Linkerd2: linkerd keeps talking with Terminating pods
Bug Report
What is the issue?
I encounter problems when one of my nodes crash and it looks like linkerd keeps sending traffic to pods on the failed node
How can it be reproduced?
- Install linkerd and emojivoto on a kind (procedure described here for kind) or kubeadm cluster (tested on 1.12, 1.15, 1.17) with at least 3 nodes. The number of master doesn't matter
- Install and configure metallb to provide an external IP to the emojivoto app
- mesh emojivoto
- Scale all emojivoto deployments to 2 replicas
- pause the container of a node containing a replica of an "emoji" pods
- Randomly, the web access will fail displaying emojis, being stuck on "Loading emojis"
I usually have to to the test a few times before it hits, deleting all pods and trying again but when it does occur, it doesn't matter how much time I wait, it will never get backup until i unpause the container (aka the node)
Logs, error output, etc
Here are screenshots of tests I did with relevent information
On the following screenshot, you can see that the endpoint list for the service has updated since i paused the first node, there is one valid endpoint for each service, however, the web container cannot reach the emoji service :
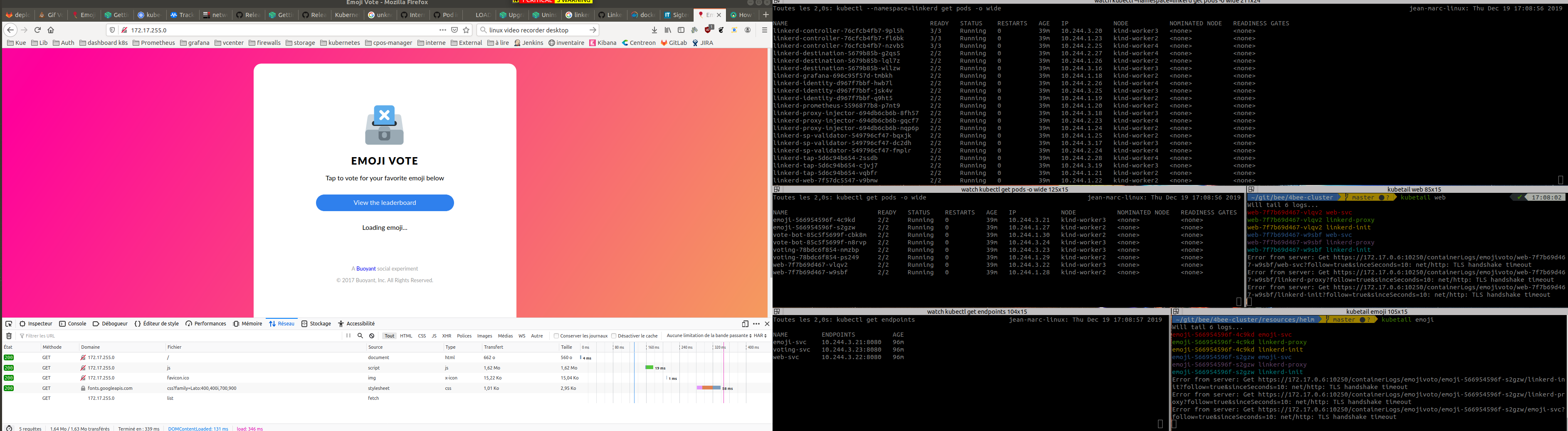
I decided to go on the web container to see if something would keep going through the pod in Terminating, and it looks like that's the case. We can see that the Terminating pods has 10.244.1.27 and when I get a failed access (Loading emojis), a line pops on tcpdump that shows an access to the Terminated pod (that is on the paused, hence unreachable node) :
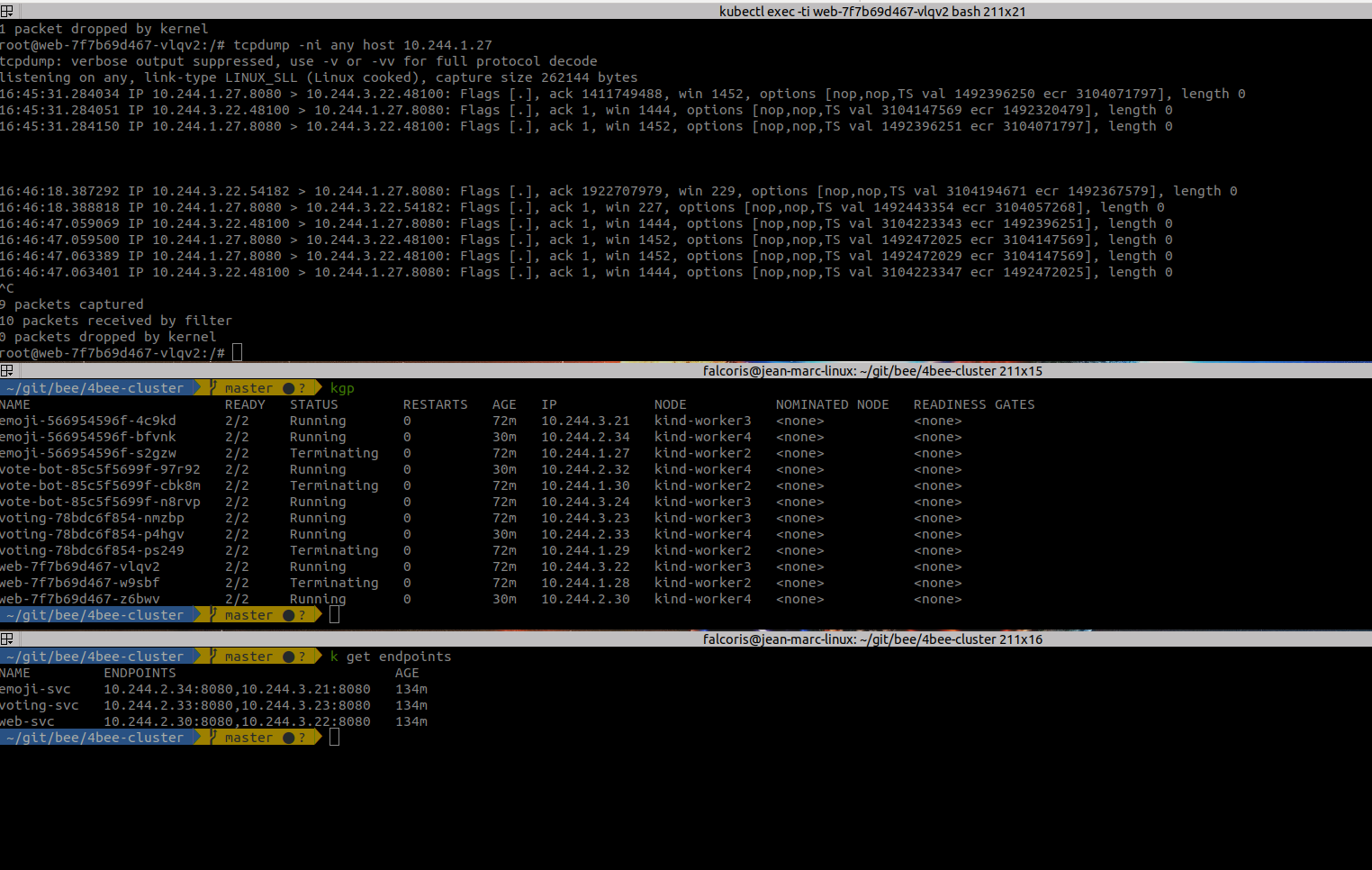
The node status is right :
**# k get nodes**
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
kind-control-plane Ready master 165m v1.17.0 172.17.0.2 <none> Ubuntu 19.10 4.15.0-72-generic containerd://1.3.2
kind-worker Ready <none> 165m v1.17.0 172.17.0.3 <none> Ubuntu 19.10 4.15.0-72-generic containerd://1.3.2
kind-worker2 NotReady <none> 165m v1.17.0 172.17.0.6 <none> Ubuntu 19.10 4.15.0-72-generic containerd://1.3.2
kind-worker3 Ready <none> 165m v1.17.0 172.17.0.5 <none> Ubuntu 19.10 4.15.0-72-generic containerd://1.3.2
kind-worker4 Ready <none> 165m v1.17.0 172.17.0.4 <none> Ubuntu 19.10 4.15.0-72-generic containerd://1.3.2
I get these logs from the web service :
**# kubetail web**
Will tail 6 logs...
