Ray: 'rollout_fragment_length' and 'truncate_episodes'
I want to check the functionality as this comment here is a bit confusing to me:
I have an episodic environment with a time wrapper that prevents it from going over 1,000 timesteps; that means, the terminal signal and reward can come at any time due to the agent succeeding or failing at the task, including at the 1,000 timestep mark.
If I set the following:
'rollout_fragment_length': 200,
'batch_mode': 'truncate_episodes',
'train_batch_size': 5000
Will all of my episodes be truncated to 200, and then accumulated until the 5,000 train_batch_size is filled, or will only the last episode that would otherwise move the train_batch_size over 5,000 be truncated?
My concern is whether or not reward signals over the 200+ timestep will be used for training.
 mimoralea
mimoralea
All 12 comments
You'll see the full rewards -- truncation is more like "chopping up", it doesn't stop the rollout of the episode until the end.
 ericl
on 19 Aug 2020
ericl
on 19 Aug 2020
Thanks, @ericl.
So, if the horizon stops the rollout of the episode, and the sgd_minibatch_size is the size that gets sampled from the training buffer of size train_batch_size, what is the purpose of this rollout_fragment_length? The comment on the variable says: # Size of batches collected from each worker.. The relevant doc section is this: https://docs.ray.io/en/latest/rllib.html?highlight=rollout_fragment_length#sample-batches
Is the purpose simply to delegate a fixed number of samples before checking whether train_batch_size has been reached or not?
mimoralea
on 20 Aug 2020
That's right, it's mostly an internal system parameter mostly, but has a couple effects:
- LSTM state is not backpropagated across rollout fragments.
- Value function is used to bootstrap rewards past the end of the sequence.
- Affects system performance (too small => high overhead, too large => high delay).
ericl
on 20 Aug 2020
Excellent. Thank you so much for the clarification.
mimoralea
on 20 Aug 2020
@ericl, help me clarifying another example case if you can.
Let's say I have an environment with a horizon of 150 timesteps (let's assume for simplicity it always takes 150 timesteps), and training settings as follows:
# assume PPO
'num_workers': 91, # 90 rollout and 1 for the trainer process
'num_envs_per_worker': 1,
'rollout_fragment_length': 100,
'batch_mode': 'truncate_episodes',
'train_batch_size': 6000
Will the trainer receive any complete episode, or will all episodes be truncated?
Here is my take:
- 90 workers x 100 samples per worker each rollout = 9,000 samples from the first batch of collection.
- The train batch size is 6,000, so the first rollout returns 3,000 more samples than requested.
Will RLlib gather as many complete episodes from a few workers, say 40 in this case (40x150=6,000) and truncate only the samples from workers 41-90, or will RLlib rollout all 90 workers in parallel and truncate from the end of the workers that took the longest to come back with the batch, say 60 workers (60x100=6,000), then truncate 61-90? Or maybe some other way?
mimoralea
on 4 Sep 2020
It's done in two phases. First, rollout workers generate rollout fragments of the specified size, and this is done completely independently per worker. Second, the fragments are concatenated, and we keep gathering fragments until the desired train batch size is reached.
So to answer your question directly, all episodes will be truncated to at most 100 steps regardless of where they came from. Some fragments will be 50 steps, some 100.
ericl
on 4 Sep 2020
Well, in the case above is unlikely that any fragment will be 50 steps, correct? Given that we have 90 workers sampling 100 steps, it is likely we will reach the 6,000 from a single rollout phase. Although, not guaranteed because say worker 1 may return the first 100 and sample the next 50 before work 17 returns the first 100 steps, correct?
mimoralea
on 4 Sep 2020
That's right, you'll have 9000 gathered right off for an algorithm like PPO. It might print a warning that the train batch size was larger than expected. For other algorithms like IMPALA the extra steps will just go to the next train batch.
Regardless since the episode is 150 steps, you'll always have 100 step and 50 step chunks. Data is never thrown away or anything like that, it's either accumulated into an extra large train batch or used for the next batch.
ericl
on 4 Sep 2020
Interesting! Wouldn't the next batch become off-policy for an algorithm like PPO or is the new policy used for the next rollout?
Say 90 workers collect 100, that's 9,000, a warning is shown, and PPO trainer samples from that training batch mini-batches according to sgd_minibatch_size and num_sgd_iter. The policy is updated, then the rollouts continue from where they stop, in the example above from timestep 101 to 150, then new episodes begin.
I think that makes sense.
mimoralea
on 4 Sep 2020
It's not really off policy, since sampling is paused until the policy is
updated for PPO. The starting state is indeed from the last episode but
that seems unlikely to cause problems.
