One: [onert] Reducing peak memory usage during model loading
onert consumes almost twice as much memory as the model size during model loading.
Model loading process
- Read a whole model file into memory (
_buffervariable) - Load operators from
_bufferand create Graph - Load weight and bias data and copy them into
CachedData:point_left: Peak memory - Deallocate
_bufferfrom memory
At step 3, weight and bias data are duplicated at _buffer and CachedData.
How to reduce peak memory usage? (list of options)
- Deallocate memory area for weight and bias data when it is copied into
CachedData
- Later phases are not affected
- How to deallocate memory area for weight and bias data?
- Using
mmapto read model file andCachedDatahasmmapaddress
- Deallocation using
munmapis needed at dtor ofCachedData - Any problem when nnapi is used?
- Deallocation using
 periannath
periannath
All 10 comments
Profiling memory usage using valgrind (option 1)
- Commit : ed2e01f
- Model : inception_v3_2018_04_27
- command
bash $ BACKENDS=cpu valgrind --tool=massif --pages-as-heap=yes --detailed-freq=1 ./Product/armv7l-linux.debug/out/bin/nnpackage_run --nnpackage ../nnpkg_tst/inception_v3_2018_04_27/
Using valgrind to profile memory usage for nnpackage_run
Valgrind will terminate after model prepare because some neon instruction is not supported at valgrind
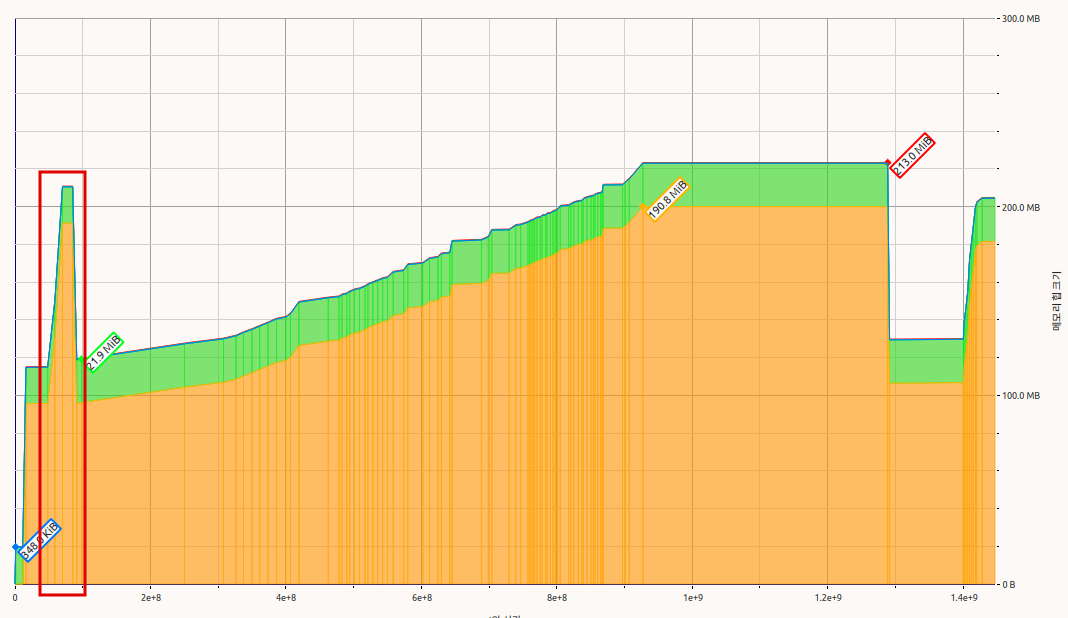
onert master
onert draft
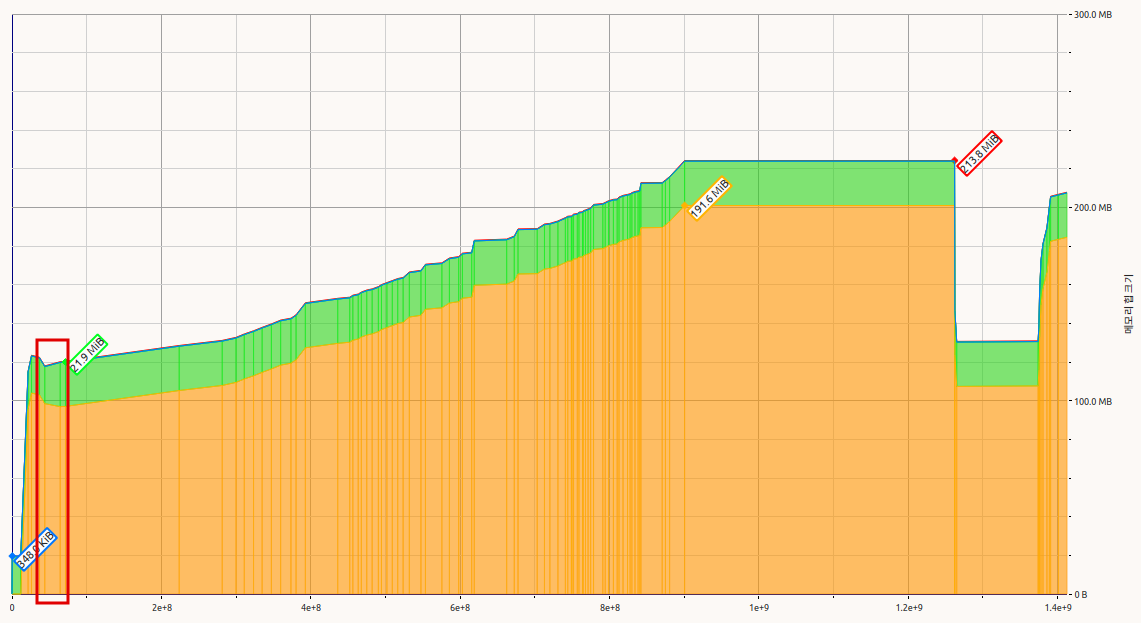
- Memory usage during model loading is almost same as model size
periannath
on 10 Jun 2020
Model load time and memory usage (option 1)
| Runtime | Memory | Load time | Prepare time |
|--|--|--|--|
| master | 187 MB | 419 ms | 288 ms |
| draft | 100 MB | 243 ms | 254 ms |
- Peak memory usage for load time is reduced
- Model load time is reduced
- Additional memory allocation for
_bufferis removed
- Additional memory allocation for
Raw data from nnpackage_run
onert master
$ BACKENDS=cpu ./Product/armv7l-linux.release/out/bin/nnpackage_run --nnpackage ../nnpkg_tst/inception_v3_2018_04_27 --mem_poll=true
... run 0 takes 1283.27 ms
===================================
MODEL_LOAD takes 419.034 ms
PREPARE takes 288.84 ms
EXECUTE takes
- Min: 1283.27 ms
- Max: 1283.27 ms
- Mean: 1283.27 ms
- GeoMean: 1283.27 ms
===================================
RSS
- MODEL_LOAD takes 191704 kb
- PREPARE takes 203244 kb
- EXECUTE takes 134940 kb
- PEAK takes 203244 kb
===================================
HWM
- MODEL_LOAD takes 194080 kb
- PREPARE takes 203808 kb
- EXECUTE takes 203808 kb
- PEAK takes 203808 kb
===================================
onert draft
$ BACKENDS=cpu ./Product/armv7l-linux.release/out/bin/nnpackage_run --nnpackage ../nnpkg_tst/inception_v3_2018_04_27 --mem_poll=true
... run 0 takes 1252.29 ms
===================================
MODEL_LOAD takes 253.247 ms
PREPARE takes 254.015 ms
EXECUTE takes
- Min: 1252.29 ms
- Max: 1252.29 ms
- Mean: 1252.29 ms
- GeoMean: 1252.29 ms
===================================
RSS
- MODEL_LOAD takes 101928 kb
- PREPARE takes 203964 kb
- EXECUTE takes 137896 kb
- PEAK takes 203964 kb
===================================
HWM
- MODEL_LOAD takes 102936 kb
- PREPARE takes 204468 kb
- EXECUTE takes 204468 kb
- PEAK takes 204468 kb
===================================
How to implement option 2
ExternalDatahasbasepointer and its size
Implementation
- mmap model file (option 1)
- Replacing
CachedDataintoExternalData
ExternalDatahas pointer to mmaped address
- Deallocation using
munmapis not yet implemented
periannath
on 12 Jun 2020
Model load time and memory usage (option 2)
- Commit: 836f297
| Runtime | Load time memory | Inference memory | Load time | Prepare time |
|--|--|--|--|--|
| master | 187 MB | 132 MB | 419 ms | 288 ms |
| option 1 | 100 MB | 137 MB | 243 ms | 254 ms |
| option 2 | 14 MB | 224 MB | 6 ms | 290 ms |
- Peak memory usage for load time is significantly reduced
- Memory allocated for
_bufferandCachedDatais removed
- Memory allocated for
- Model load time is reduced
- File access will be occurred at prepare time
- Increase of peak memory usage for inference time
- Deallocation using munmap is not yet implemented
Raw data from nnpackage_run
onert master
$ BACKENDS=cpu ./Product/armv7l-linux.release/out/bin/nnpackage_run --nnpackage ../nnpkg_tst/inception_v3_2018_04_27 --mem_poll=true
... run 0 takes 1283.27 ms
===================================
MODEL_LOAD takes 419.034 ms
PREPARE takes 288.84 ms
EXECUTE takes
- Min: 1283.27 ms
- Max: 1283.27 ms
- Mean: 1283.27 ms
- GeoMean: 1283.27 ms
===================================
RSS
- MODEL_LOAD takes 191704 kb
- PREPARE takes 203244 kb
- EXECUTE takes 134940 kb
- PEAK takes 203244 kb
===================================
HWM
- MODEL_LOAD takes 194080 kb