web-7f7b69d467-vlqv2 web-svc
web-7f7b69d467-vlqv2 linkerd-proxy
web-7f7b69d467-vlqv2 linkerd-init
web-7f7b69d467-w9sbf web-svc
web-7f7b69d467-w9sbf linkerd-proxy
web-7f7b69d467-w9sbf linkerd-init
Error from server: Get https://172.17.0.6:10250/containerLogs/emojivoto/web-7f7b69d467-w9sbf/web-svc?follow=true&sinceSeconds=10: net/http: TLS handshake timeout
Error from server: Get https://172.17.0.6:10250/containerLogs/emojivoto/web-7f7b69d467-w9sbf/linkerd-proxy?follow=true&sinceSeconds=10: net/http: TLS handshake timeout
Error from server: Get https://172.17.0.6:10250/containerLogs/emojivoto/web-7f7b69d467-w9sbf/linkerd-init?follow=true&sinceSeconds=10: net/http: TLS handshake timeout
[web-7f7b69d467-vlqv2 linkerd-proxy] WARN [ 2516.257199s] linkerd2_app_core::errors request aborted because it reached the configured dispatch deadline
[web-7f7b69d467-vlqv2 web-svc] 2019/12/19 16:11:38 Error serving request [&{GET /api/list HTTP/1.1 1 1 map[Accept:[*/*] Accept-Encoding:[gzip, deflate] Accept-Language:[fr,fr-FR;q=0.8,en-US;q=0.5,en;q=0.3] Cache-Control:[no-cache] Pragma:[no-cache] Referer:[http://172.17.255.0/] User-Agent:[Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:71.0) Gecko/20100101 Firefox/71.0]] {} <nil> 0 [] false 172.17.255.0 map[] map[] <nil> map[] 127.0.0.1:33898 /api/list <nil> <nil> <nil> 0xc00047e0f0}]: rpc error: code = Unavailable desc = Service Unavailable: HTTP status code 503; transport: missing content-type field
[web-7f7b69d467-vlqv2 linkerd-proxy] WARN [ 2523.423009s] linkerd2_app_core::errors request aborted because it reached the configured dispatch deadline
[web-7f7b69d467-vlqv2 web-svc] 2019/12/19 16:11:45 Error serving request [&{GET /api/list HTTP/1.1 1 1 map[Accept-Encoding:[gzip] L5d-Dst-Canonical:[web-svc.emojivoto.svc.cluster.local:80] User-Agent:[Go-http-client/1.1] X-B3-Sampled:[1] X-B3-Spanid:[2229d22041321333] X-B3-Traceid:[e21697090568f270b4deb8464d8c96fa]] {} <nil> 0 [] false web-svc.emojivoto:80 map[] map[] <nil> map[] 127.0.0.1:34270 /api/list <nil> <nil> <nil> 0xc00057f4d0}]: rpc error: code = Unavailable desc = Service Unavailable: HTTP status code 503; transport: missing content-type field
[web-7f7b69d467-vlqv2 linkerd-proxy] WARN [ 2527.429689s] linkerd2_app_core::errors request aborted because it reached the configured dispatch deadline
[web-7f7b69d467-vlqv2 web-svc] 2019/12/19 16:11:49 Error serving request [&{GET /api/list HTTP/1.1 1 1 map[Accept-Encoding:[gzip] L5d-Dst-Canonical:[web-svc.emojivoto.svc.cluster.local:80] User-Agent:[Go-http-client/1.1] X-B3-Sampled:[1] X-B3-Spanid:[47a066af9f620523] X-B3-Traceid:[bc0252ad9edb2ac49bfdb09c01181548]] {} <nil> 0 [] false web-svc.emojivoto:80 map[] map[] <nil> map[] 127.0.0.1:34270 /api/list <nil> <nil> <nil> 0xc00047ebd0}]: rpc error: code = Unavailable desc = Service Unavailable: HTTP status code 503; transport: missing content-type field
