Ml-agents: Performance drop when resuming training
Describe the bug
We have noticed dramatic performance drop when resuming training with ppo in our custom environments. If we try to do inference on the latest few checkpoints the performance is as expected, both in the editor using .nn model and with the tensorflow checkpoints and the built application. But if we try to resume training from the same checkpoints the performance drops within one episode. This is not something we have noticed on similar environments before.
We tried to reproduce it on the example environments. On the Reacher environment we got the same results. With the Reacher config file.
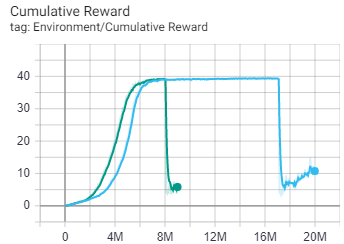
The figure above shows the training results for the Reacher environment. The blue is using the default config file. When resuming the learning rate is much smaller then starting training, since learning_rate_schedule=linear. The green is when the learning_rate_schedule=constant.
When looking at the resumed training it looks fine during the first episode. But then the reacher loose precision.
We also tried 3dBall but did not get the same result.
To Reproduce
Steps to reproduce the behavior:
- Train Reacher agents with the default ppo config file for Reacher.
- Stop training session when reward of $ \approx 40 $ is reached.
- Try to resume training with flags
--resume.
Environment (please complete the following information):
- Unity Version: 2019.4.8f1
- OS + version: Windows 10
- _ML-Agents version_: 0.19.0
- _TensorFlow version_: 2.3.0
- _Environment_: Reacher
 dlindmark
dlindmark
All 3 comments
Hi @dlindmark,
I have notified the team and we are trying to reproduce it. We will get back to you shortly.
 surfnerd
on 8 Sep 2020
surfnerd
on 8 Sep 2020
Hey guys, I´m experiencing the same issue.
The behavior I see in the agent after resuming is like if the model was partially correct, but for some reason some of the output values received in OnActionReceived(float[] continuousActions) were wrong.
I'm training a NN to control a chatacter's joints, and after resuming, some of the joints seem to behave more or less Ok, while others don't, and therefore I also have a massive performance drop after resuming that recovers after a few hours of re-training.
Maybe some of the values in that array are coming in a different order than in the previous training?
I mean, correct values but in the wrong order. Something like that would definitely be compatible with the weird behavior I'm experiencing.
Thanks a lot.
 iayucar
on 9 Sep 2020
iayucar
on 9 Sep 2020
Update: we have fixed this bug on master here https://github.com/Unity-Technologies/ml-agents/pull/4463. Thank you very much for reporting this.
 andrewcoh
on 10 Sep 2020
andrewcoh
on 10 Sep 2020
Related issues
 scotthovestadt
·
4Comments
scotthovestadt
·
4Comments
 Procuste34
·
3Comments
Procuste34
·
3Comments
 gerardsimons
·
3Comments
gerardsimons
·
3Comments
 Rodnyy
·
3Comments
Rodnyy
·
3Comments
 MrGitGo
·
4Comments
MrGitGo
·
4Comments
Most helpful comment
Update: we have fixed this bug on master here https://github.com/Unity-Technologies/ml-agents/pull/4463. Thank you very much for reporting this.