This is the requirement for Crossref Reference Linking and thus also Cited-By (I think).
If a journal is using the citations input field, it is likely that a parsing each reference for them would be fine i.e. they could have use of it.
Thus maybe to move the citations input field to a new tab in the submission metadata/catalog entry modal for editors, where they will have the possibility to parse the citations and save them (separately). This way the submission metadata forms for authors and reviewers can stay the same -- they will see only the citations input field (and not the parsed citations), that is read-only as soon as the submission is submitted. Originally we though of having a new button on the production page, that will open the modal, but maybe to keep them close to other metadata, because the citations have been considered/used with other submission metadata till now.
For now the citations would be parsed by line, displayed in the modal as a list and single citations saved as such. I.e. if something has to be changed, the changes will have to be done in the citations input field.
In the future we can eventually allow managing (e.g. editing and sorting) of the single citations.
So parsed and saved single citations would/could be used for the display on the article page, as well as in the Crossref export (which will be another/different issue).
 bozana
bozana
All 22 comments
This is how the citations tab could look like, for now, for example:
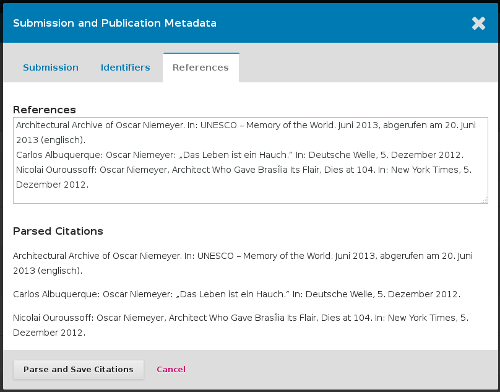
@NateWr, what do you think about this? Would it be OK to have it first/for now like this?
bozana
on 8 Nov 2017
Looks good. I'm trying to think of a better user-facing term to use than "parsed", but struggling to come up with anything. Maybe we can add a description which says something like:
The following references have been extracted and will be automatically linked to the submission metadata for citation tracking (or whatever's happening).
 NateWr
on 8 Nov 2017
NateWr
on 8 Nov 2017
PRs:
pkp-lib master: https://github.com/pkp/pkp-lib/pull/3033
ojs master: https://github.com/pkp/ojs/pull/1674
omp master: https://github.com/pkp/omp/pull/466
one more fix, the citations required form validation:
pkp-lib master: https://github.com/pkp/pkp-lib/pull/3138
ojs master: https://github.com/pkp/ojs/pull/1733 (only submodule update)
bozana
on 9 Nov 2017
@NateWr, could you take a look at the PRs above?
We could provide better explanation if needed. Would you have a suggestion?
For citation display on the article/book page, I first look if there are parsed citations and display them. If there are no parsed citations, I look if there is submission->getCitations(), in case someone does not want or forget to parse them. I am not sure if we should do/keep it like this? We could also say that we expect all of them to be parsed?
Also, I use HTML p element for the display of parsed citations and I am not sure if it should maybe be something else?
I provided a tool/script for bulk parsing of the citations (several submissions, journals or all). I am not sure if we should keep the script in the release or just provide it externally?
@asmecher, I removed the two columns (citation_state and lock_id) from the DB table citations, because they are not used at the moment. I am not sure what this would mean for those that had used Citation Assistant (if anybody had used it) -- I hope nothing, because all this is not used any more.
Also, the entries in the DB table citations have not been migrated yet and I am not sure what to do with them: shall I adapt the assoc_types there, or just leave those old entries there, or even remove all old entries there? -- I believe those old entries could maybe contain some NLM XML?, that the user surely do not want to display at the article/book page. If the Citation Assistant was not used, the table could also contain just the normal citations from OJS 2.4.x. However, there is a tool/script for bulk parsing of the citations, so a) if we adapt the assoc_types and user does not like the old citations, he/she could re-parse them, b) if we leave them with old assoc_types or remove them from the DB, the user can parse and create them anew.
What do you think?
bozana
on 9 Nov 2017
The PRs look good. Just a few minor comments. A couple additional thoughts:
I don't know how much we want to put into this, but I wondered if we could automatically link up URLs in the references? Particularly for DOIs.
I noticed that numbers get stripped from the beginning of a reference. Will this cause problems for journals that publish with numbered references (ie - Endnotes/Footnotes)?
We could provide better explanation if needed. Would you have a suggestion?
I think it's good. I made some minor suggestions.
For citation display on the article/book page, I first look if there are parsed citations and display them. If there are no parsed citations, I look if there is submission->getCitations(), in case someone does not want or forget to parse them. I am not sure if we should do/keep it like this? We could also say that we expect all of them to be parsed?
I think it's good to have the fallback.
Also, I use HTML p element for the display of parsed citations and I am not sure if it should maybe be something else?
👍
I provided a tool/script for bulk parsing of the citations (several submissions, journals or all). I am not sure if we should keep the script in the release or just provide it externally?
I don't know either! What do we do with our other tools?
NateWr
on 15 Nov 2017
Thanks a lot @NateWr! I'll go through the suggestions/comments...
I don't know how much we want to put into this, but I wondered if we could automatically link up URLs in the references? Particularly for DOIs.
I can try to do that.
After this is merged, I will work on Crossref reference linking: the extracted citations will be registered at Crossref and then the Crossref will search for the citations DOIs and return them back. Then we will have to add the found DOIs at the end of the citations. I am not sure what to do in case where a citation already contains a DOI :-(
I noticed that numbers get stripped from the beginning of a reference. Will this cause problems for journals that publish with numbered references (ie - Endnotes/Footnotes)?
I would think that this is maybe not so important -- those numbers are actually not so important in OJS and for sending citations to Crossref or wherever else.
