Ml-agents: Clarification on when a new lesson starts in curriculum learning.
Hello again, sorry for raising too many issues these days. This is definitely not urgent.
I have implemented a curriculum learning environment where the target moves further every lesson. It is working great! However, I am not sure when the lesson stepping kicks in.
In my json file I had it so that it would step up at a given reward level but in PPO I could see it pass that threshold reliably without kicking in the next lesson.
Anything I should look out for? Does it have to receive a reward higher than the threshold min_lesson_length times?
My JSON:
{
"measure" : "reward",
"thresholds" : [1.20, 2.20, 3.20, 4.20, 5.20, 6.30, 7.30, 8.30],
"min_lesson_length" : 2,
"signal_smoothing" : true,
"parameters" :
{
"target_position_z" : [0, 10, 20, 30, 40, 50, 60, 70, 80]
}
}
Here is my TensorBoard view:
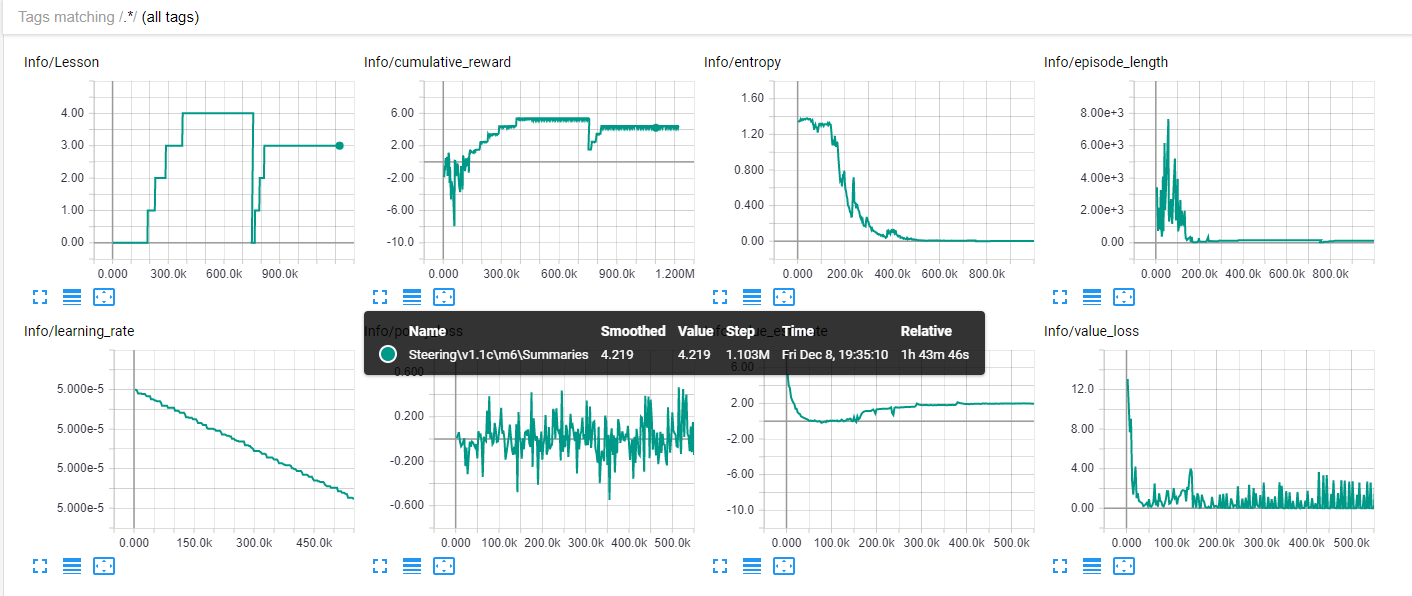
Initially, I had it so that it would go to the next lesson at 1.35 + n increments. Midway I restarted it to reduce the threshold to 1.20 +n. The highlighted point is the "low point" of the saw effect which still is higher than the active 1.20.
Here is the PPO file that has finer grain results outputted. You can see that it nicely went up to 3 but got stuck there, lesson wise.
 batu
batu
All 6 comments
Hey @batu,
So cool that you have already tried this feature out! The min_lesson_threshold and signal_smoothing both effect when lessons are incremented. Min-lesson corresponds to how many env.reset events happen before a lesson can be incremented (even if the target reward is met). The signal smoothing mixes the current reward (75%) with the previous one (25%) in order to prevent jumping up the lesson due to an outlier. Hope that makes things more clear.
 awjuliani
on 9 Dec 2017
awjuliani
on 9 Dec 2017
Does the reward measure refer to the mean reward?
