Mbed-os: [nrf5x] [NRF52_DK] - RTX mutex acquire hard faults
Description
- Type: Bug
- Related issue:
#abc - Priority: Blocker
Bug
Target
NRF52_DK
Toolchain:
GCC_ARM
Toolchain version:
mbed-cli version:
1.3.0
mbed-os sha:
caeaa49d68c67ee00275cece10cd88e0ed0f6ed3
Expected behavior
Locing the mutex and proceding.
Actual behavior
Locking in some cases causes
Mutex 0x0 error -4: Parameter error
This appears to be part of RTX5 on mutex acquire call within in an SVC event.
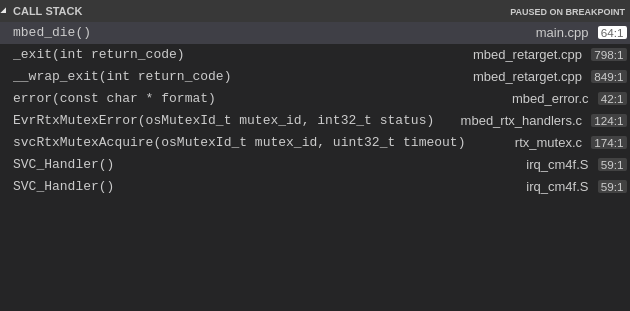
Afterwards I end up in mbed_die() hard fault handler and I am not sure what exactly is going wrong here.
 drahnr
drahnr
All 13 comments
Note that this only happens once a filesystem is used, just RD/WR to a blockdevice works just fine.
drahnr
on 6 Feb 2018
From the rtos code, the condition for parameter error in mutex acquire is:
// Check parameters
if ((mutex == NULL) || (mutex->id != osRtxIdMutex)) {
EvrRtxMutexError(mutex, osErrorParameter);
return osErrorParameter;
}
Which condition is failing in your case, is it id is invalid?
 0xc0170
on 6 Feb 2018
0xc0170
on 6 Feb 2018
I experience this issue under different circumstances. Here's my post about it if this sheds more light on the bug. https://os.mbed.com/questions/80053/mbedTLS-Mutex-Parameter-Error/
 AGlass0fMilk
on 6 Feb 2018
AGlass0fMilk
on 6 Feb 2018
@0xc0170 given the output, mutex is NULL - otherwise the %p would not become 0x0
drahnr
on 7 Feb 2018
It looks like a dangling reference is used or the memory is corrupted (due to stack overflow ???).
@drahnr Could you indicates how we can reproduce the issue ?
I found that if I moved BLE event processing to the main thread and used the spawned thread to run the encryption algorithms then I wouldn't encounter the crash/errors I was seeing before. I also reduced the stack size of the spawned thread until the encryption algorithm failed (it came back with a non-zero error) but even then mbed didn't crash.
@AGlass0fMilk Do you have local, global or dynamically allocated ble objects ?
 pan-
on 7 Feb 2018
pan-
on 7 Feb 2018
@pan- I can try to reproduce, I still have the git state branched but I can not share that code freely. But I am going to retry with a bigger stack size / moving the variable out of main to static.
drahnr
on 7 Feb 2018
@pan- As far as I know, BLE functions as a singleton. I simply call:
BLE &l_BLE = BLE::Instance();
l_BLE.onEventsToProcess(scheduleBleEventsProcessing);
l_BLE.init(bleInitComplete);
and that initializes it. This occurs in the thread that handles crypto calculations, but the main thread is actually dispatching the EventQueue driving the BLE system.
I thought it may have been a stack overflow problem (still seems like that) but I couldn't reproduce it even after reducing the crypto thread stack size to 2kB. The stack is globally allocated for the crypto thread, if that makes a difference.
As a side note, is there any definitive way to increase the default main thread stack size with mbed_app.json? The settings I've tried seem to have no effect.
AGlass0fMilk
on 7 Feb 2018
This is 100% reproducible for me.
Increasing the stack size from 4K to 16K by means of starting another thread does not change the behaviour.
int main() {
Thread thread (osPriorityNormal, 16 * 1024);
thread.start(main_x);
thread.join();
thread.terminate();
}
It also seems unrelated to LittleFilSystem / FATFileSystem, it was only a coincidence that this commit introduced them as it seems.
I tried to print the stack primitives but apparently the thread functions do not work in the hardfault
handler.
Any input on what to do/how I can support this being fixed would be appreciated. Also note, that this is resolved with my current repo state.
drahnr
on 8 Feb 2018
@drahnr It would be interesting to have the caller stack trace so you can understand which function actually do the mutex lock call and look at object state.
Also note, that this is resolved with my current repo state.
What do you mean ? What change resolved your issue ?
@AGlass0fMilk GATT services and GATT characteristics are maintained by the application code; I was wondering if these elements were located on the stack, heap or data segment.
I thought it may have been a stack overflow problem (still seems like that) but I couldn't reproduce it even after reducing the crypto thread stack size to 2kB. The stack is globally allocated for the crypto thread, if that makes a difference.
These issue are hard to reproduce because they depends on the state of the system and global object placement. It may help to get the stack from a larger memory chunk and fill the unused part with a pattern so you can actually check that the stack is not overflown. The kernel stack overflow checks are based on the position of the thread stack pointer when scheduling happen; it can miss overflows.
pan-
on 8 Feb 2018
@pan- what do you mean by object state? The mutex?
Regarding repo state: The commit identified to be the cause was ditchted.
Callstack, which confirms the mutex itself is zero:
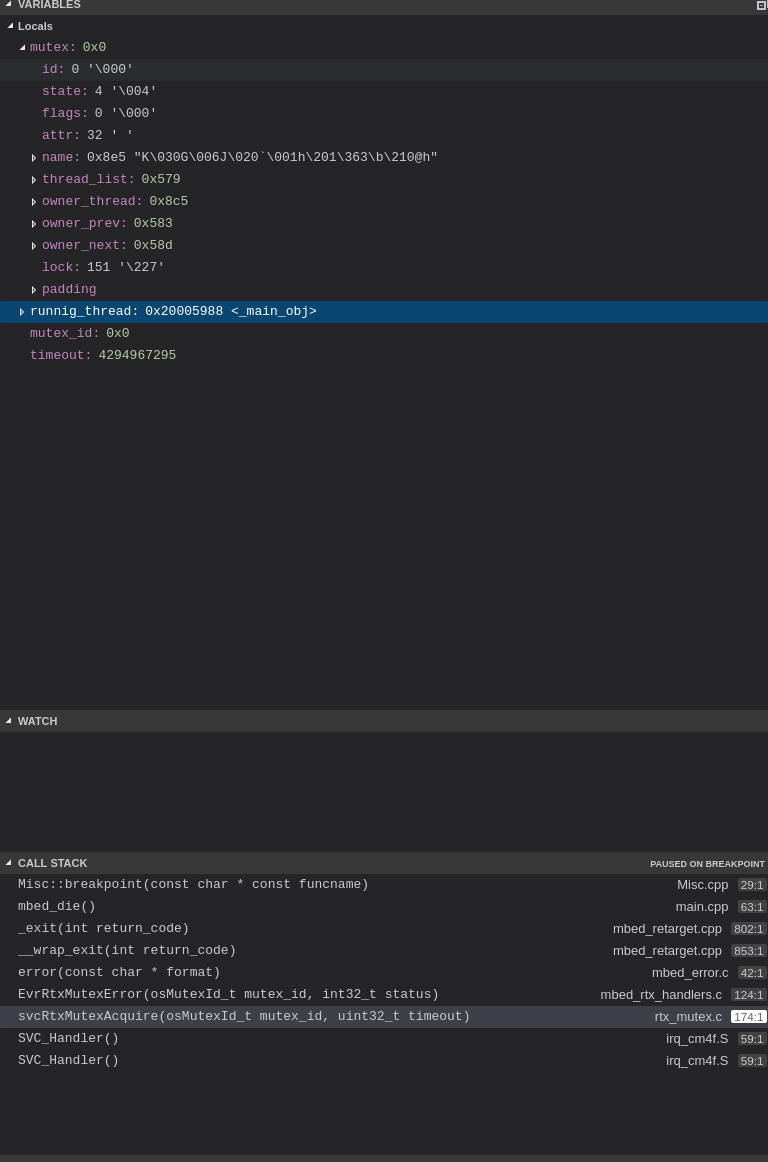
drahnr
on 8 Feb 2018
After a few hours of dissecting:
class Winc : public WincWifi, public WincFlash {
public:
Winc ();
virtual ~Winc ();
nsapi_error_t hw_init ();
nsapi_error_t hw_deinit ();
nsapi_error_t hw_reset ();
where both WincWifi and WincFlash both implement a non-virtual method called hw_init.
nsapi_error_t Winc::hw_init ()
{
hw_reset ();
reinterpret_cast<WincWifi *> (this)->hw_init ();
//reinterpret_cast<WincFlash *> (this)->hw_init (); // uncommenting this causes the issue
return NSAPI_ERROR_OK;
}
Commenting reinterpret_cast<WincFlash *> (this)->hw_init () - despite not using any mutexes (besides the one for logging) - does not cause the hard fault anymore.
drahnr
on 8 Feb 2018
That's not how you should call hw_init; and a reinterpret_cast is inappropriate here, a static_cast would have been better.
Anyway, to access parent member functions in case of ambiguity, you just have to qualify the call with the parent class:
nsapi_error_t Winc::hw_init ()
{
hw_reset ();
WincWifi::hw_init ();
WincFlash::hw_init ();
return NSAPI_ERROR_OK;
}
To add more context (I'm leaving virtual inheritance aside). Given the two base classes Foo and Bar :
struct Foo {
int foo;
};
struct Bar {
int bar;
};
````
If a class inherit from both, it need to reserve space for both instances. The class layout is very similar to what is seen with composition:
```c++
struct FooBar : Foo, Bar { };
// Similar to:
struct CompositionFooBar {
Foo foo;
Bar bar;
};
In that setup, it is clear that it would be a bad idea to treat a pointer to a CompositionFooBar as a pointer to a Bar instance: reinterpret_cast<Bar*> on a composition foo bar instance would indeed yield a pointer to CompositionFooBar::foo; not CompositionFooBar::bar.
pan-
on 8 Feb 2018
@pan- Mea culpa, actually I initially had dynamic cast right there but due to -fno-rtti I apparently made a huge mistake when fixing all those occurences, forgetting about the fact that static_cast would have calculated the offset for multiple inheritance. This blew up for the second dervied class, where the offset for this callback was calculated incorrectly, essentially calling/jumping to a garbage address causing a hardfault.
Note that the reason this blew up with right this commit, was the fact that all hw_* methods had their virtual removed which caused a lookup based on type and the lookup address is the same for all 3 types/classes.
Thanks for the reminder.
While static_cast works, the above should be considered best practice, since it also works with virtual methods explicitly calling the flavour desired unlike with static cast.
Sorry for the noise.
drahnr
on 8 Feb 2018
Related issues
 rbonghi
·
3Comments
rbonghi
·
3Comments
 ghost
·
4Comments
ghost
·
4Comments
 ashok-rao
·
4Comments
ashok-rao
·
4Comments
 neilt6
·
4Comments
neilt6
·
4Comments
 davidantaki
·
3Comments
davidantaki
·
3Comments