compose', 'exec', 'api', 'rq', 'info', '--only-workers', '--raw', '--url', 'redis://codexbackendfull_redis_1'])
redis_workers = redis_workers.split('\n')
redis_workers_clean = []
for x in redis_workers:
a=re.search('[a-f0-9]{12}',x)
if a is not None:
redis_workers_clean.append(a.group(0))
zombies = list(set(redis_workers_clean)-set(containers))
return zombies
zombies = get_zombie_workers()
for x in zombies:
print str(x),
remove_zombies.py
import sys
import subprocess
from IPython import embed
import re
from env import envget
from rq import Worker
from redis import Redis
import datetime
def remove_zombies():
workers_and_tasks = []
connection = Redis(host=envget('redis.host'))
workers = Worker.all(connection=connection)
for worker in workers:
if worker.name[0:12] in sys.argv:
job = worker.get_current_job()
if job is not None:
job.ended_at = datetime.datetime.utcnow()
worker.failed_queue.quarantine(job, exc_info=("Dead worker", "Moving job to failed queue"))
worker.register_death()
remove_zombies()
The executing is done by doing
python get_zombies.py
I will return a list of zombie workers
and then, (in our setup is inside a docker container)
docker-compose exec some_container python remove_zombies.py <zombie_1> <zombie_2> etc
 CrimsonGlory
on 25 Mar 2017
CrimsonGlory
on 25 Mar 2017
This is definitely a problem.
I don't have a better way for identifying zombie workers than @WeatherGod 's suggestion.
I think a good first step is to write a worker.cleanup_zombies() method. Keep in mind that workers can be run in multiple different servers so the worker only needs check for the status of other workers running in the same box. When zombie workers are detected, jobs should be failed over automatically.
This should be run by the worker periodically, similar to worker.clean_registries() here: https://github.com/nvie/rq/blob/master/rq/worker.py#L456
Thoughts?
 selwin
on 19 Apr 2017
selwin
on 19 Apr 2017
I was also having this issue. For my case I always knew that when my worker re-started, that would mean it should remove the zombie worker it was replacing, so in worker.py I made the worker save it's job name to a file, and then while starting look for that file, load that file, and register it's old zombie worker as dead. This seems to be working well for me (but wish RQ had some way of handling this internally)
Here is the code I use (this snippet contains some extra stuff specific to my project, but also contains the relevant code, in case it is helpful to anyone)
if __name__ == '__main__':
with Connection(redis_connection):
queue_names = sys.argv[1:]
queues = map(Queue, queue_names) or [Queue()]
_log('++ listening to queues: {}'.format(queue_names))
worker = Worker(queues)
worker.push_exc_handler(retry_handler)
if 'w1' in queue_names:
worker_num = '1'
elif 'w2' in queue_names:
worker_num = '2'
else:
worker_num = None
if worker_num:
worker_id_path = 'workers/{}'.format(worker_num)
requeue_queue = get_osf_queue(queue_names[0])
# try to remove zombie worker
if file_exists(worker_id_path):
old_worker_dict = load_dict(worker_id_path)
old_worker_name = old_worker_dict['worker_name']
workers = Worker.all()
for w in workers:
if w.name == old_worker_name:
_log('++ removing zombie worker: {}'.format(old_worker_name))
job = w.get_current_job()
if job is not None:
_log('++ requeing job {}'.format(job.id))
job.ended_at = datetime.datetime.utcnow()
requeue_queue.enqueue_job(job)
w.register_death()
# save name of current worker
worker_dict = {'worker_name': worker.name}
save_dict(worker_dict, worker_id_path)
from osf_scraper_api.web.app import create_app
app = create_app()
with app.app_context():
worker.work()`
 mhfowler
on 19 Oct 2017
mhfowler
on 19 Oct 2017
@mhfowler Is this code sample can be used for an app deployed on heroku as the file overwriting mentioned will be a complicated one?
 vtvenugopal
on 22 Nov 2017
vtvenugopal
on 22 Nov 2017
Hi. I can only confirm that I've got to kill zombies myself, too. I'm using rq==0.8. No power failures. It happens from time to time.
 marcinn
on 11 Dec 2017
marcinn
on 11 Dec 2017
Hi.
What is the reason of creation of zombie workers?
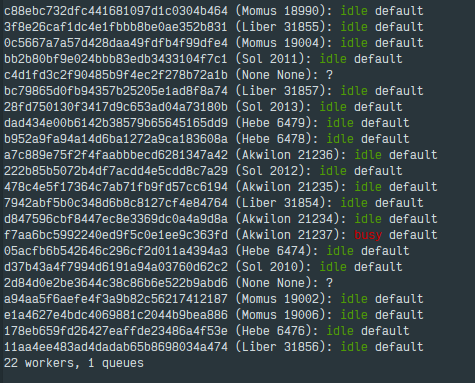
They were quite rare until I switched to the master branch.
My workers are restarting periodically (via cron, SIGTERM). I suspect that zombies comes more frequently when restart occurs (but that's not a rule).
marcinn
on 13 Mar 2020
Hi.
What is the reason of creation of zombie workers?
If the workers exit because of a crash, Out of memry,, power outage or something not nice, I'll get a zombie.
It the crash is inside the task, you will not get the zombie. as the crash in handled by rq and the task sent to the list of failed tasks.
CrimsonGlory
on 16 Mar 2020
Before this PR was merged, zombies could also be created when a job runs for longer than allowed time and the horse is hard killed by the worker process.
Zombie workers should also be cleared from the worker registry so they shouldn't appear when rqinfo is run.
@marcinn's screenshot shows two zombie workers, were you running rqinfo with --interval argument?
selwin
on 17 Mar 2020
were you running rqinfo with --interval argument?
Yes, set to 5 secs.
For each queue:
bin/rqinfo -i 5 <QUEUE> -u redis://<IP>:6379/<DB>
Ok, the fix for this would be to clean the registry for each refresh.
On 17 Mar 2020, at 07.19, Marcin Nowak notifications@github.com wrote:
were you running rqinfo with --interval argument?Yes, set to 5 secs.
For each queue:
bin/rqinfo -i 5
-u redis:// :6379/
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub, or unsubscribe.
selwin
on 17 Mar 2020
Hmm..
I've opened rqinfo (previously 1-2 days ago), and I see something like that:
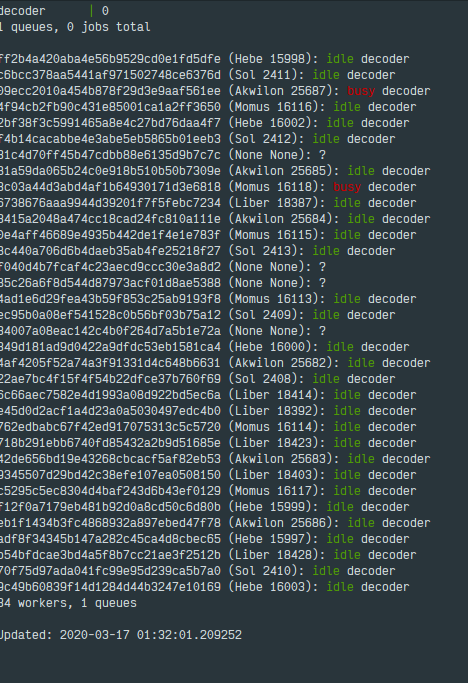
2 of 6 queues are affected. Timeouts and exceptions happens mostly for both.
marcinn
on 17 Mar 2020
I'm investigating zombie workers issue.
I've found that zombie workers have less metadata stored in Redis key, and they're exists regardless how task ends.
