Openfoodnetwork: Subscription Orders not Created
Description
This week Banc Organics experienced huge failures on the generation of orders from Subscriptions.
3 Subscriptions were created successfully: R204511658, R522328655, R642514522.
These align to the first 3 active subscriptions in their subscription list.
23 subscriptions then failed to have orders created for them.
@luisramos0 noticed a Bugsnag related to subscriptions and I can confirm that this was the OC in question - Banc Organics OC opened at 6pm on Feb 27th so this message is definitely related to this OC.
https://openfoodnetwork.slack.com/archives/CEF14NU3V/p1582826433008200
Expected Behavior
All subs should open without error.
Actual Behaviour
3 opened and 27 failed to open.
Steps to Reproduce
I currently have no idea how to reproduce this. We have seen an issue in the past for THIS enterprise on subscriptions which resulted in an s2 issue (I suspected user error) followed by an issue to create logging in subscriptions so that we could debug issues more successfully in future:
https://github.com/openfoodfoundation/openfoodnetwork/issues/4462
Animated Gif/Screenshot
The best way to understand this issue more closely will be to log into UK production and inspect Banc's subscriptions.
Subscriptions for OC A5 are marked as 'Pending' for all but the first three relevant subscriptions. The successfully opened subscription orders are marked at 'Cart'.
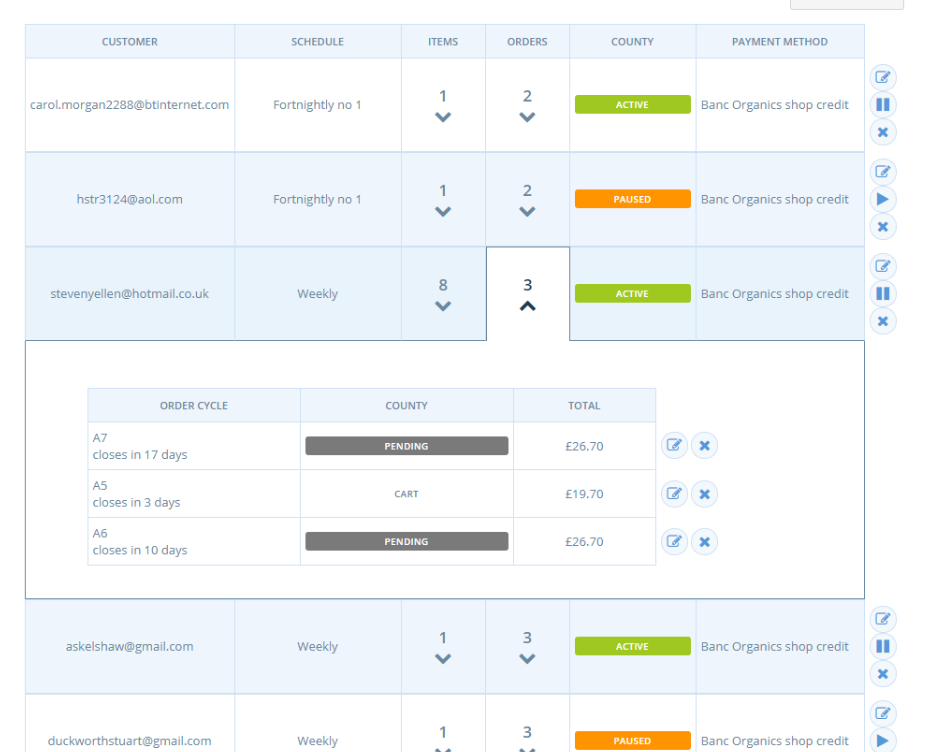
Ignore that it says 'County' instead of 'State'. I think I've now fixed this in transifex :-)
Workaround
The most urgent part of this issue is that we need a good workaround to ensure that Banc's subscription orders are opened this week. I'd like to chat this through with someone.
Currently I'm wondering if I should:
1) Cancel the open orders
2) Shift the open date of this OC to after now()
3) Check that subscriptions open correctly.