- PREPARE takes 203808 kb
- EXECUTE takes 203808 kb
- PEAK takes 203808 kb
===================================
option 1
$ BACKENDS=cpu ./Product/armv7l-linux.release/out/bin/nnpackage_run --nnpackage ../nnpkg_tst/inception_v3_2018_04_27 --mem_poll=true
... run 0 takes 1252.29 ms
===================================
MODEL_LOAD takes 253.247 ms
PREPARE takes 254.015 ms
EXECUTE takes
- Min: 1252.29 ms
- Max: 1252.29 ms
- Mean: 1252.29 ms
- GeoMean: 1252.29 ms
===================================
RSS
- MODEL_LOAD takes 101928 kb
- PREPARE takes 203964 kb
- EXECUTE takes 137896 kb
- PEAK takes 203964 kb
===================================
HWM
- MODEL_LOAD takes 102936 kb
- PREPARE takes 204468 kb
- EXECUTE takes 204468 kb
- PEAK takes 204468 kb
===================================
option 2
$ BACKENDS=cpu ./Product/armv7l-linux.release/out/bin/nnpackage_run --nnpackage ../nnpkg_tst/inception_v3_2018_04_27 -m1
... run 0 takes 1235.91 ms
===================================
MODEL_LOAD takes 6.275 ms
PREPARE takes 295.026 ms
EXECUTE takes
- Min: 1235.91 ms
- Max: 1235.91 ms
- Mean: 1235.91 ms
- GeoMean: 1235.91 ms
===================================
RSS
- MODEL_LOAD takes 13984 kb
- PREPARE takes 200916 kb
- EXECUTE takes 229052 kb
- PEAK takes 229052 kb
===================================
HWM
- MODEL_LOAD takes 13984 kb
- PREPARE takes 200916 kb
- EXECUTE takes 229340 kb
- PEAK takes 229340 kb
===================================
Personally I've tried this further for using ExternalData all phases(ModelLoad~Execute). https://github.com/YongseopKim/ONE/commit/e69aa3a0c674fb8c74f449175b352329e299f280
device: xu4-ubuntu
backend: cpu
Inv3
Memory
| version | ModelLoad | Prepare | Execute |
|---------|-----------|---------|---------|
| master | 192 MB | 203 MB | 135 MB |
| draft | 10 MB | 21 MB | 204 MB |
Latency
| version | ModelLoad | Prepare | Execute |
|---------|-----------|---------|---------|
| master | 400 ms | 229 ms | 1271 ms |
| draft | 71 ms | 109 ms | 1310 ms |
Mv2
Memory
| version | ModelLoad | Prepare | Execute |
|---------|-----------|---------|---------|
| master | 33 MB | 41 MB | 34 MB |
| draft | 7 MB | 16 MB | 41 MB |
Latency
| version | ModelLoad | Prepare | Execute |
|---------|-----------|---------|---------|
| master | 149 ms | 153 ms | 296 ms |
| draft | 5 ms | 26 ms | 297 ms |
other models
The draft can't run the other models for now.
 YongseopKim
on 15 Jun 2020
YongseopKim
on 15 Jun 2020
The above table seems too weird... I'll update it soon. updated.
YongseopKim
on 16 Jun 2020
I've profiled my draft version because I thought the peak of rss is too high(223mb).
- master: use mmap but allocate CachedData (d262411f)
- the draft: use
external datafrommodel loadtoexecute
- CachedData -> ExternalData by mmap()
- const BackendTensor copied from CachedData -> const BackendTensor has the pointer of ExternalData
tl;dr
- I can't answer the reason why the peak of rss is too high.
- However, I guess that not main threads copy the mapped memory from main thread.
- If a goal is to lower the latency of model load and prepare, this is a good option.
- If a goal is to lower memory of overall, it's better to focus on lowering memory of prepare phase by mixed external data & const backend tensor & unmap.
Test env
- backend: cpu
- model: inception_v3_2018
Default thread number
- tflite: 4
- onert: 8
Latency
- unit: ms
- warming up 5 & running 5
| | MODEL_LOAD | PREPARE | EXECUTE |
|-----------------|------------|---------|---------|
| tflite | 16 | 0.5 | 1565 |
| onert-master | 235 | 1000 | 1278 |
| onert-draft-T=8 | 33 | 822 | 1248 |
| onert-draft-T=4 | 33 | 784 | 1331 |
| onert-draft-T=2 | 35 | 810 | 1494 |
| onert-draft-T=1 | 32 | 814 | 2155 |
RSS
- unit: kb
- physically on ram
| | MODEL_LOAD | PREPARE | EXECUTE |
|-----------------|------------|---------|---------|
| tflite | 8580 | 9752 | 228017 |
| onert-master | 101760 | 204152 | 136860 |
| onert-draft-T=8 | 7132 | 22236 | 223887 |
| onert-draft-T=4 | 7128 | 21440 | 223615 |
| onert-draft-T=2 | 7188 | 22756 | 224579 |
| onert-draft-T=1 | 7128 | 22232 | 205872 |
VMS
- unit: kb
- logically on ram
| | MODEL_LOAD | PREPARE | EXECUTE |
|-----------------|------------|---------|---------|
| tflite | 173016 | 305596 | 352232 |
| onert-master | 121924 | 217348 | 242270 |
| onert-draft-T=8 | 113740 | 123228 | 325640 |
| onert-draft-T=4 | 113868 | 123224 | 288756 |
| onert-draft-T=2 | 113736 | 123224 | 270276 |
| onert-draft-T=1 | 113736 | 123224 | 226891 |
If you're interested in, please see https://github.com/YongseopKim/ONE/issues/2
YongseopKim
on 23 Jun 2020
Investigate peak memory usage of above draft
Draft of @YongseopKim : https://github.com/YongseopKim/ONE/tree/test/use_external_data_pulled
I've profiled above draft using valgrind on x86_64 system. Valgrind on x86_64 runs well without any error.
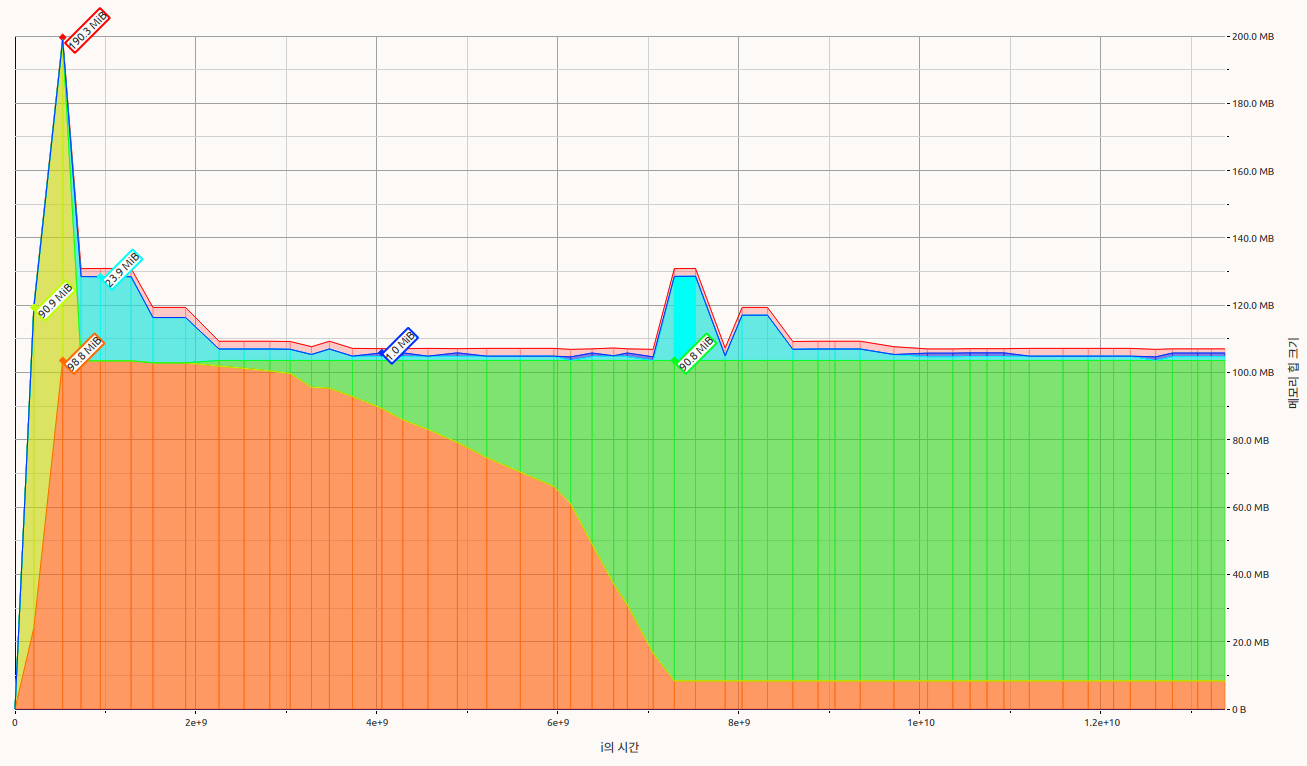
Memory usage of master
Memory usage of draft
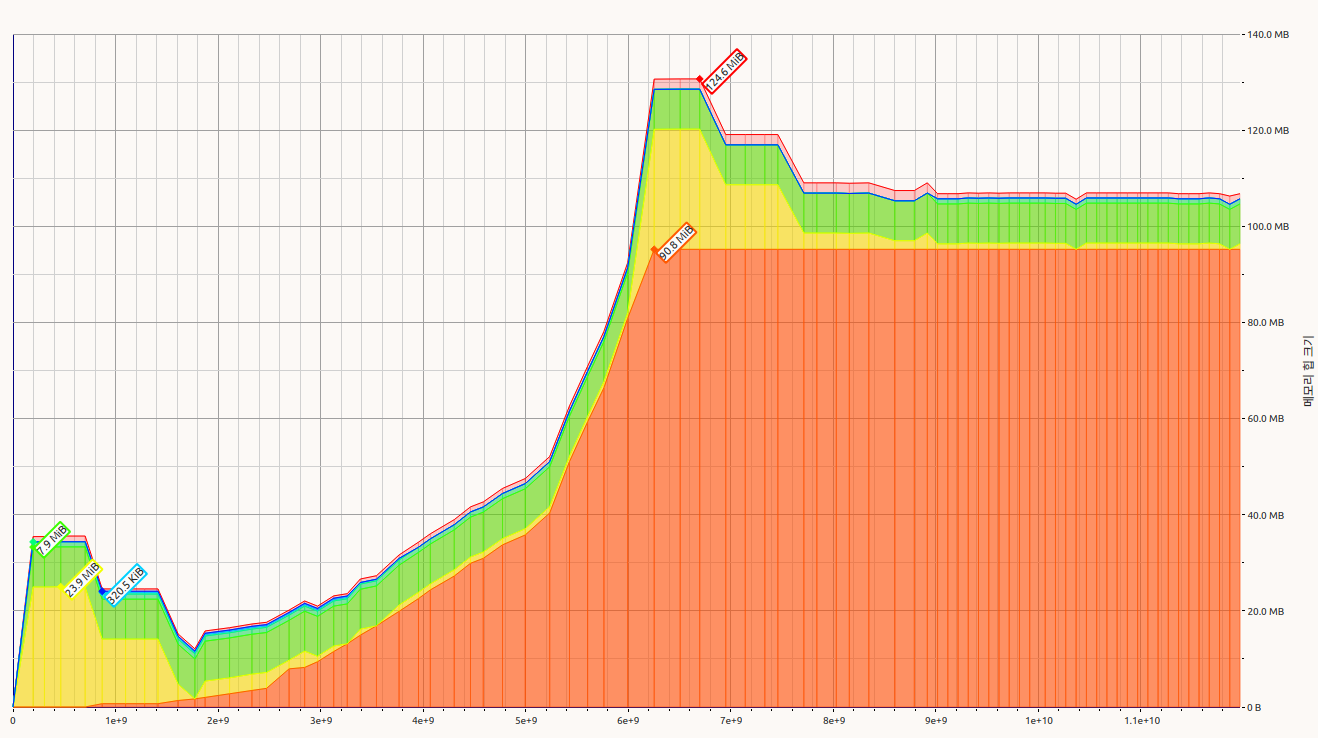
Cause of memory peak in inference
- Convolution layer allocates additional memory to copy
filter_data - Master : Copied
filter_datainCachedDatais deallocated - Draft : Copied
filter_datainExternalDatais not unmapped
Solution (?)
- Deallocate
ExternalDataafter it is copied for convolution
periannath
on 23 Jun 2020
Accroding to @periannath 's advice, I can remove the external data on the execute phase.
draft2: https://github.com/YongseopKim/ONE/tree/test/use_external_data_pulled
Latency
- unit: ms
- warming up 5 & running 5
| | MODEL_LOAD | PREPARE | EXECUTE |
|-----------------|------------|---------|---------|
| tflite | 16 | 0.5 | 1565 |
| onert-master | 235 | 1000 | 1278 |
| onert-draft | 33 | 822 | 1248 |
| onert-draft2 | 33 | 769 | 1251 |
RSS
- unit: kb
- physically on ram
| | MODEL_LOAD | PREPARE | EXECUTE |
|-----------------|------------|---------|---------|
| tflite | 8580 | 9752 | 228017 |
| onert-master | 101760 | 204152 | 136860 |
| onert-draft | 7132 | 22236 | 223887 |
