Rancher: RKE clusters/Imported GKE cluster shows provisioning state for sometime after upgrading Rancher server.
What kind of request is this (question/bug/enhancement/feature request):
BUG
Steps to reproduce (least amount of steps as possible):
- install Rancher v2.1.7 in HA mode
- import a GKE cluster
- upgrade Rancher to v2.2.0-rc8
Result:
- the imported GKE cluster goes to
provisioningfor a short time, and thenunavailableand finallyactive - RKE cluster, AKS, EKS go to
unavailableand finallyactive
Other details that may be helpful:
Environment information
- Rancher version (
rancher/rancher/rancher/serverimage tag or shown bottom left in the UI): - Installation option (single install/HA):
Cluster information
- Cluster type (Hosted/Infrastructure Provider/Custom/Imported):
- Machine type (cloud/VM/metal) and specifications (CPU/memory):
- Kubernetes version (use
kubectl version):
Client Version: version.Info{Major:"1", Minor:"12", GitVersion:"v1.12.6", GitCommit:"ab91afd7062d4240e95e51ac00a18bd58fddd365", GitTreeState:"clean", BuildDate:"2019-02-26T12:59:46Z", GoVersion:"go1.10.8", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"11+", GitVersion:"v1.11.7-gke.4", GitCommit:"618716cbb236fb7ca9cabd822b5947e298ad09f7", GitTreeState:"clean", BuildDate:"2019-02-05T19:22:29Z", GoVersion:"go1.10.7b4", Compiler:"gc", Platform:"linux/amd64"}
- Docker version (use
docker version):
Client:
Version: 17.03.2-ce
API version: 1.27
Go version: go1.7.5
Git commit: f5ec1e2
Built: Tue Jun 27 03:35:14 2017
OS/Arch: linux/amd64
Server:
Version: 17.03.2-ce
API version: 1.27 (minimum version 1.12)
Go version: go1.7.5
Git commit: f5ec1e2
Built: Tue Jun 27 03:35:14 2017
OS/Arch: linux/amd64
Experimental: false
 jiaqiluo
jiaqiluo
All 53 comments
Upgraded from v2.1.7 to v2.2.0-rc8 on HA setup
It was observed that after upgrade to v2.2.0-rc8, import and rke clusters went to provisioning state.
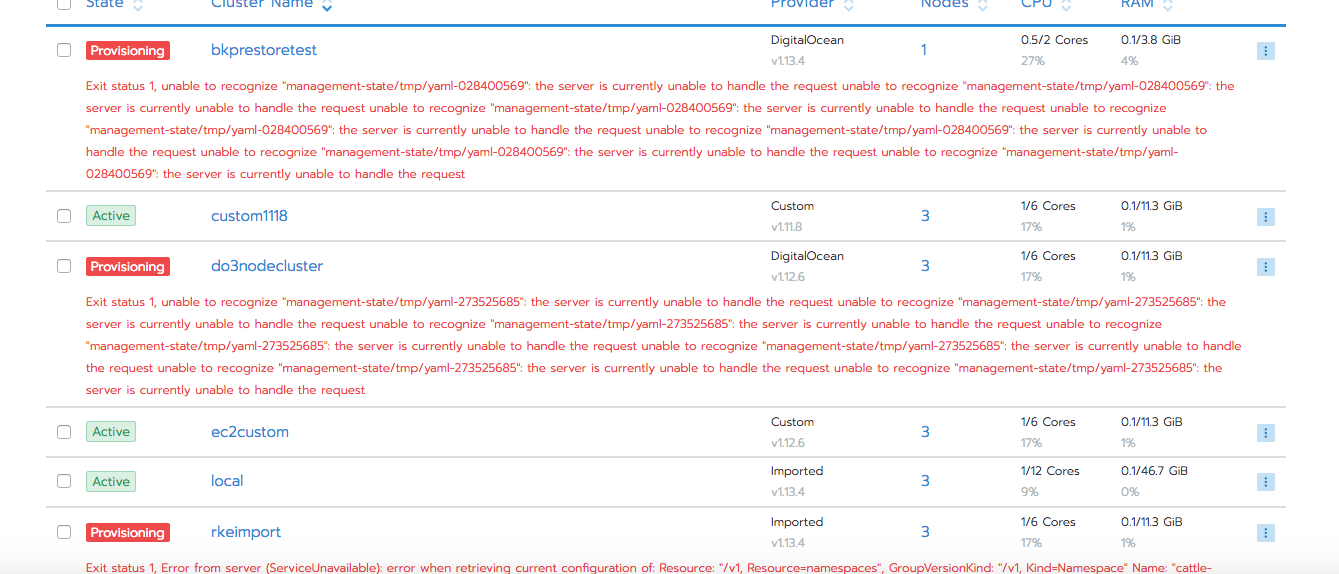
Clusters came to Active state
 soumyalj
on 21 Mar 2019
soumyalj
on 21 Mar 2019
Moving out of the release. This was seen temporarily during upgrade and is related to attempting to deploy the cluster agent. The initial deploy fails, which triggers the cluster to go into provisioning because the agentDeployed condition maps to the "provisioning" transitioning state (vendor/github.com/rancher/types/status/status.go).