[web-7f7b69d467-vlqv2 web-svc] 2019/12/19 16:11:53 Error serving request [&{GET /api/list HTTP/1.1 1 1 map[Accept-Encoding:[gzip] L5d-Dst-Canonical:[web-svc.emojivoto.svc.cluster.local:80] User-Agent:[Go-http-client/1.1] X-B3-Sampled:[1] X-B3-Spanid:[918e8fcc5cc3e902] X-B3-Traceid:[5ab67ff9b2b31ef1f90d44da10360d5e]] {} <nil> 0 [] false web-svc.emojivoto:80 map[] map[] <nil> map[] 127.0.0.1:34270 /api/list <nil> <nil> <nil> 0xc00057ff20}]: rpc error: code = Unavailable desc = Service Unavailable: HTTP status code 503; transport: missing content-type field
[web-7f7b69d467-vlqv2 linkerd-proxy] WARN [ 2531.435677s] linkerd2_app_core::errors request aborted because it reached the configured dispatch deadline
[web-7f7b69d467-vlqv2 linkerd-proxy] WARN [ 2535.453758s] linkerd2_app_core::errors request aborted because it reached the configured dispatch deadline
[web-7f7b69d467-vlqv2 web-svc] 2019/12/19 16:11:57 Error serving request [&{GET /api/list HTTP/1.1 1 1 map[Accept-Encoding:[gzip] L5d-Dst-Canonical:[web-svc.emojivoto.svc.cluster.local:80] User-Agent:[Go-http-client/1.1] X-B3-Sampled:[1] X-B3-Spanid:[b605245bbbf3dbf2] X-B3-Traceid:[ce0959706dc28605ef27acfdffe97274]] {} <nil> 0 [] false web-svc.emojivoto:80 map[] map[] <nil> map[] 127.0.0.1:34270 /api/list <nil> <nil> <nil> 0xc000435830}]: rpc error: code = Unavailable desc = Service Unavailable: HTTP status code 503; transport: missing content-type field
[web-7f7b69d467-vlqv2 web-svc] 2019/12/19 16:12:21 Error serving request [&{GET /api/list HTTP/1.1 1 1 map[Accept:[*/*] Accept-Encoding:[gzip, deflate] Accept-Language:[fr,fr-FR;q=0.8,en-US;q=0.5,en;q=0.3] Cache-Control:[no-cache] Pragma:[no-cache] Referer:[http://172.17.255.0/] User-Agent:[Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:71.0) Gecko/20100101 Firefox/71.0]] {} <nil> 0 [] false 172.17.255.0 map[] map[] <nil> map[] 127.0.0.1:33898 /api/list <nil> <nil> <nil> 0xc00057e6c0}]: rpc error: code = Unavailable desc = Service Unavailable: HTTP status code 503; transport: missing content-type field
[web-7f7b69d467-vlqv2 linkerd-proxy] WARN [ 2559.210677s] linkerd2_app_core::errors request aborted because it reached the configured dispatch deadline
[web-7f7b69d467-vlqv2 linkerd-proxy] WARN [ 2598.756060s] linkerd2_app_core::errors request aborted because it reached the configured dispatch deadline
linkerd check output
kubernetes-api
--------------
√ can initialize the client
√ can query the Kubernetes API
kubernetes-version
------------------
√ is running the minimum Kubernetes API version
√ is running the minimum kubectl version
linkerd-config
--------------
√ control plane Namespace exists
√ control plane ClusterRoles exist
√ control plane ClusterRoleBindings exist
√ control plane ServiceAccounts exist
√ control plane CustomResourceDefinitions exist
√ control plane MutatingWebhookConfigurations exist
√ control plane ValidatingWebhookConfigurations exist
√ control plane PodSecurityPolicies exist
linkerd-existence
-----------------
√ 'linkerd-config' config map exists
√ heartbeat ServiceAccount exist
√ control plane replica sets are ready
× no unschedulable pods
linkerd-controller-76cfcb4fb7-88kxm: 0/5 nodes are available: 2 node(s) didn't match pod affinity/anti-affinity, 3 node(s) had taints that the pod didn't tolerate.
