Maskrcnn-benchmark: the reason why DATALOADER: SIZE_DIVISIBILITY: 32
❓ Questions and Help
hi,
after reading the code, I have a question: for the parameter:
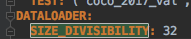
why in resnet 50 and resnet 101 ,it is set to 32. I guess the reason is for resnet 50 and resnet101 , the downsampling rate is 1/32. so to make sure the feauture map size is integral after conv and downsampling at the end of the last stage? thks a lot
 alexwq100
alexwq100
>All comments
That's precisely the reason.
In fact, original Detectron models use a fixed upsampling ratio in the FPN, which means that the image size should be a multiple of the smallest feature stride.
https://github.com/facebookresearch/maskrcnn-benchmark/blob/1589ce0941c118dda90a8b134c8708b67f36cb5f/maskrcnn_benchmark/modeling/backbone/fpn.py#L54
If we instead used https://github.com/facebookresearch/maskrcnn-benchmark/blob/1589ce0941c118dda90a8b134c8708b67f36cb5f/maskrcnn_benchmark/modeling/backbone/fpn.py#L56
then we wouldn't need to have SIZE_DIVISIBILITY, but results are slightly worse without it, possibly because the receptive fields are not aligned as before.
 fmassa
on 11 Feb 2019
fmassa
on 11 Feb 2019
Related issues
 BelhalK
·
4Comments
BelhalK
·
4Comments
 qijiezhao
·
3Comments
qijiezhao
·
3Comments
 SkeletonOne
·
3Comments
SkeletonOne
·
3Comments
 adityaarun1
·
3Comments
adityaarun1
·
3Comments
 Nacho114
·
4Comments
Nacho114
·
4Comments
Most helpful comment
That's precisely the reason.
In fact, original Detectron models use a fixed upsampling ratio in the FPN, which means that the image size should be a multiple of the smallest feature stride.
https://github.com/facebookresearch/maskrcnn-benchmark/blob/1589ce0941c118dda90a8b134c8708b67f36cb5f/maskrcnn_benchmark/modeling/backbone/fpn.py#L54
If we instead used https://github.com/facebookresearch/maskrcnn-benchmark/blob/1589ce0941c118dda90a8b134c8708b67f36cb5f/maskrcnn_benchmark/modeling/backbone/fpn.py#L56
then we wouldn't need to have
SIZE_DIVISIBILITY, but results are slightly worse without it, possibly because the receptive fields are not aligned as before.