Here's the condition in its failure state:
{
"lastUpdateTime": "2019-03-21T01:40:14Z",
"message": "exit status 1, unable to recognize \"management-state/tmp/yaml-348345915\": the server is currently unable to handle the request\nunable to recognize \"management-state/tmp/yaml-348345915\": the server is currently unable to handle the request\nunable to recognize \"management-state/tmp/yaml-348345915\": the server is currently unable to handle the request\nunable to recognize \"management-state/tmp/yaml-348345915\": the server is currently unable to handle the request\nunable to recognize \"management-state/tmp/yaml-348345915\": the server is currently unable to handle the request\nunable to recognize \"management-state/tmp/yaml-348345915\": the server is currently unable to handle the request\nunable to recognize \"management-state/tmp/yaml-348345915\": the server is currently unable to handle the request\n",
"reason": "Error",
"status": "False",
"type": "AgentDeployed"
},
Once we retry, deploying the agent succeeds and the cluster successfully goes active
 cjellick
on 21 Mar 2019
cjellick
on 21 Mar 2019
New single node setup on 2.2.0 has this same error. Any recommended steps to pass this blocker?
Edit 1: I've had other 2.X versions on this machine in the past
After experiencing this error I rm -rf /var/lib/rancher /etc/kubernetes and /var/lib/kubelet in an attempt to have a clean system
Next, I spun up 2.2.0 from scratch. After adding the agent to initiate provisioning, it still experiences:
Exit status 1, unable to recognize "management-statefile_path_redacted"
Hanging on This cluster is currently Updating; areas that interact directly with it will not be available until the API is ready.
Must I remove any other files on the system to have a fresh install?
Edit 2: I returned to 2.1.5, repeating the same actions above and there were no problems provisioning. I'll stick on 2.1.5 for now
 martin-kieliszek
on 13 Apr 2019
martin-kieliszek
on 13 Apr 2019
Upon upgrading from v2.1.3 to v2.2.2 some of the existing clusters went to upgrading state and it looks like RKE reconciliation was triggered.
Is this related or a different issue?
@cjellick
This cluster is currently Updating.
[workerPlane] Failed to bring up Worker Plane: [Failed to verify healthcheck: Failed to check https://localhost:10250/healthz for service [kubelet] on host [10.237.4.228]: Get https://localhost:10250/healthz: dial tcp [::1]:10250: connect: connection refused, log: ++ grep '^/var/run/']
 janeczku
on 18 Apr 2019
janeczku
on 18 Apr 2019
@galal-hussein can you look?
cjellick
on 18 Apr 2019
Had the same issue upgrading from 2.1.5 to 2.2.2. We were able to resolve it by adding a new worker node to the cluster. Once the new node had finished provisioning the error disappeared and we removed the extra node.
 avestuk
on 26 Apr 2019
avestuk
on 26 Apr 2019
I'm having this same issue when importing a managed Digital Ocean K8s cluster into rancher 2.2.2
 praveenperera
on 4 May 2019
praveenperera
on 4 May 2019
I am having the same issue in v2.1.6 on AWS. A single node install. I tried adding a worker node but the message is stuck there. Any way around it?
This is a small dev environment so for us a single node install with EBS volume appeared to be the best simple solution. I am about to do a prod infra build with 3 etcd and single node. Would like to know how to address this beforehand. Thanks
 rancheradminau
on 8 May 2019
rancheradminau
on 8 May 2019
I get same prblem, when i upgrade v2.2.2 to v2.2.4, if you upgrade with Air Gap, before upgrade, you should push image rancher/rancher-agent:v2.2.4 rancher/jimmidyson-configmap-reload:v0.2.2, and others image into your private image registry.
 ntfs32
on 8 Jun 2019
ntfs32
on 8 Jun 2019
I ran into this after trying to perform a cluster reset. Two nodes were published as the same IP address, and were disconnected. The cluster was unable to reinitialize after a reboot because the set-url needed refreshed. I cleaned up my server, using cleanup.sh, and performed a reboot.
After connecting the IP and PORT to manually set the settings and saving the server-url this started popping up. I am now deleting the effected cluster, and purging the work to start from scratch.
I apologize there isn't much to go on; I didn't expect to document this. I just wanted to share my experience in hopes of adding more detail to an open issue.
Docker version:
Client: 18.09.6
Engine - Community: 18.09.6
Rancher version: v2.2.4
Ubuntu 18.04.2 LTS (bionic)
 ragaar
on 20 Jun 2019
ragaar
on 20 Jun 2019
We experienced the same issue.
Upgrading from Rancher v2.2.3 to v2.2.4
Our Rancher instance is managing 4 clusters, and 2 got the error.
Exit status 1, unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request
All clusters where on Kubernetes v1.13.4-rancher1-2
We managed to fix the issue on the 2 erroring clusters by upgrading Kubernetes to v1.13.5-rancher1-3
 danielbjornadal
on 27 Jun 2019
danielbjornadal
on 27 Jun 2019
After upgrade single node cluster from 2.2.4 to 2.2.5.
In node setup external ip and it seems to prevent the node from connecting to the server
This cluster is currently Provisioning; areas that interact directly with it will not be available until the API is ready.
Exit status 1, unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request
 aleksey005
on 16 Jul 2019
aleksey005
on 16 Jul 2019
I wanted to open a new issue but it seems to be covered here, as @aleksey005 I updated my rancher server from 2.2.4 to 2.2.5 and got the same error message. Currently blocked to access any of my services.
 dutangp
on 17 Jul 2019
dutangp
on 17 Jul 2019
After restarting the node and the managing server, the error disappeared and the cluster was updated. Updating on the other two clusters (Custom 3 and 6 nodes) from 2.2.4 to 2.2.5 did not cause this error
aleksey005
on 17 Jul 2019
I should had wait for your comment, I am recreating the full cluster. I have few others to update, I will try what you said and keep you updated. Anyway I don't think this is a beautiful workaround.
dutangp
on 17 Jul 2019
ok I confirm everything works fine now, I did what you told me
dutangp
on 17 Jul 2019
I seem to be having this issue as well after upgrading Rancher 2.2.4 -> 2.2.5 in all but one cluster.
I installed a new SSL cert for the Rancher server as the default self-signed one was due to expire in August. I switched to one signed by an internal CA instead.
I've yet been able to get the clusters to recover. I've tried restarting a master node, no luck. I've restarted the rancher server, no luck.
Any thoughts?
 MaxDiOrio
on 19 Jul 2019
MaxDiOrio
on 19 Jul 2019
@MaxDiOrio I came across this and I had to reinstall the cluster, then I made a rollback through snapshot.
aleksey005
on 20 Jul 2019
Yikes - I have about 10 clusters, some in production with a public facing website. Any way to do this without blowing away the cluster?
MaxDiOrio
on 20 Jul 2019
https://github.com/rancher/rancher/issues/20994
maybe this will help you?
aleksey005
on 20 Jul 2019
I actually got most of the clusters fixed up finally. My GKE clusters needed to be deleted and re-imported since they were custom and I don't have access to the control plane.
I now only have issues with my dev windows cluster and a test rook cluster that I can delete and re-create as they weren't in production.
Which means only one cluster left that is giving me a problem and I don't think it's related. After I did the Rancher upgrade and logged in, it said the certs needed to be rotated on the cluster. I did this, then it lost the old certs somehow, or at least is complaining it lost them. Can't recover this cluster like I did the others because of this.