linkerd-destination-5679b85b-w6tmn: 0/5 nodes are available: 2 node(s) didn't match pod affinity/anti-affinity, 3 node(s) had taints that the pod didn't tolerate.
linkerd-identity-d967f7bbf-z4dlf: 0/5 nodes are available: 2 node(s) didn't match pod affinity/anti-affinity, 3 node(s) had taints that the pod didn't tolerate.
linkerd-proxy-injector-694db6cb6b-rk7bm: 0/5 nodes are available: 2 node(s) didn't match pod affinity/anti-affinity, 3 node(s) had taints that the pod didn't tolerate.
linkerd-sp-validator-549796cf47-sw5px: 0/5 nodes are available: 2 node(s) didn't match pod affinity/anti-affinity, 3 node(s) had taints that the pod didn't tolerate.
linkerd-tap-5d6c94b654-4677v: 0/5 nodes are available: 2 node(s) didn't match pod affinity/anti-affinity, 3 node(s) had taints that the pod didn't tolerate.
see https://linkerd.io/checks/#l5d-existence-unschedulable-pods for hints
Status check results are ×
which is normal since I installed linkerd with HA replicas 3, it doesn't have enough nodes to schedule new pods to
# kr get pods
NAME READY STATUS RESTARTS AGE
linkerd-controller-76cfcb4fb7-88kxm 0/3 Pending 0 63m
linkerd-controller-76cfcb4fb7-9pl5h 3/3 Running 0 106m
linkerd-controller-76cfcb4fb7-fl6bk 3/3 Terminating 0 106m
linkerd-controller-76cfcb4fb7-nzvb5 3/3 Running 0 106m
linkerd-destination-5679b85b-g2qs5 2/2 Running 0 106m
linkerd-destination-5679b85b-lql7z 2/2 Terminating 0 106m
linkerd-destination-5679b85b-w6tmn 0/2 Pending 0 63m
linkerd-destination-5679b85b-wllzw 2/2 Running 0 106m
linkerd-grafana-696c95f57d-gxxjx 2/2 Running 0 63m
linkerd-grafana-696c95f57d-tmbkh 2/2 Terminating 0 106m
linkerd-identity-d967f7bbf-hwb7l 2/2 Running 0 106m
linkerd-identity-d967f7bbf-jsk4v 2/2 Running 0 106m
linkerd-identity-d967f7bbf-q9ht5 2/2 Terminating 0 106m
linkerd-identity-d967f7bbf-z4dlf 0/2 Pending 0 63m
linkerd-prometheus-5596877b8-4k2l4 2/2 Running 0 63m
linkerd-prometheus-5596877b8-p7nt9 2/2 Terminating 0 106m
linkerd-proxy-injector-694db6cb6b-8fh57 2/2 Running 0 106m
linkerd-proxy-injector-694db6cb6b-gqcf7 2/2 Running 0 106m
linkerd-proxy-injector-694db6cb6b-nqp6p 2/2 Terminating 0 106m
linkerd-proxy-injector-694db6cb6b-rk7bm 0/2 Pending 0 63m
linkerd-sp-validator-549796cf47-bqxjk 2/2 Terminating 0 106m
linkerd-sp-validator-549796cf47-dc2dh 2/2 Running 0 106m
linkerd-sp-validator-549796cf47-fmplr 2/2 Running 0 106m
linkerd-sp-validator-549796cf47-sw5px 0/2 Pending 0 63m
linkerd-tap-5d6c94b654-2ssdb 2/2 Running 0 106m
linkerd-tap-5d6c94b654-4677v 0/2 Pending 0 63m
linkerd-tap-5d6c94b654-cjvj7 2/2 Running 0 106m
linkerd-tap-5d6c94b654-vqbfr 2/2 Terminating 0 106m
linkerd-web-7f57dc5547-lhrqs 2/2 Running 0 63m
linkerd-web-7f57dc5547-v9bmw 2/2 Terminating 0 106m
Environment
- Kubernetes Version: 1.17
- Cluster Environment: Kind
- Host OS: Ubuntu 19.10
- Linkerd version: 2.6.1
Possible solution
Additional context
 falcoriss
falcoriss
All 16 comments
@adleong @olix0r I'm pattern matching, but this sounds like more staleness in what appears to be an easy repro.
 grampelberg
on 19 Dec 2019
grampelberg
on 19 Dec 2019
It would be good to narrow this down a bit to help determine if this is a kind/kubeadm bug or a Linked bug. I'm not too familiar with the consequences of pausing node containers.
What output does kubectl -n emojivoto get endpoints/emoji yield? Does that command show the up-to-date emoji ip addresses, or the stale ones? Similarly, what about linkerd endpoints emoji.emojivoto.svc.cluster.local?
 adleong
on 23 Dec 2019
adleong
on 23 Dec 2019
It would be good to narrow this down a bit to help determine if this is a kind/kubeadm bug or a Linked bug. I'm not too familiar with the consequences of pausing node containers.
I orginally noticed the bug on VMWare VMs installed with kubespray (kubeadm) so it's not just a container linkerd problem. I switched to kind for tests because it's more convenient and because i could reproduce this.
What output does kubectl -n emojivoto get endpoints/emoji yield? Does that command show the up-to-date emoji ip addresses, or the stale ones?
This information is displayed on the first screenshot (right screen, bottom left hand corner). When the pod-eviction-timeout occurs, a second pod is added to the endpoints but the problem remains. the k8s endpoints are therefore correct.
Similarly, what about linkerd endpoints emoji.emojivoto.svc.cluster.local?
They do update too (although i noticed that they don't always but it doesn't seem to affect the end result.)
Here's attached a video recording of my test. there are watch commands on the right while I pause the container of one of the node backing up 1/2 emoji pod. I thought it would be helpfull.
It took me 3 tries to get it today (deleting all pods in the namespace between each try)
falcoriss
on 24 Dec 2019
Thanks for all this super detailed info, @falcoriss. This does indeed sound like a staleness issue. I'll spend some time following your instructions and see if I can reproduce this myself. In the meantime, if you're able to reproduce this with the proxy log level set to DEBUG, the proxy logs from the web pod would also be very helpful.
adleong
on 30 Dec 2019
Ok so I think this happens when the node that you pause happens to be the node with the linkerd-destination instance that web is talking to.
When the node container becomes paused, the linkerd-destination process will be paused and will not send any updates to the linkerd-proxy in the web pod. However, in my testing, the linkerd-destination pod will still ack TCP keep-alives. (perhaps because TCP acks are handled by the host os?) This means that the linkerd-proxy in the web pod will never detect this connection as dead and will not attempt to reconnect to a different linkerd-destination pod.
In the long term, I think the right solution for issues like this is to have higher level keepalives in the form of HTTP2 ping frames.
adleong
on 31 Dec 2019
In terms of work-arounds, I'd need to know more about why you're pausing node containers and if that's a scenario that can be avoided.
adleong
on 31 Dec 2019
Ok so I think this happens when the node that you pause happens to be the node with the linkerd-destination instance that web is talking to.
You must be onto something cause I did notice a link between the problem and the destination pods
In terms of work-arounds, I'd need to know more about why you're pausing node containers and if that's a scenario that can be avoided.