After tracking it down, it is retrieved from models.py:72.
I'm confused about that. On my first curriculum environment, the lesson did not get incremented after resulting mean rewards, which are greater than the threshold specified as the reward measure.
 MarcoMeter
on 22 Dec 2017
MarcoMeter
on 22 Dec 2017
I think I'm also having a problem getting my lessons to increment. Here's my JSON:
{
"measure" : "reward",
"thresholds" : [25.0, 25.0, 25.0, 25.0, 25.0, 25.0, 25.0, 25.0, 25.0],
"min_lesson_length" : 5,
"signal_smoothing" : true,
"parameters" :
{
"target_size" : [20.0, 18.0, 16.0, 14.0, 12.0, 10.0, 8.0, 6.0, 4.0, 2.0]
}
}
And the initial results of my training (I added lesson_number to the write_summary output):
Unity Academy name: DriveAcademy
Number of brains: 1
Reset Parameters :
target_size -> 20.0
Unity brain name: DriveBrain
Number of observations (per agent): 0
State space type: continuous
State space size (per agent): 7
Action space type: discrete
Action space size (per agent): 3
Memory space size (per agent): 0
Action descriptions: Straight, Left, Right
2018-01-07 09:42:06.542309: I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.2 AVX AVX2 FMA
Step: 10000. Lesson: 0. Mean Reward: 27.0026136976. Std of Reward: 7.9425788293.
Step: 20000. Lesson: 0. Mean Reward: 28.7547758239. Std of Reward: 7.2587905042.
Step: 30000. Lesson: 0. Mean Reward: 31.1615654032. Std of Reward: 5.94781466697.
Step: 40000. Lesson: 0. Mean Reward: 30.7876757336. Std of Reward: 5.2069585033.
Step: 50000. Lesson: 0. Mean Reward: 29.4665671334. Std of Reward: 6.48221127502.
Saved Model
Step: 60000. Lesson: 0. Mean Reward: 28.8183934497. Std of Reward: 7.58078148925.
Step: 70000. Lesson: 0. Mean Reward: 32.0647062828. Std of Reward: 4.84924025188.
Step: 80000. Lesson: 0. Mean Reward: 33.0762510162. Std of Reward: 4.71043129986.
Step: 90000. Lesson: 0. Mean Reward: 32.6510774327. Std of Reward: 4.63454553307.
Step: 100000. Lesson: 0. Mean Reward: 34.6704716932. Std of Reward: 3.68656337751.
Saved Model
As you can see, lesson_number remains at lesson 0, even though it appears that the curriculum threshold of 25 and min_lesson_length of 5 seem to have been met. Am I doing something wrong?
 jglazman
on 7 Jan 2018
jglazman
on 7 Jan 2018
Ok, I figured out what my problem was. A 'lesson' is whenever the Academy resets, and I had my Academy Max Steps set to 0. I changed max steps to 50000 (so every 50000 steps the lesson will end) and now it works as expected.
[Edit: I was able to reach the same cumulative reward level in HALF the time using curriculum learning. awesome!]
jglazman
on 7 Jan 2018
Hi @batu, thanks for reaching out to us. Hopefully you were able to resolve your issue. We are closing this due to inactivity, but if you need additional assistance, feel free to reopen the issue.
 vladimiroster
on 28 Mar 2018
vladimiroster
on 28 Mar 2018
This thread has been automatically locked since there has not been any recent activity after it was closed. Please open a new issue for related bugs.
![lock[bot] picture](https://avatars1.githubusercontent.com/in/6672?v=4&s=40) lock[bot]
on 3 Jan 2020
lock[bot]
on 3 Jan 2020
Related issues
 Porigon45
·
3Comments
Porigon45
·
3Comments
 Sohojoe
·
3Comments
Sohojoe
·
3Comments
 MrGitGo
·
4Comments
MrGitGo
·
4Comments
 mattinjersey
·
3Comments
mattinjersey
·
3Comments
 Procuste34
·
3Comments
Procuste34
·
3Comments
Most helpful comment
Ok, I figured out what my problem was. A 'lesson' is whenever the Academy resets, and I had my Academy Max Steps set to 0. I changed max steps to 50000 (so every 50000 steps the lesson will end) and now it works as expected.
[Edit: I was able to reach the same cumulative reward level in HALF the time using curriculum learning. awesome!]