I think this will work but I wonder if there are any potential side effects... one is that the users will receive another email about their subscription this week.
Severity
S1 - I am marking this as an S1 as subscriptions is an officially supported feature that opens orders and the orders did not open. Failure to create orders and thus take payments represents a critical feature being broken.
I'm not going to call anyone to work on this on a Sunday, however.
Once we have successfully opened the orders for this week I will also be happy to downgrade to an S2.
Your Environment
- Version used: 2.7.6 UK production
Possible Fix
 lin-d-hop
lin-d-hop
All 25 comments
lin-d-hop
on 1 Mar 2020
This is OC 204060
This gives us the list of orders placed:
select * from proxy_orders where order_cycle_id = 204060;
Only 3 with order_id, the placement order job must have failed.
The bugsnag error is related and shows that the process failed while authenticating with the email server. The process is not designed to continue if an error occurs while sending email.
I assume one of the 3 orders did not get an email sent to the user.
Anyway, for now, I think it's obvious what I need to do: remove the "placed_at" label from the other orders and run the process again. I'll report back.
 luisramos0
on 2 Mar 2020
luisramos0
on 2 Mar 2020
To be clear: more logs would not help here.
luisramos0
on 2 Mar 2020
I have updated 23 missing orders (35 subscriptions in total - 2 are canceled - 7 are paused - the 3 already placed = 23), the job has run now and it looks good.
The manager got this email: "A total of 23 subscriptions were marked for automatic processing.
Of these, 21 were processed successfully. Details of the issues encountered are provided below."
One issse was insuficccient stock and another was no stock.
Looks like the job failed on Thursday because of a temporary problem with the email server. Rerunning it fixed the problem.
Looking at the ids of the 3 placed orders I'd say order R642514522 is missing an email to the user. We can resend the email on the admin orders page, right?
I'd say the problem is solved. I'll wait for confirmation.
Some ideas for a postmoterm:
- we can make the placement job a bit more resilient by maybe adding some delayed retries accessing the email server. We can also make it go through all orders even if there is a problem (like this one) placing one of the orders.
- the bugsnag alert was there on Thursday and I commented on it. We could have fixed this proactively :-( We do have the right alert tools in place :+1:
luisramos0
on 2 Mar 2020
Thanks @luisramos0! This is great :-)
I guess at the time we didn't know that a failed email would have caused all orders to fail?
At least I didn't know that otherwise I would have acted then. I assume you didn't know it @luisramos0 or you might have done more than comment?
I feel like we _almost_ have the right tools in place. Personally, I would have liked a notification that the job failed.
On another note - UK have experienced a recent, dramatic increase in emails being flagged as spam (despite the work gone into updating mail servers). Is there a chance the failed emails could be related?
lin-d-hop
on 2 Mar 2020
this looks like a connectivity/authentication issue, not a deliverability issue seen in dmarc.
luisramos0
on 2 Mar 2020
Yep. Understand. Deleting the above comments as they are unrelated to the issue at hand.
lin-d-hop
on 2 Mar 2020
Another question @luisramos0
Am I correct in thinking that only 1/10 Bugsnag issues are posted into Slack? I remember there is something about them not all creating notifications. I recall @sigmundpetersen pointed this out in the past.
If this is the case are we confident that we'll get any notification on the failure of the subscriptions job?
We've had a lot of this kind of failure in the UK and France and the knowledge that an error on one subscription can cause all the subs in the job to fail seems like a pertinent insight to me. Can we act on this?
lin-d-hop
on 2 Mar 2020
I marked the issue in bugsnag fixed, that way, if it happens again, we will get a notification for sure. We dont receive notifications for existing issues in bugsnag.
luisramos0
on 2 Mar 2020
I remember there is something about them not all creating notifications. I recall @sigmundpetersen pointed this out in the past.
Bugsnag notifies only the 1st, 10th and so on.
 RachL
on 2 Mar 2020
RachL
on 2 Mar 2020
Thanks both.
All makes sense.
What are the next steps.... ?