Failed to rotate certificates: can't find old certificates
MaxDiOrio
on 20 Jul 2019
Once again I come to the conclusion that the cluster deployment should be automated, the services along with the cluster should be deployed simultaneously and the data migrate to the new cluster ...
aleksey005
on 20 Jul 2019
FYI - I finally got the last cluster back up. I had to manually replace the root ca cert in /etc/kubernetes/ssl/certs/serverca and bounce the nodes. They all came up fine after that.
MaxDiOrio
on 22 Jul 2019
@MaxDiOrio this made possible by penetration into the container file system? but how did you secure the checksums of the containers? unfortunately, leaving the container is still possible due to hardware vulnerabilities, which is why it is important to protect not only bash, but also what is designed to be vulnerable.
aleksey005
on 22 Jul 2019
Nope - has nothing to do with the containers. This was on the node filesystem itself.
MaxDiOrio
on 22 Jul 2019
Yes, I understand that. But only that it is possible to replace the certificate inside the file system so that the cluster remains in the same consistency already raises doubts about security. In a good system, it is impossible to replace the certificate so that the work of the program does not break ...
aleksey005
on 23 Jul 2019
21806 and before I received the message Exit status 1, unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request
aleksey005
on 26 Jul 2019
Same issue.. Ended up deleting and re-importing the cluster.. Not ideal as it blew away all of the project associations and references to apps.
 ananth-racherla
on 27 Jul 2019
ananth-racherla
on 27 Jul 2019
I had to use the following resuscitation procedure.
$create new vm rancher
$scp rancher-data-backup-* rancher@rancher:/home/rancher
$ssh rancher@rancher
$sudo docker run -d --restart=unless-stopped -p 80:80 -p 443:443 rancher/rancher:latest --acme-domain domain.example.com
$sudo docker ps
$sudo docker stop modest_curie
$sudo docker create --volumes-from modest_curie --name rancher-data rancher/rancher:latest
$sudo docker run --volumes-from rancher-data -v $PWD:/backup alpine sh -c "rm /var/lib/rancher/* -rf && tar zxvf /backup/rancher-data-backup-v2.2.5-26072019.tar.gz
$sudo docker run -d --volumes-from rancher-data --restart=unless-stopped -p 80:80 -p 443:443 rancher/rancher:latest --acme-domain domain.example.com
Yesterday everything was working fine. Today I completely wiped all docker containers and started clean. I go this exact error. :/ I've tried adding nodes, I've tried changing things around. I don't understand how it can break from yesterday, even though I haven't updated anything. What is the solution to this issue, because I can't really find it...
 half2me
on 2 Aug 2019
half2me
on 2 Aug 2019
Avter upgrade cluster v2.2.6 -> v2.2.7
This cluster is currently Provisioning; areas that interact directly with it will not be available until the API is ready.
Exit status 1, unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request
aleksey005
on 8 Aug 2019
same issue :
Exit status 1, unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized ; waiting for nodes; exit status 1, unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized
 nagaland88
on 12 Aug 2019
nagaland88
on 12 Aug 2019
same issue:
This cluster is currently Provisioning; areas that interact directly with it will not be available until the API is ready.
Exit status 1, unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized ; Waiting for API to be available; exit status 1, unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized unable to recognize "management-statefile_path_redacted": Unauthorized
 bale836
on 20 Aug 2019
bale836
on 20 Aug 2019
I ran into the same issue when upgrading from v2.2.7 to v2.2.8
I suspect it's because my cluster was overloaded with too many imported GKE clusters trying to reconnect/reconcile. So the cattle-cluster-agent pod didn't try to reconnect.
I was able to solve this by deleting the cattle-cluster-agent pod on each imported cluster that failed to reconnect.
 bluemalkin
on 21 Aug 2019
bluemalkin
on 21 Aug 2019
My issue was resolved by following the guide here: https://rancher.com/docs/rancher/v2.x/en/cluster-admin/cleaning-cluster-nodes/ I had a load of mounts, interfaces, and files left over from previous testing. After I cleaned out everything, it worked fine. Guess I just have to read the documentation next time :)
half2me
on 4 Sep 2019
My issue was resolved by following the guide here: https://rancher.com/docs/rancher/v2.x/en/cluster-admin/cleaning-cluster-nodes/ I had a load of mounts, interfaces, and files left over from previous testing. After I cleaned out everything, it worked fine. Guess I just have to read the documentation next time :)
Hi @half2me ,
and you had the same _'Exit status 1, unable to recognize "management-statefile_path_redacted"'_ issue? Cleaning everything sounds like we will end up in a fresh installation .... but i will use the System in the same configuration and the same cluster. Do you have a minute and describe what you did? That would help me a lot ! Thanks ! :)
 v15170r
on 4 Sep 2019
v15170r
on 4 Sep 2019
@v15170r I was only running this for testing, so I had no data on there that I wanted to preserve. I know wiping everything isn't exactly a solution for everyone. To be honest I don't know exactly which step made the difference, but my guess is one of the files that were left behind after an old installation caused the issue.
- I wiped all docker containers networks and volumes
- Unmounted all mounts from kubelet
Removed directories:
rm -rf /etc/ceph \
/etc/cni \
/etc/kubernetes \
/opt/cni \
/opt/rke \
/run/secrets/kubernetes.io \
/run/calico \
/run/flannel \
/var/lib/calico \
/var/lib/etcd \
/var/lib/cni \
/var/lib/kubelet \
/var/lib/rancher/rke/log \
/var/log/containers \
/var/log/pods \
/var/run/calico
I removed an old interface I had left behind from calico:
ip link delete interface_name
Thats all I did.
half2me
on 5 Sep 2019
same issue :
This cluster is currently Provisioning.
Exit status 1, unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request
 iDube
on 16 Sep 2019
iDube
on 16 Sep 2019
I'm stuck with the same issue trying to upgrade from v2.0.8 to the latest version:
Exit status 1, unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": ; failed to get Kubernetes server version: Get https://11.120.101.90:6443/version?timeout=32s: can not build dialer to c-4pjwd:m-84bda8fb86ba
Note: I can get to https://11.120.101.90:6443/version?timeout=32s just fine, it loads a page (self signed cert) with the following:
{
"major": "1",
"minor": "11",
"gitVersion": "v1.11.2",
"gitCommit": "bb9ffb1654d4a729bb4cec18ff088eacc153c239",
"gitTreeState": "clean",
"buildDate": "2018-08-07T23:08:19Z",
"goVersion": "go1.10.3",
"compiler": "gc",
"platform": "linux/amd64"
}
I've tried adding a worker node which isn't working:
ERROR: https://mdc2vr018:9443/ping is not accessible (Failed to connect to mdc2vr018 port 9443: Connection refused)
I'm stuck and would greatly appreciate any help with this issue.
 tonyturino
on 20 Sep 2019
tonyturino
on 20 Sep 2019
@cjellick Any updates on this ? Our cluster is still stuck with the above error
nagaland88
on 1 Oct 2019
I have the same issue upgrading from 2.3.0-rc8 to 2.3.0 (final) on rancher with imported gke cluster
 pirminjanka
on 9 Oct 2019
pirminjanka
on 9 Oct 2019
Same issue when upgrading from Rancher 2.2.8 to 2.3.0 (single node install), and 2.2.8 to 2.3.2 (HA install)
Followup:
This issue on the single node install disappeared after a few days, I don't know what happened but nothing has been changed by me
The newly-upgraded HA cluster is now giving me this on the UI:
Exit status 1, unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request
--
 Jamesits
on 12 Oct 2019
Jamesits
on 12 Oct 2019
Opened & closed #23855 same issue; think that stable tag was a tad premature.
Same issue from 2.2.9 to 2.3.2
 ChrisMcKee
on 4 Nov 2019
ChrisMcKee
on 4 Nov 2019
Just saw this going from v2.3.0 -> v2.3.2. I guess the consensus right now is that there's no good way to fix this aside from rebuilding the cluster?
Edit: turns out I goofed. During the upgrade, I changed the port the Rancher container was listening on but forgot to also change it in the Rancher UI. Not sure if just changing the port would have even worked (since the nodes were expecting the old port), but I ended up rebuilding the cluster anyway.