First two are zombie workers, third is an active worker:
# redis-cli -n 2 hgetall rq:worker:2d84d0e2be3644c38c86b6e522b9abd6
1) "failed_job_count"
2) "1"
3) "total_working_time"
4) "462.54465"
# redis-cli -n 2 hgetall rq:worker:348eee29664547a1801f2384e82a9f65
1) "successful_job_count"
2) "1"
3) "total_working_time"
4) "90.159074"
# redis-cli -n 2 hgetall rq:worker:8497ab4067bf4acd989200123cb01f51
1) "birth"
2) "2020-03-26T11:22:04.759157Z"
3) "last_heartbeat"
4) "2020-03-26T11:45:33.371041Z"
5) "queues"
6) "default"
7) "pid"
8) "5105"
9) "hostname"
10) "Hebe"
11) "version"
12) "1.2.2-dev2"
13) "python_version"
14) "3.7.3 (default, Apr 3 2019, 05:39:12) \n[GCC 8.3.0]"
15) "state"
16) "idle"
17) "successful_job_count"
18) "358"
19) "total_working_time"
20) "163.17717700000000007"
I wonder why first two keys aren't expired. Maybe some function, which updates worker status, is setting these values after key expiration?
marcinn
on 26 Mar 2020
That's a really good find. I think you're right, judging from the content of the key, it should be related to stats keeping mechanism.
selwin
on 26 Mar 2020
So I have found a plausible explanation for this.
Worker keys' TTL are routinely extended when jobs are being performed here: https://github.com/rq/rq/blob/master/rq/worker.py#L690 . The TTL being used by default is 35 (30 + 5).
Worker stats are updated in two locations, in handle_job_failure() and in handle_job_success(). The fact that the keys are missing many information indicates that they key has been expired from Redis before the stats are written.
If a job is killed because of timeout, the worker would have 5 seconds to finish handle_job_failure(). Depending on network or CPU conditions, this may not be enough time.
I think a quick fix for this would be to increase the TTL here to job_monitoring_interval + 90. This gives the worker 90 seconds to finish handle_job_failure(). This should fix your zombie workers problem.
Do you mind opening a PR for this?
selwin
on 26 Mar 2020
Thanks @selwin. I'm using fork of rq (because of #1216), so I can quickly apply suggested change and check results. I'll create PR if quickfix will work as expected.
marcinn
on 26 Mar 2020
@marcinn did you check if your PR solves your problem?
selwin
on 1 Apr 2020
I've tried to set hearbeat dependent on job's timeout value. Zombies are still there.
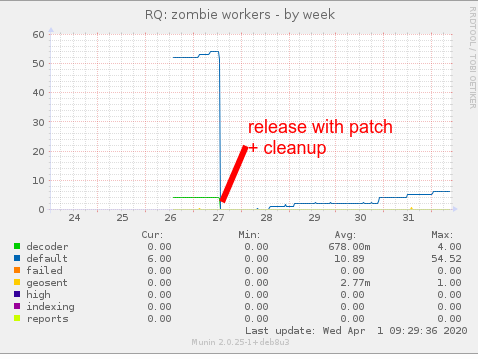
marcinn
on 1 Apr 2020
Can you try changing this line to exactly this?
self.heartbeat(self.job_monitoring_interval + 90)
selwin
on 1 Apr 2020
Yes, I'll try.
marcinn
on 1 Apr 2020
Thanks!
On 1 Apr 2020, at 15.06, Marcin Nowak notifications@github.com wrote:
Yes, I'll try.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub, or unsubscribe.
selwin
on 1 Apr 2020
Related issues
 sivabudh
·
4Comments
sivabudh
·
4Comments
 Houd1ny
·
4Comments
Houd1ny
·
4Comments
 alkalinin
·
3Comments
alkalinin
·
3Comments
 yishenggudou
·
8Comments
yishenggudou
·
8Comments
 anduingaiden
·
6Comments
anduingaiden
·
6Comments
Most helpful comment
To get the list of zombie workers we do the following:
To remove them nicely:
First we get the zombie worker object and make the job fail by doing
worker.failed_queue.quarantine(job, exc_info=("Dead worker", "Moving job to failed queue"))and then register the death of the worker:
worker.register_death()In code:
get_zombies.py
remove_zombies.py
The executing is done by doing
python get_zombies.pyI will return a list of zombie workers
and then, (in our setup is inside a docker container)