On Thu, Sep 3, 2020, 4:36 PM Miguel Morales notifications@github.com
wrote:
Interesting! Wouldn't the next batch become off-policy for an algorithm
like PPO or is the new policy used for the next rollout?Say 90 workers collect 100, that's 9,000, a warning is shown, and PPO
trainer samples from that training batch mini-batches according to
sgd_minibatch_size and num_sgd_iter. The policy is updated, then the
rollouts continue from where they stop, in the example above from timestep
101 to 150, then new episodes begin.I think that makes sense.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/ray-project/ray/issues/10179#issuecomment-686817021,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AAADUSSZUBWJTSHUKCTE77LSEASAVANCNFSM4QDX4KRA
.
ericl
on 4 Sep 2020
Outstanding. Thank you!
mimoralea
on 4 Sep 2020
Hi,
I'm having some troubles to understand this rollout_fragment_length.... I am training in a multiagent custom environment with IMPALA and the following settings:
"lr": 0.00005,
"gamma": 1.00,
"vf_loss_coeff": 0.5,
"entropy_coeff": 0.0,
**"num_workers": 0,
"num_envs_per_worker": 4,**
"num_gpus": 1,
**"rollout_fragment_length": 100,**
**"batch_mode": "complete_episodes",**
"vtrace": False,
**"train_batch_size": 100,**
"num_sgd_iter": 1,
**"replay_proportion": 0.1,
"replay_buffer_num_slots": 20000,**
"learner_queue_size": 100,
"learner_queue_timeout": 1000,
"multiagent": {
"policies": {
"agent_0": (None, obs_space, act_space, {
"model": {
"fcnet_hiddens": [32, 64, 128, 64, 32],
"fcnet_activation": "relu",
"use_lstm": True,
"max_seq_len": 10,
"lstm_cell_size": 32,
}
}),
"agent_1": (None, obs_space, act_space, {
"model": {
"fcnet_hiddens": [32, 64, 128, 64, 32],
"fcnet_activation": "relu",
"use_lstm": True,
"max_seq_len": 10,
"lstm_cell_size": 32,
}
}),
},
With this configuration, the RL algorithm seems to train well and is very stable on 3000 different training sessions over 1M steps with different environment parameters, here is a screenshot where I repeat 10 training session for 3 different environment parameters (30 training session are plotted):
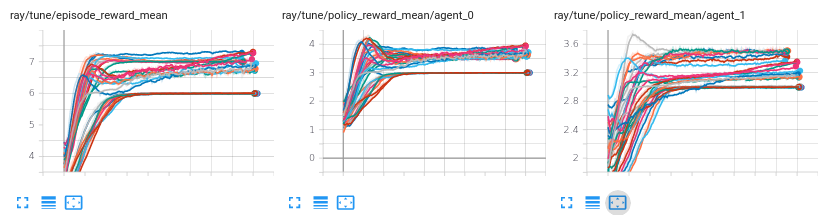
If I change the "rollout_fragment_length" parameter from 100 to 10, the RL algorithm doesn't train well, it is unstable and achieve worse performance in average, here is a screenshot with 10 training session over the same 3 different environment parameters:
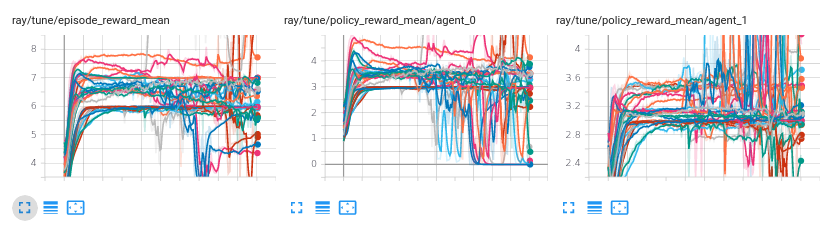
I am trying to understand why is that....
1/ With rollout_fragment_length = 10, the worker generate 3 fragments length 4*10 (because there are 4 vectorized environments), hence 12 episodes of length 10 = 120 steps. Then the first 100 steps are gathered for training to IMPALA (because train_batch_size is 100), and there are 20 remaining steps. Next, the worker generate 2 fragments of length 40, so now there are 20 old steps + 80 new steps in the buffer, which are gathered by the trainer for a new training step, and so on. Is it correct ?
2/ With rollout_fragment_length = 100, the worker generate 1 fragment of length 4*100 = 400 steps. 100 steps are gathered to the trainer for one training session. But then what ? Do the trainer uses the 300 remaining steps to do 3 more training steps ?
What would be the rational that could explain such training issue ? Also, I use LSTM of sequence length = 10... And I am quite a novice in machine learning ;-)
Thanks !
 jeanibarz
on 29 Oct 2020
jeanibarz
on 29 Oct 2020
Related issues
 robertnishihara
·
3Comments
robertnishihara
·
3Comments
 coreylowman
·
3Comments
coreylowman
·
3Comments
 zhaokang1228
·
3Comments
zhaokang1228
·
3Comments
 heavyinfo
·
3Comments
heavyinfo
·
3Comments
 1beb
·
3Comments
1beb
·
3Comments
Most helpful comment
That's right, it's mostly an internal system parameter mostly, but has a couple effects: