Monaco-editor: Exit a state at end of line
The language I'm writing for has "to end of line" sub languages. I use a "first token of the line" root state to dispatch to sub-states, but then am having trouble exiting those sub states at end of line. It seems there's a design feature of Monaco to not match @eos as a token. Can anyone suggest a mechanism by which I can achieve this?
In this case, a * at the beginning of a statement (either start of line, or after a :), is a "to end of line" keyword. But within a line it's a multiply.
This * should be tokenised as an operator
PRINT 10 * 20
This needs to be a single line keyword:
```basic
*FX200, 3
````
This shows both, the PRINT bit is one, the *FX part needs to be to end of line.
```basic
PRINT 23:FX200, 3
````
Example of me trying to do this: https://github.com/mattgodbolt/owlet-editor/commit/b5ce47c63389891866eccf315ead7422b9890af7
The approach is to go to a "submode" once the first token is determined not to be a star (or a REM or other). A colon exits the submode, and ideally I'd like "end of line" to do the same. Any thoughts? THanks!
 mattgodbolt
mattgodbolt
All 12 comments
I think helping you would be easier if you could provide a copy and pasteable example of the language and your language definition that can be put here https://microsoft.github.io/monaco-editor/monarch.html
Or even a simplified test case and the desired behavior.
 Prinzhorn
on 16 Dec 2020
Prinzhorn
on 16 Dec 2020
I've been struggling with this too. I'm working with a language that interleaves "command" and plaintext-esqe lines (both with variable indentation) like so:
*command
*command
*command
plain text
plain text
*command
plain text
plain text
plain text
*command
plain
*command
plain
Thus far I've thought of two possible solutions:
Using @\eos: but this only seems to work as a 'case' guard. So whilst I do think it would work, I believe you'd need to have an @\eos case for every other possible rule/match you have in that state (strings, identifiers, numbers, delimiters...), which felt overly verbose and prone to error by omission.
The other way is to detect the _start_ of the line instead of the end. In the example below I use two simple states and have a first case in each that will match against a new line of the other type, forcing a state switch (with @\rematch to make sure it isn't consumed). It doesn't feel "right", but it does seem to work, at least for my simple case.
tokenizer: {
command: [
{
regex: /^\s*[^\*]\w+.*$/,
action: { token: '@rematch', switchTo: '@text', log: "switching to text line parsing at: $0" }
},
{
regex: /\*?\w+/,
action: { token: 'keyword' }
},
],
text: [
{
regex: /^\s*\*.*$/,
action: { token: '@rematch', switchTo: '@command', log: "switching to command line parsing at: $0" }
},
{
regex: /\w+/,
action: { token: 'annotation' }
},
]
}
Result:

So that's what I'm rolling with at the moment, but if anyone has a cleaner solution I'd love to hear it!
 CareyJWilliams
on 28 Dec 2020
CareyJWilliams
on 28 Dec 2020
@Prinzhorn absolutely, to make things concrete:
return {
defaultToken: "invalid",
brackets: [["(", ")", "delimiter.parenthesis"]],
operators: [
"+",
"-",
"*",
"/",
"<<",
">>",
"^",
"=",
"==",
"<>",
"!=",
"<",
">",
"<=",
">=",
"$",
"?",
";",
",",
"~",
"!",
"'",
],
symbols: /[-+#=><!*/{}:?$;,~^']+/,
tokenizer: {
root: [
[/(\bREM|\xf4)$/, {token: "keyword"}], // A REM on its own line
[/(\bREM|\xf4)/, {token: "keyword", next: "@remStatement"}], // A REM consumes to EOL
[/\*.*/, {token: "keyword.oscli"}],
[/./, {token: "@rematch", next: "notFirst"}],
],
notFirst: [
[/:/, {token: "symbol", next: "@pop"}],
// ARGH need to "pop" at end of line somehow!!!
[/[A-Z$]+\./, "keyword"],
[/^\s*\d+/, "enum"], // line numbers
{include: "@common"},
["\\[", {token: "delimiter.square", next: "@asm"}],
],
common: [
{include: "@whitespace"},
// immediate
[
"@symbols",
{
cases: {
"@operators": "operator",
"@default": "symbol",
},
},
],
// numbers
[/\d*\.\d*(E[-+]?\d+)?/, "number.float"],
[/\d+E[-+]?\d+/, "number.float"],
[/\d+/, "number"],
[/&[0-9A-F]+/, "number.hex"],
[/[{}()]/, "@brackets"],
[/[a-zA-Z_][\w]*[$%]?/, "variable"],
// strings
[/["\u201c\u201d]/, {token: "string.quote", next: "@string"}],
// Unusual cases. We treat @% as a regular variable (see #28).