| onert-draft2 | 7292 | 21860 | 132173 |
YongseopKim
on 24 Jun 2020
All related PRs merged. Please see #2580 if someone is interested in using ExternalData instead of CachedData.
periannath
on 25 Jun 2020
Related issues
 mhs4670go
·
3Comments
mhs4670go
·
3Comments
 binarman
·
3Comments
binarman
·
3Comments
 kishcs
·
3Comments
mhs4670go
·
3Comments
kishcs
·
3Comments
mhs4670go
·
3Comments
 lucenticus
·
3Comments
lucenticus
·
3Comments
Most helpful comment
Accroding to @periannath 's advice, I can remove the external data on the execute phase.
draft2: https://github.com/YongseopKim/ONE/tree/test/use_external_data_pulled
Latency
| | MODEL_LOAD | PREPARE | EXECUTE |
|-----------------|------------|---------|---------|
| tflite | 16 | 0.5 | 1565 |
| onert-master | 235 | 1000 | 1278 |
| onert-draft | 33 | 822 | 1248 |
| onert-draft2 | 33 | 769 | 1251 |
RSS
| | MODEL_LOAD | PREPARE | EXECUTE |
|-----------------|------------|---------|---------|
| tflite | 8580 | 9752 | 228017 |
| onert-master | 101760 | 204152 | 136860 |
| onert-draft | 7132 | 22236 | 223887 |
| onert-draft2 | 7292 | 21860 | 132173 |