Lightgbm: instability caused by floating point errors
How you are using LightGBM?
LightGBM component: Python package
Environment info
Operating System: Ubuntu 20.04.1 LTS
CPU/GPU model: Intel(R) Xeon(R) Platinum 8259CL CPU @ 2.50GHz
C++ compiler version: gcc version 9.3.0 (Ubuntu 9.3.0-10ubuntu2)
CMake version: 3.16.3
Java version: N/A
Python version: 3.8.5
R version: N/A
Other:
LightGBM version or commit hash: 3.0.0 (also happens in 3.0.0.99 afc76d2cb8234f6876ed75d923a7916bfef9a1e5)
Error message and / or logs
Given the same data/parameters/seeds lightgbm sometimes produces different models/outputs. This makes experiment reproducibility problematic. I believe this is the result of some kind of floating point operation error propagation. Models initially start the same but when the pickled model files are inspected they start to differ after >250 iterations. I have noticed this error before in lightgbm 2.3.1 but worked around it by disabling bagging. #2598 In this version I get the same error even without using bagging. In the notebook inside the linked repo I have tried running the models 5 times and got different results every time. Results also change when the notebook is restarted.
Reproducible example(s)
Data and code required to reproduce this bug: https://github.com/rebidaldal/lightgbmBugreport
X_train = pd.read_feather("X_train.feather")
y_train = pd.read_feather("y_train.feather")
X_test = pd.read_feather("X_test.feather")
param = {}
param['boosting_type'] = 'gbdt'
param['feature_fraction'] = 0.2
param['feature_fraction_bynode'] = 0.5
param['lambda_l2'] = 1
param['learning_rate'] = 0.02
param['max_bin'] = 31
param['max_delta_step'] = 63
param['max_depth'] = 20
param['metric'] = 'rmse'
param['min_data_in_bin'] = 8191
param['min_data_in_leaf'] = 8191
param['min_gain_to_split'] = 1
param['num_leaves'] = 100
param['objective'] = 'regression'
param['verbosity'] = -1
param['seed'] = 1
dTrain = lgb.Dataset(X_train, label=y_train)
model = lgb.train( param, dTrain, 1000)
preds = model.predict(X_test)
preds
array([15.032409 , 15.06296509, 14.98345116, ..., 15.24531394,
15.1225563 , 15.07920504])
dTrain = lgb.Dataset(X_train, label=y_train)
model2 = lgb.train( param, dTrain, 1000)
preds2 = model2.predict(X_test)
preds2
array([15.05416012, 15.00900578, 14.97445924, ..., 15.17322033,
15.05276989, 15.01204842])
np.corrcoef(preds, preds2)
array([[1. , 0.98490951],
[0.98490951, 1. ]])
Steps to reproduce
- Download and unzip data from repo: https://github.com/rebidaldal/lightgbmBugreport
- Run the jupyter notebook from the repo :bug.ipynb or the code above
- Observe results
 rebidaldal
rebidaldal
All 44 comments
@rebidaldal i run your codes, and seems no problem.

you can try to set force_col_wise=True.
 guolinke
on 9 Sep 2020
guolinke
on 9 Sep 2020
BTW, you set min_data_in_bin to a very large value. This seems unreasonable.
guolinke
on 9 Sep 2020
I also run it for 100 times. seems no problems.