["@%", "variable"],
],
whitespace: [[/[ \t\r\n]+/, "white"]],
string: [
[/[^"\u201c\u201d]+/, "string"],
[/["\u201c\u201d]/, {token: "string.quote", next: "@pop"}],
],
remStatement: [[/.*/, "comment", "@pop"]],
asm: [
[
/ADC|AND|ASL|B(CC|CS|EQ|MI|NE|PL|VC|VS)|BIT|BRK|CL[CDIV]|CMP|CP[XY]|DE[CXY]|EOR|IN[CXY]|JMP|JSR|LD[AXY]|LSR|NOP|ORA|PH[AP]|PL[AP]|RO[LR]|RTI|RTS|SBC|SE[CDI]|ST[AXY]|TA[XY]|TSX|TX[AS]|TYA/,
"keyword",
],
[/OPT|EQU[BDSW]/, "keyword.directive"],
[/[;\\][^:]*/, "comment"],
[/,\s*[XY]/, "keyword"],
// labels
[/\.([a-zA-Z_][\w]*%?|@%)/, "type.identifier"],
{include: "@common"},
["]", {token: "delimiter.square", next: "@pop"}],
],
},
};
and an example:
PRINT "HELLO"
*FX100,20
PRINT "HELLO":*FX200,2
PRINT "GOODBYE"
Here the second line needs to be completely "blue" (in default colours"). The *FX200,2 on line 3 is blue as it is after a colon.
mattgodbolt
on 28 Dec 2020
@CareyJWilliams the rematch on a non-* start of line seems to be something I can try: thanks so much!
mattgodbolt
on 28 Dec 2020
(though in my case I am getting infinite loops toggling between notFirst and root using that technique; I need to rephrase the states somehow)
mattgodbolt
on 28 Dec 2020
Here is what I could come up with:
- the root state generates
numbertokens (cyan) - the inner state generates
keywordtokens (blue)
https://microsoft.github.io/monaco-editor/monarch.html
return {
defaultToken: 'invalid',
tokenizer: {
root: [
[/^\*/, 'keyword', '@inner'],
[/\:\*/, 'keyword', '@inner'],
[/[^*:]+/, 'number'],
[/./, 'number']
],
inner: [
[/.$/, 'keyword', '@pop'],
[/./, 'keyword']
]
}
};
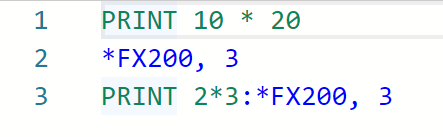
PRINT 10 * 20
*FX200, 3
PRINT 2*3:*FX200, 3
 alexdima
on 29 Dec 2020
alexdima
on 29 Dec 2020
@alexdima that's a great start: thanks. Within each state I need to tokenise more, e.g. without the [^*:]+ I need to remain in another state, continuing to tokenise based on "I'm not in a * state". It's leaving that state that has the issue. Any ideas how to do that? I appreciate you're busy and there's a lot of things to do, and this is a super fringe use of the library, but it seems other grammars have similar "to end of line" type subgrammars.
More specifically, I need to be able to tokenise the non-* line as the tokens PRINT (command) 10 (number) * (operator) 20 (number). I've been doing this by dispatching to a subgrammar once I've realise the line _didn't_ start with a *. It's the "return" from this subgrammar that's the tricky part as a new-line needs to exit. I see the case @CareyJWilliams noted looks similar.
mattgodbolt
on 30 Dec 2020
[/.$/, 'keyword', '@pop'] is roughly where I was going with the EOS cases.
The difficulty is that it doesn't scale well, for example when you're not sure what the last token in the line might be.
E.g. if you have a function/command that takes an arbitrary number of parameters of any type:
call myfunc: true "string" 1234 false "another string"
In this case you'd need to have at least three @\pop cases, one for each type, perhaps more if you could pass expressions, objects or functions etc.
I don't currently see any way around that (without resorting to the SOL detection I mentioned before). I don't know if you could match on a linebreak? I didn't have much luck doing so, but I won't pretend to have tried for very long.
CareyJWilliams
on 30 Dec 2020
In this case you'd need to have at least three @\pop cases, one for each type, perhaps more if you could pass expressions, objects or functions etc.
Right; this is kind of my problem. Once I've discovered the line didn't start with * I have quite a complex set of things if could be; trying to put a "but what if it was the end of the line" too would double the size of the grammar and make it (more? :grin: ) unreadable.
(offtopic, the editor's live and doing well enough modulo this at https://bbcmic.ro :) - thanks for sharing such a great project!)
mattgodbolt
on 30 Dec 2020
By setting includeLF: true in the Monarch grammar, the editor will now add \n at the end of lines. This has to be done behind a flag in order to maintain backwards compatibility. So a grammar will be able to do something like this:
{
includeLF: true,
tokenizer: {
root: [
[/^\*/, '', '@inner'],
[/\:\*/, '', '@inner'],
[/[^*:]+/, 'string'],
[/[*:]/, 'string']
],
inner: [
[/\n/, '', '@pop'],
[/\d+/, 'number'],
[/[^\d]+/, '']
]
}
}
That sounds great, @alexdima -- thank you!
mattgodbolt
on 30 Dec 2020
Indeed, brilliant! Thank you so much.
CareyJWilliams
on 30 Dec 2020
Related issues
 Kang-Jun-sik
·
3Comments
Kang-Jun-sik
·
3Comments
 Kedyn
·
3Comments
Kedyn
·
3Comments
 chengtie
·
3Comments
chengtie
·
3Comments
 robclive
·
3Comments
robclive
·
3Comments
 SoftTimur
·
3Comments
SoftTimur
·
3Comments