We've started experiencing this problem because one of our node went all crazy high load until it was mostly unresponsive (couldn't SSH and stuff). It happened a few times in a few months and everytime we'd have an app outage, I don't find this normal as it would always only be one node and I thought kubernetes should handle this well.
Now the docker pause thing was a way to simulate a suddenly unresponsive node. I did also try with VMs + kubeadm and was experiencing similar problems when pausing them.
BTW, if you have a better idea to try this out I'm keen :)
In the long term, I think the right solution for issues like this is to have higher level keepalives in the form of HTTP2 ping frames.
That sounds like a great idea. How hard would that be to change that ?
falcoriss
on 31 Dec 2019
I've reopened #1580 to track the HTTP/2 ping frame work.
Another potential solution would be to add some kind of timeout that causes Linkerd to re-establish connections which have been idle for a certain duration.
adleong
on 7 Jan 2020
sounds good !
Do you still need me to try with the proxy log level set to DEBUG as you asked earlier or it's not needed anymore ?
Also, I'm wondering why the communication with destination is mandatory for the service to work. As I understood it, linkerd could work without the control plane. Or is it because there is a change in the data plane at the same time that it makes all this mess ?
falcoriss
on 7 Jan 2020
I think we've got a pretty good understanding of the issue now, so I don't think we need to gather additional logs.
The Linkerd proxy gets service discovery information from the destination controller. If that communication fails, Linkerd will continue to work with the last known service discovery information, but whenever pods are created or destroyed, the Linkerd proxy will not receive updates and will continue to attempt to route to the outdated addresses.
adleong
on 7 Jan 2020
Newer versions of Linkerd (e.g., edge-20.3.4) have been updated to handle service discovery differently. If you're still experiencing these issues, I recommend annotating your workload with config.linkerd.io/proxy-version: edge-20.3.4. If you test this, please report back! These changes will be released soon in stable-2.7.1.
 olix0r
on 30 Mar 2020
olix0r
on 30 Mar 2020
Sorry it took me so long to come back here, I was busy on other matters.
I've migrated on 2.7.1 and the problem still occurs. Cutting a node with a replicas of linkerd-destination still wrecks everything.
I advise to test with the same scenario to check that out.
falcoriss
on 12 Jun 2020
We're seeing the same issue as @falcoriss in our clusters. @olix0r or @adleong what is the status on this bug?
for reference we are running the following versions in AKS -
k8s - 1.16.7
LinkerD stable-2.7.1
 jawhites
on 19 Jun 2020
jawhites
on 19 Jun 2020
@falcoriss sorry for the radio silence here, this issue fell off of my radar. Sorry to hear that 2.7.1 didn't resolve this for you. I still maintain that adding ping frames as described in https://github.com/linkerd/linkerd2/issues/1580 is the right long term solution to this problem.
In the meantime, if there's any way to avoid pausing node containers, that's what I'd strongly recommend.
adleong
on 7 Aug 2020
This issue has been automatically marked as stale because it has not had recent activity. It will be closed in 14 days if no further activity occurs. Thank you for your contributions.
![stale[bot] picture](https://avatars3.githubusercontent.com/in/1724?v=4&s=40) stale[bot]
on 7 Nov 2020
stale[bot]
on 7 Nov 2020
I'm going to close this issue in favor of #1580, which is slated for stable-2.10
olix0r
on 12 Nov 2020
Related issues
 wmorgan
·
3Comments
wmorgan
·
3Comments
 vikas027
·
4Comments
vikas027
·
4Comments
 ihcsim
·
4Comments
ihcsim
·
4Comments
 miklezzzz
·
3Comments
ihcsim
·
4Comments
miklezzzz
·
3Comments
ihcsim
·
4Comments
Most helpful comment
Sorry it took me so long to come back here, I was busy on other matters.
I've migrated on 2.7.1 and the problem still occurs. Cutting a node with a replicas of linkerd-destination still wrecks everything.
I advise to test with the same scenario to check that out.