Pipelines: [Regression] SDK Compiler fails to compile a pipeline containing a container_op with PipelineParam in base_image
What steps did you take:
The bug appear only in 1.0.0-rc.3, it does not exist in 0.5.1.
Given a container_op whose base_image contains a PipelineParam (pipeline argument for instance), the compiler cannot compile a pipeline containing such container_op.
What happened:
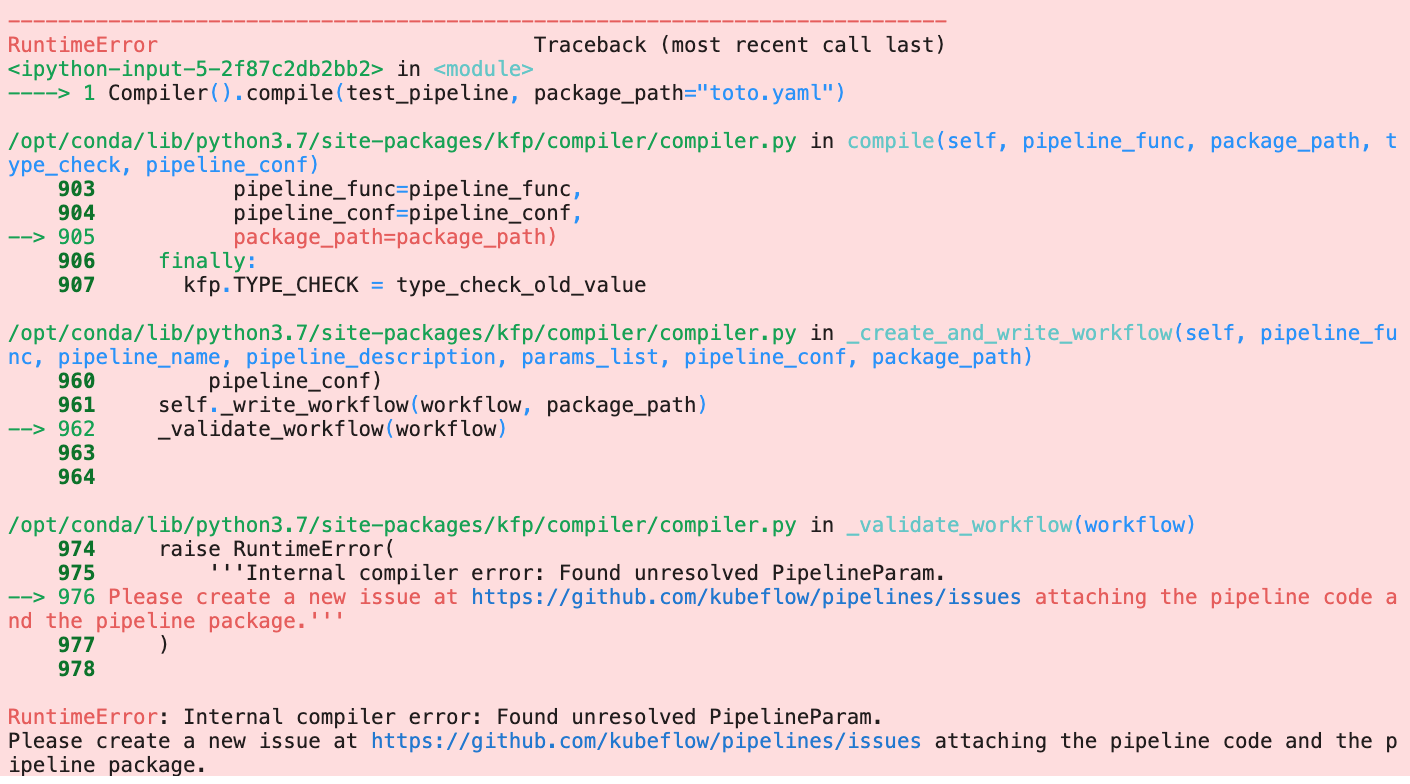
The compile fails with this error message:
RuntimeError: Internal compiler error: Found unresolved PipelineParam.
Please create a new issue at https://github.com/kubeflow/pipelines/issues attaching the pipeline code and the pipeline package.
What did you expect to happen:
The pipeline must compile successfuly
Environment:
python 3.7 + kfp 1.0.0-rc.3
Pipfile.lock is attached.
How did you deploy Kubeflow Pipelines (KFP)?
No installation is used, this happen in python sdk.
KFP SDK version: 1.0.0-rc.3
Anything else you would like to add: Reproducing bug
Python code
from kfp.compiler import Compiler
from kfp.components import func_to_container_op
from kfp.dsl import pipeline
def print_version():
import sys
print(sys.version)
@pipeline(name="reproduce image bug")
def test_pipeline(python_version: str):
func_to_container_op(func=print_version, base_image=f"library/python:{python_version}")()
Compiler().compile(test_pipeline, package_path="toto.yaml")
The bug does not exist in kfp 0.5.1
!pip install kfp==0.5.1
Code runs successfully.
The bug appears with kfp 1.0.0-rc.3
!pip install kfp==1.0.0-rc.3 --pre
/kind bug
/area sdk
 radcheb
radcheb
All 9 comments
Thanks for the report!
/assign @Ark-kun
 Bobgy
on 3 Jul 2020
Bobgy
on 3 Jul 2020
Think you for your report.
We've added sanity checks for the compiled workflow which and added some annotation which cased the error message to start triggering.
We do not support any dynamic configuration in the components themselves. This is by design, because otherwise components are not standalone and not shareable. Indeed, how can you share or load a component that has dependency on the runtime data of a pipeline run?
You can easily verify that the component you've built this way is broken even in 0.5.1:
func_to_container_op(func=print_version, base_image=f"library/python:{python_version}", output_component_file='print.component.yaml')
```yaml
name: Print version
implementation:
container:
image: library/python:{{pipelineparam:op=;name=python_version}}
command: ...
If you try to load that component in another pipeline you'll have problems at runtime since "library/python:{{pipelineparam:op=;name=python_version}}" is not a valid image.
### Solution:
What we support instead is a way to customize the tasks (component instances) created from the components.
```python
from kfp.compiler import Compiler
from kfp.components import func_to_container_op
from kfp.dsl import pipeline
def print_version():
import sys
print(sys.version)
print_version_op = func_to_container_op(func=print_version, base_image="python:3.7")
def test_pipeline(python_version: str):
print_version_task = print_version_op()
print_version_task.container.image = 'library/python:' + str(python_version)
Compiler().compile(test_pipeline, package_path="toto.yaml")
Please tell me whether this fixed your issue.
P.S. I'd also like to know your usage scenario to better understand why you want to specify the image name/version at runtime. The components are usually created in a way where they're reproducible. They often pin the image version, so that they won't be broken in the future is a new incompatible image is released.
 Ark-kun
on 7 Jul 2020
Ark-kun
on 7 Jul 2020
Thanks @Ark-kun , so this isn't a regression then.
Bobgy
on 8 Jul 2020
updated tags
Bobgy
on 8 Jul 2020
Thanks @Ark-kun this fixed the issue and the pipeline compile successfully.
We do not support any dynamic configuration in the components themselves. This is by design, because otherwise components are not standalone and not shareable. Indeed, how can you share or load a component that has dependency on the runtime data of a pipeline run?
Actually we noticed this error in one of our pipelines where we define the component inside the pipeline definition. We don't use this feature with exported components.
P.S. I'd also like to know your usage scenario to better understand why you want to specify the image name/version at runtime. The components are usually created in a way where they're reproducible. They often pin the image version, so that they won't be broken in the future is a new incompatible image is released.
We have some generic inference pipeline that must perform inference on model trained with a compatible code versions. Therefore, inference pipeline arguments include model version which is used to retrieve a specific model docker image that include a compatible version of code.
If you are interested, I would be pleased to present you more details about our use-case.
radcheb
on 8 Jul 2020
The pipeline must compile successfuly
The pipeline still compiles BTW. The validation happens after writing the file so that you can inspect the compiled pipeline or send it for debugging.
so this isn't a regression then.
I think so. This was never supported, but it started triggering error due to a combination of changes and behavior quirks. (The component_spec annotation is added after all placeholders are resolved, so it can contain unresolved placeholders if there were any. Previously, that annotation was missing the implementation part which contained the offending placeholder, but now it's included.)
Ark-kun
on 8 Jul 2020
Thanks @Ark-kun this fixed the issue and the pipeline compile successfully.
Glad to hear that!
We have some generic inference pipeline that must perform inference on model trained with a compatible code versions.
I see. Just for my education: Is this due to pickling? What ML framework do you use? How is it sensitive to the python version?
I'm creating training components for multiple ML frameworks and I'd like to know the gotchas.
Just brainstorming: Maybe you can also standardize on some python version for training and inference and update it across components once a year?
Ark-kun
on 8 Jul 2020
We have some generic inference pipeline that must perform inference on model trained with a compatible code versions.
I see. Just for my education: Is this due to pickling? What ML framework do you use? How is it sensitive to the python version?
I'm creating training components for multiple ML frameworks and I'd like to know the gotchas.
We use PyTorch as ML framework. We don't have issues with pickling, however since we are continuously iterating on our models and we would like to have a stable and generic inference pipeline for our client-facing constraints, we were usually forced to update our inference pipeline due to breaking changes in our model. These changes may not impact the model components (apply model, etc), however it impacts the logic inside (we are preprocessing data internally before applying model due to the lack of sparse matrices).
Thus, passing a model version as argument helped us keeping same generic pipeline while continuously improving the model.
Just brainstorming: Maybe you can also standardize on some python version for training and inference and update it across components once a year?
The python version was used in the issue example to make it easier to reproduce. Dis I misunderstand your question ?
radcheb
on 8 Jul 2020
Thank you for describing your scenario.
Closing this issue since the problem has been solved.
Ark-kun
on 8 Jul 2020
Related issues
 zijianjoy
·
3Comments
zijianjoy
·
3Comments
 talhairfanbentley
·
5Comments
talhairfanbentley
·
5Comments
 IronPan
·
4Comments
zijianjoy
·
5Comments
IronPan
·
4Comments
zijianjoy
·
5Comments
 goswamig
·
5Comments
goswamig
·
5Comments
Most helpful comment
The pipeline still compiles BTW. The validation happens after writing the file so that you can inspect the compiled pipeline or send it for debugging.
I think so. This was never supported, but it started triggering error due to a combination of changes and behavior quirks. (The
component_specannotation is added after all placeholders are resolved, so it can contain unresolved placeholders if there were any. Previously, that annotation was missing theimplementationpart which contained the offending placeholder, but now it's included.)