Maybe we could add a anchor before every citations, e.g. cit1, cit2, etc. so that the users can reference it from somewhere if needed?
Else, if used as Endnotes/Footnotes, maybe they should be contained in the full text document as such?
So maybe to leave it for now as it is?
bozana
on 15 Nov 2017
I am not sure what to do in case where a citation already contains a DOI
Actually, it'd be good if we can replace the URLs in the reference text where they exist, instead of appending them, since everyone will have their own preferred citation style.
So maybe to leave it for now as it is?
Sure, we can add more logic if it's actually a use-case.
NateWr
on 15 Nov 2017
@bozana, sorry to be coming at this late, but I think that without the citation assistant the citations table etc. will never get populated. Citation data should still be available per the submissions.citations column, as filled in from the metadata form, but we don't have anything in OJS to replace the citation assistant in terms of parsing/using more fine-grained citation information. At a high level, we've spoken about a few different directions:
- Using the CrossRef citation parser to break the block of citations into finer-grained detail
- The same, but with the Google Scholar parser
- Relying on OTS
Broadly speaking, I don't think we've made any inroads into any of these yet, e.g. in getting OJS to display any richer information that may be available to it.
 asmecher
on 16 Nov 2017
asmecher
on 16 Nov 2017
@NateWr, I made the changes suggested in the code review (one commit) and tried to replace the URLs through the HTML links (another commit).
In order to display those HTML links I then use strip_unsafe_html. This only works, if really HTML links are used, s. the comment from Clinton here: https://github.com/pkp/pkp-lib/issues/2570#issuecomment-310472854. Currently the URLs are always replaced, so that I think that it is safe/correct to proceed like that.
The URLs are only replaced in the extracted/parsed citations. The text inserted in the textarea citations field by the user stays the same. On the one side, this means that the HTML links will not be used/displayed as such if the user did not parse/extracted those citations -- we just display the textarea content as it is. On the other side, this is good so -- that way we always have the original.
And finally, I am not sure if it is good to save the replaced URLs in the DB table or maybe just to do the replacement for the display -- I am not sure if those HTML links are not good to be sent to Crossref or somewhere else... Hmmm... What do you think?
THANKS a lot!
bozana
on 22 Nov 2017
In order to display those HTML links I then use strip_unsafe_html
What happens with a reference that contains something like <http://anything.com>?
The URLs are only replaced in the extracted/parsed citations.
:+1:
And finally, I am not sure if it is good to save the replaced URLs in the DB table or maybe just to do the replacement for the display -- I am not sure if those HTML links are not good to be sent to Crossref or somewhere else... Hmmm... What do you think?
I don't know anything about Crossref, but I think you're right that this is a display technique. I'd say save them "plain" in the database and make the conversion before passing to the template.
NateWr
on 22 Nov 2017
the example would be converted like this <<a href="http://anything.com">http://anything.com</a>>. OK?
bozana
on 22 Nov 2017
@NateWr, I implemented a function in the class Citation that replaces URLs with HTML links and it is called for the display in OJS and OMP. The parsed/extracted citations are saved as they are in the DB... Could you please take hopefully the last look? :-)
THANKS!!!
bozana
on 22 Nov 2017
@bozana I took another pass at the code and it looks good. Just tested out your latest changes and they're working well, except the href of the links isn't coming out right. In my test it came out like:
<a href="%5C">https://doi.org/10.1073/pnas.0907862106</a>
This is the text file I'm using for citations. I just pulled them from an eLife article and did some basic formatting to put one per line.
NateWr
on 22 Nov 2017
Ah, I know where the problem is: you change the " to ' and forget not to escape the other "s and there is a problem... fix coming... sorry :-(
bozana
on 22 Nov 2017
The fix committed: https://github.com/pkp/pkp-lib/pull/3033/commits/1b141570126c5d41b637d9d199efe7204a9e1bb4
bozana
on 22 Nov 2017
Hmmm... To find out where the URL ends, I look after these characters: ) [ ] { } , ; " ' : < > . and space. But in your example there is for example such an URL: https://doi.org/10.1016/S0092-8674(00)81518-4 i.e. containing ). Hmmm... I do not know if there is any 100% way to deal with all this... ?
bozana
on 22 Nov 2017
OK, I think I found even better solution -- those characters have to be followed by space...
bozana
on 22 Nov 2017
Yeah this is tough. I would maybe err on the side of caution and only seek out characters not allowed in the RFC, as specified here: https://stackoverflow.com/questions/1547899/which-characters-make-a-url-invalid.
(Just saw your comment. :+1:)
NateWr
on 22 Nov 2017
This change improves the URL end detection a little bit better: https://github.com/pkp/pkp-lib/pull/3033/commits/8b1d8a76dd06a507f52415499a624ca1404ea549 -- it solves the problem from the example above...
bozana
on 22 Nov 2017
:+1: That was the last comment I had on the PRs. You can merge when you'd like.
NateWr
on 22 Nov 2017
Thanks a lot @NateWr! I'll wait for tests to pass and merge then... I believe I blocked Travis for the whole night with my 100000 pushes... :-(
bozana
on 22 Nov 2017
@bozana, regarding the CLI tool (https://github.com/pkp/pkp-lib/blob/master/tools/parseCitations.php) -- I don't see any harm in including it...
asmecher
on 27 Nov 2017
Related issues
NateWr
·
5Comments
 ajnyga
·
7Comments
ajnyga
·
7Comments
 mtub
·
6Comments
mtub
·
6Comments
 sssoz
·
3Comments
sssoz
·
3Comments
 jmacgreg
·
5Comments
jmacgreg
·
5Comments
Most helpful comment
This is how the citations tab could look like, for now, for example:
@NateWr, what do you think about this? Would it be OK to have it first/for now like this?