Linkerd2: Public facing services exposed via nginx-ingress suffer from higher latencies
I have 2 public-facing services, handled by nginx-ingress-controller. Since injecting Conduit into one of the service deployments (the green one on the following chart), its avg response time (as reported by nginx to prometheus) keeps going up.
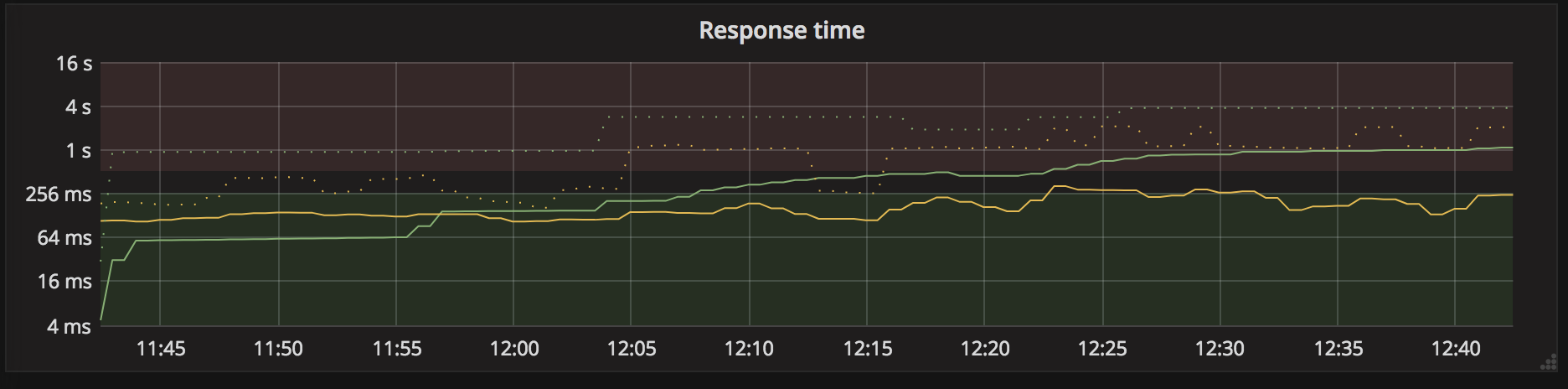
Looking at the Conduit stats in the dashboard for this service, I am not seeing this rise in response time.
Restarting the ingress controller pods made the response time go back down where it usually is, but it started growing again over time.
In short, the calls go from (nginx) -> (conduit proxy -> green service)
and conduit's stats don't reflect that latency increase, but nginx's do.
 bourquep
bourquep
All 20 comments
I'm curious if #434 could be related to this -- does the _green service_ talk to MongoDB by any chance?
My theory is that latency increases as we leak connections.
 olix0r
on 23 Feb 2018
olix0r
on 23 Feb 2018
Yes, it does talk to Mongo but not via Conduit anymore (I am excluding the Mongo port from outbound connections via --skip-outbound-ports).
bourquep
on 23 Feb 2018
But the nature of both problems feels similar: in the Mongo case, it is pretty clearly a connection leak issue. In the nginx-controller case, could it be that the Conduit proxy receiving those external requests also leaks those connections, leading to higher latencies between nginx and conduit?
Since I am not observing those high latency in Conduit Dashboard, it leads to think that the actual service implementation is still as fast as it used to, but ingress connections pile up.
bourquep
on 23 Feb 2018
I don't have any leads yet on to why the latency is increasing, but I think I do know why Conduit isn't reporting it: the http Event::StreamRequestOpen is triggered just before we serialize the request, and so any time since having accepted the request originally and waiting on DNS, connecting, and waiting in queue is not calculated in the latency.
 seanmonstar
on 27 Feb 2018
seanmonstar
on 27 Feb 2018
So, we do collect telemetry on both client and server socket opens and closes, but it looks like those events don't get forward into prometheus, and so cannot be shown in the conduit dashboard. So, the next is: is it possible to collect stats from nginx and/or the service in regards to if they are creating/receiving many connections that then just sit idle, never used again?
seanmonstar
on 27 Feb 2018
I separated out the aspect of the telemetry not being accurate into #479 so that this issue can be about the latency being bad and/or increasing.
 briansmith
on 28 Feb 2018
briansmith
on 28 Feb 2018
Hi @bourquep,
We're looking into reproducing this behavior right now. It would be helpful to know what protocols are being used in your case: Is it HTTP/1, HTTP/2, or TCP by chance?
Thanks!
 franziskagoltz
on 14 Mar 2018
franziskagoltz
on 14 Mar 2018
Ingress traffic is HTTP/1 (that may be upgraded to 2). Intra-service comms are via gRPC.
bourquep
on 14 Mar 2018
Quick update:
In an attempt to recreate this, we've had services receiving traffic via the conduit proxy for about ~30 hours now and have not seen an increase in latency.
Screenshot below:
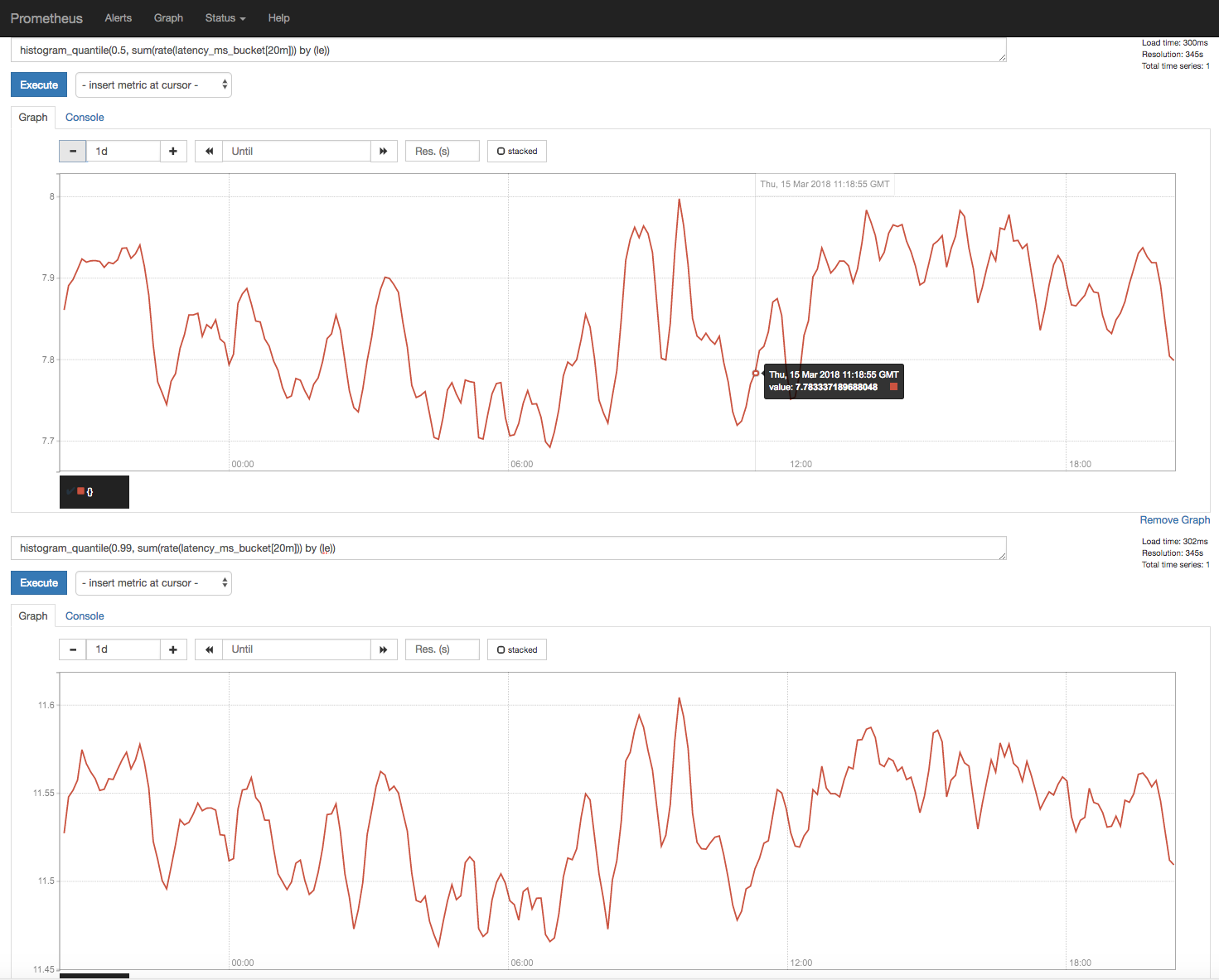
Right now, we've added nginx to route calls to the proxy. So far we haven't seen an increase in latency, though it's only been ~1 hour. We will keep this running for another day as well to see if anything changes and give another update.
This is the config we're using in an attempt to recreate the issue:
https://gist.github.com/franziskagoltz/67de000256122ba37d326657cbd8ef15
However, if you have a config that recreates this issue and are willing to share it with us, that might help us with debugging and speed up the process. If there's anything you'd be willing to share, we'd appreciate it. Thanks!
franziskagoltz
on 16 Mar 2018
In my case, the main HTTP handler for the ingress traffic calls into a few internal services via gRPC and HTTP, all of them proxied by Conduit.
Could I be observing the sum of overhead introduced by each proxy traversal?
I will try this again once 0.3.1 is released, and I'll try to gather more data to help diagnose this issue.
bourquep
on 16 Mar 2018
 wmorgan
on 16 Mar 2018
wmorgan
on 16 Mar 2018
What?!? Did I miss the announcement? Anyhow, cool! I'll give it a spin tomorrow!
bourquep
on 16 Mar 2018
The announcement is only about 30mins old 😄
And great, thanks! We'll update as well once the new test has been running for a while longer.
franziskagoltz
on 16 Mar 2018
I've been running 0.3.1 in prod for about an hour, and so far I haven't observed the raise in ingress latency that I was experiencing initially. So far so good!
bourquep
on 16 Mar 2018
Wonderful, very glad to hear! Is it still latency still stable?
We've been running the test overnight and so far also have not been able to reproduce it either.
franziskagoltz
on 16 Mar 2018
We've been running the test overnight and so far also have not been able to reproduce it either.
Did we reproduce it on 0.3.0?
briansmith
on 16 Mar 2018
Yes, I should have been more clear. We've been trying to reproduce it with 0.3.0 but without success.
franziskagoltz
on 16 Mar 2018
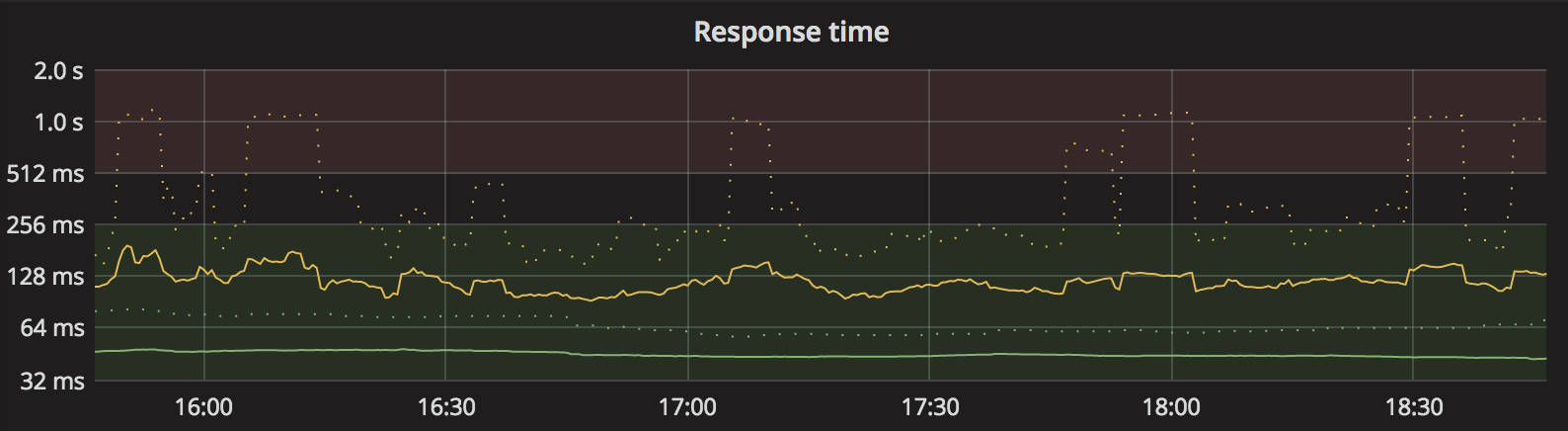
Yup, still stable. Here's the same chart as I had initially posted when opening this issue, for the past 3 hours with Conduit 0.3.1 injected into the same services as initially:
bourquep
on 16 Mar 2018
So I'm not quite sure what the cause was, but anyhow it is fine now. I believe you can close this issue now. #479 will still be useful, but unrelated to the current issue.
bourquep
on 16 Mar 2018
Alright, I'll go ahead and close the issue. Please feel free to reopen it again, if you see the issue again.
franziskagoltz
on 17 Mar 2018
Related issues
 geekmush
·
4Comments
geekmush
·
4Comments
 miklezzzz
·
3Comments
miklezzzz
·
3Comments
 alpeb
·
3Comments
alpeb
·
3Comments
 adleong
·
4Comments
wmorgan
·
3Comments
adleong
·
4Comments
wmorgan
·
3Comments
Most helpful comment
Yup, still stable. Here's the same chart as I had initially posted when opening this issue, for the past 3 hours with Conduit 0.3.1 injected into the same services as initially: