Ml-agents: Agent stuck in one behavior after first batch
Hi,
I am trying to train an agent to finish a short game ( for my bachelor thesis on using ML in game testing).
My colleague gave me his game to play around Falling Down
I wanted to use visual observations, and train the agent to change shape and get through obstacles.
The problem is, that after a batch of data is processed, the training script ( mlagents-learn ) stops sending actions to my agent script.
I tried:
- using different number of observed parameters
- not using any except visual ( main camera )
- changing reward values ( I never go beyond 1 >= r >= -1 )
- changing parameters in the config.yaml file (I used the same, that worked in a different project and those from examples ( Pyramids and PushBlock ) - all it changes is how quick the freezing happens (i think it depends on the batch size)
- using an executable and training from Unity Editor.
- copied my app to the UnitySDK asset folder in ml-agents (first I tried a separate project)
Don't know what I else could I do differently.
My agent script:
Public class FallAgent : Agent
{
[Header( "Specific to Falling-Down" )]
Player player;
public override void InitializeAgent()
{
player = GameObject.FindObjectOfType<Player>();
}
public override void CollectObservations()
{
}
public override void AgentAction( float[] vectorAction, string textAction )
{
var actionShapeshift = Mathf.FloorToInt( vectorAction[0] );
player.shapeshift = actionShapeshift == 1;
if( !player.IsAlive )
{
SetReward( -1f );
Done();
}
else
{
if( player.points > 0 )
{
SetReward( 2f );
--player.points;
}
}
}
public override void AgentReset()
{
player.InvokeRespawn();
}
}
Brain config file (most recent one)
trainer: ppo
batch_size: 512
beta: 1.0e-2
buffer_size: 2048
epsilon: 0.2
gamma: 0.99
hidden_units: 128
lambd: 0.95
learning_rate: 3.0e-4
max_steps: 5.0e4
memory_size: 256
normalize: true
num_epoch: 3
num_layers: 3
time_horizon: 64
sequence_length: 64
summary_freq: 1000
use_recurrent: true
use_curiosity: false
curiosity_strength: 0.01
curiosity_enc_size: 128
I would really appreciate some help.
 Szpaqn
Szpaqn
All 13 comments
why are you using SetReward instead of AddReward?
Also I don't know this game but if player is alive doesn't he always have more than 0 point which would lead to you giving agent 2 points ( afaik you should only give between -1 and 1 ) of reward almost every frame?
I think that what you will end up achieving is Agent who does not want to not perform any action as long as he has at least 1 point... Maybe that's why you're not receiving any actions. Perhaps your model deducted that not performing any action translates to biggest reward.
 oddEventHorizon
on 30 Dec 2018
oddEventHorizon
on 30 Dec 2018
Thank you for your response.
SetReward() was a typo, I was meaning to use AddReward() (I'm dislectic).
Thank you for noticing.
What I have done since then:
- changed that, so it gets a negative reward each time it dies.
- tried giving -1 each time
AgentReset()is called. - clamp the reward between -1 and 1.
- changed the player to change shape to square if agent decides 0, and to circle if decides 1 ( previously 1 was changing shape to another )
It still freezes after first batch (buffer is full).
my agent code now:
public class FallAgent : Agent
{
[Header( "Specific to Falling-Down" )]
Player player;
float globalScore = 0;
int isCircle = 0;
bool firstTime = true;
public override void InitializeAgent()
{
player = GameObject.FindObjectOfType<Player>();
}
public override void CollectObservations()
{
AddVectorObs( player.TargetCirclePercent );
}
public override void AgentAction( float[] vectorAction, string textAction )
{
isCircle = (int)player.TargetCirclePercent; // equals 1 if circle
var actionShapeshift = Mathf.FloorToInt( vectorAction[0] );
switch( actionShapeshift )
{
case 0:
if( isCircle == 1 )
{
player.shapeshift = true; //makes player shift shape, than defaults to false
UnityEngine.Debug.Log( "AgentAction actionShapeshift = " + actionShapeshift.ToString() + " circle = " + isCircle.ToString() );
}
break;
case 1:
if( isCircle == 0 )
{
player.shapeshift = true; //makes player shift shape, than defaults to false
UnityEngine.Debug.Log( "AgentAction actionShapeshift = " + actionShapeshift.ToString() + " circle = " + isCircle.ToString() );
}
break;
default:
break;
}
if( !player.IsAlive )
{
if( firstTime )
{
firstTime = false;
AddReward( -1f );
Done();
}
}
else
{
if( player.points > 0 )
{
AddReward( 0.1f );
--player.points;
}
}
}
public override void AgentReset()
{
player.InvokeRespawn();
firstTime = true;
}
}
Output (after that the agent stops responding):
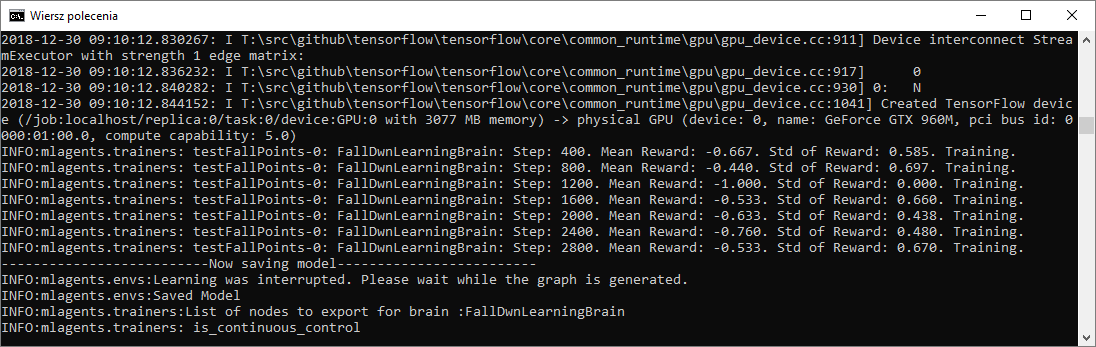
Current brain:
default:
trainer: ppo
batch_size: 512
beta: 5.0e-3
buffer_size: 5120
epsilon: 0.2
gamma: 0.99
hidden_units: 128
lambd: 0.95
learning_rate: 3.0e-4
max_steps: 5.0e4
memory_size: 256
normalize: true
num_epoch: 3
num_layers: 3
time_horizon: 64
sequence_length: 64
summary_freq: 400
use_recurrent: true
use_curiosity: false
curiosity_strength: 0.01
curiosity_enc_size: 128
I had some bugs in my code.
I was assigning a rewaed lower than -1, so after Matf.Clamp() I ended up with -1 most of the time.
I have fixed it now, but I still get the same behavior.
After training the neural network, no matter if the buffer is 1280 or 128000, the agent still freezes after the buffer content is fed to the NN.
Szpaqn
on 30 Dec 2018
I'm having a similar problem as well. My agents can train without issue when use_recurrent: false but once I set to use_recurrent: true something seems to be going wrong. Qualitatively, the agents behave as expected until the first batch. At that point, the agents get locked into only one behavior. This has only begun happening with the upgrade from 5.0 to 6.0. I'm beginning to debug and/or hunt for the issue. The only piece of info I have is that after the first batch I receive this warning:

I suspected that perhaps line 160 in trainer.py should be if len(agent_brain_info.memories) > 0: instead of if len(agent_brain_info.memories > 0):, but the bug still persists after changing the line. I suspect something is going wrong w/ the first incident of memories being used? I'm going to continue hunting!
 striderdoom
on 31 Dec 2018
striderdoom
on 31 Dec 2018
I haven't solved anything, but I've found some clues! (Forgive me for spamming thread whilest I try to solve. I figure others might find this helpful if I can't find the solution in the next few hours!)
I added a simple print command in ppo/trainer.py to find out what memories were being appended

Here's what the memories look like before the first batch:

And then after the first batch (this is when my agents appear to be locked into one action)

I haven't spent loads of time digging into the python code, but I know that nans are not ideal :P. I'm gonna keep hunting, but hopefully this can put others on the trail too! Optimistically though, we know our agents are not remembering any painful memories from the past!!
striderdoom
on 1 Jan 2019
HAH I think I understand -- this issue appears to be fixed for me in hotfix-0.6.0a branch.
I forgot to mention I'm using lots of masked actions. As a result, I think I was encountering massive "divide by 0" issues which are fixed with the padding change in the hotfix branch. My babies are learning WOO
striderdoom
on 3 Jan 2019
Thank you very much!
I haven't had the time to look at it yet, as it something I do after hours.
I will try to verify today, if this branch helps me as well, but looks like it.
I was looking on other branches, but didn't see it, or maybe I ignored it, since it's 0.0.6a, and I thought that a stands for alpha.
Szpaqn
on 3 Jan 2019
Following up,
The hotfix appears to address everything. I've been running a fairly complicated test (for me at least!) w/ lots of masking for 15 hours and my agents are improving excellently! I'm training digital farmers to milk digital cows and they are now averaging over 3 cows per session!

Thanks a ton for your work on ML-Agents :). So fun to work with!
striderdoom
on 5 Jan 2019
@striderdoom
I'd love to see your environment! Do you mind sharing a video?
 MarcoMeter
on 7 Jan 2019
MarcoMeter
on 7 Jan 2019
I've checked the hotfix-0.6.0a branch.
It solves my problem.
Thank you, for your help @striderdoom.
Szpaqn
on 7 Jan 2019
My though is to have my mobile work behind the home PC is auto dial home
base or navigate form HQ. The cloud storage and line flow works against
best forward now. I have a 2015 HP and what I when is aikia abeton 10 and
live controler. s machenie iTunes great start I wasn't awaeear of til
yesterday. My HP needs a password bios and charger. My emahines also Bios
password. I have a better understanding how to wright tyyt but I not going
to day in and out, I am self severing but I have a reach if we are in
agreement.
On Jan 7, 2019 2:40 AM, "Jakub" notifications@github.com wrote:
I've checked the hotfix-0.6.0a branch.
It solves my problem.
Thank you, for your help @striderdoom https://github.com/striderdoom.
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
https://github.com/Unity-Technologies/ml-agents/issues/1539#issuecomment-451860352,
or mute the thread
https://github.com/notifications/unsubscribe-auth/Amp7Q28DF4IPoLmZXj3g_Waq3D4Hp-Beks5vAwgZgaJpZM4Zkwp7
.
 cratkid
on 7 Jan 2019
cratkid
on 7 Jan 2019
As the issue is solved, I am closing the thread.
Szpaqn
on 7 Jan 2019
This thread has been automatically locked since there has not been any recent activity after it was closed. Please open a new issue for related bugs.
![lock[bot] picture](https://avatars1.githubusercontent.com/in/6672?v=4&s=40) lock[bot]
on 7 Jan 2020
lock[bot]
on 7 Jan 2020
Related issues
 GeriBP
·
3Comments
GeriBP
·
3Comments
 jlanis
·
4Comments
jlanis
·
4Comments
 Porigon45
·
3Comments
Porigon45
·
3Comments
 Sohojoe
·
3Comments
Sohojoe
·
3Comments
 dlindmark
·
3Comments
dlindmark
·
3Comments
Most helpful comment
I'm having a similar problem as well. My agents can train without issue when
use_recurrent: falsebut once I set touse_recurrent: truesomething seems to be going wrong. Qualitatively, the agents behave as expected until the first batch. At that point, the agents get locked into only one behavior. This has only begun happening with the upgrade from 5.0 to 6.0. I'm beginning to debug and/or hunt for the issue. The only piece of info I have is that after the first batch I receive this warning:I suspected that perhaps line 160 in trainer.py should be
if len(agent_brain_info.memories) > 0:instead ofif len(agent_brain_info.memories > 0):, but the bug still persists after changing the line. I suspect something is going wrong w/ the first incident ofmemoriesbeing used? I'm going to continue hunting!