Ray: [rllib] Test reward much lower than training reward
I'm using the latest RLlib to train a PPO agent on a custom environment. My agent converged to a mean reward of almost 60:
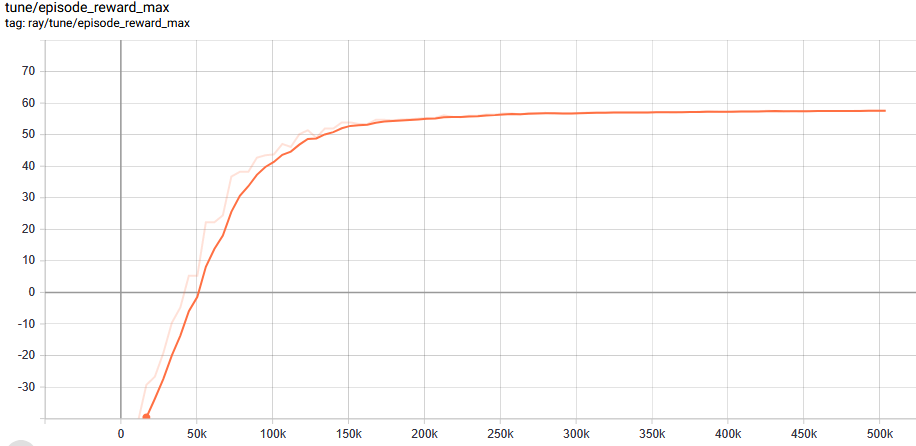
But when loading and testing the trained agent on the same environment with the same seed, the episode reward is much worse (negative!)!
I seed the environment after every reset such that each training episode should be the same, except for the agent's decisions.
I load the agent with
self.agent = PPOTrainer(config=self.config, env=self.env_class)
self.agent.restore(checkpoint_path)
For testing, I basically use a simple loop calling compute_action() as described in the docs.
I tried setting config['explore'] = False during testing, but that lead to even worse results.
Any idea what could be the issue?
 stefanbschneider
stefanbschneider
All 7 comments
My action space is gym.spaces.Discrete(x). I noticed that it works fine for x=3 or 4, ie, the train and test rewards are similar.
But for a larger scenario with x=8, I get the behavior described above that training reward is much higher than testing reward. How's that possible?
Are observations or actions processed differently when calling compute_action() compared to normal training?
stefanbschneider
on 5 Aug 2020
Hey @stefanbschneider . Would you be able to share your env here so we can debug this?
We have had similar problems reported to us from other users, but can't seem to identify the cause of this. Recently added a test for this for Pendulum.
Also, quick question: Are you setting:
config:
evaluation_config:
explore: False
?
 sven1977
on 5 Aug 2020
sven1977
on 5 Aug 2020
Sorry, I can't publicly disclose my environment at this point.
I use PPO's default config and didn't touch config['evaluation_config']; I think it's currently an empty dict. config['explore']=True during training.
stefanbschneider
on 6 Aug 2020
I digged deeper and found the cause of the problem.
To ensure that each episode is the same, I seeded the environment in every reset:
def reset(self):
random.seed(self.my_seed)
# other reset stuff
This ensured that all episodes during training where the same and all episodes during testing were the same.
However, I found that the training episodes were still different from the testing episodes.
I think the reason is that RLlib uses random during training. So even though, the same random numbers are generated in each episode by the global random RNG, different parts of these random numbers are used by the env since some are used by RLlib during training, but not during testing.
To resolve the issue, I now use a separate RNG instance in my environment that doesn't share state/random numbers with the global random generator, which is apparently used by RLlib too:
class MyEnv(gym.Env):
def __init__(self, env_config):
super().__init__()
self.my_seed = env_config['seed']
self.rng = random.Random(self.my_seed)
# ...
def reset(self):
self.rng.seed(self.my_seed)
# ....
With this, I now get the exact same env behavior in both training and testing episodes. Consequently the rewards are also similar.
Btw: This problem didn't occur when always training and testing on random episodes. And also not on small problem instances. My guess is that training on random episodes or on small problem instances, the agent still observes similar situations during training and testing and can generalize fairly well.
Only for large problem instances with fixed seed in every episode, the fixed training episode/scenario may be very different from the fixed testing episode such that the agent behaves poorly during testing.
For me, that solves the issue. I hope, this also helps others.
stefanbschneider
on 6 Aug 2020
Awesome! Thanks @stefanbschneider for describing the solution for this. This was really helpful.
sven1977
on 6 Aug 2020
Btw, @stefanbschneider are you already on our slack channel?
https://docs.google.com/forms/d/e/1FAIpQLSfAcoiLCHOguOm8e7Jnn-JJdZaCxPGjgVCvFijHB5PLaQLeig/viewform
sven1977
on 6 Aug 2020
@sven1977 Yes, thanks, I joined a few weeks ago. But haven't checked in for a while.
stefanbschneider
on 6 Aug 2020
Related issues
 coreylowman
·
3Comments
coreylowman
·
3Comments
 heavyinfo
·
3Comments
heavyinfo
·
3Comments
 xudongliao
·
3Comments
xudongliao
·
3Comments
 ericl
·
3Comments
ericl
·
3Comments
 1beb
·
3Comments
1beb
·
3Comments