Pytorch3d: Point Cloud backward pass is 30 times slower that forward Pass
During Point Cloud rendering with a cuda device I noticed a 30 times slower backward pass comparing to the forward pass I consider this being unexpected combining with the fact that the profiling showed an abnormal use of the CPU.
More specifically the attached script produces the following results in a 1080 GPU:
Backward 1.3152024745941162
Forward 0.05700278282165527

Instructions To Reproduce the Issue:
I am using the following SHA: e37085d9990bf94c7fcee6a9df5dc8db35391608
I also uploaded a script as minimal as possible that reproduces the issue and you will need to download the following point-cloud file which I took from one of the demos uploaded in the repository, you will need to store it in the same path as the python script.
script: https://www.codepile.net/pile/2WEPleby
point-cloud: https://dl.fbaipublicfiles.com/pytorch3d/data/PittsburghBridge/pointcloud.npz
 grgkopanas
grgkopanas
All 4 comments
CUDA kernels can execute asynchronously with host code in Python, so when running timing benchmarks you need to insert explicit synchronization calls to get correct timing information.
Can you try changing this:
import time
time1 = time.time()
loss, _ = model()
time2 = time.time()
loss.backward()
time3 = time.time()
print("Backward {}".format(time3-time2))
print("Forward {}".format(time2-time1))
time1 = time.time()
loss, _ = model()
time2 = time.time()
loss.backward()
time3 = time.time()
print("Backward {}".format(time3-time2))
print("Forward {}".format(time2-time1))
To this:
import time
torch.cuda.synchronize()
time1 = time.time()
loss, _ = model()
torch.cuda.synchronize()
time2 = time.time()
loss.backward()
torch.cuda.synchronize()
time3 = time.time()
print("Backward {}".format(time3-time2))
print("Forward {}".format(time2-time1))
torch.cuda.synchronize()
time1 = time.time()
loss, _ = model()
torch.cuda.synchronize()
time2 = time.time()
loss.backward()
torch.cuda.synchronize()
time3 = time.time()
print("Backward {}".format(time3-time2))
print("Forward {}".format(time2-time1))
and see if you see the same slowdown?
 jcjohnson
on 7 Apr 2020
jcjohnson
on 7 Apr 2020
Hi, thanks for your thoughtful answer, I thought that even if my cuda kernels were not fully synchronized the bottleneck tool that I did the profiling with would insert proper synchronization.
Indeed the cuda synchronization changed the times but it switched the bottleneck to the forward pass:
Backward 0.024988412857055664
Forward 1.7400264739990234
Backward 0.013993501663208008
Forward 1.3462226390838623
Also it is surprising that the bottleneck tool also changed the reports by a lot, the new report is here:
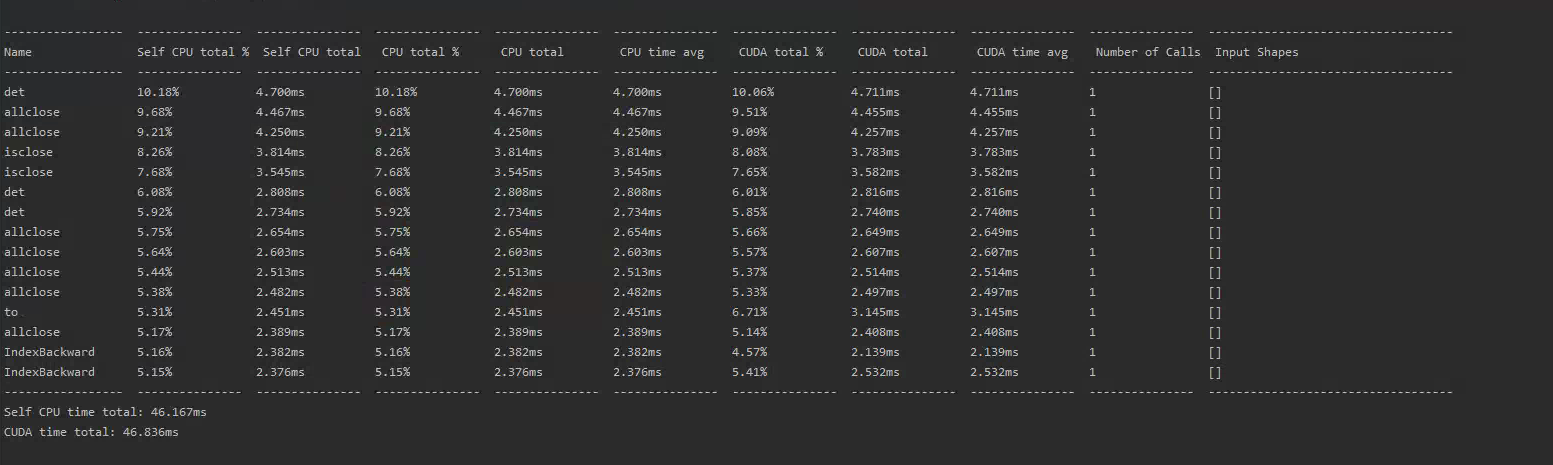
In the report the fact that we only see things in ms while the FW pass takes more than a second raises some questions.
Is there a way to find out why there is such a big discrepancy between the forward and the backward pass?
grgkopanas
on 7 Apr 2020
Ok, these numbers look more reasonable.
For the pointcloud rasterizer I'd expect the forward pass to be much slower than the backward pass, because it does more work. The forward pass needs to check every point against every pixel in order to find the nearest K points in depth, so it's complexity is something like O(number_of_points * number_of_pixels). In contrast the backward pass only needs to pass gradients to these K nearest points, so its complexity is something like O(K * number_of_pixels).
From another look at your code, it seems that you are using the "naive" forward pass implementation for the point cloud rasterizer. You should remove the bin_size argument from your raster_settings; this will invoke the more efficient binned forward pass, which should be significantly faster.
jcjohnson
on 7 Apr 2020
Thanks a lot, it makes sense to have different order of magnitudes between passes then. Closing the ticket.
grgkopanas
on 7 Apr 2020
Related issues
 unlugi
·
3Comments
unlugi
·
3Comments
 eliemichel
·
3Comments
eliemichel
·
3Comments
 udemegane
·
3Comments
udemegane
·
3Comments
 aluo-x
·
3Comments
aluo-x
·
3Comments
 ldepn
·
3Comments
ldepn
·
3Comments
Most helpful comment
Ok, these numbers look more reasonable.
For the pointcloud rasterizer I'd expect the forward pass to be much slower than the backward pass, because it does more work. The forward pass needs to check every point against every pixel in order to find the nearest K points in depth, so it's complexity is something like O(number_of_points * number_of_pixels). In contrast the backward pass only needs to pass gradients to these K nearest points, so its complexity is something like O(K * number_of_pixels).
From another look at your code, it seems that you are using the "naive" forward pass implementation for the point cloud rasterizer. You should remove the
bin_sizeargument from yourraster_settings; this will invoke the more efficient binned forward pass, which should be significantly faster.