Maskrcnn-benchmark: Strange output and interrupt when perform multi-GPU training
❓ Questions and Help
Hi @fmassa , thank you for your great maskrcnn-benchmark.
Now we encounter some problems. When perform multi-GPU training with our own network, the strange output will appear:

However, when we training Faster R-CNN network with multi-GPU that you provide, there is not that problem.
And training our network with single GPU, there is also not that problem.
We ensure our parameter (batch size or other things) setting is suitable.
Here is some information:
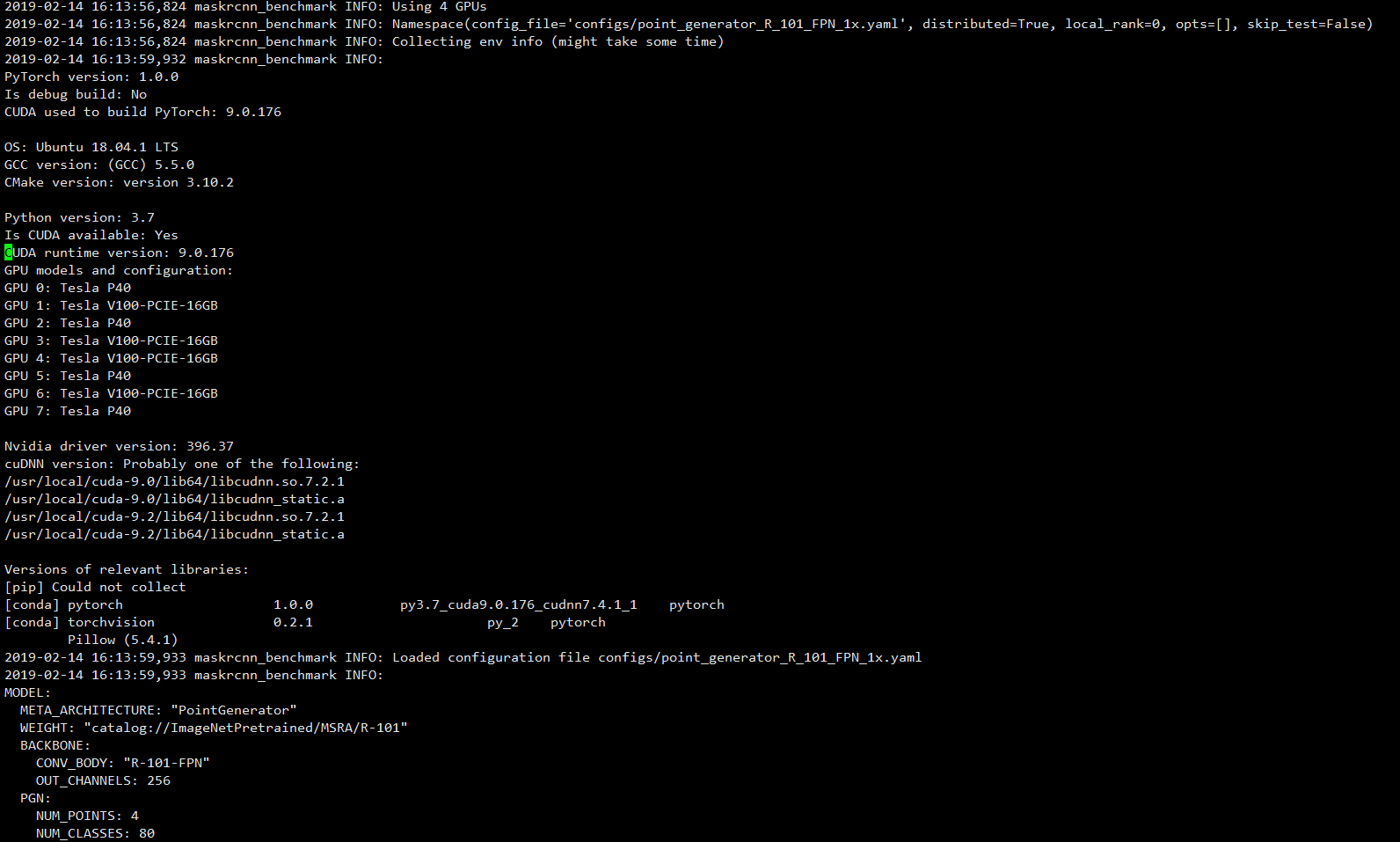
Thank you! @fmassa
 ChenJoya
ChenJoya
All 8 comments
emm…… meet the same problem, anyone can help?
 jiachen0212
on 14 Feb 2019
jiachen0212
on 14 Feb 2019
Hi,
It looks like your model didn't train properly. It might be that it might require some different learning rates / hyper parameters for it to train.
I would recommend checking the loss and see if it decreases over time, and also evaluating the model on the different checkpoints that were generated, to see if it is actually learning something.
 fmassa
on 14 Feb 2019
fmassa
on 14 Feb 2019
Hi, @fmassa
It cannot be trained. The program will be interrupted when start training, and output these strange numbers.........
Thanks for your help.
ChenJoya
on 15 Feb 2019
Did you change anything in the implementation?
Also, are you using a custom dataset?
I can't think of any part of the codebase where I deliberately print a tensor, so maybe the code has been modified in some way?
fmassa
on 15 Feb 2019
I also met the problem when I used two GPUs for training. @ChenJoya, do you solve the problem?
 longrongyang
on 22 Feb 2019
longrongyang
on 22 Feb 2019
@ChenJoya @2678918253 Hi, I have met one similar bug. I wonder if it is caused by distributed launch. If your own model has parameters which are not used in model forward , distributed launch may take this bug.
I think you can use log text to find if your bug has some info like **"TypeError: _queue_reduction(): incompatible function arguments. The following argument types are supported:
- (process_group: torch.distributed.ProcessGroup, grads_batch:List[List[at::Tensor]], devices: List[int]) -> Tuple[torch.distributed.Work, at::Tensor]".**
If you have these bug info, I recommend two ways to solve it. One is trying to find parameters not used in your model forward process and delete it. Second is using NVIDIA apex to wrap your model.
 Lausannen
on 26 Feb 2019
Lausannen
on 26 Feb 2019
Thank you!
ChenJoya
on 27 Feb 2019
@Lausannen Thank you, problem has been solved following idea!
 yangwf1
on 1 Apr 2019
yangwf1
on 1 Apr 2019
Related issues
 jbitton
·
4Comments
jbitton
·
4Comments
 KuribohG
·
3Comments
KuribohG
·
3Comments
 nanyoullm
·
3Comments
nanyoullm
·
3Comments
 hadim
·
4Comments
hadim
·
4Comments
 kaaier
·
3Comments
kaaier
·
3Comments
Most helpful comment
@ChenJoya @2678918253 Hi, I have met one similar bug. I wonder if it is caused by distributed launch. If your own model has parameters which are not used in model forward , distributed launch may take this bug.
I think you can use log text to find if your bug has some info like **"TypeError: _queue_reduction(): incompatible function arguments. The following argument types are supported:
If you have these bug info, I recommend two ways to solve it. One is trying to find parameters not used in your model forward process and delete it. Second is using NVIDIA apex to wrap your model.