I like Luis' ideas above:
_we can make the placement job a bit more resilient by maybe adding some delayed retries accessing the email server. We can also make it go through all orders even if there is a problem (like this one) placing one of the orders._
In particular, I am still concerned that we do _NOT_ have all the right alerts in place to catch something like this in future. To me a simple step might be some specific notification if the subs job is killed part way through.
lin-d-hop
on 2 Mar 2020
that's a good idea, specific bugsnag message :+1:
the bugsnag rules are not just 1, 10, etc. it's configured like this:
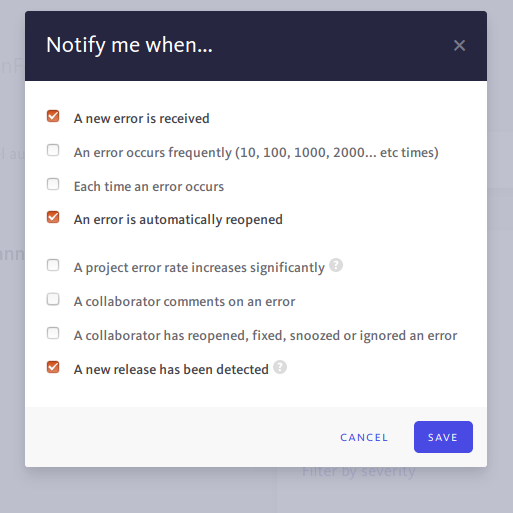
luisramos0
on 2 Mar 2020
You ok to test this @lin-d-hop? Figure you understand subscriptions the most 😄
 daniellemoorhead
on 3 Mar 2020
daniellemoorhead
on 3 Mar 2020
@luisramos0 @RachL
I don't want to close this issue until we can have a clear strategy of knowing when it happens in the future. As a support person there is nothing worse than having an issue reappear that you 'fixed' simply because we didn't even make a warning/error/bugsnag last time.
Options:
1) Specific bugsnag message when subs placement job fails mid process (this must flow through to slack)
2) Add delayed retries on the placement job
3) If one sub placement fails, don't kill the job. Post an error to bugsnag and continue placing subs. (Error must flow through to slack)
My preference would be 3. However if we can't prioritise that now but we can prioritise 1 then I vote 1.
I'm almost ready to deprecate it to UK users.
Please can we prioritise small steps to make subs more supportable?
lin-d-hop
on 5 Mar 2020
@luisramos0 @lin-d-hop I think we can add to dev ready the specific bugsnag message for sure. Can you create the issue @lin-d-hop ?
About the job, I agree 3 sounds good, can we have an idea of the size? I'm not saying we shouldn't do it, I would like more to understand "when". Thanks :)
RachL
on 6 Mar 2020
yes, we can implement point 3, I am not sure it's the worth it just because the retries will fail in most cases: most errors will not be specific to the order.
I'd like a second opinion here @openfoodfoundation/core-devs
luisramos0
on 10 Mar 2020
I think we do have the necessary monitoring in place, it is just about having the necessary alerting on top of it. Let me share my ideas on each topic.
Monitoring and alerting
Besides having exceptions in Bugsnag, we also have Datadog monitoring Delayed Job, like any other part of our infrastructure. We have it currently watching the error rate plus any change in throughput. This means we receive a message in the devops-alerts Slack channel with a graph when that happens, similar to https://openfoodnetwork.slack.com/archives/GLJQ2LASF/p1583409853000200. IMO, we could have seen the true impact of this bugsnag error if we checked these monitors. We would have seen a sudden decrease in throughput, different from the regular patterns.
The question to me is how can make this visible to an instance manager/devops team? It's clear that we do have the information but it doesn't serve its purpose. I acknowledge the fact that I can't attend all the alerts I see and as a result, I tend to pay little attention to things that do deserve it. It is probably both an excess of information but also not having the necessary (ops) resources our instances need.
The problem is that all this monitoring is only applied to FR and not the UK. We decided so to keep costs as low as possible. IMO in this particular case, possibly the costs in human hours trying to fix the issue and the impact on user satisfaction clearly outweigh the 35$/month this dedicated monitoring costs.
