Machinelearning: Memory leak when featurizing text with the default settings
When featurizing text with the default settings, references to the entire dataset rows are kept around
 daholste
daholste
All 3 comments
So I've talked with @daholste offline, and also worked with @harishsk towards a solution, and I will open a PR soon with a couple of proposals. In the meantime here I will further describe the issue and add a small sample to explain it.
Issue
When loading a dataset using the FeaturizeText featurizer, at some point a NormStr pool is created and it holds the NormStrs created while featurizing each row of the dataset. Each NormStr has a readonly field ReadOnlyMemory<char> Value which has a non-public member _object, typically this member is a string over which the ReadOnlyMemory<char> is based on.
_Sometimes_, it is the case that this _object member holds a reference to a string that contains the whole row where the NormStr was found.
So, for example, as seen in the sample code I provide at the end of this post, if I have a CSV file such as this one:
Index,Column1,Column2
1,Uppercase string,44
2,lowercase string,33
And if I use FeaturizeText to load Column1, with the following options:
new TextFeaturizingEstimator.Options()
{
CharFeatureExtractor = null,
WordFeatureExtractor = new WordBagEstimator.Options()
{
NgramLength = 2,
MaximumNgramsCount = new int[] { 200000 }
}
}
Then, after fitting, the following NormStrs are created and held in a NormStr pool used by the transformer:
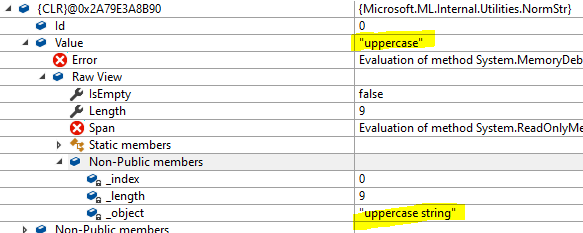
_"uppercase"_
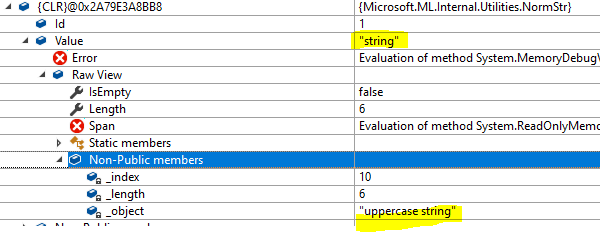
_"string"_
_"lowercase"_
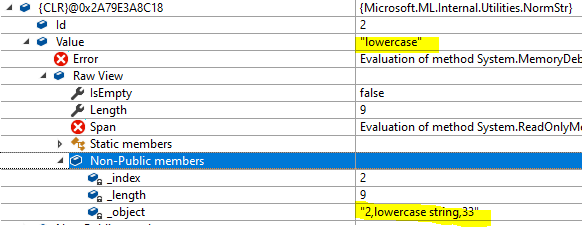
As seen above, both "uppercase" and "string" share an _object reference to the same string which holds the content of the Column1 of the first row "uppercase string". On the other hand "lowercase" has an _object with the string that holds the _whole second row_ "2,lowercase string,33".
Notice that in the sample code there's only one featurizer, the one for Column1, so we are actually only interested in reading that column. Still, we get in memory this string that holds the content of the whole second row.
In bigger datasets this becomes a problem, when there are many NormStrs that hold references to strings that contain whole rows. Because these NormStrs are required by the transformer that uses the featurizer, they are not supposed to be garbage collected even after fitting, and so they stay in memory along with their respective _object strings.
For instance, when using a dataset with 100k rows and 2.5+k columns, we _can_ get NormStr pools of over 150MB for each column we are interested in loading (there's a NormStr pool for each one of those). And this can cause a lot of innecesary memory usage since there is no real need to keep whole rows in memory..
One cause of the problem: TextNormalizingTransformer
After some investigation, I've found that the reason to explain the behavior described above is in the NormalizeSrc method of TextNormalizingTransformer.Mapper. I feel there are other places where similar problems might be caused, but I still need further investigation. In the meantime, in the experiments I've done recently, I found the NormalizeSrc to be the main source of this problem (at least for the case of daholste).