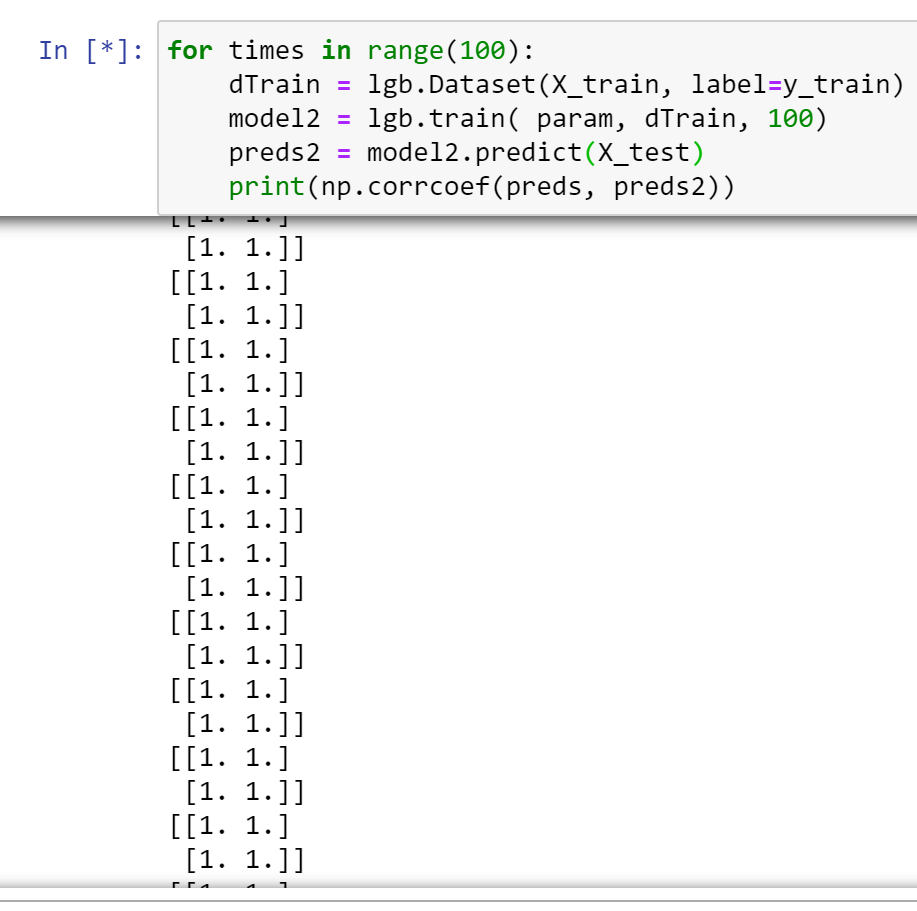
guolinke
on 9 Sep 2020
I tried it with your suggestions (force_col_wise=True, min_data_in_bin = 100 (now constrained with max_bin)) However the issue persists.
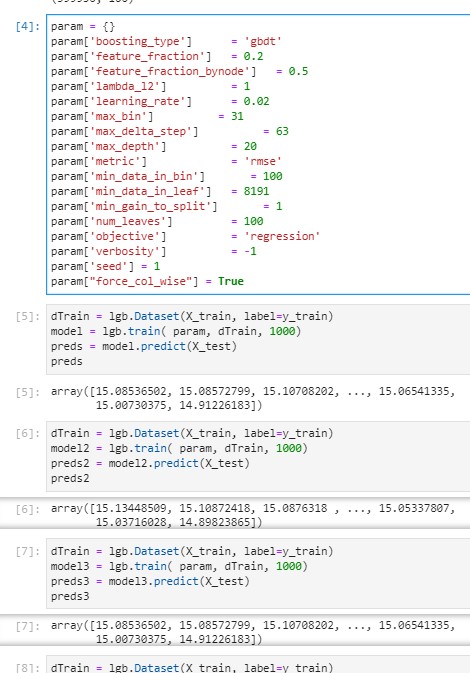
rebidaldal
on 9 Sep 2020
I have added the model files to https://github.com/rebidaldal/lightgbmBugreport if that helps. I also managed to create an even more minimal example:
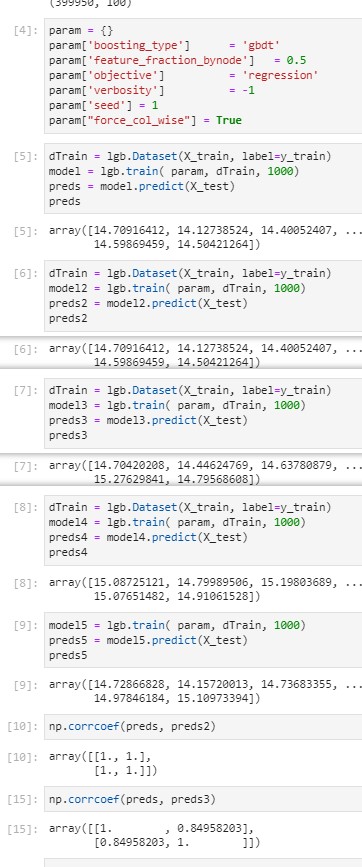
issue seems to be related to feature fraction by node. However the models have the same feature_fraction_seed (generated by main seed). It also may be related to number of cores. I can consistently get this bug on the AWS machine I use (r5.12xlarge with Xeon(R) Platinum 8259CL CPU which has 48 cores) but not on my laptop (core i7-7500U with only 2 cores)
rebidaldal
on 9 Sep 2020
I was able to reproduce the problem using WSL2 with Ubuntu 20.04 (I did not try on any other distro) but it works fine on Windows 10.0.19041.450 , on the same machine. might be due to fork vs creation..
 kocas
on 9 Sep 2020
kocas
on 9 Sep 2020
@rebidaldal
I check the generated model file, it seems the problem is in training. There are some floating-point rounding differences.
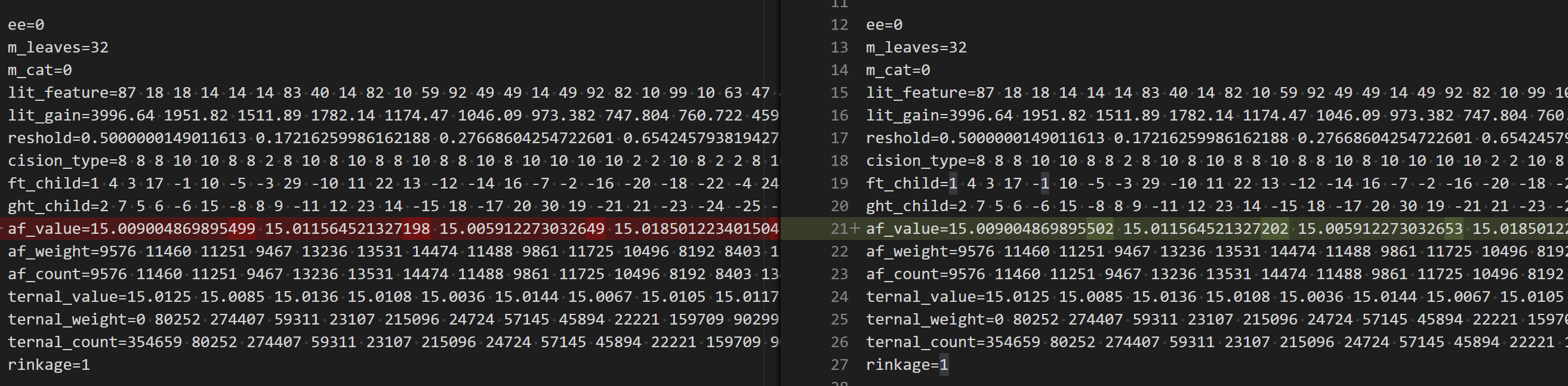
@rebidaldal can you try to fix num_threads to a relatively small value? like 8 or 4?
guolinke
on 10 Sep 2020
BTW, can you try boost_from_average to false?
I find all leaf values are different in the first tree, it may be related to this.
guolinke
on 10 Sep 2020
Hi @guolinke thank you for your suggestions.
I have tried running it with different number of threads, it works fine with 4 threads but instability starts to build up after 8 threads. In this sample data using 4 threads is fine but my actual data is nearly 1000 times larger thus I need to run it with 96 cores. So far this issue seems to be related to some combination of linux/threading/colsample_bynode.
@guolinke have you tried running it on some non-windows machine to replicate the bug?

disabling boosting from average does not help and actually makes this issue worse since I guess it gets to the build floating point error more when staring from 0 instead of 15.
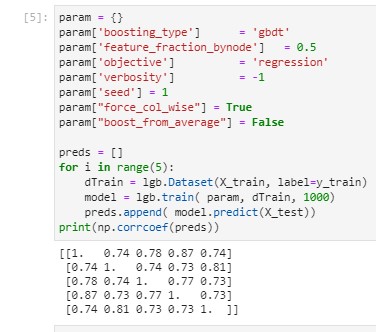
rebidaldal
on 10 Sep 2020
@rebidaldal I think colsample_bynode will not cause this problem.
did you try boost_from_average=false ?
guolinke
on 10 Sep 2020
@rebidaldal BTW, LightGBM is not NUMA-aware, using it to the multi-socket cpus will be much slower.
96-core seems is multi-socket. you can try to use the cores of one CPU only.
guolinke
on 10 Sep 2020
@rebidaldal I think
colsample_bynodewill not cause this problem.
did you try boost_from_average=false ?
yes I did, but unfortunately it did not help.
Code is in notebook bug_4 in the repo.
rebidaldal
on 10 Sep 2020
In this example I worked on a single socket 32 machine but at only 8 threads training results start to differ
@rebidaldal BTW, LightGBM is not NUMA-aware, using it to the multi-socket cpus will be much slower.
96-core seems is multi-socket. you can try to use the cores of one CPU only.
In this example I worked on a single socket 32 core machine but strating from num_threads = 8 training results are unstable
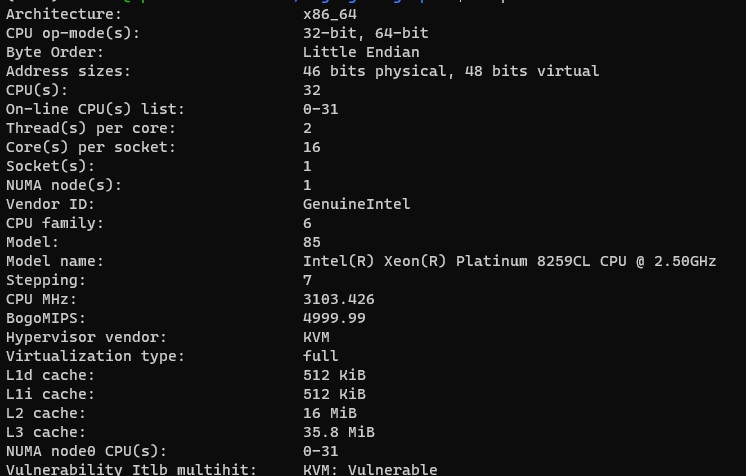
rebidaldal
on 10 Sep 2020
@rebidaldal I think
colsample_bynodewill not cause this problem.
Yes, this issue is not specific to colsample_bynode but related to threading + randomness in general. I get a similar error when I try to use bagging too.
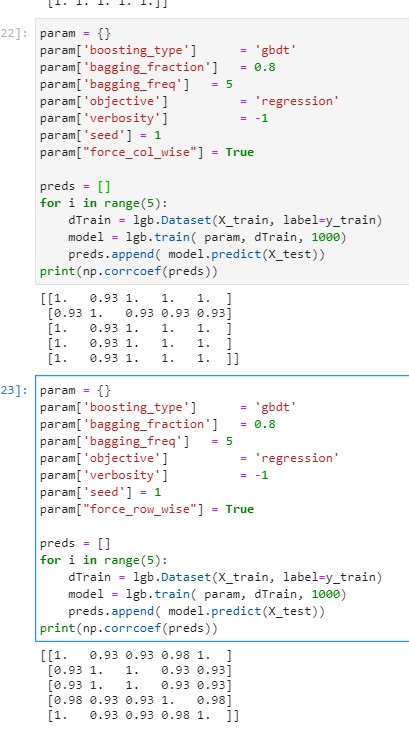
rebidaldal
on 10 Sep 2020
@rebidaldal did you mean that without bagging/sub_feature, the result is stable?
guolinke
on 10 Sep 2020
@rebidaldal BTW, can you try keep_training_booster=True in lgb.train?
guolinke
on 10 Sep 2020
@rebidaldal did you mean that without bagging/sub_feature, the result is stable?
Yes. I need to disable them both to keep it stable. Only turning one of them on is however sufficient for this bug to occur.
All params default:
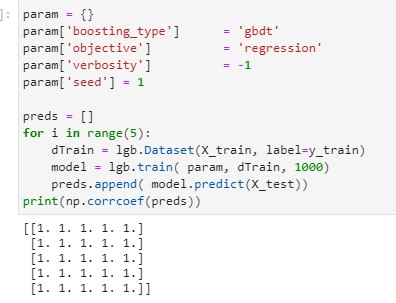
All params set to some custom value vs all but bagging/ff_by_node :

rebidaldal
on 10 Sep 2020
@rebidaldal BTW, can you try
keep_training_booster=Truein lgb.train?