🤷♂️
 r734
on 7 Nov 2019
r734
on 7 Nov 2019
I met this bug with error info
Exit status 1, unable to recognize "management-statefile_path_redacted": no matches for kind "ClusterRole" in version "rbac.authorization.k8s.io/v1" unable to recognize "management-statefile_path_redacted": no matches for kind "ClusterRoleBinding" in version "rbac.authorization.k8s.io/v1" unable to recognize "management-statefile_path_redacted": no matches for kind "Namespace" in version "v1" unable to recognize "management-statefile_path_redacted": no matches for kind "ServiceAccount" in version "v1" unable to recognize "management-statefile_path_redacted": no matches for kind "ClusterRoleBinding" in version "rbac.authorization.k8s.io/v1beta1" unable to recognize "management-statefile_path_redacted": no matches for kind "Secret" in version "v1" unable to recognize "management-statefile_path_redacted": no matches for kind "ClusterRole" in version "rbac.authorization.k8s.io/v1" unable to recognize "management-statefile_path_redacted": no matches for kind "Deployment" in version "extensions/v1beta1" unable to recognize "management-statefile_path_redacted": no matches for kind "DaemonSet" in version "extensions/v1beta1"
so confused...
 satomic
on 11 Nov 2019
satomic
on 11 Nov 2019
Any solution for this? I have this problem after changing my https certificates to the new ones.
[ERROR] ClusterController c-j5q9b failed to start user controllers for cluster c-4xfbq: failed to contact server: Get https://10.0.100.161:6443/api/v1/namespaces/kube-system?timeout=30s: waiting for cluster agent to connect, failed to start user controllers for cluster c-j5q9b: failed to contact server: Get https://10.0.50.163:6443/api/v1/namespaces/kube-system?timeout=30s: waiting for cluster agent to connect
I started the new cluster yesterday and still has 1 node because of testing.

 kobozo
on 12 Dec 2019
kobozo
on 12 Dec 2019
If this happens when you recreate a node, it's probably because host hasn't been properly cleaned up, like mentioned by @half2me here above. But hard to find amid similar complaints ;)
My issue was resolved by following the guide here: https://rancher.com/docs/rancher/v2.x/en/cluster-admin/cleaning-cluster-nodes/ I had a load of mounts, interfaces, and files left over from previous testing. After I cleaned out everything, it worked fine. Guess I just have to read the documentation next time :)
 scndel
on 14 Mar 2020
scndel
on 14 Mar 2020
I met this bug with error info
Exit status 1, unable to recognize "management-statefile_path_redacted": no matches for kind "ClusterRole" in version "rbac.authorization.k8s.io/v1" unable to recognize "management-statefile_path_redacted": no matches for kind "ClusterRoleBinding" in version "rbac.authorization.k8s.io/v1" unable to recognize "management-statefile_path_redacted": no matches for kind "Namespace" in version "v1" unable to recognize "management-statefile_path_redacted": no matches for kind "ServiceAccount" in version "v1" unable to recognize "management-statefile_path_redacted": no matches for kind "ClusterRoleBinding" in version "rbac.authorization.k8s.io/v1beta1" unable to recognize "management-statefile_path_redacted": no matches for kind "Secret" in version "v1" unable to recognize "management-statefile_path_redacted": no matches for kind "ClusterRole" in version "rbac.authorization.k8s.io/v1" unable to recognize "management-statefile_path_redacted": no matches for kind "Deployment" in version "extensions/v1beta1" unable to recognize "management-statefile_path_redacted": no matches for kind "DaemonSet" in version "extensions/v1beta1"so confused... I meet the same problem
 autumn1023
on 22 Mar 2020
autumn1023
on 22 Mar 2020
当前集群Provisioning中...
Exit status 1, unable to recognize "management-statefile_path_redacted": no matches for kind "ClusterRole" in version "rbac.authorization.k8s.io/v1" unable to recognize "management-statefile_path_redacted": no matches for kind "ClusterRoleBinding" in version "rbac.authorization.k8s.io/v1" unable to recognize "management-statefile_path_redacted": no matches for kind "Namespace" in version "v1" unable to recognize "management-statefile_path_redacted": no matches for kind "ServiceAccount" in version "v1" unable to recognize "management-statefile_path_redacted": no matches for kind "ClusterRoleBinding" in version "rbac.authorization.k8s.io/v1beta1" unable to recognize "management-statefile_path_redacted": no matches for kind "Secret" in version "v1" unable to recognize "management-statefile_path_redacted": no matches for kind "ClusterRole" in version "rbac.authorization.k8s.io/v1" unable to recognize "management-statefile_path_redacted": no matches for kind "Deployment" in version "apps/v1" unable to recognize "management-statefile_path_redacted": no matches for kind "DaemonSet" in version "apps/v1"
autumn1023
on 22 Mar 2020
Hello,
I had this issue at my office and fixed it today but it was not easy. So In my case I was upgrading to the latest cert-manager as well as 2.2.4 from 2.1.8.