Related to this, I'd worth to check if the custom Delayed Job Bugsnag config we have in https://github.com/openfoodfoundation/openfoodnetwork/blob/master/config/initializers/delayed_job.rb is really needed.
A more resilient job
Agree with everyone. Now it's time to bring that extra resilience our background jobs didn't need until now. I'd go with option 3 but also:
- Tune the various config settings listed in https://github.com/collectiveidea/delayed_job/#gory-details. Specifically,
reschedule_atandmax_attempts. I agree with @luisramos0 that most of the time retrying is pointless but it does help with temporary problems. - Have a subs. specific queue so that we can group these jobs together and operate on them manually retrying them, for instance.
 sauloperez
on 10 Mar 2020
sauloperez
on 10 Mar 2020
I am not sure I understand why you talk about datadog when we are talking about a case that already generates a bugsnag event. Can you clarify?
luisramos0
on 10 Mar 2020
Now. I finished my comment. Hope it's clear.
sauloperez
on 10 Mar 2020
Thanks @sauloperez. It's hard to me to know if DD is the best solution here without understanding what the actual process is. All I want is to be alerted every time OFN fails to place subscriptions, so I can take action before I have angry users that have no orders.
I would like to progress this S1 and create a new issue. Unfortunately I don't understand your suggestion well enough to make an issue. I don't want to make you feel like a bottleneck on DD either.
How to become unstuck on this?
lin-d-hop
on 10 Mar 2020
IMO if you need to be notified and not miss any notification you better check the email account associated with Bugsnag. I created a label in Gmail so I don't miss them the ones for Katuma in the wealth of emails. The Slack channel gives visibility to the global team, while email notification are better suited for instance managers.
Other than that, I think the action item here is your number 3. Specifically to make the job handle this failure scenario and continue with the process plus
Tune the various config settings listed in https://github.com/collectiveidea/delayed_job/#gory-details. Specifically, reschedule_at and max_attempts. I agree with @luisramos0 that most of the time retrying is pointless but it does help with temporary problems.
Then, we can have a debate around DD and the role it plays alongside Bugsnag. Sorry if it felt overwhelming :sweat_smile:
sauloperez
on 10 Mar 2020
The specific problem here was the the error, that was noticed, said 'A Subs Email failed to send'. And we all happily went on with our days not realising that this failure actually meant that no Subs orders were placed.
I think the conversation on how we do alerts, while obviously important, is out of scope here.
I'm going to make an issue that a Bugsnag and clear error message is raised when the Subs Placement job is interrupted. The message should contain enough information that the instance manager can act.
lin-d-hop
on 10 Mar 2020
cool :+1:
the problem I see here is that those alerts will not be actionable by instance managers. We will be catching exceptions that we dont know about like the last one email server not available. So we wont know what to do until we look at the error ourselves. So, I think these alerts will always be for tech support/devs.
Anyway, lets do point 1 and 3.
luisramos0
on 10 Mar 2020
If we have an alert that offers a little more detail about the Subs placement job that failed then instance managers can mitigate with users more effectively. We'll also be able to raise issues for devs.
So I'm hoping we can include a bit more info in the alerts :crossed_fingers:
Off to create the issues. Will close this once they are open
lin-d-hop
on 10 Mar 2020
Improve notifications on subs placement job failure: https://github.com/openfoodfoundation/openfoodnetwork/issues/4981
Continue Subs Placement job when a subs order creation fails:
https://github.com/openfoodfoundation/openfoodnetwork/issues/4983
lin-d-hop
on 12 Mar 2020
Related issues
 filipefurtad0
·
3Comments
lin-d-hop
·
3Comments
filipefurtad0
·
3Comments
sauloperez
·
3Comments
sauloperez
·
3Comments
filipefurtad0
·
3Comments
lin-d-hop
·
3Comments
filipefurtad0
·
3Comments
sauloperez
·
3Comments
sauloperez
·
3Comments