thank you for the suggestion but it also did not help
rebidaldal
on 10 Sep 2020
Interesting, I will find a Linux machine to test this weekend.
guolinke
on 11 Sep 2020
@rebidaldal
could you try fillna by constants? like
X_train = pd.read_feather("X_train.feather").fillna(0)
y_train = pd.read_feather("y_train.feather")
X_test = pd.read_feather("X_test.feather").fillna(0)
@rebidaldal
I think #3384 should fix the instability when using subfeature_bynode, you can have a try.
guolinke
on 12 Sep 2020
3385 should fix the bagging.
@rebidaldal please let me know if the problem still exists.
guolinke
on 12 Sep 2020
Hi @guolinke
I have checked out branch #3385 with the two fixes and re-ran my tests and it looks like the instability problem is solved for now. I will do more tests on real-life sized data and I will let you know if there are any remaining issues.
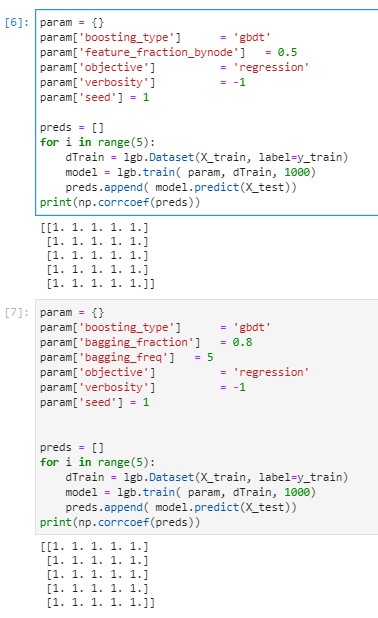
Thank you very much for the fixes.
rebidaldal
on 12 Sep 2020
Hi @guolinke
I was maybe too eager to declare that the instability issue is solved. One more test on the sample data with both baggingand feature_fraction_bynodeon shows that there is at least one more bug remaining.
both turned on using the same 32 core machine with single socket / single NUMA node
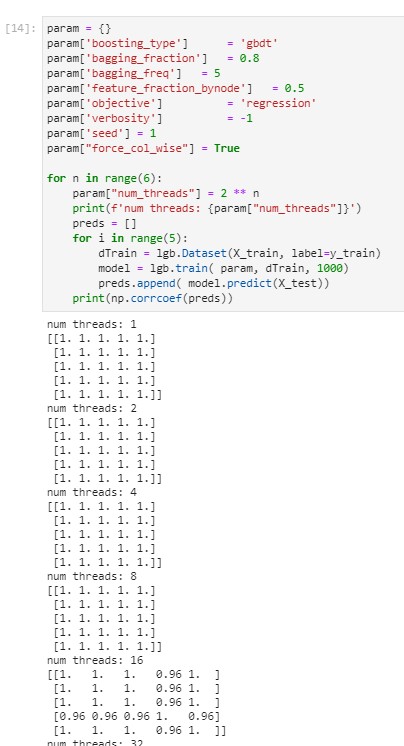
rebidaldal
on 12 Sep 2020
my tests show that the issue with feature_fraction_bynode is solved, but the baggingproblem remains. Although it is mitigated since I did not catch it with 5 runs.

rebidaldal
on 12 Sep 2020
@rebidaldal is it the same test data?
guolinke
on 13 Sep 2020
It is very strange, #3385 should make the deterministic sum operations for floating-point.
I push some new changes, could you test again?
If it still cannot work, can you try to set is_sparse = False ?
guolinke
on 13 Sep 2020
Hi @guolinke
Yes, I am still using the same data. Although I changed the number of test from 5 to 10.
I tested again with the new changes;
- The issue related to ff_bynode is solved, therefore I stopped testing for it
- The issue related to bagging remains.
- is_sparse = False unfortunately did not work.

rebidaldal
on 14 Sep 2020
@rebidaldal can you test this branch? https://github.com/microsoft/LightGBM/tree/sum-test
guolinke
on 14 Sep 2020
@rebidaldal BTW, on my linux machine, I cannot reproduce this anymore, with fixes in #3385
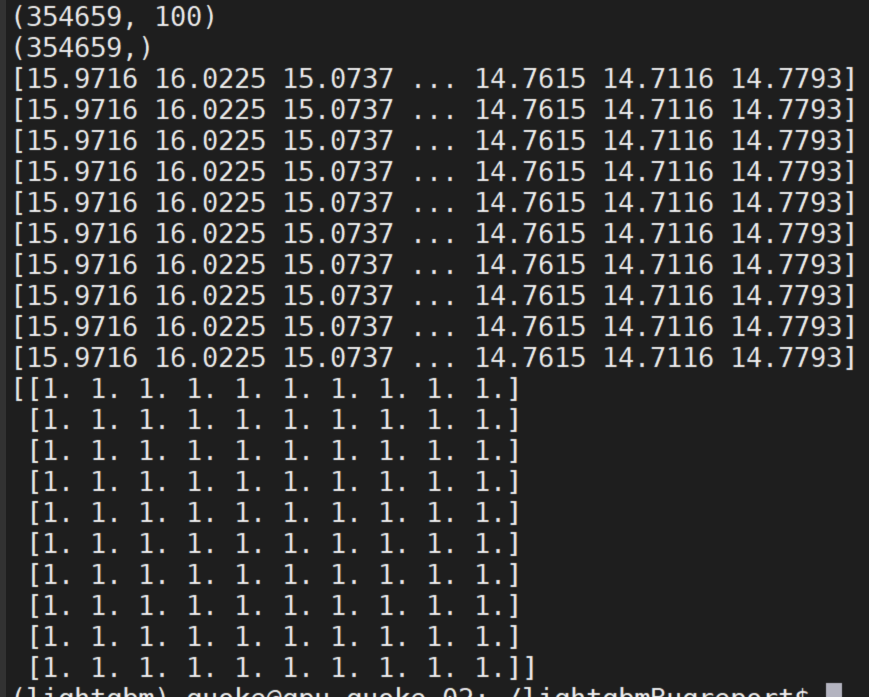
guolinke
on 14 Sep 2020
@rebidaldal can you test this branch? https://github.com/microsoft/LightGBM/tree/sum-test
This branch breaks ff_bynode. Perhaps #3384 fix is not in it. But it does not fix bagging.

It looks likefillna(0)also fixes instability but this workaround is not acceptable for my use case.
the fixes in #3385 have really mitigated the instability issue. Sometimes I get lucky and see no instability at all. (usually up to 8 cores, then with 16-32-64 cores some instability starts). I will try to revert to branch omp-reduction, build on a fresh machine, etc ... to check again.
rebidaldal
on 14 Sep 2020
@rebidaldal yeah, that branch is to debug the omp reduction is the root cause or not.
As it doesn't work with bagging, i think there are some other places that also cause the problem.
guolinke
on 14 Sep 2020
I will try on ubuntu 20.04 this weekend. Currently, I use 18.04, and seems everything is fine. (24 cores).
guolinke
on 14 Sep 2020
sorry, I am busy recently, will come back to this issue at the end of OCT.
guolinke
on 27 Sep 2020
an update: the previous solution for stable multi-threading sum is very slow.
I just create a PR to rollback it. it may cause the instability of floating-point. But I think efficiency is more important.
Maybe we can have a parameter, named deterministic, and generate stable results (but may slower) when it is enabled.
guolinke
on 27 Oct 2020
@rebidaldal
I just run your code on 20.04 with deterministic branch, but still cannot reproduce.
the results:
>>> X_train = pd.read_feather("X_train.feather")
>>> y_train = pd.read_feather("y_train.feather")
>>>
>>> param = {}
>>> param['boosting_type'] = 'gbdt'
>>> #param['feature_fraction_bynode'] = 0.5
>>> param['bagging_freq'] = 5
>>> param['bagging'] = 0.8
>>> param['objective'] = 'l2'
>>> param['verbosity'] = -1
>>> param["force_col_wise"] = True
>>> param["boost_from_average"] = False
>>> param["deterministic"] = True
>>>
>>>
>>> preds = []
>>>
>>> for i in range(10):
... dTrain = lgb.Dataset(X_train, label=y_train)
... model = lgb.train(param, dTrain, 1000)
... model.save_model('model_{}.txt'.format(i))
... pred = model.predict(X_train)
... print(pred)
... preds.append(pred)
...
<lightgbm.basic.Booster object at 0x7fcc995826a0>
[15.7589 15.4859 14.8892 ... 14.6908 14.5152 14.6325]
<lightgbm.basic.Booster object at 0x7fcc99582e80>
[15.7589 15.4859 14.8892 ... 14.6908 14.5152 14.6325]
<lightgbm.basic.Booster object at 0x7fcc99582580>
[15.7589 15.4859 14.8892 ... 14.6908 14.5152 14.6325]
<lightgbm.basic.Booster object at 0x7fcc995827f0>
[15.7589 15.4859 14.8892 ... 14.6908 14.5152 14.6325]
<lightgbm.basic.Booster object at 0x7fcc995825e0>
[15.7589 15.4859 14.8892 ... 14.6908 14.5152 14.6325]
<lightgbm.basic.Booster object at 0x7fcc99582850>
[15.7589 15.4859 14.8892 ... 14.6908 14.5152 14.6325]
<lightgbm.basic.Booster object at 0x7fcc995827c0>
[15.7589 15.4859 14.8892 ... 14.6908 14.5152 14.6325]
<lightgbm.basic.Booster object at 0x7fcc995825e0>
[15.7589 15.4859 14.8892 ... 14.6908 14.5152 14.6325]
<lightgbm.basic.Booster object at 0x7fcc99582fa0>
[15.7589 15.4859 14.8892 ... 14.6908 14.5152 14.6325]
<lightgbm.basic.Booster object at 0x7fcc99582f70>
[15.7589 15.4859 14.8892 ... 14.6908 14.5152 14.6325]
>>> print(np.corrcoef(preds))
[[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]]
Is that possible that we reproduce it in a docker?
guolinke
on 27 Oct 2020
Hi Guolin, I will try to make docker containers for deterministic and default (3.0.99) branches and share it with you. I already have some Amazon Machine Images on hand but they are kind of troublesome to share. Is there any other branches you would suggest me to try and reproduce the bug?
Thanks.
rebidaldal
on 27 Oct 2020
Thanks @rebidaldal , you can usedeterministic branch, with param["deterministic"] = True.
guolinke
on 28 Oct 2020
@guolinke
I've noticed you've write in #3494
partial fix #3372
Should we reopen this issue?
 StrikerRUS
on 1 Nov 2020
StrikerRUS
on 1 Nov 2020
yes, as I cannot reproduce @rebidaldal 's case, let us wait for the docker version.
guolinke
on 2 Nov 2020
Hi Guolin,
Today as I was trying to set up the docker image I noticed that as-of version 3.1.0 and param["deterministic"] = True the instability issue looks solved.
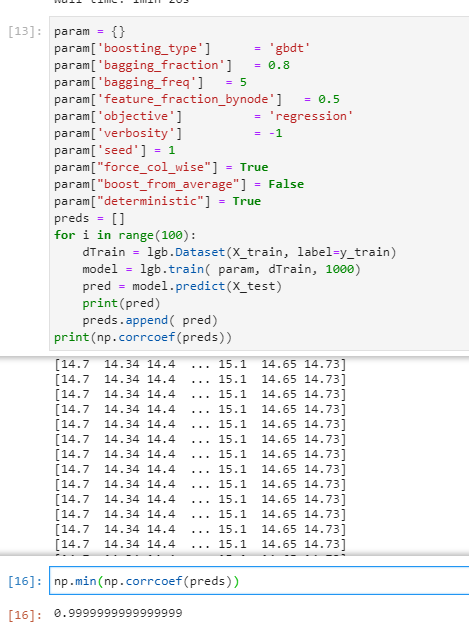
After 100 runs the results do not differ at all :D
Also as far as I can see with this rudimentary benchmark, the performance is not adversely affected at all. ( %1 difference is negligible )
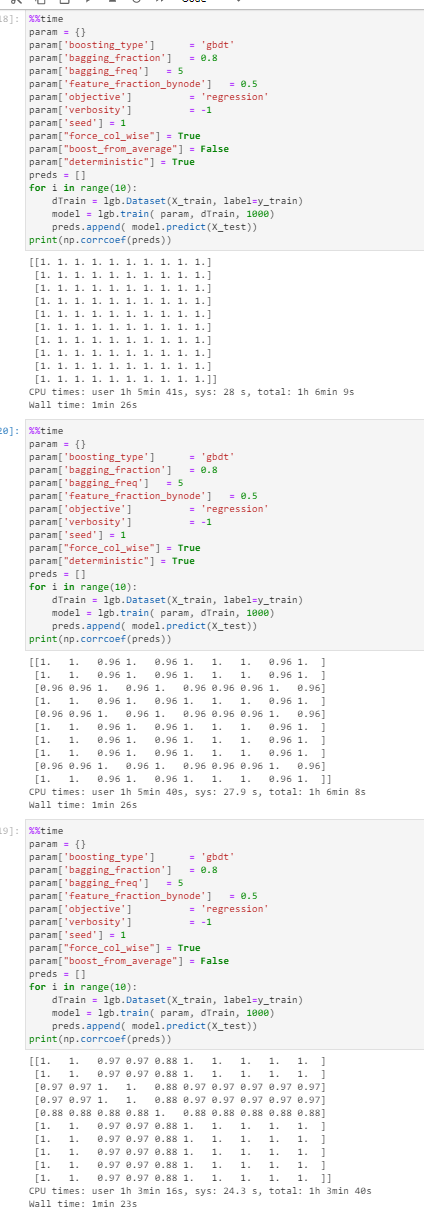
One remaining issue is param["deterministic"] = True needs param["boost_from_average"] = False to work correctly, maybe it should override that, or display a warning to do so. Tomorrow I will test this version with a larger real-life use case and see if the issue is solved for good.
rebidaldal
on 17 Nov 2020
@rebidaldal good news, thank you very much! I will take a look for boost_from_average
guolinke
on 18 Nov 2020
@rebidaldal I think #3578 should fix the boost_from_average problem.
guolinke
on 18 Nov 2020
I just tested the new release with real-life data (approx. 85GBs of tabular data in feather format) today. Using 5 identical machines with 48 cores (single socket) and with the same image file, I was able to replicate the results 5 times.
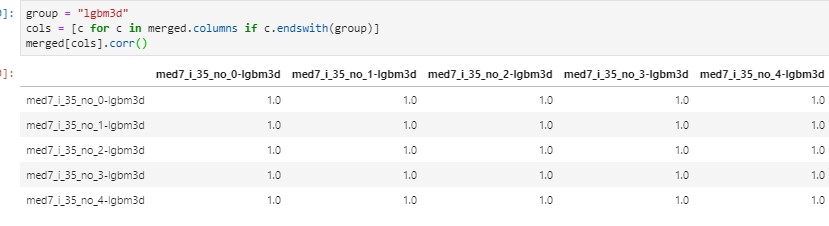
From this mini experiment I see that same data + same code + same seed + same image + same kind of machine ensures replicability which is sufficient for me, and I guess it is also sufficient for most people who needs replicability.
Tomorrow I will also try the branch #3578 to see if boost_from_averageis fixed for me.
Thanks.
rebidaldal
on 18 Nov 2020
Related issues
 jameslamb
·
3Comments
jameslamb
·
3Comments
 tbenthompson
·
3Comments
tbenthompson
·
3Comments
 ivinogra
·
3Comments
ivinogra
·
3Comments
 NicolasHug
·
3Comments
NicolasHug
·
3Comments
 mayer79
·
3Comments
mayer79
·
3Comments
Most helpful comment
Hi Guolin, I will try to make docker containers for deterministic and default (3.0.99) branches and share it with you. I already have some Amazon Machine Images on hand but they are kind of troublesome to share. Is there any other branches you would suggest me to try and reproduce the bug?
Thanks.