The NormalizeSrc method has the following parameters:
in ReadOnlyMemory<char> src, ref ReadOnlyMemory<char> dst, StringBuilder buffer
The src holds the text of a given row in a given column that is to be normalized, and dst is where the text is left after normalizing.
When calling NormalizeSrc, src seems to always have a _object that holds the string of the whole row. Later on in the method, if there was nothing to normalize in src (e.g., if it didn't have uppercases) then the method simply makes:
dst = src;
If there were things that needed to be normalized, then buffer is used to build the normalized string, which is then converted into a ReadOnlyMemory<char>:
dst = buffer.ToString().AsMemory();
(link to code in NormalizeSrc)
Because of the above, if there was nothing to normalize in the source text, then dst still has an _object with a string containing the whole row. In contrast, if there was _something_ to normalize in the given src, then dst has an _object with only the contents of the row in the specific column that is being processed.
Later on in other methods, new ReadOnlyMemory objects are created for each "word" (or "token") inside dst, but they share the same _object as the dst they are based in, and they are used to create new NormStrs. This explains the behavior of the sample I provided, where the content of "Uppercase string" had to be normalized, and thus the NormStrs for "uppercase" and "string" only had a reference to the content of that column, whereas "lowercase" had a reference to the whole row since "lowercase string" didn't have to be normalized.
Code and input data
_data.csv_
Index,Column1,Column2
1,Uppercase string,44
2,lowercase string,33
_Program.cs_
using Microsoft.ML;
using Microsoft.ML.Data;
using Microsoft.ML.Transforms.Text;
using System;
namespace MyData
{
class MyData
{
static void Main(string[] args)
{
var mlContext = new MLContext();
var textLoader = mlContext.Data.CreateTextLoader(new TextLoader.Options()
{
Columns = new TextLoader.Column[]
{
new TextLoader.Column("Index", DataKind.String, 0),
new TextLoader.Column("Column1", DataKind.String, 1),
new TextLoader.Column("Column2", DataKind.String, 2),
},
HasHeader = true,
Separators = new char[] { ',' }
});
var data = textLoader.Load(@"C:\Users\anvelazq\Desktop\issue15\mydata.csv");
IEstimator<ITransformer> featurizer = mlContext.Transforms.Text.FeaturizeText("Column1", new TextFeaturizingEstimator.Options()
{
CharFeatureExtractor = null,
WordFeatureExtractor = new WordBagEstimator.Options()
{
NgramLength = 2,
MaximumNgramsCount = new int[] { 200000 }
}
});
var model = featurizer.Fit(data);
var transformed = model.Transform(data);
Console.WriteLine("Done");
}
}
}
 antoniovs1029
on 13 Dec 2019
antoniovs1029
on 13 Dec 2019
As a possible solution, we can allocate a new string for the dictionary which stores the ngram-to-slot-number-key. This will break the pointer chain back to the original text row of data, and release the memory as the transform moves to the next row.
When saving a model, the dictionary is serialized to disk, it will be storing the exact strings instead of the string slices. The possible solution above would be similar to loading the serialized dictionary from disk.
Allocating strings of course is non-free, but it will only be done once per string stored in the dictionary.
String slices can be more memory efficient for long charactergram lengths, but I think the overheads will bring it to similar memory usage. For example, the 8-char-grams of "<stx>The cat ran down the street<etx>" is ["<stx>The cat", "The cat ", "he cat r", "e cat ra", " cat ran", "cat ran ", "at ran d", "t ran do", " ran dow", "ran down", "an down ", "n down t", " down th", "down the", "own the ", "wn the s", "n the st", " the str", "the stre", "he stree", "e street", " street<etx>"]. But even though this is 178 chars when created with individual strings and the slices all point to the same 27 chars, there are overheads in keeping the offset and length of each string slice.
 justinormont
on 13 Dec 2019
justinormont
on 13 Dec 2019
As a possible solution, we can allocate a new string for the dictionary which stores the ngram-to-slot-number-key. This will break the pointer chain back to the original text row of data, and release the memory as the transform moves to the next row.
For the record, I have discussed this offline with @justinormont , and his suggestion is now Proposal 3 in the PR I opened about this.
antoniovs1029
on 14 Dec 2019
Related issues
 frankhaugen
·
3Comments
frankhaugen
·
3Comments
 samueleresca
·
3Comments
samueleresca
·
3Comments
 darren-zdc
·
3Comments
darren-zdc
·
3Comments
 rebecca-burwei
·
3Comments
rebecca-burwei
·
3Comments
 maxt3r
·
3Comments
maxt3r
·
3Comments
Most helpful comment
So I've talked with @daholste offline, and also worked with @harishsk towards a solution, and I will open a PR soon with a couple of proposals. In the meantime here I will further describe the issue and add a small sample to explain it.
Issue
When loading a dataset using the
FeaturizeTextfeaturizer, at some point aNormStr poolis created and it holds theNormStrs created while featurizing each row of the dataset. EachNormStrhas a readonly fieldReadOnlyMemory<char> Valuewhich has a non-public member_object, typically this member is a string over which theReadOnlyMemory<char>is based on._Sometimes_, it is the case that this
_objectmember holds a reference to a string that contains the whole row where theNormStrwas found.So, for example, as seen in the sample code I provide at the end of this post, if I have a CSV file such as this one:
And if I use
FeaturizeTextto loadColumn1, with the following options:Then, after fitting, the following
NormStrs are created and held in aNormStrpool used by the transformer:_"uppercase"_

_"string"_

_"lowercase"_

As seen above, both "uppercase" and "string" share an
_objectreference to the same string which holds the content of theColumn1of the first row "uppercase string". On the other hand "lowercase" has an_objectwith the string that holds the _whole second row_ "2,lowercase string,33".Notice that in the sample code there's only one featurizer, the one for
Column1, so we are actually only interested in reading that column. Still, we get in memory this string that holds the content of the whole second row.In bigger datasets this becomes a problem, when there are many
NormStrs that hold references to strings that contain whole rows. Because theseNormStrs are required by the transformer that uses the featurizer, they are not supposed to be garbage collected even after fitting, and so they stay in memory along with their respective_objectstrings.For instance, when using a dataset with 100k rows and 2.5+k columns, we _can_ get
NormStr poolsof over 150MB for each column we are interested in loading (there's aNormStr poolfor each one of those). And this can cause a lot of innecesary memory usage since there is no real need to keep whole rows in memory..One cause of the problem: TextNormalizingTransformer
After some investigation, I've found that the reason to explain the behavior described above is in the
NormalizeSrcmethod ofTextNormalizingTransformer.Mapper. I feel there are other places where similar problems might be caused, but I still need further investigation. In the meantime, in the experiments I've done recently, I found theNormalizeSrcto be the main source of this problem (at least for the case of daholste).The
NormalizeSrcmethod has the following parameters:The
srcholds the text of a given row in a given column that is to be normalized, anddstis where the text is left after normalizing.When calling
NormalizeSrc,srcseems to always have a_objectthat holds the string of the whole row. Later on in the method, if there was nothing to normalize insrc(e.g., if it didn't have uppercases) then the method simply makes:dst = src;If there were things that needed to be normalized, then
bufferis used to build the normalized string, which is then converted into aReadOnlyMemory<char>:dst = buffer.ToString().AsMemory();(link to code in NormalizeSrc)
Because of the above, if there was nothing to normalize in the source text, then
dststill has an_objectwith a string containing the whole row. In contrast, if there was _something_ to normalize in the givensrc, thendsthas an_objectwith only the contents of the row in the specific column that is being processed.Later on in other methods, new
ReadOnlyMemoryobjects are created for each "word" (or "token") insidedst, but they share the same_objectas thedstthey are based in, and they are used to create newNormStrs. This explains the behavior of the sample I provided, where the content of "Uppercase string" had to be normalized, and thus theNormStrs for "uppercase" and "string" only had a reference to the content of that column, whereas "lowercase" had a reference to the whole row since "lowercase string" didn't have to be normalized.Code and input data
_data.csv_
_Program.cs_