The steps I took to fix my system
1.) rotate the certs on all the k8s in the worker cluster. This took ~10 minutes to permeate through the system
2.) once the control pane and etcd nodes come up clean the workers were showing unavailable. A reboot of the hosts brought them back in line
Then all my workloads started back up and I was back on the road. Not a smooth update process but it could have been worse. Hope this helps someone.
 Ismarticus
on 16 Apr 2020
Ismarticus
on 16 Apr 2020
I experienced this but had already upgraded my cluster from a week or so ago!
The only thing I was doing was bringing new Worker Nodes into and out of the cluster for some prototyping of an autoscaling behavior.
Out of no where, I get the error that everyone else is referencing.
Given my scenario, I am not sure its strictly at the time of an upgrade and might be more related to when Nodes actually bootstrap to the cluster.
I should also note I tried to restore from etcd snapshot and it failed to find older nodes that used to be part of the cluster --> i think this is a result of me selecting the 3rd option when restoring from etcd, which includes restoring the kubernetes version and the cluster config (which wasn't necessary given the cluster had upgraded weeks ago)
 zbialik
on 19 Jun 2020
zbialik
on 19 Jun 2020
Here is a clean up script that might help:
docker rm -f $(docker ps -qa)
docker rmi -f $(docker images -q)
docker volume rm $(docker volume ls -q)
for mount in $(mount | grep tmpfs | grep '/var/lib/kubelet' | awk '{ print $3 }') /var/lib/kubelet /var/lib/rancher; do umount $mount; done
rm -rf /etc/ceph \
/etc/cni \
/etc/kubernetes \
/opt/cni \
/opt/rke \
/run/secrets/kubernetes.io \
/run/calico \
/run/flannel \
/var/lib/calico \
/var/lib/etcd \
/var/lib/cni \
/var/lib/kubelet \
/var/lib/rancher/rke/log \
/var/log/containers \
/var/log/kube-audit \
/var/log/pods \
/var/run/calico
sudo reboot
 joehoeller
on 5 Sep 2020
joehoeller
on 5 Sep 2020
Here is a clean up script that might help:
docker rm -f $(docker ps -qa) docker rmi -f $(docker images -q) docker volume rm $(docker volume ls -q) for mount in $(mount | grep tmpfs | grep '/var/lib/kubelet' | awk '{ print $3 }') /var/lib/kubelet /var/lib/rancher; do umount $mount; done rm -rf /etc/ceph \ /etc/cni \ /etc/kubernetes \ /opt/cni \ /opt/rke \ /run/secrets/kubernetes.io \ /run/calico \ /run/flannel \ /var/lib/calico \ /var/lib/etcd \ /var/lib/cni \ /var/lib/kubelet \ /var/lib/rancher/rke/log \ /var/log/containers \ /var/log/kube-audit \ /var/log/pods \ /var/run/calico sudo reboot
This solution worked in an airgap environment. No need to delete all images or reboot, slightly overkill. I believe this happens b/c the user that rancher creates is not removed properly. In our environment we were making and destroying the rancher container over and over again and connecting an agent. One of the removed directories above is what solves this completely.-my guess is the kubelet directory at a glance, but i haven't done much digging. I hope this helps someone.
 JoeBartelmo
on 17 Nov 2020
JoeBartelmo
on 17 Nov 2020
Related issues
 dmzaytsev
·
63Comments
dmzaytsev
·
63Comments
 jasonsoft
·
42Comments
jasonsoft
·
42Comments
 niranjan94
·
53Comments
niranjan94
·
53Comments
 bfosberry
·
54Comments
bfosberry
·
54Comments
 gary-skwirrel
·
47Comments
gary-skwirrel
·
47Comments
Most helpful comment
Avter upgrade cluster v2.2.6 -> v2.2.7
Exit status 1, unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request unable to recognize "management-statefile_path_redacted": the server is currently unable to handle the request